Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Pith reviewed 2026-05-18 11:45 UTC · model grok-4.3
The pith
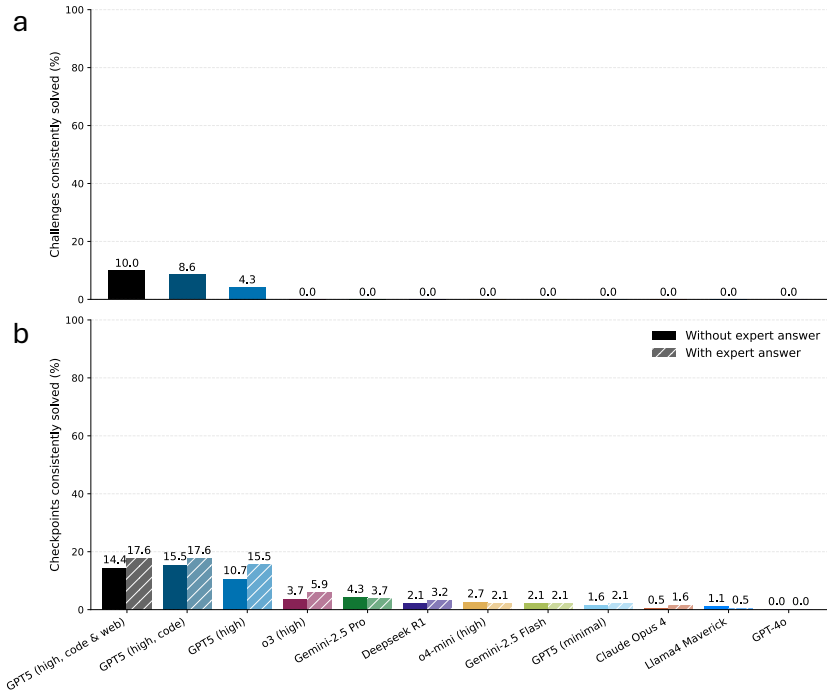
Large language models reach only 5.7 percent accuracy on full-scale frontier physics research challenges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that while LLMs demonstrate early promise on isolated reasoning checkpoints drawn from physics research, they fall short when faced with complete, composite research-scale challenges. Specifically, the highest average accuracy on the 71 full challenges is 5.7 percent for the top base model, increasing to around 10 percent when coding tools are provided. This evaluation uses problems newly created by over 50 active physicists to ensure they reflect real demands and are verifiable by machine.
What carries the argument
The CritPt benchmark, a collection of 71 composite research challenges and 190 checkpoints designed to simulate entry-level full-scale physics research projects.
If this is right
- LLMs equipped with coding tools show moderate improvement but remain unreliable on complete research challenges.
- The benchmark spans condensed matter, quantum physics, astrophysics, high energy physics and other subfields to give a broad view of current capabilities.
- Automated grading pipelines customized for advanced physics output formats enable consistent, scalable evaluation of research-style answers.
- The results provide a standardized foundation for tracking whether future models can assist with realistic scientific projects.
Where Pith is reading between the lines
- Similar benchmarks could be built for other scientific domains to test whether the same performance gap appears outside physics.
- Training approaches that emphasize competition-style problems may need supplementation with research-like tasks to improve outcomes.
- Integrating LLMs with domain-specific simulation or literature tools might help close the gap on challenges involving nonlinear dynamics or biophysics.
Load-bearing premise
The 71 composite challenges, newly created by active physicists and hand-curated to be guess-resistant and machine-verifiable, accurately represent the demands of frontier physics research.
What would settle it
If a future model achieves over 50 percent accuracy on the full set of 71 composite challenges without external tools, this would indicate the claimed large disconnect has been closed.
Figures





read the original abstract
While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 5.7%, achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the CritPt benchmark for testing LLMs on unpublished, research-level physics reasoning tasks across subfields including condensed matter, quantum physics, astrophysics, high energy physics, and others. It comprises 71 composite challenges created by 50+ active physicists from their own research, decomposed into 190 simpler checkpoint tasks. All problems are hand-curated for guess-resistant, machine-verifiable answers and evaluated via a customized automated grading pipeline for advanced physics output formats. The central empirical result is that current SOTA LLMs show limited performance on full challenges, with the best base-model average accuracy at 5.7% (GPT-5 high) and rising only to around 10% when equipped with coding tools, indicating a substantial gap between model capabilities and realistic frontier physics research demands.
