Combating the Memory Walls: Optimization Pathways for Long-Context Agentic LLM Inference
Pith reviewed 2026-05-18 17:44 UTC · model grok-4.3
The pith
PLENA overcomes memory walls for long-context agentic LLM inference using a flattened systolic array and asymmetric quantization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that a co-designed architecture centered on a flattened systolic array, compute and memory units that implement asymmetric quantization, and direct FlashAttention hardware, together with supporting software, removes the dominant memory bottlenecks in long-context agentic workloads and thereby produces up to 2.23 times the throughput of an A100 GPU and 4.70 times that of a TPU v6e while using identical multiplier counts and memory configurations, plus up to 4.04 times better energy efficiency than the A100.
What carries the argument
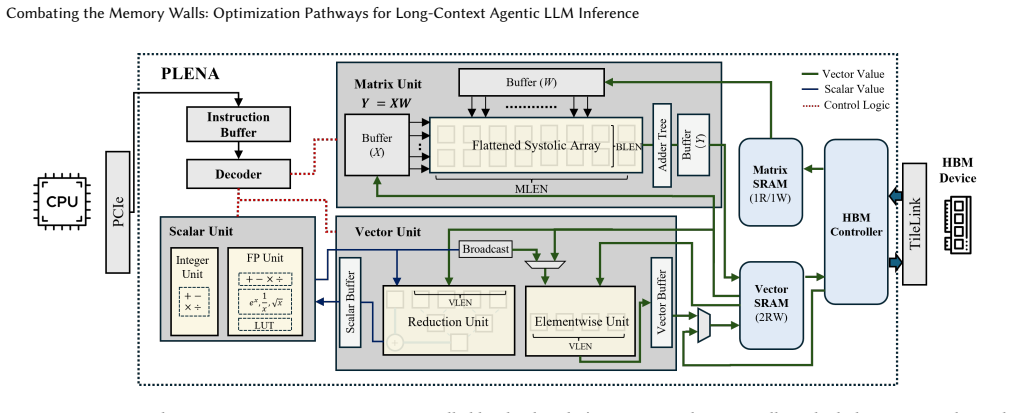
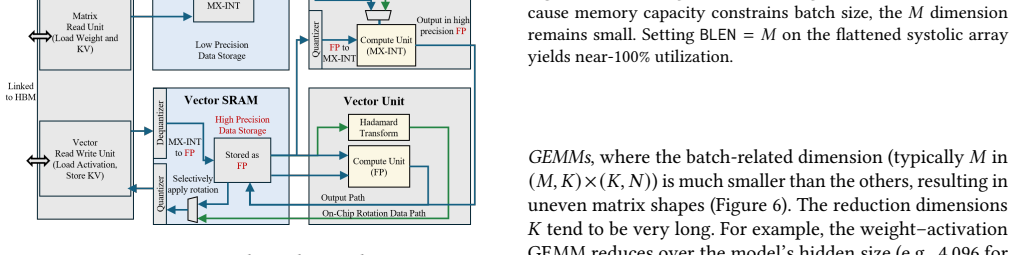
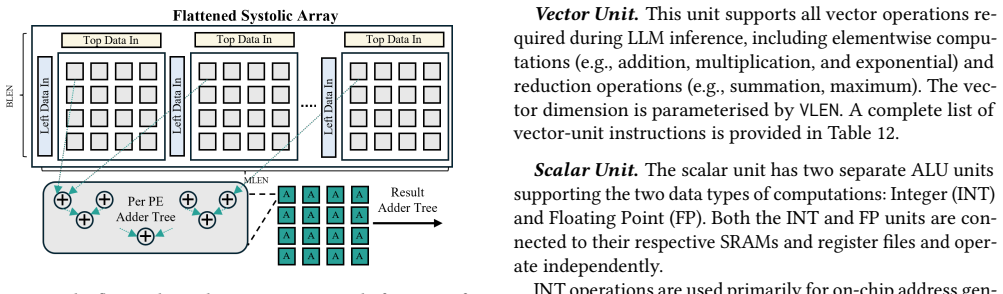
The flattened systolic-array architecture, which rearranges processing elements to reduce data movement across long sequences, combined with asymmetric quantization that trims memory traffic by applying different precisions to weights and activations.
