MECAT: A Multi-Experts Constructed Benchmark for Fine-Grained Audio Understanding Tasks
Pith reviewed 2026-05-19 02:35 UTC · model grok-4.3
The pith
MECAT introduces a benchmark for fine-grained audio understanding using multi-expert construction and a new DATE evaluation metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
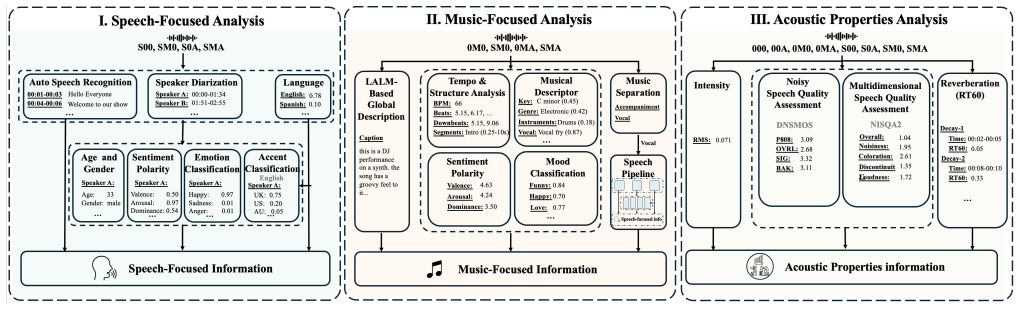
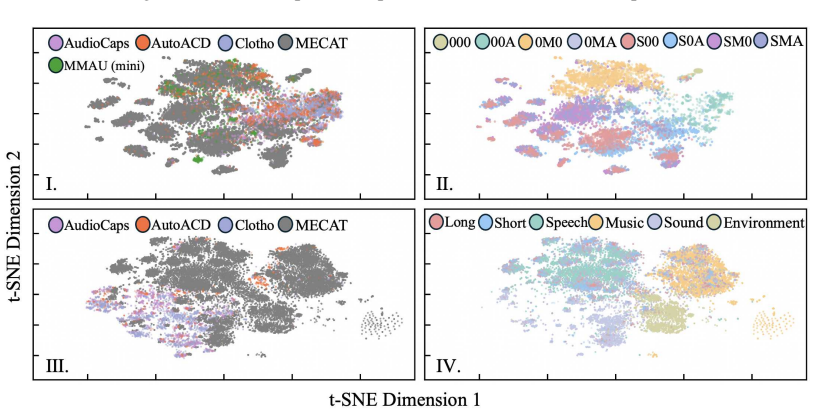
MECAT is constructed via a pipeline integrating analysis from specialized expert models with Chain-of-Thought large language model reasoning, providing multi-perspective, fine-grained captions and open-set question-answering pairs for audio understanding tasks, evaluated with the DATE metric that penalizes generic terms and rewards detailed descriptions through single-sample semantic similarity combined with cross-sample discriminability.
What carries the argument
The multi-expert construction pipeline that merges outputs from specialized audio expert models with chain-of-thought reasoning from large language models to generate accurate fine-grained annotations.
If this is right
- State-of-the-art audio models can be more precisely evaluated for their ability to produce detailed rather than generic descriptions.
- New insights into model limitations in capturing nuanced audio elements are provided.
- Future audio-language model development can target improvements measured by the DATE metric.
Where Pith is reading between the lines
- Similar multi-expert pipelines could be applied to create benchmarks in other sensory domains like video or multimodal data.
- Adoption of DATE-like metrics might improve evaluation standards across language model benchmarks in general.
- The open-set QA pairs could support training models directly for better fine-grained understanding.
Load-bearing premise
The pipeline integrating specialized expert models with chain-of-thought large language model reasoning reliably produces accurate and unbiased fine-grained annotations that match true human distinctions in audio content.
What would settle it
Human evaluation where listeners compare the generated fine-grained captions and questions against the actual audio to check if they capture details that generic annotations miss, or if they introduce inaccuracies.
