Dejavu: Towards Experience Feedback Learning for Embodied Intelligence
Pith reviewed 2026-05-18 07:56 UTC · model grok-4.3
The pith
Augmenting frozen VLA policies with retrieved past experiences lets embodied agents learn after deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An Experience Feedback Network trained by reinforcement learning and semantic similarity rewards can retrieve relevant prior execution memories and condition a frozen VLA policy's action outputs on those memories, enabling continual post-deployment improvement through memory expansion without updating the base model.
What carries the argument
Experience Feedback Network (EFN): a module that identifies contextually relevant prior action experiences through semantic similarity and conditions the frozen VLA policy's action prediction on the retrieved guidance.
If this is right
- Agents can adapt to new conditions without retraining or redeploying the base VLA model.
- Success rates rise when action choices are guided by semantically similar past trajectories.
- Memory expansion during use produces ongoing robustness gains across diverse tasks.
- The same retrieval-and-conditioning approach can be applied to any frozen policy that outputs actions from observations.
Where Pith is reading between the lines
- The method could lower the cost of maintaining deployed robots by shifting adaptation from model updates to memory growth.
- Similar retrieval mechanisms might extend to non-robotic domains that use frozen generative models for sequential decisions.
- Combining EFN with occasional light fine-tuning of the base policy could yield further gains beyond pure post-deployment memory use.
Load-bearing premise
Contextually relevant prior action experiences can be reliably retrieved and conditioning action prediction on them via semantic similarity rewards produces measurably better policies.
What would settle it
A controlled deployment trial in which the EFN-augmented agent shows no improvement or a drop in task success rate compared with the frozen baseline across the same set of environments.
Figures



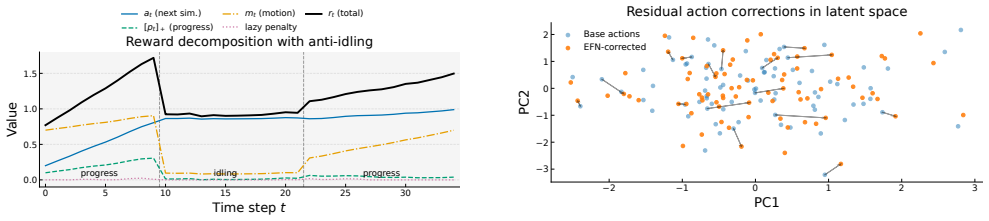
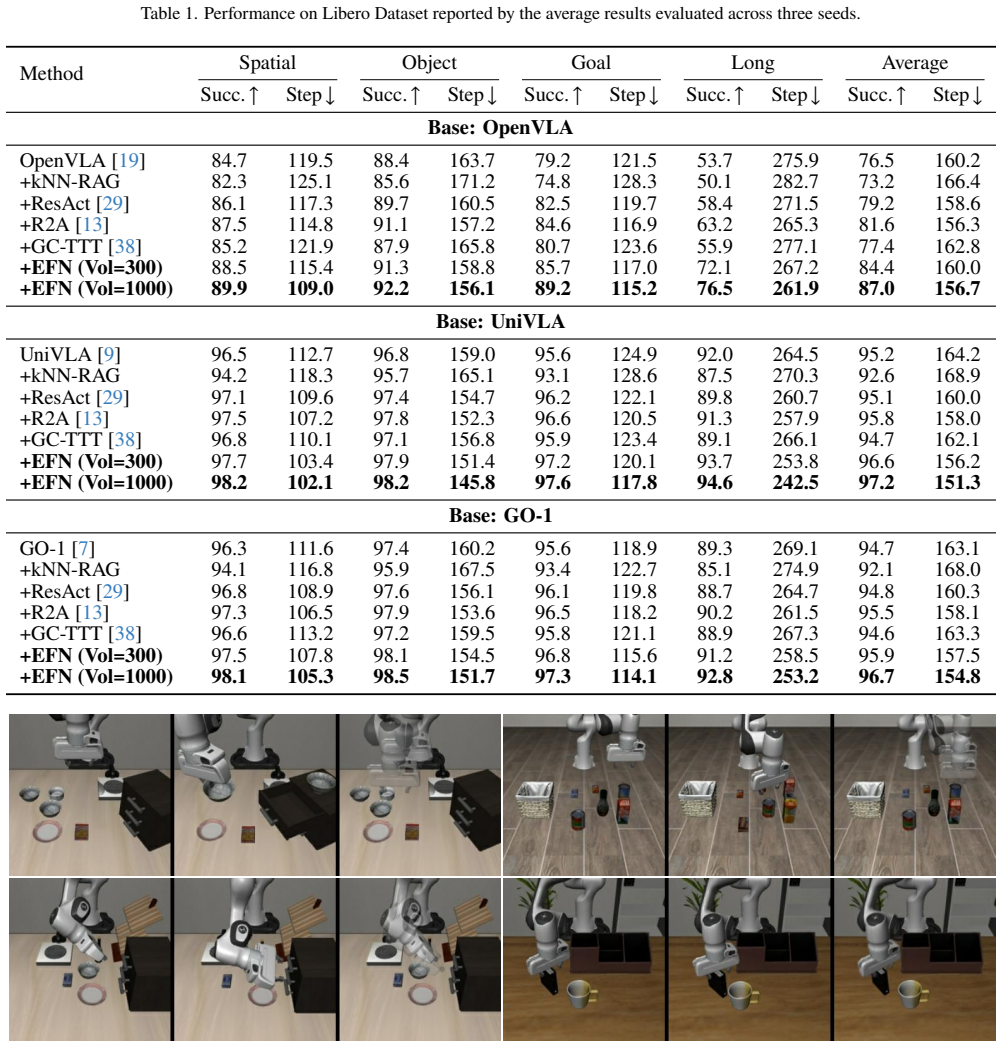




read the original abstract
Embodied agents face a fundamental limitation: once deployed in real-world environments, they cannot easily acquire new knowledge to improve task performance. In this paper, we propose Dejavu, a general post-deployment learning framework that augments a frozen Vision-Language-Action (VLA) policy with retrieved execution memories through an Experience Feedback Network (EFN). EFN identifies contextually relevant prior action experiences and conditions action prediction on the retrieved guidance. We train EFN with reinforcement learning and semantic similarity rewards, encouraging the predicted actions to align with past behaviors under the current observation. During deployment, EFN continually expands its memory with new trajectories, enabling the agent to exhibit ``learning from experience.'' Experiments across diverse embodied tasks show that EFN improves adaptability, robustness, and success rates over frozen baselines. Our Project Page is https://dejavu2025.