If this is right
- Agentic queries with contexts that include full webpages or extended tool trajectories complete more work per second on hardware with the same multiplier and memory budget.
- Energy per inference drops enough to support sustained operation of AI agents in power-limited settings.
- Compute utilization rises because fewer cycles are spent waiting for off-chip data.
- The open software stack of ISA, compiler, and simulator makes it easier to adapt the same pathways to related long-sequence workloads.
Where Pith is reading between the lines
- The same flattened layout could be tested on other memory-heavy models such as large recommendation systems or video transformers.
- As context lengths continue to grow, the architecture might be paired with software context-compression methods to stretch gains further.
- The automated design-space exploration flow offers a template for quickly evaluating similar co-designs in neighboring domains like graph processing accelerators.
Load-bearing premise
The transaction-level simulator and automated design-space exploration correctly forecast how the flattened systolic array and asymmetric quantization will behave in real silicon under long-context agentic workloads.
What would settle it
Fabricate a PLENA chip and run LLaMA-based agentic inference with long contexts on it, then compare measured throughput and energy numbers directly against the simulator predictions.
Figures










read the original abstract
LLMs now form the backbone of AI agents across a diverse range of applications, including tool use, command-line interfaces, and web or computer interaction. These agentic LLM inference tasks are fundamentally different from chatbot-focused inference. They often involve much longer context lengths to capture complex and prolonged inputs, such as an entire webpage DOM or complicated tool-call trajectories. This, in turn, generates significant off-chip memory traffic during inference and causes workloads to be constrained by two memory walls, namely the bandwidth wall and the capacity wall, preventing compute units from achieving high utilization. In this paper, we introduce PLENA, a hardware-software co-designed system built around three core optimization pathways. PLENA features a novel flattened systolic-array architecture (Pathway 1) and efficient compute and memory units that support an asymmetric quantization scheme (Pathway 2). It also provides native support for FlashAttention (Pathway 3). In addition, PLENA includes a complete software-hardware stack, consisting of a custom ISA, a compiler, a transaction-level simulator, and an automated design-space exploration flow. Experimental results show that PLENA delivers up to 2.23x and 4.70x higher throughput than the A100 GPU and TPU v6e, respectively, under identical multiplier counts and memory configurations during LLaMA agentic inference. PLENA also achieves up to 4.04x higher energy efficiency than the A100 GPU. The full PLENA system, including its simulator, compiler, ISA, and RTL implementation, will be open-sourced to the research community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PLENA, a hardware-software co-designed system to address memory bandwidth and capacity walls in long-context agentic LLM inference. It proposes a flattened systolic-array architecture, asymmetric quantization with efficient compute/memory units, native FlashAttention support, and a full stack including custom ISA, compiler, transaction-level simulator, and automated design-space exploration. Simulation results under matched multiplier counts and memory configurations claim up to 2.23x higher throughput than A100 GPU and 4.70x than TPU v6e, plus up to 4.04x higher energy efficiency than A100, for LLaMA agentic workloads. The full system including simulator, compiler, ISA, and RTL is planned for open-sourcing.
Significance. If the simulator results hold under real hardware, this work could meaningfully advance specialized accelerators for agentic AI by targeting memory walls in long-context scenarios that differ from standard chatbot inference. The complete co-design stack and commitment to open-sourcing the simulator, compiler, ISA, and RTL are notable strengths that support reproducibility and further research.
major comments (1)
- [Abstract and performance evaluation] Abstract and performance evaluation: The central throughput (2.23x vs A100, 4.70x vs TPU v6e) and energy efficiency (4.04x vs A100) claims are obtained exclusively from the custom transaction-level simulator and automated DSE flow. The manuscript reports no cycle-accurate RTL simulation results, micro-benchmark correlations with the simulator, or fabricated silicon measurements to confirm accurate modeling of memory traffic, interconnect contention, and asymmetric quantization effects at the scale of long-context agentic LLaMA workloads. This validation gap is load-bearing for the headline claims.
minor comments (2)
- [Abstract] The abstract and experimental results lack error bars, detailed workload descriptions (e.g., specific context lengths or tool-call trajectories), and quantification of accuracy impact from the asymmetric quantization scheme.
