UniGeoSeg: Towards Unified Open-World Segmentation for Geospatial Scenes
Pith reviewed 2026-05-17 04:34 UTC · model grok-4.3
The pith
UniGeoSeg unifies referring, interactive, and reasoning segmentation for remote sensing images through a new million-scale dataset and multi-task training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
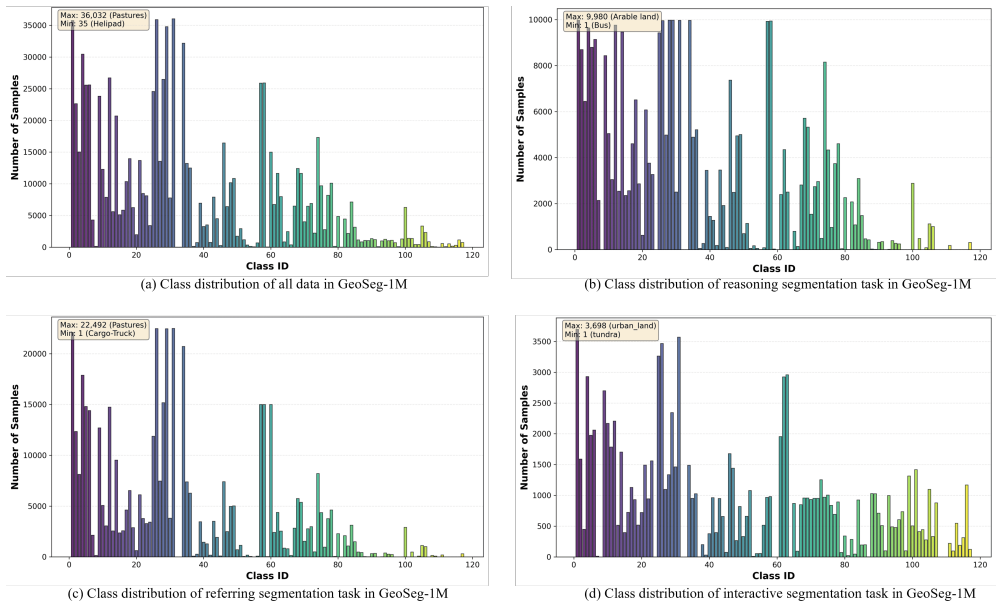
We introduce GeoSeg-1M containing 1.1M image-mask-instruction triplets across 117 categories and curate GeoSeg-Bench to test contextual understanding, then present UniGeoSeg as a baseline framework that achieves state-of-the-art results on the new benchmark and public datasets while showing strong zero-shot generalization through its task-aware components and training strategy.
What carries the argument
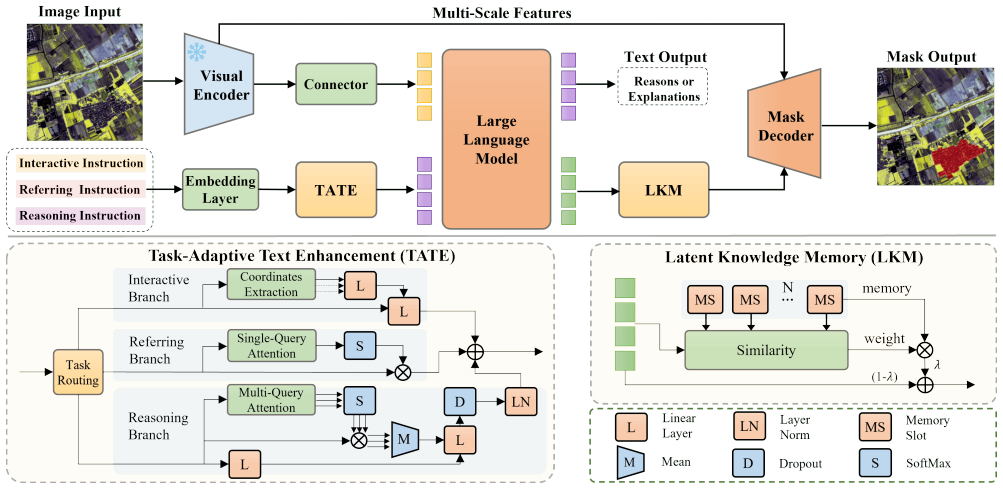
The UniGeoSeg framework that incorporates task-aware text enhancement, latent knowledge memory, and progressive training to enable multi-task learning over referring, interactive, and reasoning segmentation instructions.
If this is right
- UniGeoSeg reaches state-of-the-art performance on GeoSeg-Bench and multiple public remote-sensing benchmarks.
- The same model handles referring, interactive, and reasoning segmentation within one training run.
- Strong zero-shot transfer occurs to unseen instructions and complex geospatial scenes.
- Multi-task learning improves contextual understanding compared with task-specific models.
Where Pith is reading between the lines
- The automatic data-synthesis approach could be reused to scale instruction data in other vision domains that currently lack large paired instruction sets.
- Unified models of this type might reduce the need for domain experts to maintain separate segmentation tools for different geospatial applications.
- If the memory and enhancement modules prove reusable, they could serve as drop-in components for open-world segmentation outside remote sensing.
Load-bearing premise
The automatic mask filtering and instruction generation pipeline creates high-quality, unbiased triplets that support effective multi-task learning and real-world generalization.
What would settle it
Run UniGeoSeg on a fresh collection of geospatial images paired with human-written instructions that were never seen during the automatic pipeline and measure whether zero-shot accuracy falls substantially below the reported levels on GeoSeg-Bench.