Figures




read the original abstract
While large audio-language models have advanced open-ended audio understanding, they still fall short of nuanced human-level comprehension. This gap persists largely because current benchmarks, limited by data annotations and evaluation metrics, fail to reliably distinguish between generic and highly detailed model outputs. To this end, this work introduces MECAT, a Multi-Expert Constructed Benchmark for Fine-Grained Audio Understanding Tasks. Generated via a pipeline that integrates analysis from specialized expert models with Chain-of-Thought large language model reasoning, MECAT provides multi-perspective, fine-grained captions and open-set question-answering pairs. The benchmark is complemented by a novel metric: DATE (Discriminative-Enhanced Audio Text Evaluation). This metric penalizes generic terms and rewards detailed descriptions by combining single-sample semantic similarity with cross-sample discriminability. A comprehensive evaluation of state-of-the-art audio models is also presented, providing new insights into their current capabilities and limitations. The data and code are available at https://github.com/xiaomi-research/mecat
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MECAT, a benchmark for fine-grained audio understanding tasks generated via a pipeline that integrates specialized expert models with Chain-of-Thought LLM reasoning to produce multi-perspective captions and open-set QA pairs. It also proposes the DATE metric, which evaluates outputs by combining single-sample semantic similarity with cross-sample discriminability to penalize generic terms and reward detailed descriptions, and reports evaluations of state-of-the-art audio models.
Significance. If the generated annotations prove reliable, MECAT and DATE could meaningfully advance audio-language model evaluation by addressing the inability of existing benchmarks to distinguish nuanced from generic outputs. The public release of data and code at the provided GitHub link is a clear strength that supports reproducibility.
major comments (2)
- [Abstract] Abstract and benchmark construction description: the central claim that the multi-expert + CoT pipeline produces accurate fine-grained annotations reflecting human-level distinctions lacks any reported quantitative human agreement study, inter-annotator comparison, or systematic error analysis on the outputs of the expert models and LLM.
- [Evaluation] Evaluation section: no detailed results, ablations, or comparisons are provided to demonstrate that DATE offers a measurable advantage over standard metrics in distinguishing model capabilities on fine-grained tasks.
minor comments (2)
- [Abstract] The abstract would benefit from including basic statistics such as the number of audio clips or total annotations to give readers immediate context on benchmark scale.
- [Metric Definition] Ensure consistent definition of the DATE acronym and its components on first use in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, acknowledging areas where additional evidence would strengthen the work, and describe the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract and benchmark construction description: the central claim that the multi-expert + CoT pipeline produces accurate fine-grained annotations reflecting human-level distinctions lacks any reported quantitative human agreement study, inter-annotator comparison, or systematic error analysis on the outputs of the expert models and LLM.
Authors: We agree that a quantitative human validation study would provide stronger support for the reliability of the generated annotations. The manuscript currently emphasizes the design of the multi-expert pipeline combined with Chain-of-Thought reasoning to capture fine-grained distinctions, without including formal inter-annotator agreement metrics or a systematic error analysis. In the revised manuscript, we will add a dedicated human evaluation subsection. This will include agreement statistics (e.g., Cohen's kappa or Krippendorff's alpha) computed on a sampled subset of captions and QA pairs, along with qualitative error categorization comparing expert-model outputs against human judgments. revision: yes
-
Referee: [Evaluation] Evaluation section: no detailed results, ablations, or comparisons are provided to demonstrate that DATE offers a measurable advantage over standard metrics in distinguishing model capabilities on fine-grained tasks.
