InternScenes: A Large-scale Simulatable Indoor Scene Dataset with Realistic Layouts
Pith reviewed 2026-05-18 17:08 UTC · model grok-4.3
The pith
InternScenes integrates real scans, procedural and designer scenes into 40,000 simulatable indoor environments with realistic layouts and small objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
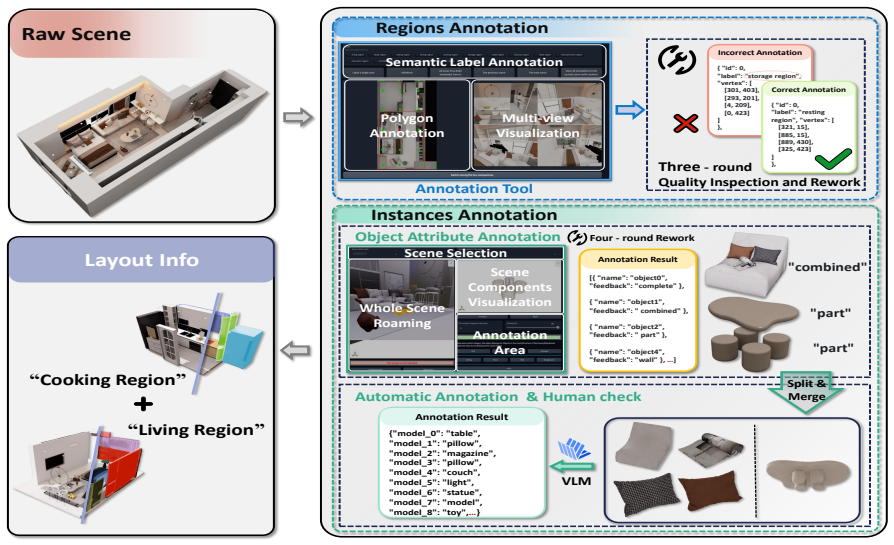
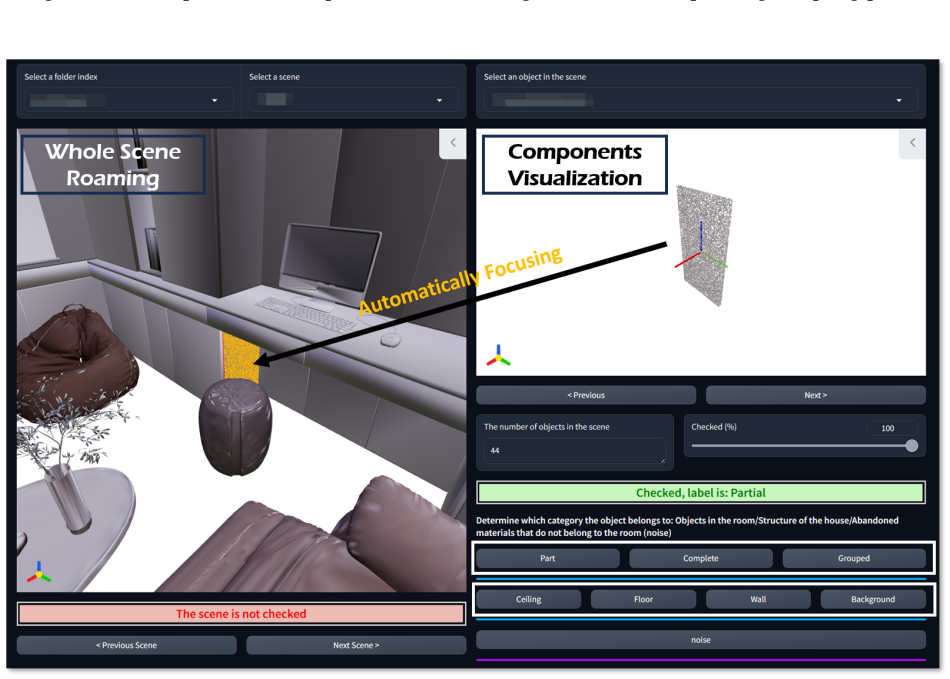
InternScenes is a large-scale simulatable indoor scene dataset built by merging real-world scans, procedurally generated scenes, and designer-created scenes to produce approximately 40,000 diverse environments containing 1.96M 3D objects, 15 common scene types, and 288 object classes. The dataset preserves massive numbers of small items, yielding realistic layouts with an average of 41.5 objects per region. A dedicated processing pipeline creates real-to-sim replicas, inserts interactive objects, and eliminates collisions through physical simulation, thereby supporting training at scale for embodied AI tasks such as scene layout generation and point-goal navigation.
What carries the argument
The data processing pipeline that converts real scans into simulatable replicas, adds interactive objects, and clears collisions with physical simulations while retaining scene diversity.
If this is right
- Scene layout generation and point-goal navigation tasks become feasible at larger scale because the dataset supplies complex yet collision-free environments.
- Training on these scenes exposes models to new difficulties arising from dense small-object layouts that earlier datasets omitted.
