The Signal is in the Steps: Local Scoring for Reasoning Data Selection
Pith reviewed 2026-05-18 10:11 UTC · model grok-4.3
The pith
Local step scoring selects better reasoning data than full-solution probability when teachers are diverse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
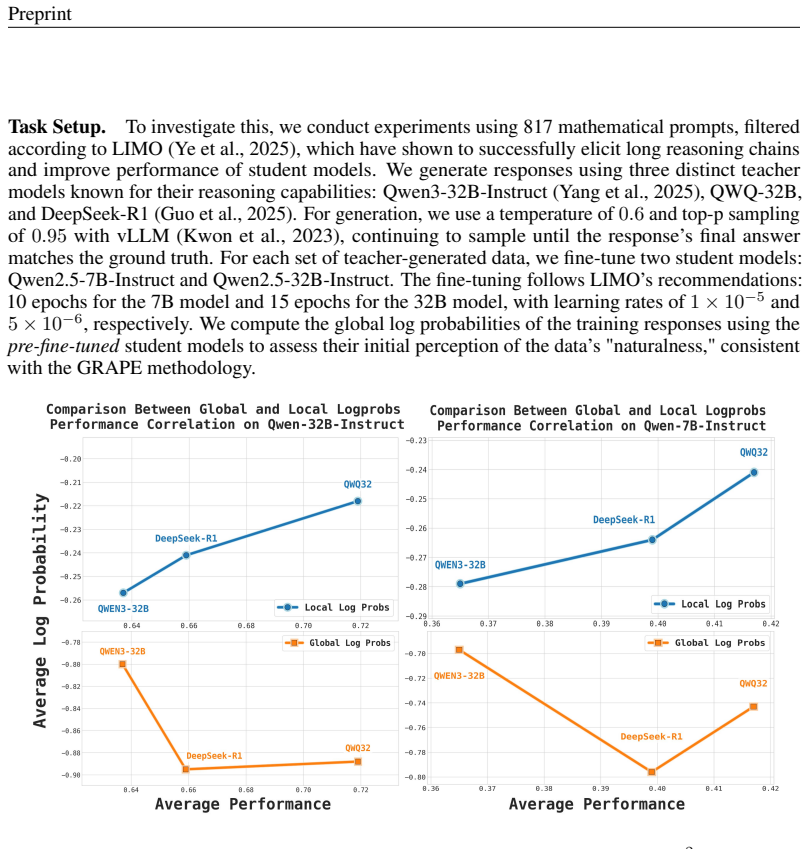
The central claim is that the transferable signal for reasoning lies in local step transitions, not global solution fluency. When candidate traces come from heterogeneous teachers, full-trajectory probability favors responses that look natural as wholes while ignoring whether the individual inferences are locally coherent to the student. LALP instead averages the log-probabilities of tokens inside each reasoning step conditioned on only a limited preceding window, thereby measuring whether each step follows from its immediate premises. This change in scoring target enables reliable teacher selection and data curation that improves downstream accuracy on reasoning tasks.
What carries the argument
Local Average Log Probability (LALP): scores each reasoning step by averaging token log-probabilities conditioned on a short preceding context window rather than the entire solution.
If this is right
- Selecting the single best teacher model before any fine-tuning becomes feasible and more accurate.
- Training data can be reliably curated from pools that mix outputs of many different teachers.
- Final student accuracy rises on math, coding, and science reasoning benchmarks when the locally most natural solutions are retained.
- The performance edge appears because local transitions, not whole-trace fluency, carry the recombineable signal.
Where Pith is reading between the lines
- The same local-window principle could be tested on other compositional tasks such as multi-step planning or code synthesis.
- Iterative filtering pipelines might repeatedly apply LALP to refine data quality over multiple rounds.
- If the local-window size is treated as a tunable hyperparameter, performance curves could reveal an optimal context length for different domains.
Load-bearing premise
Students generalize reasoning by recombining familiar local steps rather than by memorizing complete solutions.
What would settle it
If a student trained on data selected by global probability from a diverse teacher pool matches or exceeds the accuracy of one trained on LALP-selected data across the same math, coding, and science tasks, the claimed advantage of local scoring would be falsified.