Significance. If the 71 challenges prove representative of entry-level frontier research and the grading pipeline is robust, this benchmark would offer a valuable, contamination-resistant tool for measuring progress toward AI-assisted physics research. The involvement of active physicists in problem creation and the focus on composite, open-ended tasks rather than isolated math or coding problems represent a clear advance over existing benchmarks. However, the absence of the full manuscript prevents confirmation of these strengths or assessment of whether the reported accuracies genuinely reflect capability limits.
major comments (2)
- [Abstract] Abstract: The central claim that LLMs 'remain far from being able to reliably solve full research-scale challenges' rests on the reported 5.7% and ~10% accuracies. These figures depend entirely on the physics-specific automated grading pipeline and the hand-curation criteria for guess-resistance and machine-verifiability, none of which are described or exemplified in the provided text. Without these details it is impossible to determine whether the low scores arise from model limitations or from benchmark construction choices.
- [Abstract] Abstract: The assertion that the 71 composite challenges 'broadly covers modern physics research areas' and 'accurately represent the demands of frontier physics research' is load-bearing for the benchmark's claimed utility. The text provides no information on curation criteria, subfield balance, difficulty calibration, or how the 190 checkpoints were derived, leaving open the possibility that performance gaps reflect selection artifacts rather than general research demands.
minor comments (1)
- [Abstract] Abstract: The parenthetical expansion of the acronym CritPt ('Complex Research using Integrated Thinking - Physics Test') should be verified for consistency with the title phrasing 'Probing the Critical Point (CritPt)'.
Simulated Author's Rebuttal
We thank the referee for their comments and for acknowledging the potential value of the CritPt benchmark in testing LLMs on realistic frontier physics tasks. We note that the review was performed on the abstract alone, as the full manuscript (which details the grading pipeline, curation process, and problem construction) was not provided to the referee. This explains the absence of methodological specifics in the reviewed text. We address the major comments point by point below and are open to revisions that improve clarity without altering the core findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that LLMs 'remain far from being able to reliably solve full research-scale challenges' rests on the reported 5.7% and ~10% accuracies. These figures depend entirely on the physics-specific automated grading pipeline and the hand-curation criteria for guess-resistance and machine-verifiability, none of which are described or exemplified in the provided text. Without these details it is impossible to determine whether the low scores arise from model limitations or from benchmark construction choices.
Authors: We agree the abstract lacks these details due to length constraints. The full manuscript includes a dedicated methods section describing the customized automated grading pipeline for advanced physics output formats (e.g., handling symbolic expressions, diagrams, and multi-step derivations) and the hand-curation criteria applied by active physicists to ensure guess-resistance and machine-verifiability. These design choices were deliberate to produce a contamination-resistant benchmark focused on verifiable research outputs rather than open-ended generation. We will revise the abstract to include a concise reference to the pipeline and curation approach. revision: partial
-
Referee: [Abstract] Abstract: The assertion that the 71 composite challenges 'broadly covers modern physics research areas' and 'accurately represent the demands of frontier physics research' is load-bearing for the benchmark's claimed utility. The text provides no information on curation criteria, subfield balance, difficulty calibration, or how the 190 checkpoints were derived, leaving open the possibility that performance gaps reflect selection artifacts rather than general research demands.
Authors: The full manuscript provides these details: the 71 challenges were created by 50+ active physicists directly from their unpublished research, decomposed into 190 checkpoints for granular evaluation, and selected to span entry-level frontier work across condensed matter, quantum physics, astrophysics, high energy physics, and the other listed subfields with attention to balance and realistic composite structure. Difficulty was calibrated by the contributing researchers to reflect actual research demands rather than artificial selection. We will add a brief summary of subfield distribution and curation criteria to the abstract or include a supporting table in revisions. revision: yes
Circularity Check
No circularity: purely empirical benchmark with independent problem creation and direct accuracy measurement
full rationale
The paper introduces a new benchmark of 71 hand-curated research challenges created by 50+ physicists from their own work, decomposed into 190 checkpoints, and evaluates LLMs via an automated grading pipeline. The central result (5.7% average accuracy for base models) is a direct empirical measurement on this freshly constructed test set. No derivations, equations, fitted parameters, or predictions are presented that could reduce to inputs by construction. No self-citations or uniqueness theorems are invoked in the available text. The evaluation is self-contained against the stated benchmark; representativeness is an external validity question, not a circularity issue within the reported chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CritPt consists of 71 composite research challenges... evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
All problems are newly created by 50+ active physics researchers... hand-curated to admit a guess-resistant and machine-verifiable answer
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Fine-Tuning Small Reasoning Models for Quantum Field Theory
Small 7B reasoning models were fine-tuned on synthetic and curated QFT problems using RL and SFT, yielding performance gains, error analysis, and public release of data and traces.