- The combination of real scans and generated content allows direct comparison of performance across different scene origins within the same benchmark suite.
Where Pith is reading between the lines
- The dataset could support additional embodied tasks such as object manipulation or multi-agent interaction once interactive objects are more fully utilized.
- Similar merging pipelines might be applied to outdoor or dynamic environments to create comparable large-scale resources.
- Open-sourcing the data and benchmarks invites direct replication studies that measure how much the added small objects and collision resolution improve downstream robotic transfer.
Load-bearing premise
The processing steps that turn real scans into simulatable versions, add interactive objects, and remove collisions succeed without creating new artifacts or lowering scene variety.
What would settle it
Models trained on InternScenes show no measurable gain in success rate or efficiency for point-goal navigation or layout generation when tested against models trained only on prior smaller datasets.
Figures

















read the original abstract
The advancement of Embodied AI heavily relies on large-scale, simulatable 3D scene datasets characterized by scene diversity and realistic layouts. However, existing datasets typically suffer from limitations in data scale or diversity, sanitized layouts lacking small items, and severe object collisions. To address these shortcomings, we introduce \textbf{InternScenes}, a novel large-scale simulatable indoor scene dataset comprising approximately 40,000 diverse scenes by integrating three disparate scene sources, real-world scans, procedurally generated scenes, and designer-created scenes, including 1.96M 3D objects and covering 15 common scene types and 288 object classes. We particularly preserve massive small items in the scenes, resulting in realistic and complex layouts with an average of 41.5 objects per region. Our comprehensive data processing pipeline ensures simulatability by creating real-to-sim replicas for real-world scans, enhances interactivity by incorporating interactive objects into these scenes, and resolves object collisions by physical simulations. We demonstrate the value of InternScenes with two benchmark applications: scene layout generation and point-goal navigation. Both show the new challenges posed by the complex and realistic layouts. More importantly, InternScenes paves the way for scaling up the model training for both tasks, making the generation and navigation in such complex scenes possible. We commit to open-sourcing the data, models, and benchmarks to benefit the whole community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InternScenes, a large-scale simulatable indoor scene dataset of approximately 40,000 scenes constructed by integrating real-world scans, procedurally generated scenes, and designer-created scenes. It contains 1.96M 3D objects across 15 scene types and 288 classes, with an average of 41.5 objects per region to preserve small items and achieve realistic, complex layouts. A data processing pipeline creates real-to-sim replicas, adds interactive objects, and resolves collisions through physical simulations. The dataset is evaluated on scene layout generation and point-goal navigation benchmarks, which demonstrate new challenges from the complex layouts and support scaling model training.
Significance. If the pipeline produces scenes that remain both simulatable and faithful to realistic layouts, InternScenes would address key limitations in existing datasets (scale, diversity, small-object density, and collision-free simulatability) and provide a useful resource for Embodied AI research. The open-sourcing commitment and the two benchmark tasks that expose scaling challenges are positive contributions.
major comments (2)
- [Abstract / Data Processing Pipeline] Abstract and pipeline description: the claim that physical simulation resolves collisions while preserving realistic layouts lacks any quantitative pre-/post-simulation metrics (overlap volume, centroid displacement, layout entropy, or small-object distribution statistics). Without these, it is impossible to verify that the dynamics-driven adjustments do not systematically alter placements in dense scenes (average 41.5 objects per region).
- [Abstract] Abstract: no error metrics, fidelity scores, or before-after comparisons are reported for the real-to-sim replica creation step, leaving the central claim of simulatability and realism without empirical grounding.
minor comments (2)
- [Abstract] The abstract states coverage of 15 scene types and 288 object classes but does not clarify how these categories were defined or validated against standard taxonomies.
- Figure and table captions should explicitly state whether statistics (e.g., object counts, region averages) are computed before or after the collision-resolution step.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on our manuscript. We address each major comment below with clarifications and indicate where revisions will be made to strengthen the presentation of the data processing pipeline.
read point-by-point responses
-
Referee: [Abstract / Data Processing Pipeline] Abstract and pipeline description: the claim that physical simulation resolves collisions while preserving realistic layouts lacks any quantitative pre-/post-simulation metrics (overlap volume, centroid displacement, layout entropy, or small-object distribution statistics). Without these, it is impossible to verify that the dynamics-driven adjustments do not systematically alter placements in dense scenes (average 41.5 objects per region).
Authors: We agree that quantitative pre-/post-simulation metrics would provide stronger empirical support for the claim that physical simulation resolves collisions without systematically distorting realistic layouts. The current manuscript describes the simulation-based collision resolution process and reports the final average of 41.5 objects per region, but does not include the suggested before-and-after statistics. In the revised manuscript we will add a dedicated analysis subsection with metrics including average overlap volume reduction, mean centroid displacement, layout entropy change, and small-object count distribution before versus after simulation. These will be computed on a representative subset of scenes and reported in the data processing pipeline section. revision: yes
-
Referee: [Abstract] Abstract: no error metrics, fidelity scores, or before-after comparisons are reported for the real-to-sim replica creation step, leaving the central claim of simulatability and realism without empirical grounding.