Figures





read the original abstract
Distilling long-form reasoning from teacher models into smaller students requires selecting which candidate solutions to train on. Recent work argues that one should select responses the student model assigns highest probability, i.e., favoring solutions ``natural'' to the student. However, we find that this approach works within a single teacher but fails when scaling to long reasoning traces from multiple diverse teachers. We identify a key cause: this approach scores entire solutions, but students generalize by recombining familiar reasoning steps, not by memorizing complete solutions. Full-trajectory scoring optimizes the wrong target; it rewards global fluency while the transferable signal lies in local step transitions. We propose Local Average Log Probability (LALP), which scores each reasoning step using only a small window of preceding context, measuring whether each step is justified by its immediate premises rather than whether the full response looks natural to the student. LALP enables two practical use cases: selecting the best teacher before fine-tuning and curating training data from diverse teacher pools. Across math, coding, and science reasoning tasks, LALP consistently improves accuracy when selecting the most natural solutions by a large margin.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that global full-trajectory log-probability scoring for selecting reasoning traces works within a single teacher but fails across diverse teachers because students generalize by recombining local steps rather than memorizing complete solutions. It proposes Local Average Log Probability (LALP), which scores each step using only a small preceding context window to measure local justification, and demonstrates that this enables effective teacher selection before fine-tuning and curation of training data from mixed teacher pools, yielding consistent accuracy gains on math, coding, and science reasoning benchmarks.
Significance. If the results hold, the work offers a practical, student-model-native method for curating high-quality long-form reasoning data from heterogeneous sources, addressing a scalability bottleneck in distillation. By shifting focus from global fluency to local step transitions, it provides a new lens on what constitutes transferable signal in reasoning traces and supports two concrete use cases without requiring exhaustive fine-tuning trials for every candidate.
major comments (2)
- [Abstract] Abstract: The claim that global scoring fails because 'students generalize by recombining familiar reasoning steps, not by memorizing complete solutions' is load-bearing for preferring LALP, yet no analysis, ablation, or controlled test isolates recombination (e.g., step n-gram novelty, cross-teacher combination problems, or comparison of memorization-like behavior under global vs. local selection). Alternative accounts such as incidental preference for shorter steps therefore remain viable.
- [Abstract] Abstract / Experiments: The reported improvements are described only qualitatively ('consistently improves accuracy ... by a large margin') with no effect sizes, number of runs, baseline details, or statistical significance tests, which weakens assessment of whether the gains reliably support the local-vs-global distinction.
minor comments (1)
- [Method] The precise definition of the 'small window of preceding context' and the exact averaging procedure for LALP should be stated explicitly, including any hyperparameters and how they are chosen.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comments point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that global scoring fails because 'students generalize by recombining familiar reasoning steps, not by memorizing complete solutions' is load-bearing for preferring LALP, yet no analysis, ablation, or controlled test isolates recombination (e.g., step n-gram novelty, cross-teacher combination problems, or comparison of memorization-like behavior under global vs. local selection). Alternative accounts such as incidental preference for shorter steps therefore remain viable.
Authors: We appreciate this observation. The manuscript interprets the empirical gap—global scoring succeeding within a single teacher but failing across diverse teachers—as evidence that students benefit from recombining local steps rather than memorizing full trajectories. We acknowledge that the current version does not include direct ablations such as step n-gram novelty metrics or controlled comparisons of recombination versus memorization behavior. In the revision we will add an analysis of step novelty and cross-teacher step combinations in selected data to better isolate this mechanism and address alternatives such as step-length bias. revision: yes
-
Referee: [Abstract] Abstract / Experiments: The reported improvements are described only qualitatively ('consistently improves accuracy ... by a large margin') with no effect sizes, number of runs, baseline details, or statistical significance tests, which weakens assessment of whether the gains reliably support the local-vs-global distinction.
