Tiny but Mighty: A Software-Hardware Co-Design Approach for Efficient Multimodal Inference on Battery-Powered Small Devices
Pith reviewed 2026-05-18 13:22 UTC · model grok-4.3
The pith
Nanomind splits large multimodal models into modular bricks mapped to optimal accelerators on small devices, cutting energy use by 42.3 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
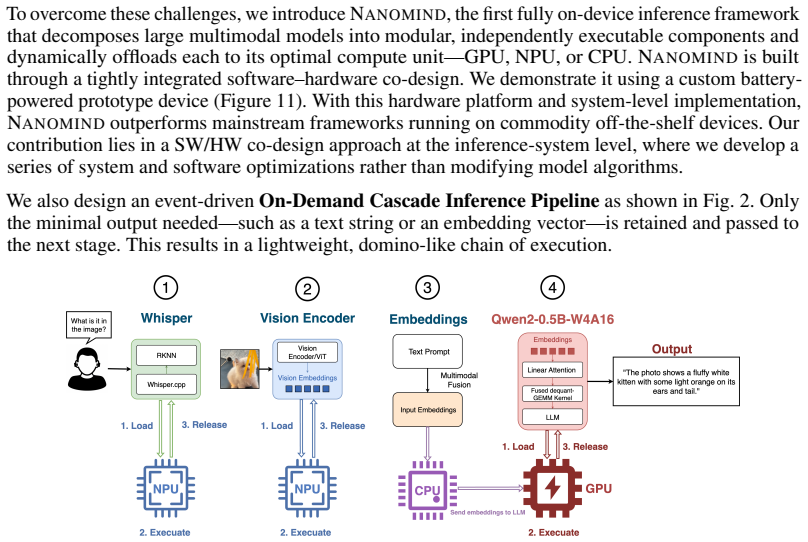
Nanomind is a hardware-software co-design inference framework that decomposes each LMM into modular bricks—vision, projector, language, and audio—and maps each brick to its best-suited compute units. A Token-Aware Buffer Manager enables zero-copy embedding transfer across accelerators on unified-memory SoCs, bypassing CPU bottlenecks. Combined with customized hardware, a battery-aware scheduler, and fused low-bit GEMM kernels, Nanomind runs entirely on a compact, battery-powered prototype that operates fully offline.
What carries the argument
Modular bricks decomposition of LMMs paired with the Token-Aware Buffer Manager (TABM) for zero-copy transfers between heterogeneous accelerators on unified-memory SoCs.
If this is right
- Multimodal inference becomes feasible for many hours on devices limited to small batteries without cloud support.
- Heterogeneous accelerators on modern SoCs can be fully utilized instead of underused by monolithic execution.
- On-demand low-power modes allow continuous camera-based applications while preserving battery life.
- Fused low-bit kernels and schedulers further reduce power draw for offline operation.
Where Pith is reading between the lines
- The brick-mapping idea may apply to other staged AI pipelines that separate perception from reasoning.
- Zero-copy buffer techniques could be tested on additional memory architectures to check broader compatibility.
- Extended runtime on portable hardware suggests new designs for always-available multimodal sensors in constrained environments.
Load-bearing premise
The measured energy reductions and long battery runtime depend on the specific unified-memory SoC prototype and the size of the tested multimodal model.
What would settle it
Repeating the energy and runtime measurements on a different SoC or with a larger multimodal model to determine whether the 42.3 percent savings and 18.8-hour operation persist.
Figures












read the original abstract
Large Multimodal Models (LMMs) are inherently modular, comprising vision and audio encoders, a projector, and a language backbone. Yet existing systems execute them monolithically, underutilizing the heterogeneous accelerators (NPUs, GPUs, DSPs) on modern SoCs and inflating end-to-end latency. We present Nanomind, a hardware-software co-design inference framework that decomposes each LMM into modular "bricks"--vision, projector, language, and audio--and maps each brick to its best-suited compute units. A Token-Aware Buffer Manager (TABM) enables zero-copy embedding transfer across accelerators on unified-memory SoCs, bypassing CPU bottlenecks. Combined with customized hardware, a battery-aware scheduler, and fused low-bit GEMM kernels, Nanomind runs entirely on a compact, battery-powered prototype that operates fully offline. Nanomind reduces end-to-end energy by 42.3% against mainstream edge frameworks and devkits; in its on-demand low-power mode, the prototype runs LLaVA-OneVision-Qwen2-0.5B with a camera for nearly 18.8 hours on a single 2,000 mAh battery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Nanomind, a software-hardware co-design framework for efficient multimodal inference on battery-powered small devices. It decomposes LMMs into modular bricks (vision, projector, language, audio) mapped to heterogeneous accelerators (NPUs, GPUs, DSPs) on unified-memory SoCs, introduces a Token-Aware Buffer Manager (TABM) for zero-copy embedding transfers, and adds a battery-aware scheduler plus fused low-bit GEMM kernels. On a custom prototype, it reports 42.3% end-to-end energy reduction versus mainstream edge frameworks and nearly 18.8 hours of runtime for LLaVA-OneVision-Qwen2-0.5B with camera input on a 2,000 mAh battery in on-demand low-power mode.
