Recognition: 1 theorem link
· Lean TheoremVery Efficient Listwise Multimodal Reranking for Long Documents
Pith reviewed 2026-05-13 05:12 UTC · model grok-4.3
The pith
ZipRerank achieves state-of-the-art multimodal listwise reranking accuracy on long documents while cutting inference latency by up to an order of magnitude.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
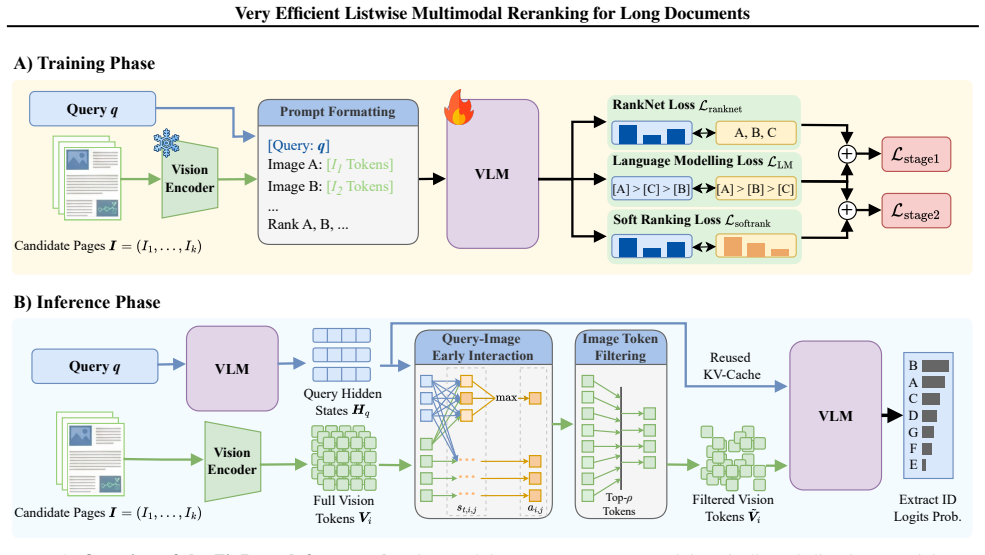
ZipRerank reduces input length via lightweight query-image early interaction and replaces autoregressive decoding with single-forward-pass scoring of all candidates. A two-stage training process—listwise pretraining on rendered text images followed by multimodal fine-tuning using VLM-teacher-distilled soft supervision—enables the model to match or exceed prior multimodal rerankers on the MMDocIR benchmark while lowering LLM inference latency by up to ten times.
What carries the argument
Lightweight query-image early interaction combined with single-pass listwise scoring that avoids autoregressive token generation.
If this is right
- Listwise reranking can now be applied in real-time multimodal retrieval systems that previously found it too slow.
- The same efficiency pattern extends directly to other long-document vision-language tasks that rely on ranking.
- Two-stage training starting from rendered text allows reuse of large text datasets for multimodal rerankers.
- Single-pass scoring removes the need for multi-step decoding in listwise settings.
Where Pith is reading between the lines
- The method may scale to documents longer than those tested if the early-interaction compression remains effective.
- Similar early-interaction designs could be tested in non-ranking multimodal generation pipelines to reduce token counts.
- If the distilled supervision generalizes, the approach offers a template for distilling efficiency into other vision-language ranking models.
Load-bearing premise
That the early interaction and single-pass scoring, after training that begins with rendered text images, continue to preserve ranking quality on actual long multimodal documents.
What would settle it
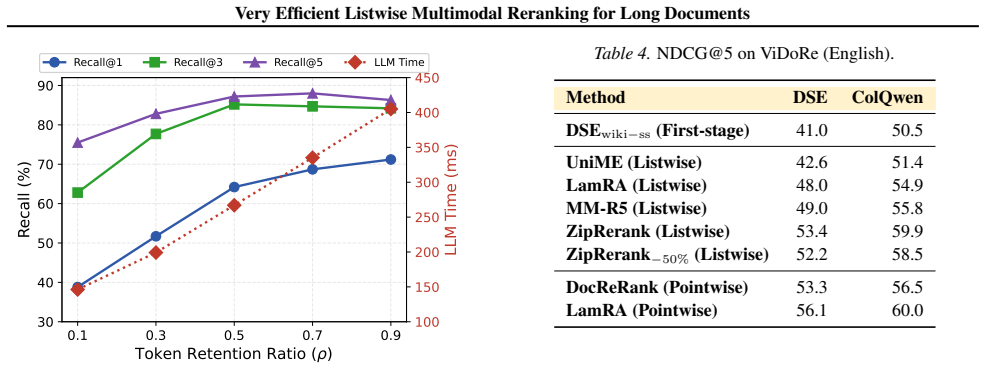
Compare ZipRerank against a standard VLM-based listwise reranker on the same MMDocIR queries; if NDCG or similar ranking metrics drop by more than a few points while claimed latency gains hold, the efficiency claim is refuted.
