Recognition: unknown
Tempus: A Temporally Scalable Resource-Invariant GEMM Streaming Framework for Versal AI Edge
Pith reviewed 2026-05-09 19:05 UTC · model grok-4.3
The pith
Tempus scales GEMM workloads temporally with a fixed set of 16 cores to achieve high efficiency on resource-constrained edge devices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Tempus achieves a 211.2x higher prominence factor than leading spatial methods by using a fixed compute block of 16 cores, iterative graph execution, and algorithmic data tiling and replication, while maintaining zero utilization of certain memory and processing resources and providing 22.0x core frugality, 7.1x power frugality, and 6.3x I/O reduction.
What carries the argument
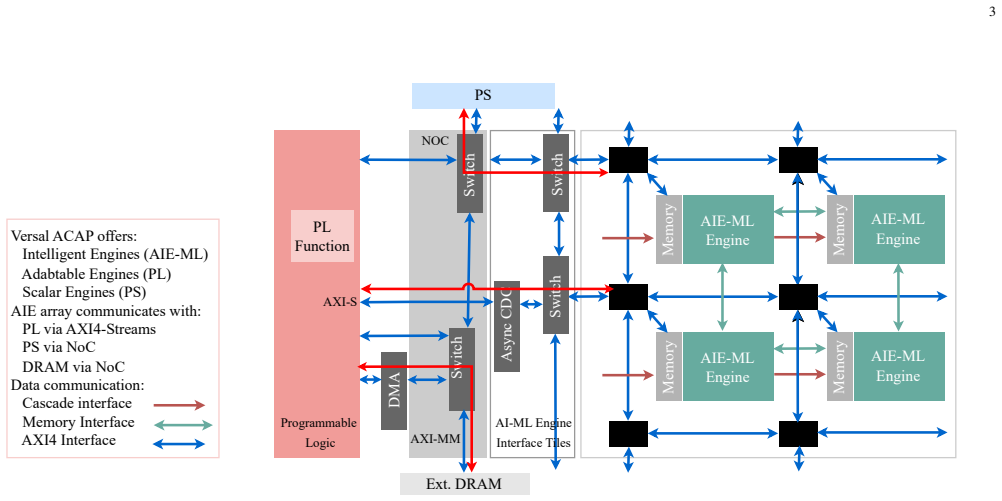
A fixed compute block of 16 specialized cores with high-speed cascade streaming for partial sum reduction and a deadlock-free dataflow protocol to maximize overlap.
If this is right
- Delivers 607 GOPS performance at 10.677 W total on-chip power.
- Maintains 0.00% utilization of URAM and DSP resources.
- Achieves 211.2 times higher platform-aware utility prominence than spatial state-of-the-art.
- Reduces core usage by 22 times, power by 7.1 times, and I/O demand by 6.3 times compared to alternatives.
Where Pith is reading between the lines
- This method could support running larger language models on edge devices by minimizing resource consumption.
- The temporal approach might generalize to other matrix-heavy computations beyond GEMM in AI workloads.
- Further gains could come from combining it with model compression techniques on the same hardware.
- Validation on a range of matrix dimensions would confirm if scalability holds without saturation.
Load-bearing premise
A fixed compute block of 16 cores with data tiling and replication achieves scalability for arbitrary GEMM sizes without bandwidth saturation or failures on edge systems.
What would settle it
Observing whether performance and frugality metrics hold as GEMM matrix dimensions increase significantly or if the implementation encounters physical resource or bandwidth limits on the target device.