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dejavu, a post-deployment learning framework for embodied agents. It augments a frozen Vision-Language-Action (VLA) policy with an Experience Feedback Network (EFN) that retrieves contextually relevant prior action experiences via semantic similarity (cosine similarity in a shared embedding space) and conditions action prediction on the retrieved guidance. EFN is trained with reinforcement learning using semantic similarity rewards to encourage alignment between predicted actions and past behaviors under the current observation. During deployment, the memory is continually expanded with new trajectories to enable ongoing 'learning from experience.' Experiments across diverse embodied tasks report that EFN improves adaptability, robustness, and success rates over frozen baselines.
Significance. If the central claims hold, the work would address a core limitation in embodied intelligence by enabling continual, post-deployment improvement without retraining the base VLA policy. The framework offers a practical mechanism for experience feedback in real-world robotics settings. Credit is due for the explicit post-deployment memory expansion design and the attempt to integrate retrieval with RL-based conditioning, which could support falsifiable predictions about experience-driven policy adaptation if properly validated.
major comments (2)
- [§3.2] §3.2: Retrieval is performed by cosine similarity in a shared embedding space and the policy is rewarded for aligning predicted actions with retrieved ones, but no quantitative retrieval metrics (e.g., precision@K, task-success correlation of retrieved memories, or failure-case analysis for out-of-distribution observations) are reported. This is load-bearing for the claim that EFN retrieves functionally relevant experiences rather than merely visually or linguistically similar ones.
- [§4.1] §4.1 and experiments section: The evaluation compares EFN only against frozen baselines and reports improved success rates, but provides no ablation on retrieval quality, no error bars, no dataset sizes, and no analysis of cases where semantic similarity may select irrelevant or conflicting guidance. This leaves the central claim of measurable improvement from true experience feedback without sufficient verification steps.
minor comments (1)
- [Abstract] Abstract: Reports empirical gains but omits any quantitative details on baselines, error bars, or ablation studies, which reduces clarity for readers assessing the strength of the results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below. Where the comments identify areas for strengthening the evidence, we have revised the manuscript accordingly to include the requested analyses and metrics.
read point-by-point responses
-
Referee: [§3.2] §3.2: Retrieval is performed by cosine similarity in a shared embedding space and the policy is rewarded for aligning predicted actions with retrieved ones, but no quantitative retrieval metrics (e.g., precision@K, task-success correlation of retrieved memories, or failure-case analysis for out-of-distribution observations) are reported. This is load-bearing for the claim that EFN retrieves functionally relevant experiences rather than merely visually or linguistically similar ones.