Figures


read the original abstract
Listwise reranking is a key yet computationally expensive component in vision-centric retrieval and multimodal retrieval-augmented generation (M-RAG) over long documents. While recent VLM-based rerankers achieve strong accuracy, their practicality is often limited by long visual-token sequences and multi-step autoregressive decoding. We propose ZipRerank, a highly efficient listwise multimodal reranker that directly addresses both bottlenecks. It reduces input length via a lightweight query-image early interaction mechanism and eliminates autoregressive decoding by scoring all candidates in a single forward pass. To enable effective learning, ZipRerank adopts a two-stage training strategy: (i) listwise pretraining on large-scale text data rendered as images, and (ii) multimodal finetuning with VLM-teacher-distilled soft-ranking supervision. Extensive experiments on the MMDocIR benchmark show that ZipRerank matches or surpasses state-of-the-art multimodal rerankers while reducing LLM inference latency by up to an order of magnitude, making it well-suited for latency-sensitive real-world systems. The code is available at https://github.com/dukesun99/ZipRerank.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ZipRerank, a listwise multimodal reranker for long documents that shortens visual input via a lightweight query-image early interaction mechanism and eliminates autoregressive decoding by scoring all candidates in one forward pass. It uses a two-stage training process consisting of listwise pretraining on large-scale text rendered as images followed by finetuning with soft-ranking labels distilled from a VLM teacher. On the MMDocIR benchmark, ZipRerank is reported to match or exceed state-of-the-art multimodal rerankers while cutting LLM inference latency by up to an order of magnitude.
Significance. If the empirical claims hold under scrutiny, the work is significant for practical vision-centric retrieval and M-RAG pipelines, where listwise reranking over long multimodal documents has been limited by high latency. The open-sourced code at the provided GitHub link strengthens reproducibility and potential adoption.
major comments (2)
- [Abstract and §3] Abstract and §3 (two-stage training): the claim that listwise pretraining on rendered text images followed by VLM-distilled finetuning preserves ranking quality on real long multimodal documents is load-bearing for the MMDocIR results, yet no ablations are described that test transfer to documents containing non-textual visuals (charts, photos, complex layouts) absent from the rendered-text pretraining data.