Figures


read the original abstract
Scaling laws for Large Language Models (LLMs) establish that model quality improves with computational scale, yet edge deployment imposes strict constraints on compute, memory, and power. Since General Matrix Multiplication (GEMM) accounts for up to 90% of inference time, efficient GEMM acceleration is critical for edge AI. The Adaptive Intelligent Engines available in the AMD Versal adaptive SoCs are well suited for this task, but existing state-of-the-art (SOTA) frameworks maximize performance through spatial scaling, distributing workloads across hundreds of cores -- an approach that fails on resource-limited edge SoCs due to physical implementation failures, bandwidth saturation, and excessive resource consumption. We propose Tempus, a Resource-Invariant Temporal GEMM framework for the AMD Versal AI Edge SoC. Rather than expanding hardware resources with matrix size, Tempus employs a fixed compute block of 16 AIE-ML cores, achieving scalability through iterative graph execution and algorithmic data tiling and replication in the Programmable Logic. High-speed cascade streaming ensures low-latency partial sum reduction at Initiation Interval (II) of 1, while a deadlock-free DATAFLOW protocol maximizes transfer-compute overlap and PLIO reuse. Evaluated on GEMM workloads, Tempus achieves 607 GOPS at 10.677 W total on-chip power. By characterizing system-level efficiency through the Platform-Aware Utility (PAU) metric, we prove that Tempus achieves a 211.2x higher prominence factor than the leading spatial SOTA (ARIES). Furthermore, the framework maintains a 0.00% utilization of URAM/DSP, yielding 22.0x core frugality, 7.1x power frugality, and a 6.3x reduction in I/O demand, establishing a sustainable, scalable foundation for edge LLM inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Tempus, a temporally scalable, resource-invariant GEMM streaming framework targeting the AMD Versal AI Edge SoC. It employs a fixed compute block of 16 AIE-ML cores with algorithmic data tiling and replication in the Programmable Logic (PL), high-speed cascade streaming at initiation interval (II) of 1, and a deadlock-free DATAFLOW protocol for transfer-compute overlap. The framework reports 607 GOPS at 10.677 W total on-chip power with 0% URAM/DSP utilization. Using the newly introduced Platform-Aware Utility (PAU) metric, it claims a 211.2x higher prominence factor than the spatial SOTA ARIES, plus 22.0x core frugality, 7.1x power frugality, and 6.3x I/O demand reduction, positioning it as a sustainable foundation for edge LLM inference.
Significance. If the PAU-based superiority and resource-invariant scalability hold under independent scrutiny, the work offers a viable alternative to spatial scaling approaches that often fail on resource-limited edge devices. The concrete performance point (607 GOPS / 10.677 W) and emphasis on frugality metrics could inform practical edge AI deployments, particularly where URAM/DSP constraints are binding. However, the reliance on a custom metric and single-point results limits immediate impact without further validation.
major comments (3)
- Abstract and evaluation section: The central claim of a 211.2x higher prominence factor rests on the Platform-Aware Utility (PAU) metric introduced by the authors. The manuscript must supply the exact mathematical definition of PAU (including how 'prominence factor' is computed), the raw measurements from both Tempus and ARIES, and any equations used to derive the 211.2x ratio. Without this, the result is at risk of circularity since superiority is defined solely in terms of the new metric.
- Scalability discussion (likely §4 or §5): The claim of arbitrary-GEMM scalability with a fixed 16 AIE-ML core block plus PL tiling/replication is load-bearing but unsupported by evidence of constant bandwidth utilization or I/O demand as matrix dimensions increase. The manuscript should include bandwidth utilization curves, tile-transfer volume analysis, or performance data across a range of MxNxK sizes to demonstrate absence of PLIO saturation or implementation failures on the target device.
- Abstract and results: All reported factors (607 GOPS, 10.677 W, 22.0x core frugality, 7.1x power frugality, 6.3x I/O reduction) are presented as single-point values. The paper must specify the exact workload dimensions, number of independent runs, measurement methodology, and statistical validation (e.g., standard deviation) to allow reproducibility and to substantiate the cross-framework comparisons.
minor comments (3)
- Abstract: The phrasing 'we prove' is used for an empirical result; rephrase to 'we demonstrate' or 'we show' for precision.
- Throughout: Ensure first-use definitions for all acronyms (AIE-ML, PLIO, DATAFLOW, PAU) and consistent notation for matrix dimensions.
- Evaluation section: Add a side-by-side table of raw metrics (GOPS, power, resource utilization) for Tempus versus ARIES to facilitate direct comparison independent of PAU.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to improve clarity, provide supporting evidence, and enhance reproducibility.
read point-by-point responses
-
Referee: Abstract and evaluation section: The central claim of a 211.2x higher prominence factor rests on the Platform-Aware Utility (PAU) metric introduced by the authors. The manuscript must supply the exact mathematical definition of PAU (including how 'prominence factor' is computed), the raw measurements from both Tempus and ARIES, and any equations used to derive the 211.2x ratio. Without this, the result is at risk of circularity since superiority is defined solely in terms of the new metric.