Authors: We agree that quantitative details are needed for rigorous evaluation. The current manuscript reports improvements qualitatively without effect sizes, run counts, full baseline specifications, or significance tests. We will revise the abstract and experimental sections to report absolute accuracy deltas with standard deviations across multiple runs, explicit baseline details, and statistical significance results to substantiate the local-versus-global comparison. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines LALP directly from the student model's local token probabilities over short context windows, an independent observable quantity. Reported gains are measured on downstream task accuracy on standard benchmarks rather than by construction from fitted inputs. No equations, self-citations, or uniqueness theorems are invoked in the provided text to create a definitional loop. The recombination assumption is stated as motivation but does not reduce the method or results to the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Students generalize reasoning by recombining familiar local steps rather than memorizing full trajectories.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
students generalize by recombining familiar reasoning steps, not by memorizing complete solutions. Full-trajectory scoring optimizes the wrong target; it rewards global fluency while the transferable signal lies in local step transitions.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce Local Naturalness, which scores a response by measuring the student’s log-probabilities over short, sequential reasoning steps (e.g., sentences) conditioned only on a small local window.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Fine-Tuning Small Reasoning Models for Quantum Field Theory
Small 7B reasoning models were fine-tuned on synthetic and curated QFT problems using RL and SFT, yielding performance gains, error analysis, and public release of data and traces.
-
On the Step Length Confounding in LLM Reasoning Data Selection
Average log probability selection for LLM reasoning datasets is confounded by step length because longer steps dilute low-probability first tokens; ASLEC-DROP and ASLEC-CASL remove this bias.
-
Which Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
Rank-Surprisal Ratio (RSR) correlates strongly (average Spearman 0.86) with post-distillation reasoning gains across five student models and trajectories from eleven teachers, outperforming existing selection metrics.
Reference graph
Works this paper leans on
-
[1]
Bie, T., Cao, M., Chen, K., Du, L., Gong, M., Gong, Z., Gu, Y ., Hu, J., Huang, Z., Lan, Z., et al
URLhttps://arxiv.org/abs/2505.00949. Sang Keun Choe, Hwijeen Ahn, Juhan Bae, Kewen Zhao, Minsoo Kang, Youngseog Chung, Adithya Pratapa, Willie Neiswanger, Emma Strubell, Teruko Mitamura, et al. What is your data worth to gpt? llm-scale data valuation with influence functions.arXiv preprint arXiv:2405.13954,
-
[2]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Cross-lingual knowledge distillation for answer sentence selection in low-resource languages
Shivanshu Gupta, Yoshitomo Matsubara, Ankit Chadha, and Alessandro Moschitti. Cross-lingual knowledge distillation for answer sentence selection in low-resource languages. InFindings of the Association for Computational Linguistics: ACL 2023, pp. 14078–14092,
work page 2023
-
[6]
Cheng-Yu Hsieh, Chun-Liang Li, Chih-kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Computational Linguistics: ACL 2023, pp. 8003–8017,
work page 2023
-
[7]
Efficiently learning at test-time: Active fine-tuning of llms.arXiv preprint arXiv:2410.08020,
Jonas Hübotter, Sascha Bongni, Ido Hakimi, and Andreas Krause. Efficiently learning at test-time: Active fine-tuning of llms.arXiv preprint arXiv:2410.08020,
-
[8]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning.arXiv preprint arXiv:2110.06169,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Small models struggle to learn from strong reasoners
Yuetai Li, Xiang Yue, Zhangchen Xu, Fengqing Jiang, Luyao Niu, Bill Yuchen Lin, Bhaskar Ramasubramanian, and Radha Poovendran. Small models struggle to learn from strong reasoners. arXiv preprint arXiv:2502.12143,
-
[11]
Token-wise curriculum learning for neural machine translation.arXiv preprint arXiv:2103.11088,
Chen Liang, Haoming Jiang, Xiaodong Liu, Pengcheng He, Weizhu Chen, Jianfeng Gao, and Tuo Zhao. Token-wise curriculum learning for neural machine translation.arXiv preprint arXiv:2103.11088,
-
[12]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.arXiv preprint arXiv:2307.03172,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Zihan Liu, Zhuolin Yang, Yang Chen, Chankyu Lee, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Acereason-nemotron 1.1: Advancing math and code reasoning through sft and rl synergy. arXiv preprint arXiv:2506.13284,
-
[14]
Exploiting curriculum learning in unsupervised neural machine translation
Jinliang Lu and Jiajun Zhang. Exploiting curriculum learning in unsupervised neural machine translation. InFindings of the Association for Computational Linguistics: EMNLP 2021, pp. 924–934,
work page 2021
-
[15]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling.arXiv preprint arXiv:2501.19393,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Cycle-instruct: Fully seed- free instruction tuning via dual self-training and cycle consistency
Zhanming Shen, Zeyu Qin, Zenan Huang, Hao Chen, Jiaqi Hu, Yihong Zhuang, Guoshan Lu, Gang Chen, and Junbo Zhao. Merge-of-thought distillation.arXiv preprint arXiv:2509.08814,
-
[17]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Sky-t1: Train your own o1 preview model within $450
NovaSky Team. Sky-t1: Train your own o1 preview model within $450. https://novasky- ai.github.io/posts/sky-t1, 2025a. Accessed: 2025-01-09. OpenThoughts Team. Open Thoughts. https://open-thoughts.ai, January 2025b. Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, March 2025c. URL https://qwenlm.github.io/blog/qwq-32b/. Jason Wei, Xuezhi ...