- [Architecture description] Notation for the flattened systolic array and custom ISA could be clarified with additional diagrams or pseudocode to aid reader understanding of the hardware-software interface.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential significance of PLENA in addressing memory walls for long-context agentic LLM inference. We address the single major comment below with an honest assessment of our current validation approach and planned revisions.
read point-by-point responses
-
Referee: [Abstract and performance evaluation] Abstract and performance evaluation: The central throughput (2.23x vs A100, 4.70x vs TPU v6e) and energy efficiency (4.04x vs A100) claims are obtained exclusively from the custom transaction-level simulator and automated DSE flow. The manuscript reports no cycle-accurate RTL simulation results, micro-benchmark correlations with the simulator, or fabricated silicon measurements to confirm accurate modeling of memory traffic, interconnect contention, and asymmetric quantization effects at the scale of long-context agentic LLaMA workloads. This validation gap is load-bearing for the headline claims.
Authors: We acknowledge that the reported throughput and energy-efficiency numbers are generated by our transaction-level simulator and automated DSE flow rather than cycle-accurate RTL simulation or silicon measurements. The simulator was constructed specifically to model the dominant memory-bandwidth and capacity effects in long-context agentic workloads, including detailed tracking of off-chip traffic, interconnect contention, and the asymmetric quantization compute/memory units. Transaction-level modeling was selected because it permits rapid, large-scale design-space exploration that would be infeasible with cycle-accurate RTL simulation for the full system size and workload lengths considered. We have not yet performed or reported cycle-accurate RTL runs or fabricated-chip results, as the manuscript presents an architectural co-design proposal rather than a completed tape-out. In the revised manuscript we will add an expanded section describing the simulator’s modeling fidelity, the validation steps taken against simpler micro-benchmarks, and the expected accuracy bounds for the key metrics. We will also clarify that the open-sourced RTL will enable independent cycle-accurate verification by the community. We believe these additions directly address the validation concern while preserving the paper’s focus on the three optimization pathways. revision: partial
Circularity Check
No circularity: simulation outputs benchmarked against external hardware
full rationale
The paper presents PLENA's throughput and energy results exclusively as outputs from its transaction-level simulator and automated DSE flow, benchmarked against external A100 GPU and TPU v6e baselines under identical multiplier counts and memory configurations. No derivation step reduces by construction to fitted parameters, self-definitions, or load-bearing self-citations; the architecture (flattened systolic array, asymmetric quantization, FlashAttention support), custom ISA, compiler, and simulator are described as independent contributions whose metrics are generated rather than tautologically assumed. The chain remains self-contained with external comparisons and no evidence of renaming known results or smuggling ansatzes via prior self-work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PLENA features a novel flattened systolic-array architecture (Pathway 1) and efficient compute and memory units that support an asymmetric quantization scheme (Pathway 2). It also provides native support for FlashAttention (Pathway 3).
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experimental results show that PLENA delivers up to 2.23x and 4.70x higher throughput than the A100 GPU and TPU v6e, respectively, under identical multiplier counts and memory configurations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 6 Pith papers
-
NPU Design for Diffusion Language Model Inference
Introduces the first NPU accelerator for diffusion language models with dLLM-specific ISA, hardware execution model, BAOS KV quantization, and 7nm RTL synthesis.