Authors: We agree that quantitative retrieval metrics would provide stronger support for the claim that retrieved experiences are functionally relevant rather than merely superficially similar. In the revised manuscript, we have added precision@K results evaluated on a held-out set of trajectories, a correlation analysis between retrieval similarity scores and task success rates, and a dedicated failure-case analysis for out-of-distribution observations. These new results, presented in an expanded Section 3.2 and Appendix C, show that the combination of embedding-space retrieval and RL-based semantic similarity rewards preferentially selects experiences that improve action prediction under the current observation. revision: yes
-
Referee: [§4.1] §4.1 and experiments section: The evaluation compares EFN only against frozen baselines and reports improved success rates, but provides no ablation on retrieval quality, no error bars, no dataset sizes, and no analysis of cases where semantic similarity may select irrelevant or conflicting guidance. This leaves the central claim of measurable improvement from true experience feedback without sufficient verification steps.
Authors: We acknowledge that additional ablations, statistical reporting, and analysis of edge cases would increase confidence in the measured improvements. The revised version now includes an ablation comparing EFN against random-retrieval and no-retrieval controls, reports error bars computed over five independent runs for all success-rate results, explicitly states the sizes of the training and evaluation trajectory datasets, and adds an analysis of conflicting-guidance cases demonstrating that the RL-trained reward mitigates negative transfer. These updates appear in Section 4.1 and the accompanying experimental tables. revision: yes
Circularity Check
No significant circularity; derivation is self-contained with empirical validation
full rationale
The paper introduces EFN as a post-deployment augmentation to frozen VLA policies via retrieval of execution memories and RL training with semantic similarity rewards. Central claims rest on experimental improvements in adaptability and success rates over baselines across embodied tasks, not on any derivation that reduces by construction to fitted inputs or self-citations. No equations or steps equate predictions directly to training data by definition; retrieval and conditioning mechanisms are presented as novel and evaluated externally via task performance metrics. The framework is independent of the specific memory contents used in training.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL reward weighting between semantic similarity and task success
axioms (1)
- domain assumption Semantic similarity between current and past observations serves as a valid proxy for action relevance
invented entities (1)
-
Experience Feedback Network (EFN)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EFN identifies contextually relevant prior action experiences and conditions action prediction on the retrieved guidance. We train EFN with reinforcement learning and semantic similarity rewards
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose EFN, a retrieval-conditioned residual module that augments a frozen VLA policy with an episodic experience bank
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
ECHO: Continuous Hierarchical Memory for Vision-Language-Action Models
ECHO organizes VLA experiences into a hierarchical memory tree in hyperbolic space via autoencoder and entailment constraints, delivering a 12.8% success-rate gain on LIBERO-Long over the pi0 baseline.
Reference graph
Works this paper leans on
-
[1]
Marcin Andrychowicz et al. Hindsight experience re- play. In Advances in Neural Information Processing Systems (NeurIPS), 2017. 1, 3
work page 2017
-
[2]
Rraml: Reinforced retrieval augmented machine learning,
Andrea Bacciu, Florin Cuconasu, Federico Siciliano, Fab- rizio Silvestri, Nicola Tonellotto, and Giovanni Trappolini. Rraml: Reinforced retrieval augmented machine learning,
-
[3]
Test-time Offline Reinforcement Learning on Goal-related Experience
Marco Bagatella, Mert Albaba, Jonas Hübotter, Georg Mar- tius, and Andreas Krause. Test-time offline reinforcement learning on goal-related experience. CoRR, abs/2507.18809,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Charles Blundell, Benigno Uria, Alexander Pritzel, Y azhe Li, Avraham Ruderman, Joel Z. Leibo, Jack W. Rae, Daan Wier- stra, and Demis Hassabis. Model-free episodic control. arXiv preprint arXiv:1606.04460, 2016. 2
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Quantile QT-Opt for risk-aware vision- based robotic grasping
Cristian Bodnar, Adrian Li, Karol Hausman, Peter Pastor, and Mrinal Kalakrishnan. Quantile QT-Opt for risk-aware vision- based robotic grasping. In Robotics: Science and Systems (RSS), 2020. 3
work page 2020
-
[6]
Rt-1: Robotics transformer for real- world control at scale
Anthony Brohan et al. Rt-1: Robotics transformer for real- world control at scale. In Robotics: Science and Systems (RSS), 2023. 1, 2
work page 2023
-
[7]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Y an Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, Shu Jiang, Yuxin Jiang, Cheng Jing, Hongyang Li, Jialu Li, Chiming Liu, Yi Liu, Yuxiang Lu, Jianlan Luo, Ping Luo, Y ao Mu, Yuehan Niu, Yixuan Pan, Jiangmiao Pang, Yu Qiao, Guanghui Ren, Cheng Ruan, Jiaqi Shan, Y ongjian Shen, Chengshi Shi, Min...