Authors: We acknowledge that the abstract and the high-level pipeline description do not report explicit error metrics or fidelity scores for the real-to-sim replica creation. The full manuscript details the replica generation procedure (including mesh cleaning, texture mapping, and physics-ready asset conversion), yet lacks the quantitative before-after comparisons suggested. We will revise the abstract to briefly reference the fidelity evaluation and add a new results subsection with geometric error (e.g., Chamfer distance), visual similarity scores, and collision-free success rates for the replica creation step on a held-out set of real scans. revision: yes
Circularity Check
No circularity: dataset curation paper with no derivation chain
full rationale
This paper presents a new indoor scene dataset constructed by integrating three external scene sources, applying a data processing pipeline for real-to-sim conversion and collision resolution via physical simulation, and preserving small objects for realism. No equations, fitted parameters, predictions of derived quantities, uniqueness theorems, or ansatzes appear in the abstract or described contributions. The central claims concern empirical scale, diversity, and simulatability of the resulting 40k scenes rather than any reduction of outputs to inputs by construction or self-citation. The work is therefore self-contained as a data release with benchmark applications, warranting a score of 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Physical simulation can reliably detect and resolve object collisions in complex indoor layouts without altering scene semantics.
Forward citations
Cited by 4 Pith papers
-
Orchestrating Spatial Semantics via a Zone-Graph Paradigm for Intricate Indoor Scene Generation
ZoneMaestro introduces a zone-graph orchestration approach with a new dataset and alternating optimization strategy to generate intricate indoor scenes that maintain both semantic intent and geometric validity.
-
Exploring Spatial Intelligence from a Generative Perspective
Fine-tuning multimodal models on a new synthetic spatial benchmark improves generative spatial compliance on real and synthetic tasks and transfers to better spatial understanding.
-
Pair2Scene: Learning Local Object Relations for Procedural Scene Generation
Pair2Scene generates complex 3D scenes beyond training data by recursively applying a learned model of local support and functional object-pair relations inside hierarchies, using collision-aware rejection sampling fo...
-
Pair2Scene: Learning Local Object Relations for Procedural Scene Generation
Pair2Scene generates complex 3D scenes beyond training data by training a network on local object-pair placement rules and applying them recursively with collision-aware sampling.
Reference graph
Works this paper leans on
-
[1]
M. Bińkowski, D. J. Sutherland, M. Arbel, and A. Gretton. Demystifying mmd gans.arXiv preprint arXiv:1801.01401,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, et al. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Midi: Multi-instance diffusion for single image to 3d scene generation
Z. Huang, Y.-C. Guo, X. An, Y. Yang, Y. Li, Z.-X. Zou, D. Liang, X. Liu, Y.-P. Cao, and L. Sheng. Midi: Multi-instance diffusion for single image to 3d scene generation.arXiv preprint arXiv:2412.03558,
-
[4]
AI2-THOR: An Interactive 3D Environment for Visual AI
E. Kolve, R. Mottaghi, W. Han, E. VanderBilt, L. Weihs, A. Herrasti, M. Deitke, K. Ehsani, D. Gordon, Y. Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
W. Li, S. Saeedi, J. McCormac, R. Clark, D. Tzoumanikas, Q. Ye, Y. Huang, R. Tang, and S. Leuteneg- ger. Interiornet: Mega-scale multi-sensor photo-realistic indoor scenes dataset.arXiv preprint arXiv:1809.00716,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Chang, et al. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai.arXiv preprint arXiv:2109.08238,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
The Replica Dataset: A Digital Replica of Indoor Spaces
J. Straub, T. Whelan, L. Ma, Y. Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Verma, et al. The replica dataset: A digital replica of indoor spaces.arXiv preprint arXiv:1906.05797,
work page internal anchor Pith review Pith/arXiv arXiv 1906
- [9]
-
[10]
method. Notably, to enhance the realism of small object placements within scenes—particularly their ability to reside inside furniture with cavities (e.g., drawers or shelves)—we first perform a simple segmentation on cavity-containing furniture, breaking them into smaller components that expose the internal cavities. Each of these components is then indi...
work page 2020
-
[11]
GPU memory usage (in GB) under different levels of parallel simulation. Scene Type Parallel=1 Parallel=20 Parallel=40 OmniScenes-Real2Sim 2.528 GB 5.205 GB 5.385 GB OmniScenes-Gen 5.399 GB 5.476 GB 5.679 GB OmniScenes-Synthetic 7.542 GB 7.785 GB 8.168 GB 28 C. System Performance and Resource Requirements Detailed Performance Metrics.We perform a comprehen...
work page 2000
-
[12]
D. Discussion on Procedural Generation with Infinigen Indoor To enrich the diversity of generated assets and layouts in our dataset, we leverage Infinigen In- doors Raistrick et al. (2024), a procedural generation framework designed to mitigate risks of introducing bias in spatial configurations and object co-occurrence patterns through fully randomized a...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.