Authors: We acknowledge that the current evaluation could more explicitly demonstrate the advantages of DATE. The manuscript reports model rankings using DATE in conjunction with other metrics, but does not present ablations isolating the discriminability term or head-to-head comparisons showing superior correlation with human preference for detailed outputs. In the revision, we will expand the evaluation section with (i) an ablation study removing the cross-sample discriminability component, (ii) quantitative comparisons of DATE versus BLEU, CIDEr, and SPICE on the same model outputs, and (iii) a small-scale human preference study measuring which metric better ranks detailed versus generic responses. revision: yes
Circularity Check
No circularity: benchmark pipeline and DATE metric rely on external models and explicit definitions
full rationale
The paper constructs MECAT via an external pipeline of specialized expert models plus Chain-of-Thought LLM reasoning and defines the DATE metric as an explicit combination of single-sample semantic similarity with cross-sample discriminability. No derivation step reduces by the paper's own equations or self-citations to quantities fitted inside the work; the central claims rest on the described external components and the novel but non-self-referential metric definition, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Specialized expert models provide accurate and complementary analysis of audio content.
- domain assumption Chain-of-Thought reasoning in large language models can synthesize multi-perspective expert analyses into coherent, accurate fine-grained captions and QA pairs.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Generated via a pipeline that integrates analysis from specialized expert models with Chain-of-Thought large language model reasoning, MECAT provides multi-perspective, fine-grained captions and open-set question-answering pairs.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DATE ... combines single-sample semantic similarity with cross-sample discriminability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Omni-Embed-Audio: Leveraging Multimodal LLMs for Robust Audio-Text Retrieval
Omni-Embed-Audio uses multimodal LLMs to match CLAP on standard audio retrieval while improving text-to-text retrieval by 22% relative and hard negative discrimination by 4.3 points HNSR@10 on user-intent queries.
-
AU-Harness: An Open-Source Toolkit for Holistic Evaluation of Audio LLMs
AU-Harness introduces an efficient unified evaluation framework for audio LLMs featuring batch optimizations, multi-turn dialogue support, and standardized protocols for fair comparisons.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Bredin, H. 2023. pyannote. audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe. In Proceedings of the 24th Interspeech Conference (interspeech), 1983--1987. ISCA
work page 2023
-
[4]
Burkhardt, F.; Wagner, J.; Wierstorf, H.; Eyben, F.; and Schuller, B. 2023. Speech-based age and gender prediction with transformers. In Speech Communication; 15th ITG Conference, 46--50. VDE
work page 2023
-
[5]
Dinkel, H.; Wang, Y.; Yan, Z.; Zhang, J.; and Wang, Y. 2024. CED: Consistent ensemble distillation for audio tagging. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 291--295. IEEE
work page 2024
-
[6]
Ghosh, S.; Kong, Z.; Kumar, S.; Sakshi, S.; Kim, J.; Ping, W.; Valle, R.; Manocha, D.; and Catanzaro, B. 2025. Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities. In Proceedings of the 40th International Conference on Machine Learning (ICML), 1--48
work page 2025
-
[7]
Hawley, S. H. 2023. SHAART: Speech and Hearing in Audio and Real Time. https://github.com/drscotthawley/SHAART
work page 2023
- [8]
-
[9]