Authors: We agree that the PAU metric requires an explicit mathematical definition and transparent derivation to substantiate the prominence factor claim. The manuscript introduces PAU as a platform-aware efficiency metric but we acknowledge the need for greater formality. In the revised manuscript we will add a dedicated subsection that states the exact formula for PAU, defines the prominence factor computation, presents a table of raw measurements (performance, power, resource utilization, and I/O demand) for both Tempus and ARIES under identical conditions, and shows the step-by-step equations leading to the 211.2x ratio. This will ground the comparison in verifiable data and remove any appearance of circularity. revision: yes
-
Referee: Scalability discussion (likely §4 or §5): The claim of arbitrary-GEMM scalability with a fixed 16 AIE-ML core block plus PL tiling/replication is load-bearing but unsupported by evidence of constant bandwidth utilization or I/O demand as matrix dimensions increase. The manuscript should include bandwidth utilization curves, tile-transfer volume analysis, or performance data across a range of MxNxK sizes to demonstrate absence of PLIO saturation or implementation failures on the target device.
Authors: The referee correctly notes that empirical validation of resource-invariant scalability strengthens the central claim. While the framework architecture is designed to keep I/O demand bounded through fixed-core temporal execution and PL replication, the manuscript would benefit from explicit supporting data. We will revise the scalability section to include bandwidth utilization curves versus matrix size, tile-transfer volume analysis, and performance results across multiple MxNxK configurations. These additions will demonstrate that PLIO utilization remains below saturation and that I/O demand does not grow with problem size, thereby supporting the arbitrary-GEMM scalability assertion within the target device constraints. revision: yes
-
Referee: Abstract and results: All reported factors (607 GOPS, 10.677 W, 22.0x core frugality, 7.1x power frugality, 6.3x I/O reduction) are presented as single-point values. The paper must specify the exact workload dimensions, number of independent runs, measurement methodology, and statistical validation (e.g., standard deviation) to allow reproducibility and to substantiate the cross-framework comparisons.
Authors: We accept the need for explicit experimental details to support reproducibility. In the revised abstract and results section we will state the precise GEMM workload dimensions used for each reported metric, describe the measurement methodology (including tools, power estimation method, and performance counters), indicate the number of independent runs performed, and report statistical measures such as standard deviation. The same workload will be used for all cross-framework comparisons, with any normalization steps clearly documented. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper reports concrete measured results (607 GOPS at 10.677 W total on-chip power, 0.00% URAM/DSP utilization) obtained from a fixed 16-core AIE-ML block plus PL tiling. The PAU metric is introduced as a new characterization tool to compute a prominence-factor comparison (211.2x vs ARIES), but the provided text contains no equations, definitions, or self-citation chains that reduce this comparison to a tautology or fitted input by construction. Scalability is asserted via algorithmic design choices (iterative execution, cascade streaming at II=1, deadlock-free DATAFLOW) rather than derived from first principles that loop back to the same assumptions. No load-bearing step matches any enumerated circularity pattern; the central claims rest on empirical evaluation rather than self-referential redefinition.