-
ASPI: Seeking Ambiguity Clarification Amplifies Prompt Injection Vulnerability in LLM Agents
Clarification-seeking in LLM agents amplifies prompt injection attack success from ~2% to over 30% across ten frontier models in a new 728-scenario benchmark.
-
Towards Verifiable and Self-Correcting AI Physicists for Quantum Many-Body Simulations
QMP-Bench supplies a realistic test set for AI on quantum many-body problems while PhysVEC uses integrated verifiers to turn unreliable LLM generations into code that passes both syntax and physics checks, outperformi...
-
From Procedural Skills to Strategy Genes: Towards Experience-Driven Test-Time Evolution
Compact Gene representations of experience outperform documentation-oriented Skill packages for test-time control and iterative evolution in code-solving tasks, with measured gains on CritPt from 9.1% to 18.57% and 17...
Reference graph
Works this paper leans on
-
[1]
P. W. Anderson. More is different: broken symmetry and the nature of the hierarchical structure of science.Science, 177(4047):393–396, 1972
work page 1972
-
[2]
R. Sinatra, P. Deville, M. Szell, D. Wang, and A.-L. Barabási. A century of physics.Nature Physics, 11(10):791–796, 2015
work page 2015
-
[3]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polo- sukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[4]
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. pages, 4171–4186, 2019
work page 2019
- [5]
-
[6]
F. M. Delgado-Chaves, M. J. Jennings, A. Atalaia, J. Wolff, R. Horvath, Z. M. Mamdouh, J. Baumbach, and L. Baumbach. Transforming literature screening: The emerging role of large language models in systematic reviews.Proceedings of the National Academy of Sciences, 122(2): e2411962122, 2025
work page 2025
-
[7]
D. Scherbakov, N. Hubig, V . Jansari, A. Bakumenko, and L. A. Lenert. The emergence of large language models as tools in literature reviews: a large language model-assisted systematic review. Journal of the American Medical Informatics Association, 32(6):1071–1086, 2025
work page 2025
-
[8]
S. Pramanick, R. Chellappa, and S. Venugopalan. SPIQA: A dataset for multimodal question answering on scientific papers.Advances in Neural Information Processing Systems, 37:118807– 118833, 2024
work page 2024
-
[9]
T. Gao, H. Yen, J. Yu, and D. Chen. Enabling large language models to generate text with citations. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023
work page 2023
-
[10]
Y . Wang, Q. Guo, W. Yao, H. Zhang, X. Zhang, Z. Wu, M. Zhang, X. Dai, Q. Wen, W. Ye, et al. Autosurvey: Large Language Models can automatically write surveys.Advances in neural information processing systems, 37:115119–115145, 2024
work page 2024
- [11]
- [12]
-
[13]
H. Cui, Z. Shamsi, G. Cheon, X. Ma, S. Li, M. Tikhanovskaya, P. C. Norgaard, N. Mudur, M. B. Plomecka, P. Raccuglia, et al. CURIE: evaluating LLMs on multitask scientific long- context understanding and reasoning. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[14]
OpenAI. Introducing GPT-5, 2025. https://openai.com/index/introducing-gpt-5/
work page 2025
-
[15]
Introducing OpenAI o3 and o4-mini, 2025
OpenAI. Introducing OpenAI o3 and o4-mini, 2025. https://openai.com/index/introducing-o3- and-o4-mini/
work page 2025
-
[16]
Gemini 2.5: Our most intelligent AI model, 2025
Google. Gemini 2.5: Our most intelligent AI model, 2025. https://blog.google/technology/google- deepmind/gemini-model-thinking-updates-march-2025/#gemini-2-5-thinking
work page 2025
-
[17]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645(8081): 633–638, 2025
work page 2025
-
[18]
Anthropic. Introducing Claude 4, 2025. https://www.anthropic.com/news/claude-4. 24
work page 2025
-
[19]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation, 2025
Meta. The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation, 2025. https://ai.meta.com/blog/llama-4-multimodal-intelligence/
work page 2025
-
[21]
A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, et al. OpenAI o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. Gemini 2.5: Pushing the frontier with advanced rea- soning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al. Chain-of- thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[25]
T. Schick, J. Dwivedi-Yu, R. Dessí, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Can- cedda, and T. Scialom. Toolformer: language models can teach themselves to use tools. In Proceedings of the 37th International Conference on Neural Information Processing Systems, 2023