-
[9]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Y anting Y ang, Jisong Cai, et al. Univla: Learn- ing to act anywhere with task-centric latent actions. arXiv preprint arXiv:2505.06111, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Chilam Cheang, Sijin Chen, Zhongren Cui, Yingdong Hu, Liqun Huang, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Xiao Ma, Hao Niu, Wenxuan Ou, Wanli Peng, Zeyu Ren, Haixin Shi, Jiawen Tian, Hongtao Wu, Xin Xiao, Yuyang Xiao, Jiafeng Xu, and Yichu Y ang. Gr-3 technical report,
-
[11]
Foundation models in robotics: Applications, challenges, and the future
Roya Firoozi, Johnathan Tucker, Stephen Tian, Anirudha Ma- jumdar, Jiankai Sun, Weiyu Liu, Yuke Zhu, Shuran Song, Ashish Kapoor, Karol Hausman, Brian Ichter, Danny Driess, Jiajun Wu, Cewu Lu, and Mac Schwager. Foundation models in robotics: Applications, challenges, and the future. Int. J. Rob. Res., 44(5):701–739, 2025. 1
work page 2025
-
[12]
To- wards generalizable vision-language robotic manipulation: A benchmark and llm-guided 3d policy
Ricardo Garcia, Shizhe Chen, and Cordelia Schmid. To- wards generalizable vision-language robotic manipulation: A benchmark and llm-guided 3d policy. In International Con- ference on Robotics and Automation (ICRA) , 2025. 3
work page 2025
-
[13]
Retrieval-augmented reinforcement learn- ing
Anirudh Goyal, Abram Friesen, Andrea Banino, Theophane Weber, Nan Rosemary Ke, Adria Puigdomenech Badia, Arthur Guez, Mehdi Mirza, Peter C Humphreys, Ksenia Konyushova, et al. Retrieval-augmented reinforcement learn- ing. In International Conference on Machine Learning, pages 7740–7765. PMLR, 2022. 1, 2, 6, 7, 8, 15, 22, 23
work page 2022
-
[14]
Octo: An open-source generalist robot policy
Huy Ha et al. Octo: An open-source generalist robot policy. In Robotics: Science and Systems (RSS) , 2024. 1, 2
work page 2024
-
[15]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Inter- national Conference on Machine Learning (ICML) , pages 1861–1870, 2018. 2, 3, 12
work page 2018
- [16]
-
[17]
Mul- timodal fusion and vision–language models: A survey for robot vision
Xiaofeng Han, Shunpeng Chen, Zenghuang Fu, Zhe Feng, Lue Fan, Dong An, Changwei Wang, Li Guo, Weiliang Meng, Xiaopeng Zhang, Rongtao Xu, and Shibiao Xu. Mul- timodal fusion and vision–language models: A survey for robot vision. Information Fusion, 126:103652, 2026. 1
work page 2026
-
[18]
T. Johannink et al. Residual reinforcement learning for robot control. In IEEE International Conference on Robotics and Automation (ICRA), 2019. 3
work page 2019
-
[19]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Paul Foster, Pannag R. Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model. In Conference on Robot Learning, 6-9...