Significance. If the attribution of gains holds, the work would be significant for edge AI and mobile systems by showing how modular decomposition and unified-memory optimizations can extend battery life for multimodal models on compact, offline hardware. The physical prototype results provide practical evidence that could inform future co-designs for resource-constrained devices.
major comments (2)
- Abstract and Evaluation section: The 42.3% energy reduction and 18.8-hour battery-life figures are obtained exclusively on a custom unified-memory SoC prototype that incorporates customized hardware and fused low-bit GEMM kernels. Without ablations on commodity devkits (e.g., Jetson Orin) or measurements isolating the brick mapping and TABM contributions from the underlying silicon, it is not possible to substantiate that the co-design itself delivers the reported savings.
- Evaluation section: All quantitative results use only the 0.5B Qwen2-based model. The absence of results for larger LMMs leaves open whether the same mapping strategy and TABM yield comparable efficiency on models with higher compute or memory demands.
minor comments (1)
- The abstract refers to comparisons against 'mainstream edge frameworks and devkits' without naming the exact baselines or their configurations in the provided text; these details should be explicit in the evaluation for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating planned revisions where appropriate to strengthen the presentation of our results.
read point-by-point responses
-
Referee: Abstract and Evaluation section: The 42.3% energy reduction and 18.8-hour battery-life figures are obtained exclusively on a custom unified-memory SoC prototype that incorporates customized hardware and fused low-bit GEMM kernels. Without ablations on commodity devkits (e.g., Jetson Orin) or measurements isolating the brick mapping and TABM contributions from the underlying silicon, it is not possible to substantiate that the co-design itself delivers the reported savings.
Authors: We acknowledge that the reported energy savings and battery life are measured on our custom unified-memory SoC prototype, which forms an integral part of the co-design by providing the specific heterogeneous accelerators and unified memory architecture that TABM exploits for zero-copy transfers. Baseline comparisons were performed by adapting mainstream frameworks to run on the same prototype hardware. To address the request for better isolation of contributions, we will add a dedicated ablation subsection in the revised Evaluation section. This will report microbenchmark results on the prototype for: (i) full Nanomind versus execution without TABM, (ii) modular brick mapping versus monolithic execution of the LMM, and (iii) with versus without the battery-aware scheduler. We will also add a short discussion on portability, explaining architectural differences with platforms such as Jetson Orin while noting that the core software techniques (brick decomposition and TABM) are not tied to the custom silicon. These changes will make the attribution of gains clearer without requiring entirely new hardware platforms. revision: partial
-
Referee: Evaluation section: All quantitative results use only the 0.5B Qwen2-based model. The absence of results for larger LMMs leaves open whether the same mapping strategy and TABM yield comparable efficiency on models with higher compute or memory demands.
Authors: The 0.5B model was chosen because it is representative of LMMs that can realistically run on battery-powered small devices with acceptable latency and energy budgets; larger models (e.g., 7B+) typically exceed the memory and sustained compute capacity of such platforms for continuous operation. The modular brick decomposition and TABM are designed to be model-size agnostic, with benefits expected to increase for larger models due to greater opportunities for accelerator specialization and reduced data movement. In the revised manuscript we will add a paragraph in the Evaluation or Discussion section that provides a qualitative scalability analysis, including projected efficiency trends and potential bottlenecks for larger LMMs based on the same mapping principles. This addition will address generalizability while preserving the paper's focus on resource-constrained devices. revision: partial
Circularity Check
No circularity: empirical measurements on physical prototype
full rationale
The paper presents Nanomind as a hardware-software co-design system that decomposes LMMs into bricks and maps them to heterogeneous accelerators on a custom unified-memory SoC prototype, with TABM for zero-copy transfers and fused kernels. All headline results (42.3% energy reduction, 18.8 h battery life) are obtained via direct physical measurements and comparisons against mainstream edge frameworks on the same prototype hardware. No algebraic derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the evaluation chain is self-contained against external benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Battery capacity (2000 mAh)
axioms (1)
- domain assumption The prototype SoC provides unified memory accessible by NPU, GPU, and DSP without CPU copies.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We decompose models into vision, fusion, and decoding modules and schedule each to the most suitable accelerator under UMA... Token-Aware Buffer Manager (TABM) enables zero-copy embedding transfer
-
IndisputableMonolith/Foundation/Atomicity.leanatomic_tick unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On-Demand Cascade Inference... load→execute→release workflow
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Tempus: A Temporally Scalable Resource-Invariant GEMM Streaming Framework for Versal AI Edge
Tempus delivers 607 GOPS at 10.677 W using fixed 16 AIE cores on Versal AI Edge, with 211.2x better platform-aware utility than spatial SOTA ARIES and zero URAM/DSP utilization.