-
TriAxialKV: Toward Extreme Low-Precision KV-Cache Quantization for Agentic Inference Tasks
TriAxialKV introduces triaxial mixed-precision KV-cache quantization that matches BF16 accuracy at 4.5x cache size and 30% higher throughput for a Qwen3-VL agent on OSWorld.
-
Slipstream: Trajectory-Grounded Compaction Validation for Long-Horizon Agents
Slipstream uses asynchronous compaction with trajectory-grounded judge validation to improve long-horizon agent accuracy by up to 8.8 percentage points and reduce latency by up to 39.7%.
-
MemExplorer: Navigating the Heterogeneous Memory Design Space for Agentic Inference NPUs
MemExplorer optimizes heterogeneous memory systems for agentic LLM inference on NPUs and reports up to 2.3x higher energy efficiency than baselines under fixed power budgets.
-
Mix-Quant: Quantized Prefilling, Precise Decoding for Agentic LLMs
Mix-Quant quantizes prefilling to NVFP4 and keeps BF16 for decoding in agentic LLMs, achieving up to 3x prefilling speedup while largely preserving task performance on long-context and agentic benchmarks.
-
GoodServe: Towards High-Goodput Serving of Agentic LLM Inferences over Heterogeneous Resources
GoodServe proposes a predict-and-rectify routing system for agentic LLM inferences on heterogeneous GPUs that improves goodput by up to 27.4%.
Reference graph
Works this paper leans on
-
[1]
Barroso, Tathagata Chakraborti, Eli M
Mayank Agarwal, Jorge J. Barroso, Tathagata Chakraborti, Eli M. Dow, Kshitij Fadnis, Borja Godoy, Madhavan Pallan, and Kartik Tala- madupula. 2020. Project CLAI: Instrumenting the Command Line as a New Environment for AI Agents. arXiv:2002.00762 [cs.HC] https://arxiv.org/abs/2002.00762
-
[2]
Meta AI. 2025.The Llama 4 herd: The beginning of a new era of na- tively multimodal AI innovation.https://ai.meta.com/blog/llama-4- multimodal-intelligence/Accessed: 2025-08-16
work page 2025
-
[3]
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: A Next-generation Hyperparameter Optimization Framework. arXiv:1907.10902
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[4]
Reza Yazdani Aminabadi, Samyam Rajbhandari, Minjia Zhang, Am- mar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Jeff Rasley, Shaden Smith, Olatunji Ruwase, and Yuxiong He. 2022. DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale. arXiv:2207.00032 [cs.LG]https://arxiv.org/abs/2207.00032
-
[5]
Mikel Artetxe, Shruti Bhosale, Naman Goyal, Todor Mihaylov, Myle Ott, Sam Shleifer, Xi Victoria Lin, Jingfei Du, Srinivasan Iyer, Ra- makanth Pasunuru, Giri Anantharaman, Xian Li, Shuohui Chen, Halil Akin, Mandeep Baines, Louis Martin, Xing Zhou, Punit Singh Koura, Brian O’Horo, Jeff Wang, Luke Zettlemoyer, Mona Diab, Zor- nitsa Kozareva, and Ves Stoyanov...
-
[6]
Croci, Bo Li, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. 2024. QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs. arXiv:2404.00456 [cs.LG]https://arxiv.org/abs/2404.00456
-
[7]
Junjie Bai, Fang Lu, and Ke Zhang. 2019. ONNX: Open Neural Network Exchange.https://github.com/onnx/onnx.GitHub repository(2019)
work page 2019
- [8]
-
[9]
Maximilian Balandat, Brian Karrer, Daniel Jiang, Samuel Daulton, Ben Letham, Andrew G Wilson, and Eytan Bakshy. 2020. BoTorch: A framework for efficient Monte-Carlo Bayesian optimization.Advances in neural information processing systems33 (2020), 21524–21538
work page 2020
-
[10]
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al . 2020. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 7432–7439
work page 2020
-
[11]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[12]
Thibault Le Sellier De Chezelles, Maxime Gasse, Alexandre Drouin, Massimo Caccia, Léo Boisvert, Megh Thakkar, Tom Marty, Rim As- souel, Sahar Omidi Shayegan, Lawrence Keunho Jang, Xing Han Lù, Ori Yoran, Dehan Kong, Frank F. Xu, Siva Reddy, Quentin Cappart, Gra- ham Neubig, Ruslan Salakhutdinov, Nicolas Chapados, and Alexandre Lacoste. 2025. The BrowserGy...