work page 2024
-
[20]
RAM: Retrieval-based affordance transfer for generalizable zero-shot robotic manipulation
Yuxuan Kuang, Junjie Y e, Haoran Geng, Jiageng Mao, Con- gyue Deng, Leonidas Guibas, He Wang, and Yue Wang. RAM: Retrieval-based affordance transfer for generalizable zero-shot robotic manipulation. In Proceedings of The 8th Conference on Robot Learning , pages 547–565. PMLR,
-
[21]
So Kuroki, Mai Nishimura, and Tadashi Kozuno. Multi-agent behavior retrieval: Retrieval-augmented policy training for cooperative push manipulation by mobile robots. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024. 2
work page 2024
-
[22]
Solving continu- ous control with episodic memory
Igor Kuznetsov and Andrey Filchenkov. Solving continu- ous control with episodic memory. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelli- gence (IJCAI-21), pages 2651–2657. International Joint Con- ferences on Artificial Intelligence Organization, 2021. 2
work page 2021
-
[23]
RT-Cache: Training-free retrieval for real- time manipulation
Owen Kwon, Abraham George, Alison Bartsch, and Amir Barati Farimani. RT-Cache: Training-free retrieval for real- time manipulation. arXiv preprint arXiv:2505.09040, 2025. 2
-
[24]
Libero: Benchmarking knowl- 9 edge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowl- 9 edge transfer for lifelong robot learning. In Advances in Neu- ral Information Processing Systems (NeurIPS) — Datasets and Benchmarks, 2023. 2, 3, 6, 14
work page 2023
-
[25]
Huihan Liu, Soroush Nasiriany, Lance Zhang, Zhiyao Bao, and Yuke Zhu. Robot learning on the job: Human-in-the-loop autonomy and learning during deployment.The International Journal of Robotics Research, 2024. 1, 2
work page 2024
-
[26]
Embodied in- telligence: A synergy of morphology, action, perception and learning
Huaping Liu, Di Guo, and Angelo Cangelosi. Embodied in- telligence: A synergy of morphology, action, perception and learning. ACM Computing Surveys, 57(7):1–36, 2025. 1
work page 2025
-
[27]
Embodied intelligence: A synergy of morphol- ogy, action, and learning
Hao Liu et al. Embodied intelligence: A synergy of morphol- ogy, action, and learning. ACM Computing Surveys, 2025. 1
work page 2025
-
[28]
Robomamba: Efficient vision-language- action model for robotic reasoning and manipulation
Jiaming Liu et al. Robomamba: Efficient vision-language- action model for robotic reasoning and manipulation. In Ad- vances in Neural Information Processing Systems (NeurIPS),
-
[29]
Visual rein- forcement learning with residual action
Zhenxian Liu, Peixi Peng, and Y onghong Tian. Visual rein- forcement learning with residual action. In AAAI-25, Spon- sored by the Association for the Advancement of Artificial In- telligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pages 19050–19058. AAAI Press, 2025. 6, 7, 8, 15, 18, 22, 23
work page 2025
-
[30]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wol- fram Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipu- lation tasks. IEEE Robotics and Automation Letters , 7(3): 7327–7334, 2022. 14, 23
work page 2022
-
[31]
STRAP: Robot sub-trajectory retrieval for augmented policy learning
Marius Memmel, Jacob Berg, Bingqing Chen, Abhishek Gupta, and Jonathan Francis. STRAP: Robot sub-trajectory retrieval for augmented policy learning. In The Thirteenth In- ternational Conference on Learning Representations , 2025. 2
work page 2025
-
[32]
A W AC: Accelerating online reinforcement learning with offline datasets
Ashvin Nair, Murtaza Dalal, Abhishek Gupta, and Sergey Levine. A W AC: Accelerating online reinforcement learning with offline datasets. In Advances in Neural Information Pro- cessing Systems (NeurIPS), 2020. 3
work page 2020
-
[33]
Junhyuk Oh, Yijie Guo, Satinder Singh, and Honglak Lee. Self-imitation learning. In International Conference on Ma- chine Learning (ICML), pages 3878–3887, 2018. 1
work page 2018
-
[34]
Alexander Pritzel, Benigno Uria, Sriram Srinivasan, Adrià Puigdomènech Badia, Oriol Vinyals, Demis Hassabis, Daan Wierstra, and Charles Blundell. Neural episodic control. In Proceedings of the 34th International Conference on Ma- chine Learning, pages 2827–2836. PMLR, 2017. 2