work page 2025
-
[19]
Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, et al. Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond. arXiv preprint arXiv:2503.10460,
-
[20]
Yang Xiao, Jiashuo Wang, Ruifeng Yuan, Chunpu Xu, Kaishuai Xu, Wenjie Li, and Pengfei Liu. Limopro: Reasoning refinement for efficient and effective test-time scaling.arXiv preprint arXiv:2505.19187,
-
[21]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
URLhttps://arxiv.org/abs/2505.09388. 13 Preprint Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu. Limo: Less is more for reasoning. InSecond Conference on Language Modeling,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
URL https://openreview. net/forum?id=LH2ZKviJoI. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl- zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
The best instruction-tuning data are those that fit.arXiv preprint arXiv:2502.04194,
Dylan Zhang, Qirun Dai, and Hao Peng. The best instruction-tuning data are those that fit.arXiv preprint arXiv:2502.04194,
-
[26]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Association for Computational Linguistics. URLhttp://arxiv.org/abs/2403.13372. 14 Preprint A ADDITIONALDETAILS To ensure clarity and facilitate reproducibility, this section outlines the datasets used for training and evaluation, the student model and teacher model architectures, and the hyperparameters used during our supervised fine-tuning process. A.1 ...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
(500 Samples) URL: https://huggingface.co/datasets/EleutherAI/hendrycks_ math • AIME 2025 (American Invitational Mathematics Examination) (30 Samples) URL:https://huggingface.co/datasets/opencompass/AIME2025 • AMC 2023(American Mathematics Competition) (40 Samples) URL:https://huggingface.co/datasets/math-ai/amc23 • MINERV A (Lewkowycz et al.,
work page 2025
-
[28]
Property Value Number of samples 1/16 Temperature 0.0/1.0 Top P 1.0/0.95 Top K 1/40 Max Tokens 42786+ Table 4: The hyperparameters for sampling from the teacher models using vLLM (Kwon et al., 2023). Training Hyperparameters.For supervised fine-tuning on student models, we leverage the LLaMA-Factory (Zheng et al.,
work page 2023
-
[29]
platform that offers efficient training and apply the following setting of hyperparameters (listed in Table 5): Property Value Train Batch Size Per Device 1/2 Gradient Accumulation Steps 8 Learning Rate5.0×10 −6/1.0×10 −5 Epochs 10/15 Warmup Ratio 0.0 BFloat16 True Table 5: The hyperparameters for SFT the student models using LLaMA Factory (Zheng et al., ...
work page 2024
-
[30]
The evaluation is conducted using the hyperparameter settings from DeepSeek-R1 Guo et al
based on the Qwen2.5-Math evaluation code (Yang et al., 2024b) (available at https://github.com/GAIR-NLP/LIMO/tree/main/eval). The evaluation is conducted using the hyperparameter settings from DeepSeek-R1 Guo et al. (2025) as detailed in Table
work page 2025
-
[31]
MATH AIME25 AMC MINERV A KAOYAN OLYMPIAD CN_MATH24 A VG GPQA Student: Qwen2.5-32B-Instruct Original Model0.824 0.133 0.700 0.298 0.422 0.471 0.233 0.445 0.551 Global Highest0.876 0.433 0.825 0.331 0.592 0.636 0.733 0.632 0.611LIMO-32B0.896 0.433 0.925 0.346 0.618 0.630 0.800 0.664 0.626Sky-T1-32B-Preview0.876 0.200 0.750 0.301 0.558 0.507 0.533 0.532 0.56...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.