Kim, T.; and Nam, J. 2023. All-In-One Metrical And Functional Structure Analysis With Neighborhood Attentions on Demixed Audio. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)
work page 2023
-
[10]
Kong, Q.; Cao, Y.; Liu, H.; Choi, K.; and Wang, Y. 2021. Decoupling Magnitude and Phase Estimation with Deep ResUNet for Music Source Separation. In Proceedings of the 22nd International Society for Music Information Retrieval Conference (ISMIR), 342--349. Citeseer
work page 2021
- [11]
-
[12]
Mittag, G.; Naderi, B.; Chehadi, A.; and M \"o ller, S. 2021. NISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Prediction with Crowdsourced Datasets. In Proceedings of the 22nd Interspeech Conference (interspeech), 2127--2131
work page 2021
-
[13]
W.; Xu, T.; Brockman, G.; McLeavey, C.; and Sutskever, I
Radford, A.; Kim, J. W.; Xu, T.; Brockman, G.; McLeavey, C.; and Sutskever, I. 2023. Robust speech recognition via large-scale weak supervision. In Proceedings of the 40th International Conference on Machine Learning (ICML), 28492--28518
work page 2023
-
[14]
SpeechBrain: A general- purpose speech toolkit
Ravanelli, M.; Parcollet, T.; Plantinga, P.; Rouhe, A.; Cornell, S.; Lugosch, L.; Subakan, C.; Dawalatabad, N.; Heba, A.; Zhong, J.; Chou, J.-C.; Yeh, S.-L.; Fu, S.-W.; Liao, C.-F.; Rastorgueva, E.; Grondin, F.; Aris, W.; Na, H.; Gao, Y.; Mori, R. D.; and Bengio, Y. 2021. SpeechBrain : A General-Purpose Speech Toolkit. ArXiv:2106.04624, arXiv:2106.04624
-
[15]
Reddy, C. K. e. a. 2021. DNSMOS: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6493--6497. IEEE
work page 2021
-
[16]
Reddy, C. K. e. a. 2022. DNSMOS P. 835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 886--890. IEEE
work page 2022
-
[17]
Wagner, J.; Triantafyllopoulos, A.; Wierstorf, H.; Schmitt, M.; Burkhardt, F.; Eyben, F.; and Schuller, B. W. 2023. Dawn of the transformer era in speech emotion recognition: closing the valence gap. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9): 10745--10759
work page 2023
-
[18]
Yizhi, L.; Yuan, R.; Zhang, G.; Ma, Y.; Chen, X.; Yin, H.; Xiao, C.; Lin, C.; Ragni, A.; Benetos, E.; et al. 2023. MERT: Acoustic music understanding model with large-scale self-supervised training. In Proceedings of the 12th International Conference on Learning Representations (ICLR), 1--24
work page 2023
-
[19]
Zuluaga-Gomez, J.; Ahmed, S.; Visockas, D.; and Subakan, C. 2023. CommonAccent: Exploring Large Acoustic Pretrained Models for Accent Classification Based on Common Voice. In Proceedings of the 24th Interspeech Conference (interspeech), 5291--5295. ISCA
work page 2023
-
[20]
Anderson, P.; Fernando, B.; Johnson, M.; and Gould, S. 2016. Spice: Semantic propositional image caption evaluation. In Proceedings of the European conference on computer vision, 382--398. Springer
work page 2016
-
[21]
Bara \'n ski, M.; Jasi \'n ski, J.; Bartolewska, J.; Kacprzak, S.; Witkowski, M.; and Kowalczyk, K. 2025. Investigation of whisper asr hallucinations induced by non-speech audio. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1--5. IEEE
work page 2025
- [22]
-
[23]
Chu, Y.; Xu, J.; Zhou, X.; Yang, Q.; Zhang, S.; Yan, Z.; Zhou, C.; and Zhou, J. 2023. Qwen-Audio : Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models. arXiv preprint arXiv:2311.07919
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Deshmukh, S.; Elizalde, B.; Singh, R.; and Wang, H. 2023. Pengi: An Audio Language Model for Audio Tasks. In Oh, A.; Naumann, T.; Globerson, A.; Saenko, K.; Hardt, M.; and Levine, S., eds., Advances in Neural Information Processing Systems, volume 36, 18090--18108. Curran Associates, Inc
work page 2023
-
[25]