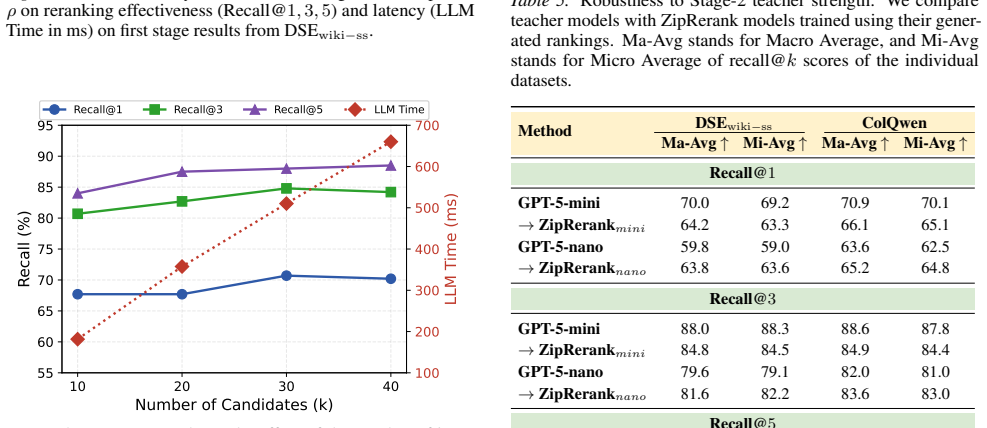
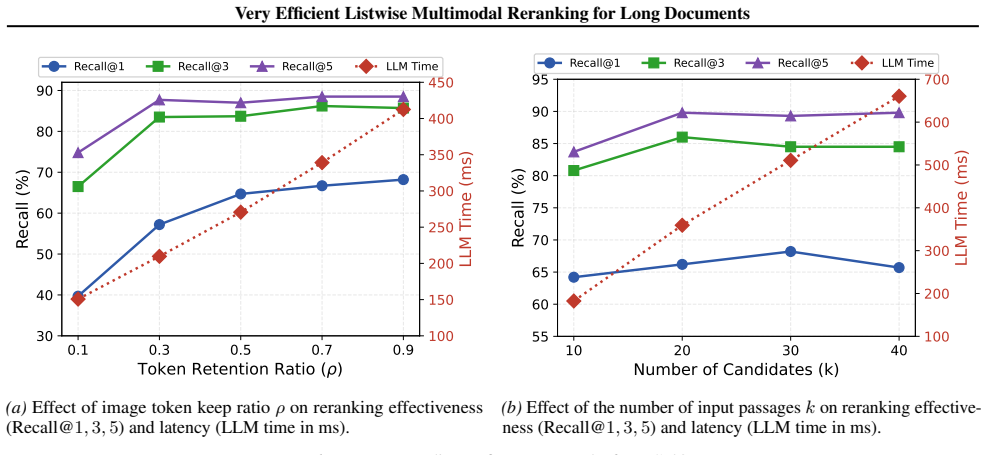
- [Experiments] Experiments section: aggregate benchmark results are presented without reported statistical significance tests, exact train/validation/test splits for MMDocIR, or implementation details of the early-interaction module and single-pass scorer, which are required to substantiate the latency gains and performance parity with SOTA rerankers.
minor comments (1)
- The abstract states that code is available at https://github.com/dukesun99/ZipRerank; confirming that the repository includes the exact training scripts and model checkpoints used for the reported numbers would aid verification.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of our training strategy and experimental reporting that we will address to strengthen the paper. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (two-stage training): the claim that listwise pretraining on rendered text images followed by VLM-distilled finetuning preserves ranking quality on real long multimodal documents is load-bearing for the MMDocIR results, yet no ablations are described that test transfer to documents containing non-textual visuals (charts, photos, complex layouts) absent from the rendered-text pretraining data.
Authors: We acknowledge the value of explicit ablations to support the transfer claim. The finetuning stage is performed on the MMDocIR training set, which contains real long documents with charts, photos, and complex layouts, allowing adaptation beyond text-only pretraining. To directly test preservation of ranking quality, we will add ablation studies in the revised manuscript comparing models with and without the rendered-text pretraining stage, evaluated on MMDocIR subsets stratified by visual complexity (e.g., text-heavy vs. chart/photo-heavy documents). These results will be reported in §3 and the experiments section. revision: yes
-
Referee: [Experiments] Experiments section: aggregate benchmark results are presented without reported statistical significance tests, exact train/validation/test splits for MMDocIR, or implementation details of the early-interaction module and single-pass scorer, which are required to substantiate the latency gains and performance parity with SOTA rerankers.
