Scaling Beyond Context: A Survey of Multimodal Retrieval-Augmented Generation for Document Understanding
Pith reviewed 2026-05-18 06:51 UTC · model grok-4.3
The pith
Multimodal RAG enables holistic retrieval and reasoning across text, tables, charts, and layout in documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Multimodal RAG is presented as the advanced paradigm required for document intelligence because it supports retrieval and reasoning that integrates every modality present in a document rather than treating them separately or losing them to preprocessing steps.
What carries the argument
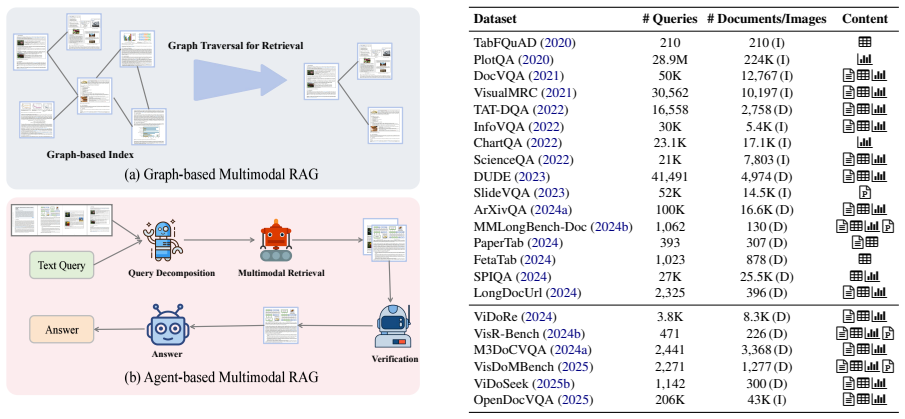
A taxonomy of Multimodal RAG systems organized by domain, retrieval modality, and granularity, extended by graph structures and agentic frameworks for coordinated retrieval and reasoning.
If this is right
- Document applications in finance and science gain the ability to preserve and use layout and visual elements during reasoning.
- Graph structures and agentic frameworks become central building blocks for scalable multimodal retrieval systems.
- New datasets and benchmarks focused on fine-grained cross-modality retrieval will be required to measure progress.
- Improvements in efficiency and robustness will determine whether these systems reach widespread industry deployment.
Where Pith is reading between the lines
- Hybrid systems that combine native multimodal models with selective retrieval could emerge as practical next steps when full-document context remains expensive.
- Testing robustness against layout perturbations or modality-specific noise would clarify whether current approaches generalize beyond clean benchmarks.
- Efficiency gains from coarser granularity retrieval might trade off against the fine-grained accuracy needed for technical documents.
Load-bearing premise
The limitations of OCR pipelines losing structural detail and native multimodal models struggling with context modeling are fundamental enough to require Multimodal RAG as a distinct and superior approach.
What would settle it
A single native multimodal model that maintains accurate reasoning over full-length documents containing mixed text, tables, and images without any external retrieval step would remove the stated motivation for Multimodal RAG.
Figures




read the original abstract
Document understanding is critical for applications from financial analysis to scientific discovery. Current approaches, whether OCR-based pipelines feeding Large Language Models (LLMs) or native Multimodal LLMs (MLLMs), face key limitations: the former loses structural detail, while the latter struggles with context modeling. Retrieval-Augmented Generation (RAG) helps ground models in external data, but documents' multimodal nature, i.e., combining text, tables, charts, and layout, demands a more advanced paradigm: Multimodal RAG. This approach enables holistic retrieval and reasoning across all modalities, unlocking comprehensive document intelligence. Recognizing its importance, this paper presents a systematic survey of Multimodal RAG for document understanding. We propose a taxonomy based on domain, retrieval modality, and granularity, and review advances involving graph structures and agentic frameworks. We also summarize key datasets, benchmarks, applications and industry deployment, and highlight open challenges in efficiency, fine-grained representation, and robustness, providing a roadmap for future progress in document AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys Multimodal Retrieval-Augmented Generation (RAG) for document understanding. It motivates the approach from limitations of OCR pipelines (loss of structural detail) and native MLLMs (context modeling struggles), proposes a taxonomy organized by domain, retrieval modality, and granularity, reviews graph-based methods and agentic frameworks, summarizes datasets, benchmarks, applications, and industry use cases, and outlines open challenges in efficiency, fine-grained representation, and robustness.