Dinkel, H.; Wang, Y.; Yan, Z.; Zhang, J.; and Wang, Y. 2024 a . CED: Consistent ensemble distillation for audio tagging. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 291--295. IEEE
work page 2024
- [26]
-
[27]
Dinkel, H.; Yan, Z.; Wang, Y.; Zhang, J.; Wang, Y.; and Wang, B. 2024 b . Scaling up masked audio encoder learning for general audio classification. In Proceedings of the 25th Interspeech Conference (interspeech), 547--551
work page 2024
-
[28]
Doh, S.; and Nam, J. 2023. LP-MusicCaps: LLM-Based Pseudo Music Captioning. In Proceedings of the 24th International Society for Music Information Retrieval Conference. International Society for Music Information Retrieval Conference
work page 2023
-
[29]
Drossos, K.; Lipping, S.; and Virtanen, T. 2020. Clotho: an Audio Captioning Dataset. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 736--740. IEEE
work page 2020
- [30]
-
[31]
Gemmeke, J. F.; Ellis, D. P.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R. C.; Plakal, M.; and Ritter, M. 2017. Audio Set: An Ontology and Human-labeled Dataset for Audio Events. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 776--780. IEEE
work page 2017
-
[32]
Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; Bi, X.; et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Hu, S.; Zhou, L.; Liu, S.; Chen, S.; Meng, L.; Hao, H.; Pan, J.; Liu, X.; Li, J.; Sivasankaran, S.; et al. 2024. WavLLM: Towards Robust and Adaptive Speech Large Language Model. In Proceedings of the Findings of the Association for Computational Linguistics (EMNLP), 4552--4572
work page 2024
-
[34]
Huang, R.; Li, M.; Yang, D.; Shi, J.; Chang, X.; Ye, Z.; Wu, Y.; Hong, Z.; Huang, J.; Liu, J.; et al. 2024. Audiogpt: Understanding and generating speech, music, sound, and talking head. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, 23802--23804
work page 2024
-
[35]
D.; Kim, B.; Lee, H.; and Kim, G
Kim, C. D.; Kim, B.; Lee, H.; and Kim, G. 2019. Audiocaps: Generating captions for audios in the wild. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 119--132
work page 2019
-
[36]
Kim, J.; Jung, J.; Lee, J.; and Woo, S. H. 2024. EnCLAP: Combining Neural Audio Codec and Audio-Text Joint Embedding for Automated Audio Captioning. In ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6735--6739
work page 2024
-
[37]
KimiTeam; Ding, D.; Ju, Z.; Leng, Y.; Liu, S.; Liu, T.; Shang, Z.; Shen, K.; Song, W.; Tan, X.; Tang, H.; Wang, Z.; Wei, C.; Xin, Y.; Xu, X.; Yu, J.; Zhang, Y.; Zhou, X.; Charles, Y.; Chen, J.; Chen, Y.; Du, Y.; He, W.; Hu, Z.; Lai, G.; Li, Q.; Liu, Y.; Sun, W.; Wang, J.; Wang, Y.; Wu, Y.; Wu, Y.; Yang, D.; Yang, H.; Yang, Y.; Yang, Z.; Yin, A.; Yuan, R.;...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Lee, S.; Chung, J.; Yu, Y.; Kim, G.; Breuel, T.; Chechik, G.; and Song, Y. 2021. Acav100m: Automatic curation of large-scale datasets for audio-visual video representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 10274--10284
work page 2021
-
[39]
Lee, Y.; Park, I.; and Kang, M. 2024. FLEUR: An Explainable Reference-Free Evaluation Metric for Image Captioning Using a Large Multimodal Model. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 3732--3746
work page 2024
-
[40]
Li, G.; Wei, Y.; Tian, Y.; Xu, C.; Wen, J.-R.; and Hu, D. 2022. Learning to answer questions in dynamic audio-visual scenarios. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 19108--19118
work page 2022
-
[41]
Lipping, S.; Sudarsanam, P.; Drossos, K.; and Virtanen, T. 2022. Clotho-aqa: A crowdsourced dataset for audio question answering. In Proceedings of the 30th European Signal Processing Conference (EUSIPCO), 1140--1144. IEEE
work page 2022
-
[42]
Liu, J.; Li, G.; Zhang, J.; Dinkel, H.; Wang, Y.; Yan, Z.; Wang, Y.; and Wang, B. 2024 a . Enhancing Automated Audio Captioning via Large Language Models with Optimized Audio Encoding. In Proceedings of the 25th Interspeech Conference (interspeech), 1135--1139