Authors: We agree these details are essential for reproducibility and validating the claims. In the revised manuscript, we will update the Experiments section to report: (i) statistical significance tests (e.g., paired bootstrap or t-tests with p-values) for all main results against baselines; (ii) the exact train/validation/test splits used from MMDocIR; and (iii) expanded implementation details, including architecture specifications, hyperparameters, and pseudocode for the query-image early interaction module and single-pass scorer (moved to an appendix if needed for space). The open-sourced code already implements these, and we will cross-reference it explicitly. revision: yes
Circularity Check
No circularity: empirical architecture and benchmark results
full rationale
The paper describes an engineering proposal (lightweight query-image interaction plus single-pass scoring) trained via a two-stage process (rendered-text pretraining followed by VLM distillation) and validated through direct comparisons on the MMDocIR benchmark. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted parameters, self-citations, or renamed inputs. All load-bearing claims rest on external experimental measurements rather than internal tautologies.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-language models can effectively process rendered text images for pretraining
- domain assumption VLM-teacher soft rankings provide useful supervision for multimodal finetuning
Reference graph
Works this paper leans on
-
[1]
FIRST : Faster Improved Listwise Reranking with Single Token Decoding
Gangi Reddy, Revanth and Doo, JaeHyeok and Xu, Yifei and Sultan, Md Arafat and Swain, Deevya and Sil, Avirup and Ji, Heng. FIRST : Faster Improved Listwise Reranking with Single Token Decoding. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.491
-
[2]
arXiv preprint arXiv:2411.05508 , year=
An Early FIRST Reproduction and Improvements to Single-Token Decoding for Fast Listwise Reranking , author=. arXiv preprint arXiv:2411.05508 , year=
-
[3]
RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze! , author=. arXiv preprint arXiv:2312.02724 , year=
-
[4]
Proceedings of the 22nd international conference on Machine learning , pages=
Learning to rank using gradient descent , author=. Proceedings of the 22nd international conference on Machine learning , pages=
-
[5]
MMD oc IR : Benchmarking Multimodal Retrieval for Long Documents
Dong, Kuicai and Chang, Yujing and Goh Xin Deik, Derrick and Li, Dexun and Tang, Ruiming and Liu, Yong. MMD oc IR : Benchmarking Multimodal Retrieval for Long Documents. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025
work page 2025
-
[6]
arXiv preprint arXiv:2506.12364 , year=
MM-R5: MultiModal Reasoning-Enhanced ReRanker via Reinforcement Learning for Document Retrieval , author=. arXiv preprint arXiv:2506.12364 , year=
-
[7]
Scaling Beyond Context: A Survey of Multimodal Retrieval-Augmented Generation for Document Understanding , author=. arXiv preprint arXiv:2510.15253 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Ma, Yubo and Li, Jinsong and Zang, Yuhang and Wu, Xiaobao and Dong, Xiaoyi and Zhang, Pan and Cao, Yuhang and Duan, Haodong and Wang, Jiaqi and Cao, Yixin and Sun, Aixin. Towards Storage-Efficient Visual Document Retrieval: An Empirical Study on Reducing Patch-Level Embeddings. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi...
-
[9]
Hierarchical multimodal transformers for multipage docvqa , author=. Pattern Recognition , volume=
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , pages =
Ryota Tanaka and Kyosuke Nishida and Kosuke Nishida and Taku Hasegawa and Itsumi Saito and Kuniko Saito , title =. Proceedings of the AAAI Conference on Artificial Intelligence , pages =
-
[11]
Towards Complex Document Understanding By Discrete Reasoning , booktitle =
Fengbin Zhu and Wenqiang Lei and Fuli Feng and Chao Wang and Haozhou Zhang and Tat. Towards Complex Document Understanding By Discrete Reasoning , booktitle =
-
[12]
SciQAG: A Framework for Auto-Generated Science Question Answering Dataset with Fine-grained Evaluation , author=. 2024 , eprint=
work page 2024
-
[13]
Document Understanding Dataset and Evaluation
Jordy Van Landeghem and Rafal Powalski and Rub. Document Understanding Dataset and Evaluation
-
[14]
Dan Hendrycks and Collin Burns and Anya Chen and Spencer Ball , title =. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks , year =
-
[15]
Unifying Multimodal Retrieval via Document Screenshot Embedding
Ma, Xueguang and Lin, Sheng-Chieh and Li, Minghan and Chen, Wenhu and Lin, Jimmy. Unifying Multimodal Retrieval via Document Screenshot Embedding. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024
work page 2024
-
[16]
The Thirteenth International Conference on Learning Representations , year=
ColPali: Efficient Document Retrieval with Vision Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[17]
Qwen3-VL Technical Report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
2013 12th International Conference on Document Analysis and Recognition , pages=
Multi-modal information integration for document retrieval , author=. 2013 12th International Conference on Document Analysis and Recognition , pages=. 2013 , organization=
work page 2013
-
[19]