-
[13]
L. T. Clark, V. Vashishtha, L. Shifren, A. Gujja, S. Sinha, B. Cline, C. Ramamurthy, and G. Yeric. 2016. ASAP: A 7-nm finFET predictive process design kit.Microelectronics Journal53 (July 2016), 105–115. doi:10.1016/j.mejo.2016.04.006
-
[14]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabhar- wal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
2024.NVIDIA Blackwell Architecture Technical Brief
NVIDIA Corporation. 2024.NVIDIA Blackwell Architecture Technical Brief. Technical Report. NVIDIA Corporation.https://resources. nvidia.com/en-us-blackwell-architecture
work page 2024
-
[16]
Tri Dao. 2023. FlashAttention-2: Faster Attention with Better Par- allelism and Work Partitioning. arXiv:2307.08691 [cs.LG]https: //arxiv.org/abs/2307.08691
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Samuel Daulton, Xingchen Wan, David Eriksson, Maximilian Balandat, Michael A Osborne, and Eytan Bakshy. 2022. Bayesian optimization over discrete and mixed spaces via probabilistic reparameterization. Advances in Neural Information Processing Systems35 (2022), 12760– 12774
work page 2022
- [18]
-
[19]
Aryan Deshwal, Syrine Belakaria, and Janardhan Rao Doppa. 2021. Bayesian optimization over hybrid spaces. InInternational Conference on Machine Learning. PMLR, 2632–2643
work page 2021
-
[20]
Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. 2024. WorkArena: How Capable are Web Agents at Solving Common Knowledge Work Tasks?. InProceed- ings of the 41st International Conference on Machine Learning (Pro- ceedings of Machine Learning Research, Vol...
work page 2024
-
[21]
Carlos M Fonseca, Andreia P Guerreiro, Manuel López-Ibánez, and Luís Paquete. 2011. On the computation of the empirical attainment function. InInternational Conference on Evolutionary Multi-criterion Optimization. Springer, 106–120
work page 2011
-
[22]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2022. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Amir Gholami, Zhewei Yao, Sehoon Kim, Coleman Hooper, Michael W. Mahoney, and Kurt Keutzer. 2024. AI and Memory Wall.IEEE Micro 44, 3 (May 2024), 33–39. doi:10.1109/MM.2024.3373763
-
[24]
2025.System Architecture: TPU VM
Google. 2025.System Architecture: TPU VM. Technical Report. Google Cloud. Last updated August 1, 2025
work page 2025
-
[25]
Cong Guo, Jiaming Tang, Weiming Hu, Jingwen Leng, Chen Zhang, Fan Yang, Yunxin Liu, Minyi Guo, and Yuhao Zhu. 2023. Olive: Accel- erating large language models via hardware-friendly outlier-victim pair quantization. InProceedings of the 50th Annual International Sym- posium on Computer Architecture. 1–15
work page 2023
- [26]
-
[27]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hong- ming Zhang, Zhenzhong Lan, and Dong Yu. 2024. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. arXiv:2401.13919 [cs.CL]https://arxiv.org/abs/2401.13919
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [28]
-
[29]
Weiming Hu, Haoyan Zhang, Cong Guo, Yu Feng, Renyang Guan, Zhendong Hua, Zihan Liu, Yue Guan, Minyi Guo, and Jingwen Leng
-
[30]
M-ANT: Efficient Low-bit Group Quantization for LLMs via Mathematically Adaptive Numerical Type. In2025 IEEE International 14 Combating the Memory Walls: Optimization Pathways for Long-Context Agentic LLM Inference Symposium on High Performance Computer Architecture (HPCA). IEEE, 1112–1126
- [31]
-
[32]
Jaeyong Jang, Yulhwa Kim, Juheun Lee, and Jae-Joon Kim. 2024. FIGNA: Integer Unit-Based Accelerator Design for FP-INT GEMM Preserving Numerical Accuracy. In2024 IEEE International Sympo- sium on High-Performance Computer Architecture (HPCA). 760–773. doi:10.1109/HPCA57654.2024.00064
-
[33]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim
-
[34]