work page 2017
-
[35]
Large vlm-based vision- language-action models for robotic manipulation: A survey,
Rui Shao, Wei Li, Lingsen Zhang, Renshan Zhang, Zhiyang Liu, Ran Chen, and Liqiang Nie. Large vlm-based vision- language-action models for robotic manipulation: A survey,
-
[36]
Smolvla: A vision-language-action model for afford- able and efficient robotics, 2025
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Ar- actingi, Caroline Pascal, Martino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, and Remi Ca- dene. Smolvla: A vision-language-action model for afford- able and efficient robotics, 2025. 2
work page 2025
-
[37]
Fuchun Sun, Runfa Chen, Tianying Ji, Yu Luo, Huaidong Zhou, and Huaping Liu. A comprehensive survey on embod- ied intelligence: Advancements, challenges, and future per- spectives. CAAI Artificial Intelligence Research, 3:9150042,
-
[38]
Test-time training with self-supervision for generalization under distribution shifts
Yu Sun, Arash Vahdat, Alexander Kirillov, Kaiming He, Zhuang Xu, Yuxin Wang, Laurent Dinh, and Nima Goyal. Test-time training with self-supervision for generalization under distribution shifts. In International Conference on Ma- chine Learning, 2020. 6, 7, 8
work page 2020
-
[39]
Y es, q- learning helps offline in-context rl, 2025
Denis Tarasov, Alexander Nikulin, Ilya Zisman, Albina Klepach, Andrei Polubarov, Nikita Lyubaykin, Alexander Derevyagin, Igor Kiselev, and Vladislav Kurenkov. Y es, q- learning helps offline in-context rl, 2025. 2
work page 2025
-
[40]
In-context reinforcement learning with retrieval- augmented generation for text-to-SQL
Rishit Toteja, Arindam Sarkar, and Prakash Mandayam Comar. In-context reinforcement learning with retrieval- augmented generation for text-to-SQL. In Proceedings of the 31st International Conference on Computational Linguistics, pages 10390–10397, Abu Dhabi, UAE, 2025. Association for Computational Linguistics. 2
work page 2025
-
[41]
Rui Y ang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, Heng Ji, Huan Zhang, and Tong Zhang. Embodiedbench: Comprehensive benchmark- ing multi-modal large language models for vision-driven em- bodied agents. In Forty-second International Conference on Machine Learning, 2025. 3
work page 2025
-
[42]
Mastering visual continuous control: Improved data- augmented reinforcement learning
Denis Y arats, Rob Fergus, Alessandro Lazaric, and Lerrel Pinto. Mastering visual continuous control: Improved data- augmented reinforcement learning. In International Confer- ence on Learning Representations (ICLR) , 2021. 3
work page 2021
-
[43]
Igniting vlms toward the embodied space, 2025
Andy Zhai, Brae Liu, Bruno Fang, Chalse Cai, Ellie Ma, Ethan Yin, Hao Wang, Hugo Zhou, James Wang, Lights Shi, Lucy Liang, Make Wang, Qian Wang, Roy Gan, Ryan Yu, Shalfun Li, Starrick Liu, Sylas Chen, Vincent Chen, and Zach Xu. Igniting vlms toward the embodied space, 2025. 2
work page 2025
-
[44]
Pure vision language action (vla) models: A comprehensive sur- vey, 2025
Dapeng Zhang, Jin Sun, Chenghui Hu, Xiaoyan Wu, Zhen- long Yuan, Rui Zhou, Fei Shen, and Qingguo Zhou. Pure vision language action (vla) models: A comprehensive sur- vey, 2025. 2
work page 2025
-
[45]
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu- Gang Jiang, and Xipeng Qiu. Vlabench: A large-scale bench- mark for language-conditioned robotics manipulation with long-horizon reasoning tasks, 2024. 3
work page 2024
-
[46]
Retrieval-augmented embodied agents
Yichen Zhu, Zhicai Ou, Xiaofeng Mou, and Jian Tang. Retrieval-augmented embodied agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17985–17995, 2024. 2
work page 2024
-
[47]
Ethan Z. Zitkovich et al. Rt-2: Vision-language-action mod- els transfer web knowledge to robotic control. In Conference on Robot Learning (CoRL) , pages 1742–1768, 2023. 1, 2 10 Appendix A. Overview Thank you for reading the Appendix for our research. This Appendix is organized as the following sections. Section B describes the detailed settings of our m...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.