Significance. If the taxonomy and synthesis hold, the survey offers a useful organizing framework for an emerging area in document AI. Credit is due for the explicit taxonomy dimensions and the coverage of graph structures plus agentic systems, which together provide a practical roadmap. The summary of datasets and benchmarks is a strength that can support future comparative work and reproducibility.
minor comments (3)
- The motivation section would benefit from a short table contrasting OCR, native MLLM, and Multimodal RAG on the dimensions of structural fidelity and long-context handling, to make the positioning more concrete.
- In the taxonomy description, the interaction between the three axes (domain, modality, granularity) is stated but not illustrated with a worked example of a single document; adding one would clarify how the dimensions are applied in practice.
- The challenges section lists efficiency and robustness but does not quantify typical retrieval latency or error rates reported in the surveyed papers; a brief summary table of reported metrics would strengthen the discussion.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our survey and the recommendation for minor revision. The feedback affirms the value of the proposed taxonomy organized by domain, retrieval modality, and granularity, as well as the coverage of graph-based methods, agentic frameworks, datasets, benchmarks, and open challenges. We appreciate the recognition that this provides a practical roadmap for the emerging area of Multimodal RAG for document understanding.
Circularity Check
No significant circularity in survey taxonomy and review
full rationale
This is a survey paper that organizes existing Multimodal RAG literature via a proposed taxonomy (domain, retrieval modality, granularity) and reviews graphs, agents, datasets, benchmarks, and challenges. The abstract and provided text contain no derivations, equations, predictions, fitted parameters, or formal claims that could reduce to self-referential inputs. Motivational positioning of Multimodal RAG draws from stated limitations of OCR and native MLLMs as described in external work, without any self-definitional loops, fitted-input predictions, or load-bearing self-citations that would create circularity. The paper is self-contained as an organizational synthesis with no internal reduction of results to its own inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a taxonomy based on domain, retrieval modality, and granularity, and review advances involving graph structures and agentic frameworks.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
highlight open challenges in efficiency, fine-grained representation, and robustness
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
Very Efficient Listwise Multimodal Reranking for Long Documents
ZipRerank delivers state-of-the-art multimodal listwise reranking accuracy for long documents at up to 10x lower latency via early interaction and single-pass scoring.
-
Visual Late Chunking: An Empirical Study of Contextual Chunking for Efficient Visual Document Retrieval
ColChunk adaptively chunks visual document patches into contextual multi-vectors via clustering, cutting storage by over 90% while raising average nDCG@5 by 9 points.
-
Sculpting the Vector Space: Towards Efficient Multi-Vector Visual Document Retrieval via Prune-then-Merge Framework
Prune-then-Merge combines adaptive pruning of low-signal patches with hierarchical merging to achieve higher compression rates and better performance than prior single-stage methods in visual document retrieval.
-
MINER: Mining Multimodal Internal Representation for Efficient Retrieval
MINER fuses internal transformer layer representations via probing and adaptive sparse fusion to improve dense single-vector retrieval quality on visual documents by up to 4.5% nDCG@5 while preserving efficiency.
-
CausalEmbed: Auto-Regressive Multi-Vector Generation in Latent Space for Visual Document Embedding
CausalEmbed uses auto-regressive generation with iterative margin loss to produce multi-vector embeddings that reduce visual token counts 30-155x while retaining competitive performance on VDR benchmarks.
Reference graph
Works this paper leans on
-
[1]
Kenneth Ward Church, Jiameng Sun, Richard Yue, Pe- ter Vickers, Walid Saba, and Raman Chandrasekar
A review of the f-measure: its history, prop- erties, criticism, and alternatives.ACM Computing Surveys, 56(3):1–24. Kenneth Ward Church, Jiameng Sun, Richard Yue, Pe- ter Vickers, Walid Saba, and Raman Chandrasekar
-
[2]
Natural Language Engineering, 30(4):870–881
Emerging trends: a gentle introduction to rag. Natural Language Engineering, 30(4):870–881. Gordon V Cormack, Charles LA Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd international ACM SIGIR conference on Research and development in informa- tion retrieval,...
-
[3]
Kalervo Järvelin and Jaana Kekäläinen
Simpledoc: Multi-modal document under- standing with dual-cue page retrieval and iterative refinement.arXiv preprint arXiv:2506.14035. Kalervo Järvelin and Jaana Kekäläinen. 2002. Cu- mulated gain-based evaluation of ir techniques. ACM Transactions on Information Systems (TOIS), 20(4):422–446. Changyue Jiang, Xudong Pan, Geng Hong, Chenfu Bao, and Min Yan...