A Survey on Large Language Models for Code Generation
A Survey on Large Language Models for Code Generation. arXiv:2406.00515 [cs.CL]https://arxiv.org/abs/2406.00515
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Joshua Knowles. 2005. A summary-attainment-surface plotting method for visualizing the performance of stochastic multiobjective optimizers. In5th International Conference on Intelligent Systems Design and Applications (ISDA’05). IEEE, 552–557
work page 2005
-
[36]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2023. Large Language Models are Zero-Shot Reasoners. arXiv:2205.11916 [cs.CL]https://arxiv.org/abs/2205.11916
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [37]
- [38]
- [39]
- [40]
-
[41]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. AWQ: Activation-aware Weight Quantization for On- Device LLM Compression and Acceleration.Proceedings of Machine Learning and Systems6 (2024), 87–100
work page 2024
-
[42]
Haitao Liu, Yew-Soon Ong, Xiaobo Shen, and Jianfei Cai. 2020. When Gaussian process meets big data: A review of scalable GPs.IEEE transactions on neural networks and learning systems31, 11 (2020), 4405–4423
work page 2020
- [43]
-
[44]
Nisa Bostancı, Ataberk Olgun, A
Haocong Luo, Yahya Can Tuğrul, F. Nisa Bostancı, Ataberk Olgun, A. Giray Yağlıkçı, and Onur Mutlu. 2023. Ramulator 2.0: A Modern, Modular, and Extensible DRAM Simulator. arXiv:2308.11030 [cs.AR] https://arxiv.org/abs/2308.11030
- [45]
-
[46]
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher
-
[47]
Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[48]
AI Meta. 2024. Introducing meta llama 3: The most capable openly available llm to date.Meta AI(2024)
work page 2024
-
[49]
2024.Browser Use: Enable AI to control your browser.https://github.com/browser-use/browser-use
Magnus Müller and Gregor Žunič. 2024.Browser Use: Enable AI to control your browser.https://github.com/browser-use/browser-use
work page 2024
-
[50]
Markus Nagel, Marios Fournarakis, Rana Ali Amjad, Yelysei Bon- darenko, Mart Van Baalen, and Tijmen Blankevoort. 2021. A white paper on neural network quantization.arXiv preprint arXiv:2106.08295 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [51]
-
[52]
OpenAI. 2024. ChatGPT.https://openai.com/index/chatgpt/. Accessed: 2024-08-04
work page 2024
-
[53]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Bern...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [54]
-
[55]
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. 2016. The LAMBADA dataset: Word prediction requiring a broad discourse context.arXiv preprint arXiv:1606.06031(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[56]
Jiajun Qin, Tianhua Xia, Cheng Tan, Jeff Zhang, and Sai Qian Zhang
-
[57]
PICACHU: Plug-In CGRA Handling Upcoming Nonlinear Op- erations in LLMs. InProceedings of the 30th ACM International Con- ference on Architectural Support for Programming Languages and Op- erating Systems, Volume 2(Rotterdam, Netherlands)(ASPLOS ’25). Association for Computing Machinery, New York, NY, USA, 845–861. doi:10.1145/3676641.3716013
-
[58]
Akshat Ramachandran, Souvik Kundu, and Tushar Krishna. 2025. Mi- croscopiq: Accelerating foundational models through outlier-aware microscaling quantization. InProceedings of the 52nd Annual Interna- tional Symposium on Computer Architecture. 1193–1209
work page 2025
- [59]
-
[60]
Bita Darvish Rouhani, Ritchie Zhao, Ankit More, Mathew Hall, Alireza Khodamoradi, Summer Deng, Dhruv Choudhary, Marius Cornea, Eric Dellinger, Kristof Denolf, Stosic Dusan, Venmugil Elango, Max- imilian Golub, Alexander Heinecke, Phil James-Roxby, Dharmesh Jani, Gaurav Kolhe, Martin Langhammer, Ada Li, Levi Melnick, Maral Mesmakhosroshahi, Andres Rodrigue...