work page 2023
-
[26]
X. Wang, Y . Chen, L. Yuan, Y . Zhang, Y . Li, H. Peng, and H. Ji. Executable code actions elicit better LLM agents. InProceedings of the International Conference on Machine Learning, 2024
work page 2024
-
[27]
L. Yuan, Y . Chen, X. Wang, Y . Fung, H. Peng, and H. Ji. CRAFT: Customizing LLMs by creating and retrieving from specialized toolsets. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[28]
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, and D. Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InProceedings of the 34th International Conference on Neural Information Processing Systems, 2020
work page 2020
-
[29]
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[30]
C. V . Snell, J. Lee, K. Xu, and A. Kumar. Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
- [31]
- [32]
-
[33]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InThe Twelfth International Conference on Learning Representations, 2024. 25
work page 2024
-
[36]
Google DeepMind. Advanced version of Gemini with deep think officially achieves gold-medal standard at the International Mathematical Olympiad, 2025
work page 2025
-
[37]
Competitive programming with large reasoning models.arXiv preprint arXiv:2502.06807, 2025
A. El-Kishky, A. Wei, A. Saraiva, B. Minaiev, D. Selsam, D. Dohan, F. Song, H. Lightman, I. Clavera, J. Pachocki, et al. Competitive programming with large reasoning models.arXiv preprint arXiv:2502.06807, 2025
-
[38]
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
M. Balunovi´c, J. Dekoninck, I. Petrov, N. Jovanovi´c, and M. Vechev. MathArena: Evaluating llms on uncontaminated math competitions.arXiv preprint arXiv:2505.23281, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
C. He, R. Luo, Y . Bai, S. Hu, Z. Thai, J. Shen, J. Hu, X. Han, Y . Huang, Y . Zhang, et al. OlympiadBench: A challenging benchmark for promoting AGI with Olympiad-level bilingual multimodal scientific problems. pages, 3828–3850, 2024
work page 2024
-
[40]
N. Jain, K. Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica. LiveCodeBench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
- [41]
-
[42]
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
work page 2021
-
[43]
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Mea- suring massive multitask language understanding. InInternational Conference on Learning Representations, 2021
work page 2021
-
[44]
Y . Wang, X. Ma, G. Zhang, Y . Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, et al. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark. Advances in Neural Information Processing Systems, 37:95266–95290, 2024
work page 2024
-
[45]
X. Wang, Z. Hu, P. Lu, Y . Zhu, J. Zhang, S. Subramaniam, A. R. Loomba, S. Zhang, Y . Sun, and W. Wang. SciBench: Evaluating college-level scientific problem-solving abilities of large language models. pages, 50622–50649. PMLR, 2024
work page 2024
-
[46]
X. Xu, Q. Xu, T. Xiao, T. Chen, Y . Yan, J. ZHANG, S. Diao, C. Yang, and Y . Wang. UGPhysics: A comprehensive benchmark for undergraduate physics reasoning with large language models. In Forty-second International Conference on Machine Learning, 2025
work page 2025
-
[47]
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y . Pang, J. Dirani, J. Michael, and S. R. Bowman. GPQA: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
work page 2024
-
[48]
M. Tian, L. Gao, S. Zhang, X. Chen, C. Fan, X. Guo, R. Haas, P. Ji, K. Krongchon, Y . Li, et al. Scicode: A research coding benchmark curated by scientists.Advances in Neural Information Processing Systems, 37:30624–30650, 2024
work page 2024
-
[49]
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
E. Glazer, E. Erdil, T. Besiroglu, D. Chicharro, E. Chen, A. Gunning, C. F. Olsson, J.-S. Denain, A. Ho, E. d. O. Santos, et al. FrontierMath: a benchmark for evaluating advanced mathematical reasoning in AI.arXiv preprint arXiv:2411.04872, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [50]
-
[51]
L. Phan, A. Gatti, Z. Han, N. Li, J. Hu, H. Zhang, C. B. C. Zhang, M. Shaaban, J. Ling, S. Shi, et al. Humanity’s last exam.arXiv preprint arXiv:2501.14249, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
H. Wang, T. Fu, Y . Du, W. Gao, K. Huang, Z. Liu, P. Chandak, S. Liu, P. Van Katwyk, A. Deac, et al. Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023. 26