arXiv preprint arXiv:2410.02729 , year=
Unified Multimodal Interleaved Document Representation for Retrieval , author=. arXiv preprint arXiv:2410.02729 , year=
-
[20]
ACM Computing Surveys , volume=
Visual question answering: A survey of methods, datasets, evaluation, and challenges , author=. ACM Computing Surveys , volume=
-
[21]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Retrieving Multimodal Information for Augmented Generation: A Survey , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
work page 2023
-
[22]
arXiv preprint arXiv:2504.08748 , year=
A survey of multimodal retrieval-augmented generation , author=. arXiv preprint arXiv:2504.08748 , year=
-
[23]
Proceedings of the IEEE international conference on computer vision , pages=
Vqa: Visual question answering , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[24]
European Conference on Information Retrieval , pages=
Cross-modal retrieval for knowledge-based visual question answering , author=. European Conference on Information Retrieval , pages=. 2024 , organization=
work page 2024
-
[25]
The state of the art for cross-modal retrieval: A survey , author=. IEEE Access , volume=
-
[26]
Mmsearch: Benchmarking the potential of large models as multi-modal search engines , author=. arXiv preprint arXiv:2409.12959 , year=
-
[27]
arXiv preprint arXiv:2407.21439 , year=
Mllm is a strong reranker: Advancing multimodal retrieval-augmented generation via knowledge-enhanced reranking and noise-injected training , author=. arXiv preprint arXiv:2407.21439 , year=
-
[28]
arXiv preprint arXiv:2501.04695 , year=
Re-ranking the context for multimodal retrieval augmented generation , author=. arXiv preprint arXiv:2501.04695 , year=
-
[29]
arXiv preprint arXiv:2507.20198 , year=
When tokens talk too much: A survey of multimodal long-context token compression across images, videos, and audios , author=. arXiv preprint arXiv:2507.20198 , year=
-
[30]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Voco-llama: Towards vision compression with large language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[31]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Visionzip: Longer is better but not necessary in vision language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[32]
The Eleventh International Conference on Learning Representations , year=
Token Merging: Your ViT But Faster , author=. The Eleventh International Conference on Learning Representations , year=
-
[33]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[34]
Forty-second International Conference on Machine Learning , year=
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference , author=. Forty-second International Conference on Machine Learning , year=
-
[35]
Song, Dingjie and Wang, Wenjun and Chen, Shunian and Wang, Xidong and Guan, Michael X. and Wang, Benyou. Less is More: A Simple yet Effective Token Reduction Method for Efficient Multi-modal LLM s. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[36]
arXiv preprint arXiv:2501.09532 , year=
AdaFV: Rethinking of Visual-Language alignment for VLM acceleration , author=. arXiv preprint arXiv:2501.09532 , year=
-
[37]
European Conference on Computer Vision , pages=
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[38]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[39]
RoFormer: Enhanced Transformer with Rotary Position Embedding,
RoFormer: Enhanced transformer with Rotary Position Embedding , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.neucom.2023.127063 , url =
-
[40]
arXiv preprint arXiv:2508.07995 , year=
Diver: A multi-stage approach for reasoning-intensive information retrieval , author=. arXiv preprint arXiv:2508.07995 , year=
-
[41]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. arXiv preprint arXiv:2506.05176 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Rankllm: A python package for reranking with llms , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[43]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[44]
Mteb: Massive text embedding benchmark , author=. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
-
[45]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models , author=. arXiv preprint arXiv:2104.08663 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Passage Re-ranking with BERT , author=. arXiv preprint arXiv:1901.04085 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[47]
A o E : Angle-optimized Embeddings for Semantic Textual Similarity
Li, Xianming and Li, Jing. A o E : Angle-optimized Embeddings for Semantic Textual Similarity. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). 2024
work page 2024
-
[48]
Reimers, Nils and Gurevych, Iryna , booktitle=
-
[49]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Text embeddings by weakly-supervised contrastive pre-training , author=. arXiv preprint arXiv:2212.03533 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation , author=. arXiv preprint arXiv:2402.03216 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
IEEE Transactions on Knowledge and Data Engineering , volume=
Approximate nearest neighbor search on high dimensional data—experiments, analyses, and improvement , author=. IEEE Transactions on Knowledge and Data Engineering , volume=
-
[52]