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, et al. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone.arXiv preprint arXiv:2404.14219,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
doi: 10.1109/ tpami.2021.3087709
ISSN 1939-3539. doi: 10.1109/ tpami.2021.3087709. URL http://dx.doi.org/10.1109/TPAMI.2021.3087709. Tim Dettmers and Luke Zettlemoyer. The case for 4-bit precision: k-bit Inference Scaling Laws,
-
[5]
RK3588 - Reverse engineering the RKNN (Rockchip Neural Processing Unit)
Tiny Devices. RK3588 - Reverse engineering the RKNN (Rockchip Neural Processing Unit). http://jas-hacks.blogspot.com/2024/02/rk3588-reverse-engineering-rknn.html. Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models
work page 2024
-
[6]
URL https://arxiv.org/abs/2407.21783. Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate Post-training Compression for Generative Pretrained Transformers.arXiv preprint arXiv:2210.17323,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
URL https://arxiv.org/abs/2306.13394. Georgi Gerganov. llama.cpp. https://github.com/ggerganov/llama.cpp, 2023a. Georgi Gerganov. whisper.cpp. https://github.com/ggml-org/whisper.cpp, 2023b. Jesse Gross. Ollama. https://github.com/jessegross/ollama,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Bo Hui, Haolin Yuan, Neil Gong, Philippe Burlina, and Yinzhi Cao
Accessed: 2025-09-24. Bo Hui, Haolin Yuan, Neil Gong, Philippe Burlina, and Yinzhi Cao. PLeak: Prompt Leaking Attacks against Large Language Model Applications. InIn Proc. of ACM CCS 2024, CCS ’24,
work page 2025
-
[9]
LLaVA-OneVision: Easy Visual Task Transfer
URL https://arxiv.org/abs/2408.03326. Yilong Li, Jingyu Liu, Hao Zhang, M Badri Narayanan, Utkarsh Sharma, Shuai Zhang, Yijing Zeng, Jayaram Raghuram, and Suman Banerjee. PALMBENCH: A COMPREHENSIVE BENCHMARK OF COMPRESSED LARGE LANGUAGE MODELS ON MOBILE PLATFORMS. InThe Thirteenth International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee
Accessed: 2025-09-24. Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2023a. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023b. Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and w...
work page 2025
-
[11]
SmolVLM: Redefining small and efficient multimodal models
Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Vaibhav Srivastav, Joshua Lochner, Hugo Larcher, Mathieu Morlon, Lewis Tunstall, Leandro von Werra, and Thomas Wolf. SmolVLM: Redefining small and efficient multimodal models.arXiv preprint arXiv:2504.05299,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
doi: 10.1109/W ACV48630.2021.00225. Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and C. V . Jawahar. InfographicVQA. In2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV),
work page doi:10.1109/w 2021
-
[13]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. InIn Proc. of ICML 2021,
work page 2021
- [14]
-
[15]
URL https://arxiv.org/abs/2503.19786. MLC team. Machine Learning Compilation (MLC)). https://llm.mlc.ai/docs/, 2023a. MLC team. MLC-LLM Github Repo. https://github.com/mlc-ai/mlc-llm, 2023b. MSOON Technology. High voltage power monitor. https://www.msoon.com/high-voltage-power- monitor,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Hongyu Wang, Shuming Ma, and Furu Wei
Accessed: 2025-09-25. Hongyu Wang, Shuming Ma, and Furu Wei. BitNet a4.8: 4-bit Activations for 1-bit LLMs.arXiv preprint arXiv:2411.04965, 2024a. Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zh...
-
[17]
Luis Wiedmann, Aritra Roy Gosthipaty, and Andrés Marafioti
URL https://arxiv.org/abs/2407.00088. Luis Wiedmann, Aritra Roy Gosthipaty, and Andrés Marafioti. nanoVLM. https://github.com/ huggingface/nanoVLM,
-
[18]
Although later adapted for edge devices, they inherit assumptions from these architectures
A APPENDIX A.1LLAMA.CPP LAYER OFFLOADING MECHANISM Most of the open-source frameworks—such as llama.cpp—were designed for desktops and servers with separate CPU–GPU memory, requiring repeated parameter copies from DRAM to GPU memory. Although later adapted for edge devices, they inherit assumptions from these architectures. Modern mobile SoCs use unified ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.