work page 2023
-
[53]
Z. Wu, L. Qiu, A. Ross, E. Akyürek, B. Chen, B. Wang, N. Kim, J. Andreas, and Y . Kim. Reasoning or reciting? exploring the capabilities and limitations of language models through counterfactual tasks. pages, 1819–1862, 2024
work page 2024
-
[54]
N. Balepur, A. Ravichander, and R. Rudinger. Artifacts or abduction: How do LLMs answer multiple-choice questions without the question? pages, 10308–10330, 2024
work page 2024
-
[55]
C. Deng, Y . Zhao, X. Tang, M. Gerstein, and A. Cohan. Investigating data contamination in modern benchmarks for large language models. pages, 8698–8711, 2024
work page 2024
-
[56]
S. Ott, A. Barbosa-Silva, K. Blagec, J. Brauner, and M. Samwald. Mapping global dynamics of benchmark creation and saturation in artificial intelligence.Nature Communications, 13(1):6793, 2022
work page 2022
-
[57]
Y . Li, Y . Guo, F. Guerin, and C. Lin. An open-source data contamination report for large language models. pages, 528–541, 2024
work page 2024
-
[58]
N. Balepur, R. Rudinger, and J. L. Boyd-Graber. Which of these best describes multiple choice evaluation with LLMs? A) forced B) flawed C) fixable D) all of the above. pages, 3394–3418. Association for Computational Linguistics, 2025
work page 2025
- [59]
-
[60]
S. Golchin and M. Surdeanu. Time travel in LLMs: Tracing data contamination in large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[61]
M. Roberts, H. Thakur, C. Herlihy, C. White, and S. Dooley. To the cutoff... and beyond? a longitudinal perspective on llm data contamination. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[62]
P. Wang, L. Li, L. Chen, Z. Cai, D. Zhu, B. Lin, Y . Cao, L. Kong, Q. Liu, T. Liu, et al. Large language models are not fair evaluators. pages, 9440–9450, 2024
work page 2024
-
[63]
J. Ye, Y . Wang, Y . Huang, D. Chen, Q. Zhang, N. Moniz, T. Gao, W. Geyer, C. Huang, P.-Y . Chen, et al. Justice or prejudice? quantifying biases in LLM-as-a-judge. InInternational Conference on Learning Representations, 2025
work page 2025
-
[64]
M. T. R. Laskar, S. Alqahtani, M. S. Bari, M. Rahman, M. A. M. Khan, H. Khan, I. Jahan, A. Bhuiyan, C. W. Tan, M. R. Parvez, E. Hoque, S. Joty, and J. Huang. A systematic survey and critical review on evaluating large language models: Challenges, limitations, and recommendations. pages, 13785–13816. Association for Computational Linguistics, 2024
work page 2024
- [65]
-
[66]
PhySH – Physics Subject Headings. https://physh.org/about. Accessed: August 18, 2025
work page 2025
-
[67]
A. T. Kalai, O. Nachum, S. S. Vempala, and E. Zhang. Why language models hallucinate.arXiv preprint arXiv:2509.04664, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Quantum fault tolerance in small experiments
D. Gottesman. Quantum fault tolerance in small experiments.arXiv preprint arXiv:1610.03507, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[69]
C. Vuillot. Is error detection helpful on IBM 5Q chips?Quantum Inf. Comput., 18(11):0949, 2017
work page 2017
-
[70]
N. M. Linke, M. Gutierrez, K. A. Landsman, C. Figgatt, S. Debnath, K. R. Brown, and C. Monroe. Fault-tolerant quantum error detection.Sci. Adv., 3(10):e1701074, 2017
work page 2017
-
[71]
R. Harper and S. T. Flammia. Fault-tolerant logical gates in the IBM quantum experience.Phys. Rev. Lett., 122:080504, 2019. 27
work page 2019
- [72]
-
[73]
Z. Zhang and Q. Zhuang. Distributed quantum sensing.Quantum Science and Technology, 6(4): 043001, 2021
work page 2021
- [74]
-
[75]
A. Zang, T.-X. Zheng, P. C. Maurer, F. T. Chong, M. Suchara, and T. Zhong. Enhancing noisy quantum sensing by GHZ state partitioning.arXiv preprint arXiv:2507.02829, 2025
-
[76]
A. H. Guth. Inflationary universe: A possible solution to the horizon and flatness problems.Phys. Rev. D, 23:347–356, 1981
work page 1981
-
[77]
A. Linde. A new inflationary universe scenario: A possible solution of the horizon, flatness, homogeneity, isotropy and primordial monopole problems.Physics Letters B, 108(6):389–393, 1982
work page 1982
-
[78]
A. Albrecht and P. J. Steinhardt. Cosmology for grand unified theories with radiatively induced symmetry breaking.Phys. Rev. Lett., 48:1220–1223, 1982
work page 1982
-
[79]
A. Linde. Chaotic inflation.Physics Letters B, 129(3):177–181, 1983
work page 1983
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.