Dense Passage Retrieval for Open-Domain Question Answering , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
work page 2020
-
[53]
arXiv preprint arXiv:2309.15088 , year=
Rankvicuna: Zero-shot listwise document reranking with open-source large language models , author=. arXiv preprint arXiv:2309.15088 , year=
-
[54]
ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
Reasonrank: Empowering passage ranking with strong reasoning ability , author=. arXiv preprint arXiv:2508.07050 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
European Conference on Information Retrieval , pages=
Guiding retrieval using llm-based listwise rankers , author=. European Conference on Information Retrieval , pages=. 2025 , organization=
work page 2025
-
[56]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Flashattention-2: Faster attention with better parallelism and work partitioning , author=. arXiv preprint arXiv:2307.08691 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Colbert: Efficient and effective passage search via contextualized late interaction over bert , author=. Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
-
[59]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
arXiv preprint arXiv:2406.10774 , year=
Quest: Query-aware sparsity for efficient long-context llm inference , author=. arXiv preprint arXiv:2406.10774 , year=
-
[62]
The Thirteenth International Conference on Learning Representations , year=
Omnikv: Dynamic context selection for efficient long-context llms , author=. The Thirteenth International Conference on Learning Representations , year=
-
[63]
Proceedings of the ACM on Management of Data , volume=
Pqcache: Product quantization-based kvcache for long context llm inference , author=. Proceedings of the ACM on Management of Data , volume=
-
[64]
Proceedings of the VLDB Endowment , volume=
DiversiNews: Enriching News Consumption with Relevant Yet Diverse News Articles Retrieval , author=. Proceedings of the VLDB Endowment , volume=
-
[65]
The Thirteenth International Conference on Learning Representations (ICLR) , year=
A General Framework for Producing Interpretable Semantic Text Embeddings , author=. The Thirteenth International Conference on Learning Representations (ICLR) , year=
-
[66]
PRISM: A Framework for Producing Interpretable Political Bias Embeddings with Political-Aware Cross-Encoder , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2025 , url=
work page 2025
-
[67]
Don't Reinvent the Wheel: Efficient Instruction-Following Text Embedding based on Guided Space Transformation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2025 , url=
work page 2025
-
[68]
arXiv preprint arXiv:2506.08354 , year=
Text embeddings should capture implicit semantics, not just surface meaning , author=. arXiv preprint arXiv:2506.08354 , year=
-
[69]
arXiv preprint arXiv:2512.00852 , year=
One Swallow Does Not Make a Summer: Understanding Semantic Structures in Embedding Spaces , author=. arXiv preprint arXiv:2512.00852 , year=
-
[70]
2017 IEEE 33rd International Conference on Data Engineering (ICDE) , pages=
Reverse query-aware locality-sensitive hashing for high-dimensional furthest neighbor search , author=. 2017 IEEE 33rd International Conference on Data Engineering (ICDE) , pages=
work page 2017
-
[71]
Accurate and fast asymmetric locality-sensitive hashing scheme for maximum inner product search , author=. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD) , pages=
-
[72]
International Conference on Machine Learning , pages=
Sublinear time nearest neighbor search over generalized weighted space , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[73]
Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (SIGMOD) , pages=
Locality-sensitive hashing scheme based on longest circular co-substring , author=. Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (SIGMOD) , pages=
work page 2020
-
[74]
Proceedings of the 2021 International Conference on Management of Data (SIGMOD) , pages=
Point-to-hyperplane nearest neighbor search beyond the unit hypersphere , author=. Proceedings of the 2021 International Conference on Management of Data (SIGMOD) , pages=
work page 2021
-
[75]
Huang, Qiang and Wang, Yanhao and Tung, Anthony KH , booktitle=
-
[76]
2023 IEEE 39th International Conference on Data Engineering (ICDE) , pages=
Lightweight-yet-efficient: Revitalizing ball-tree for point-to-hyperplane nearest neighbor search , author=. 2023 IEEE 39th International Conference on Data Engineering (ICDE) , pages=
work page 2023
-
[77]
arXiv preprint arXiv:2402.13858 , year=
Diversity-Aware k -Maximum Inner Product Search Revisited , author=. arXiv preprint arXiv:2402.13858 , year=
-
[78]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
Knowledge Completes the Vision: A Multimodal Entity-aware Retrieval-Augmented Generation Framework for News Image Captioning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[79]
arXiv preprint arXiv:2603.06213 , year=
Cut to the Chase: Training-free Multimodal Summarization via Chain-of-Events , author=. arXiv preprint arXiv:2603.06213 , year=
-
[80]
MG$^2$-RAG: Multi-Granularity Graph for Multimodal Retrieval-Augmented Generation
MG ^2 -RAG: Multi-Granularity Graph for Multimodal Retrieval-Augmented Generation , author=. arXiv preprint arXiv:2604.04969 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.