Axiom & Free-Parameter Ledger
free parameters (1)
- Fixed AIE-ML core block size =
16
axioms (1)
- domain assumption GEMM accounts for up to 90% of inference time in LLMs
invented entities (1)
-
Platform-Aware Utility (PAU) metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. Casas, L. A. Hendricks, J. Welbl, A. Clarket al., “Training compute-optimal large language models,”arXiv preprint arXiv:2203.15556, vol. 10, 2022
work page internal anchor Pith review arXiv 2022
-
[2]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[3]
Reconciling kaplan and chinchilla scaling laws,
T. Pearce and J. Song, “Reconciling kaplan and chinchilla scaling laws,” arXiv preprint arXiv:2406.12907, 2024
-
[4]
Slim: A hetero- geneous accelerator for edge inference of sparse large language model via adaptive thresholding,
W. Xu, H. Choi, P.-k. Hsu, S. Yu, and T. Simunic, “Slim: A hetero- geneous accelerator for edge inference of sparse large language model via adaptive thresholding,”ACM Transactions on Embedded Computing Systems, 2025
2025
-
[5]
F. Jiang, C. Pan, L. Dong, K. Wang, M. Debbah, D. Niyato, and Z. Han, “A comprehensive survey of large ai models for future com- munications: Foundations, applications and challenges,”arXiv preprint arXiv:2505.03556, 2025
-
[6]
A survey: Collaborative hardware and software design in the era of large language models,
C. Guo, F. Cheng, Z. Du, J. Kiessling, J. Ku, S. Li, Z. Li, M. Ma, T. Molom-Ochir, B. Morriset al., “A survey: Collaborative hardware and software design in the era of large language models,”IEEE Circuits and Systems Magazine, vol. 25, no. 1, pp. 35–57, 2025
2025
-
[7]
Y . Li, S. Zhang, Y . Zeng, H. Zhang, X. Xiong, J. Liu, P. Hu, and S. Banerjee, “Tiny but mighty: A software-hardware co-design approach for efficient multimodal inference on battery-powered small devices,” arXiv preprint arXiv:2510.05109, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Sgrace: scalable architecture for on-device inference and training of graph attention and convolutional networks,
J. Nunez-Yanez and H. M. Jeddi, “Sgrace: scalable architecture for on-device inference and training of graph attention and convolutional networks,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2025
2025
-
[9]
Heterogeneous edge computing for molecular property prediction with graph convolutional networks,
M. Grailoo and J. Nunez-Yanez, “Heterogeneous edge computing for molecular property prediction with graph convolutional networks,”Elec- tronics, vol. 14, no. 1, p. 101, 2024
2024
-
[10]
Charm 2.0: Composing heterogeneous accelerators for deep learning on versal acap architecture,
J. Zhuang, J. Lau, H. Ye, Z. Yang, S. Ji, J. Lo, K. Denolf, S. Neuen- dorffer, A. Jones, J. Hu, Y . Shi, D. Chen, J. Cong, and P. Zhou, “Charm 2.0: Composing heterogeneous accelerators for deep learning on versal acap architecture,”ACM Transactions on Reconfigurable Technology and Systems, vol. 17, Sep 2024
2024
-
[11]
Aries: An agile mlir-based compilation flow for reconfigurable devices with ai engines,
J. Zhuang, S. Xiang, H. Chen, N. Zhang, Z. Yang, T. Mao, Z. Zhang, and P. Zhou, “Aries: An agile mlir-based compilation flow for reconfigurable devices with ai engines,” inProceedings of the 2025 ACM/SIGDA International Symposium on Field Programmable Gate Arrays (FPGA ’25), ser. FPGA ’25. Association for Computing Machinery, 2025, pp. 92–102
2025
-
[12]
Accelerator design with decou- pled hardware customizations: benefits and challenges,
D. Pal, Y .-H. Lai, S. Xiang, N. Zhang, H. Chen, J. Casas, P. Cocchini, Z. Yang, J. Yang, L.-N. Pouchetet al., “Accelerator design with decou- pled hardware customizations: benefits and challenges,” inProceedings 11 of the 59th ACM/IEEE Design Automation Conference (DAC). ACM, 2022, pp. 1351–1354
2022
-
[13]
Charm: Composing heterogeneous accelerators for matrix multiply on versal acap architec- ture,
J. Zhuang, J. Lau, H. Ye, Z. Yang, Y . Du, J. Lo, K. Denolf, S. Neuendorf- fer, A. Jones, J. Hu, D. Chen, J. Cong, and P. Zhou, “Charm: Composing heterogeneous accelerators for matrix multiply on versal acap architec- ture,” inProceedings of the 2023 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, 2023