-
[61]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Winogrande: An adversarial winograd schema challenge at scale.Commun. ACM64, 9 (2021), 99–106
work page 2021
-
[62]
Satyabrata Sarangi and Bevan Baas. 2021. DeepScaleTool: A Tool for the Accurate Estimation of Technology Scaling in the Deep-Submicron Era. In2021 IEEE International Symposium on Circuits and Systems (ISCAS). 1–5. doi:10.1109/ISCAS51556.2021.9401196
-
[63]
Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P Adams, and Nando De Freitas. 2015. Taking the human out of the loop: A review of Bayesian optimization.Proc. IEEE104, 1 (2015), 148–175
work page 2015
- [65]
-
[66]
SiFive, Inc. 2020.TileLink Specification. Specification v1.8.1. SiFive, Inc.https://starfivetech.com/uploads/tilelink_spec_1.8.1.pdfVersion 1.8.1
work page 2020
-
[67]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie- Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971 [cs.CL]https://arxiv. org/abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Alma- hairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[69]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2023. Attention Is All You Need. arXiv:1706.03762 [cs.CL]https://arxiv.org/ abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
Ziyu Wang, Frank Hutter, Masrour Zoghi, David Matheson, and Nando De Feitas. 2016. Bayesian optimization in a billion dimensions via random embeddings.Journal of Artificial Intelligence Research55 (2016), 361–387
work page 2016
- [71]
- [72]
-
[73]
Emergent Abilities of Large Language Models
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Se- bastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. 2022. Emergent Abil- ities of Large Language Models. arXiv:2206.07682 [cs.CL]https: //arxiv.org/abs/2206.07682
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[74]
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational Conference on Machine Learning. PMLR, 38087–38099
work page 2023
-
[75]
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing Su, Tianyu Liu, Rui Long, Kai Shen, and Liang Xiang. 2025. Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving. arXiv:2504.02605 [cs.SE] https://arxiv.org/abs/2504.02605
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[77]
Shulin Zeng, Jun Liu, Guohao Dai, Xinhao Yang, Tianyu Fu, Hongyi Wang, Wenheng Ma, Hanbo Sun, Shiyao Li, Zixiao Huang, Yadong Dai, Jintao Li, Zehao Wang, Ruoyu Zhang, Kairui Wen, Xuefei Ning, and Yu Wang. 2024. FlightLLM: Efficient Large Language Model Inference with a Complete Mapping Flow on FPGAs. InProceedings of the 2024 ACM/SIGDA International Sympo...
-
[78]
Hengrui Zhang, August Ning, Rohan Baskar Prabhakar, and David Wentzlaff. 2024. LLMCompass: Enabling Efficient Hardware Design for Large Language Model Inference. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). 1080–1096. doi:10.1109/ISCA59077.2024.00082
-
[79]
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. 2024. Atom: Low-bit quantization for efficient and accurate llm serving.Proceedings of Machine Learning and Systems6 (2024), 196–209. 16 Combating the Memory Walls: Optimization Pathways for Long-Context Agentic LLM Inference
work page 2024
-
[80]
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2023. KIVI : Plug- and-play 2bit KV Cache Quantization with Streaming Asymmetric Quantization. (2023). doi:10.13140/RG.2.2.28167.37282 17 A Appendix A.1 Ablation Study on Quantization Methods Table 8:Ablation study on quantization techniques. Coveri...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.