-
[4]
11 Xueguang Ma, Sheng-Chieh Lin, Minghan Li, Wenhu Chen, and Jimmy Lin
Enhancing document vqa models via retrieval-augmented generation.arXiv preprint arXiv:2508.18984. 11 Xueguang Ma, Sheng-Chieh Lin, Minghan Li, Wenhu Chen, and Jimmy Lin. 2024a. Unifying multimodal retrieval via document screenshot embedding.arXiv preprint arXiv:2406.11251. Yubo Ma, Jinsong Li, Yuhang Zang, Xiaobao Wu, Xi- aoyi Dong, Pan Zhang, Yuhang Cao,...
-
[5]
Nitesh Methani, Pritha Ganguly, Mitesh M Khapra, and Pratyush Kumar
A survey of multimodal retrieval-augmented generation.arXiv preprint arXiv:2504.08748. Nitesh Methani, Pritha Ganguly, Mitesh M Khapra, and Pratyush Kumar. 2020. Plotqa: Reasoning over sci- entific plots. InProceedings of the ieee/cvf winter conference on applications of computer vision, pages 1527–1536. Kalyan Nandi and S Siva Sathya. 2024. Visual docu- ...
-
[6]
InEuropean Conference on Information Retrieval, pages 239–251
Poison-rag: Adversarial data poisoning attacks on retrieval-augmented generation in recommender systems. InEuropean Conference on Information Retrieval, pages 239–251. Springer. Thong Nguyen, Mariya Hendriksen, Andrew Yates, and Maarten de Rijke. 2024. Multimodal learned sparse retrieval with probabilistic expansion control. Preprint, arXiv:2402.17535. Th...
-
[7]
Baoguang Shi, Xiang Bai, and Cong Yao
One pic is all it takes: Poisoning visual doc- ument retrieval augmented generation with a single image.arXiv preprint arXiv:2504.02132. Baoguang Shi, Xiang Bai, and Cong Yao. 2016. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text 12 recognition.IEEE transactions on pattern analysis and machine ...
-
[8]
Understanding data poisoning attacks for rag: Insights and algorithms. Zhiyou Xiao, Qinhan Yu, Binghui Li, Geng Chen, Chong Chen, and Wentao Zhang. 2025a. M2io-r1: An efficient rl-enhanced reasoning framework for multimodal retrieval augmented multimodal genera- tion.arXiv preprint arXiv:2508.06328. Zilin Xiao, Qi Ma, Mengting Gu, Chun-cheng Jason Chen, X...
-
[9]
Docr1: Evidence page-guided grpo for multi-page document understanding.arXiv preprint arXiv:2508.07313. Mingjun Xu, Jinhan Dong, Jue Hou, Zehui Wang, Si- hang Li, Zhifeng Gao, Renxin Zhong, and Hengxing Cai. 2025a. Mm-r5: Multimodal reasoning-enhanced reranker via reinforcement learning for document re- trieval.arXiv preprint arXiv:2506.12364. 13 Mingjun ...
-
[10]
mplug-docowl: Modularized multimodal large language model for document understanding
R 2ag: Incorporating retrieval information into retrieval augmented generation. InEMNLP (Find- ings). Jiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Yuhao Dan, Chenlin Zhao, Guohai Xu, Chen- liang Li, Junfeng Tian, and 1 others. 2023. mplug- docowl: Modularized multimodal large language model for document understanding.arXiv preprint arXiv:2307.024...
-
[11]
Yinan Zhou, Yuxin Chen, Haokun Lin, Shuyu Yang, Li Zhu, Zhongang Qi, Chen Ma, and Ying Shan
Finragbench-v: A benchmark for multimodal rag with visual citation in the financial domain.arXiv preprint arXiv:2505.17471. Yinan Zhou, Yuxin Chen, Haokun Lin, Shuyu Yang, Li Zhu, Zhongang Qi, Chen Ma, and Ying Shan. 2024. Doge: Towards versatile visual document grounding and referring.arXiv preprint arXiv:2411.17125. Fengbin Zhu, Wenqiang Lei, Fuli Feng,...
-
[12]
is one of the most representative metrics. BLEU evaluates the similarity between generated text and reference text based on n-gram overlap with a brevity penalty (BP). The BLEU score is defined as: BLEU=BP·exp NX n=1 wn logp n ! ,(12) where pn is the precision for n-grams and wn is the weight assigned to each n-gram order. The brevity penalty (BP) is give...
work page 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.