2023
-
[14]
Autosa: A polyhedral compiler for high-performance systolic arrays on fpga,
J. Wang, L. Guo, and J. Cong, “Autosa: A polyhedral compiler for high-performance systolic arrays on fpga,” inProceedings of the 2021 ACM/SIGDA International Symposium on Field Programmable Gate Arrays (FPGA ’21). ACM, 2021, pp. 93–104
2021
-
[15]
Versal ai edge series gen 2 product selection guide,
AMD, “Versal ai edge series gen 2 product selection guide,” Advanced Micro Devices, Inc., Tech. Rep., 2024, product Selection Guide. [Online]. Available: https://www.eetasia.com/wp-content/uploads/sites/ 2/2024/07/16 versal-ai-edge-gen2-psg.pdf
2024
-
[16]
[Online]
——,AI Engine Kernel and Graph Programming Guide (UG1079), Ad- vanced Micro Devices, Inc., document ID: UG1079. [Online]. Available: https://docs.amd.com/r/en-US/ug1079-ai-engine-kernel-coding
-
[17]
Acap at the edge with the versal ai edge series,
Xilinx, “Acap at the edge with the versal ai edge series,” Xilinx / AMD, Tech. Rep. WP518, v1.0, Jun. 2021, white Paper. [Online]. Available: https://docs.amd.com/api/khub/ documents/Xz0szg2HiN1YFYfaJVXcrQ/content?Ft-Calling-App= ft%2Fturnkey-portal&Ft-Calling-App-Version=4.1.3&filename= wp518-ai-edge-intro.pdf
2021
-
[18]
2025.DOI: 10.48550/ ARXIV .2512.15946
D. Danopoulos, E. Lupi, C. Sun, S. Dittmeier, M. Kagan, V . Loncar, and M. Pierini, “Aie4ml: An end-to-end framework for compiling neural networks for the next generation of amd ai engines,”arXiv preprint arXiv:2512.15946, 2025
-
[19]
Gama: High-performance gemm acceleration on amd versal ml-optimized ai engines,
K. M. Mhatre, E. Taka, and A. Arora, “Gama: High-performance gemm acceleration on amd versal ml-optimized ai engines,”ArXiv preprint: 2504.09688v3, 2025
-
[20]
Maxeva: Maximizing the efficiency of matrix multiplication on versal ai engine,
E. Taka, A. Arora, K.-C. Wu, and D. Marculescu, “Maxeva: Maximizing the efficiency of matrix multiplication on versal ai engine,”arXiv preprint arXiv:2311.04980 [cs], Nov 2023
-
[21]
Activa- tion function integration for accelerating multi-layer graph convolutional neural networks,
M. Grailoo, T. Nikoubin, O. Gustafsson, and J. Nunez-Yanez, “Activa- tion function integration for accelerating multi-layer graph convolutional neural networks,” in2024 IEEE 17th Dallas Circuits and Systems Conference (DCAS). IEEE, 2024, pp. 1–6
2024
-
[22]
Ama: An analytical approach to maximizing the efficiency of deep learning on versal ai engine,
X. Deng, S. Wang, T. Gao, J. Liu, L. Liu, and N. Zheng, “Ama: An analytical approach to maximizing the efficiency of deep learning on versal ai engine,” in2024 34th International Conference on Field- Programmable Logic and Applications (FPL), 2024
2024
-
[23]
Mapping parallel matrix multiplication in gotoblas2 to the amd versal acap for deep learning,
J. Lei and E. S. Quintana-Ort ´ı, “Mapping parallel matrix multiplication in gotoblas2 to the amd versal acap for deep learning,” inProceedings of the 4th Workshop on Performance and Energy Efficiency in Concurrent and Distributed Systems, 2024, pp. 1–8
2024
-
[24]
BERT: Pre- training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre- training of deep bidirectional transformers for language understanding,” inProceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), 2019
2019
-
[25]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[26]
M. V . Koroteev, “Bert: a review of applications in natural language processing and understanding,”arXiv preprint arXiv:2103.11943, 2021
-
[27]
TinyLlama: An Open-Source Small Language Model
P. Zhang, G. Zeng, T. Wang, and W. Lu, “TinyLlama: An open-source small language model,”arXiv preprint arXiv:2401.02385, 2024
work page internal anchor Pith review arXiv 2024
-
[28]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
T. Dao, “Flashattention-2: Faster attention with better parallelism and work partitioning,”arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review arXiv 2023
-
[29]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, “Gemma: Open models based on gemini technology,” arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.