work page 2024
-
[43]
Liu, J.; Li, G.; Zhang, J.; Liu, C.; Dinkel, H.; Wang, Y.; Yan, Z.; Wang, Y.; and Wang, B. 2024 b . Leveraging ced encoder and large language models for automated audio captioning. Proceedings of the DCASE Challenge, 1--4
work page 2024
-
[44]
Lyon, R. F. 2017. Human and machine hearing. Cambridge University Press
work page 2017
- [45]
- [46]
-
[47]
InNeuRIPS Workshop on Self- Supervised Learning for Speech and Audio Process- ing
Pandey, P.; Swaminathan, R. V.; Girish, K.; Sen, A.; Xie, J.; Strimel, G. P.; and Schwarz, A. 2025. SIFT-50m: A large-scale multilingual dataset for speech instruction fine-tuning. arXiv preprint arXiv:2504.09081
-
[48]
Papineni, K.; Roukos, S.; Ward, T.; and Zhu, W.-J. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 311--318
work page 2002
-
[49]
Plack, C. J. 2023. The sense of hearing. Routledge
work page 2023
-
[50]
Reimers, N.; and Gurevych, I. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics
work page 2019
-
[51]
AudioPaLM: A Large Language Model That Can Speak and Listen
Rubenstein, P. K.; Asawaroengchai, C.; Nguyen, D. D.; Bapna, A.; Borsos, Z.; Quitry, F. d. C.; Chen, P.; Badawy, D. E.; Han, W.; Kharitonov, E.; et al. 2023. AudioPaLM : A Large Language Model That Can Speak and Listen. arXiv preprint arXiv:2306.12925
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Sakshi, S.; Tyagi, U.; Kumar, S.; Seth, A.; Selvakumar, R.; Nieto, O.; Duraiswami, R.; Ghosh, S.; and Manocha, D. 2025. MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark. In Proceedings of the 13th International Conference on Learning Representations (ICLR), 1--36
work page 2025
- [53]
-
[54]
Sun, L.; Xu, X.; Wu, M.; and Xie, W. 2024. Auto-ACD: A large-scale dataset for audio-language representation learning. In Proceedings of the 32nd ACM International Conference on Multimedia, 5025--5034
work page 2024
-
[55]
Tang, C.; Yu, W.; Sun, G.; Chen, X.; Tan, T.; Li, W.; Lu, L.; MA, Z.; and Zhang, C. 2024. SALMONN: Towards Generic Hearing Abilities for Large Language Models. In Proceedings of the 20th International Conference on Learning Representations (ICLR), 1--23
work page 2024
-
[56]
Vedantam, R.; Lawrence Zitnick, C.; and Parikh, D. 2015. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4566--4575
work page 2015
-
[57]
Wang, B.; Zou, X.; Lin, G.; Sun, S.; Liu, Z.; Zhang, W.; Liu, Z.; Aw, A.; and Chen, N. 2025. AudioBench: A Universal Benchmark for Audio Large Language Models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 4297--4316
work page 2025
- [58]
-
[59]
Wu, M.; Dinkel, H.; and Yu, K. 2019. Audio caption: Listen and tell. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 830--834. IEEE
work page 2019
-
[60]
Xu, J.; Guo, Z.; He, J.; Hu, H.; He, T.; Bai, S.; Chen, K.; Wang, J.; Fan, Y.; Dang, K.; et al. 2025. Qwen2. 5-omni technical report. arXiv preprint arXiv:2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Yuan, Y.; Jia, D.; Zhuang, X.; Chen, Y.; Chen, Z.; Wang, Y.; Wang, Y.; Liu, X.; Kang, X.; Plumbley, M. D.; et al. 2025. Sound-VECaps: Improving Audio Generation with Visually Enhanced Captions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1--5. IEEE
work page 2025
-
[62]
Zhang, T.; Yu, Y.; Mao, X.; Lu, Y.; Li, Z.; and Wang, H. 2022. FENSE: A feature-based ensemble modeling approach to cross-project just-in-time defect prediction. Empirical Software Engineering, 27(7): 162
work page 2022
-
[63]
Zheng, L.; Chiang, W.-L.; Sheng, Y.; Zhuang, S.; Wu, Z.; Zhuang, Y.; Lin, Z.; Li, Z.; Li, D.; Xing, E.; et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36: 46595--46623
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.