Figures













read the original abstract
Instruction-driven segmentation in remote sensing generates masks from guidance, offering great potential for accessible and generalizable applications. However, existing methods suffer from fragmented task formulations and limited instruction data, hindering effective understanding and generalization. To address these issues, we introduce GeoSeg-1M, the first million-scale dataset for remote sensing instruction-driven segmentation, constructed via an automatic mask filtering and instruction generation pipeline that synthesizes referring, interactive, and reasoning segmentation instructions from multiple public datasets. GeoSeg-1M contains 590K images, 117 categories, and 1.1M image-mask-instruction triplets. Building upon this foundation, we further curate GeoSeg-Bench, a challenging benchmark designed to evaluate contextual understanding and reasoning capabilities across diverse instruction-driven tasks and complex geospatial scenes. Furthermore, we present UniGeoSeg, a unified framework that serves as a strong baseline, incorporating task-aware text enhancement, latent knowledge memory, and a progressive training strategy to facilitate multi-task learning. Extensive experiments demonstrate the state-of-the-art performance of UniGeoSeg across GeoSeg-Bench and diverse public benchmarks, while exhibiting strong zero-shot generalization. Datasets and source code were released at https://github.com/MiliLab/UniGeoSeg.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents GeoSeg-1M, a 1.1M-triplet dataset for instruction-driven segmentation in remote sensing synthesized via an automatic mask-filtering and instruction-generation pipeline from existing public sources; it also introduces the GeoSeg-Bench evaluation suite and the UniGeoSeg model that combines task-aware text enhancement, latent knowledge memory, and progressive multi-task training. The central claims are that UniGeoSeg achieves state-of-the-art results on GeoSeg-Bench and diverse public benchmarks while demonstrating strong zero-shot generalization.
Significance. If the data-synthesis quality and experimental claims are substantiated, the work would supply the first large-scale resource for unified referring, interactive, and reasoning segmentation in geospatial imagery and a practical baseline architecture, thereby enabling more systematic study of multi-task and open-world capabilities in remote-sensing vision.
major comments (2)
- [Section 3] Section 3 (GeoSeg-1M Construction): the automatic mask filtering and instruction generation pipeline is load-bearing for all downstream claims, yet the manuscript reports neither human agreement rates on generated triplets, quantitative error analysis of semantic mismatches between text and masks, nor ablations on pipeline variants. Without these, performance gains on GeoSeg-Bench cannot be confidently attributed to UniGeoSeg rather than residual label noise or synthesis artifacts.
- [Section 5] Section 5 (Experiments): the SOTA and zero-shot results are presented without the full set of ablation studies on the individual components (task-aware text enhancement, latent knowledge memory, progressive training) or detailed verification of the zero-shot evaluation protocol, making it difficult to isolate the contribution of each design choice to the reported gains.
minor comments (2)
- [Figure 2] Figure 2 and the accompanying text use inconsistent terminology for the three instruction types (referring vs. interactive vs. reasoning); a single canonical naming should be adopted throughout.
- [Related Work] The manuscript does not cite prior large-scale remote-sensing segmentation datasets (e.g., LoveDA, iSAID) when discussing the construction of GeoSeg-1M; adding these references would clarify the novelty of the synthesis approach.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major comment in detail below and have revised the paper accordingly to enhance the validation of our dataset construction and experimental analysis.
read point-by-point responses
-
Referee: [Section 3] Section 3 (GeoSeg-1M Construction): the automatic mask filtering and instruction generation pipeline is load-bearing for all downstream claims, yet the manuscript reports neither human agreement rates on generated triplets, quantitative error analysis of semantic mismatches between text and masks, nor ablations on pipeline variants. Without these, performance gains on GeoSeg-Bench cannot be confidently attributed to UniGeoSeg rather than residual label noise or synthesis artifacts.
Authors: We fully agree that rigorous validation of the data synthesis pipeline is essential to substantiate our claims. Although the original manuscript focused on describing the scalable automatic pipeline, we recognize the need for human validation and error analysis. In the revised version, we have incorporated a human study involving expert annotators evaluating a sample of generated triplets for instruction-mask alignment, reporting high agreement rates. We also add a quantitative breakdown of potential semantic mismatches and ablations comparing different pipeline configurations (e.g., with and without specific filtering steps). These additions are placed in Section 3 and the supplementary material, allowing readers to better assess the dataset quality and attribute improvements to the proposed UniGeoSeg model. revision: yes
-
Referee: [Section 5] Section 5 (Experiments): the SOTA and zero-shot results are presented without the full set of ablation studies on the individual components (task-aware text enhancement, latent knowledge memory, progressive training) or detailed verification of the zero-shot evaluation protocol, making it difficult to isolate the contribution of each design choice to the reported gains.
Authors: We thank the referee for this suggestion to strengthen the experimental section. The original manuscript included some component analysis, but we agree that a more comprehensive set of ablations is warranted. In the revision, we have added detailed ablation studies for each proposed component—task-aware text enhancement, latent knowledge memory, and progressive multi-task training—showing their individual and combined impacts on performance. We have also expanded the description of the zero-shot evaluation protocol, including specifics on category and scene selection to confirm no overlap with training data. These updates are integrated into Section 5, with additional results in the appendix. revision: yes
Circularity Check
No circularity: empirical dataset construction and benchmark evaluation are self-contained
full rationale
The paper describes an automatic pipeline to synthesize GeoSeg-1M triplets from existing public datasets, curates GeoSeg-Bench from the same sources, and reports experimental SOTA results for UniGeoSeg on both the new benchmark and external public datasets. No equations, fitted parameters, or first-principles derivations are present that reduce by construction to the inputs. Claims rest on empirical performance rather than self-definitional renaming, fitted-input predictions, or load-bearing self-citations. The central results therefore remain independent of the circularity patterns enumerated in the guidelines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large-scale synthetic instruction data generated from public datasets can train models that generalize to real geospatial scenes
Forward citations
Cited by 3 Pith papers
-
AgroVG: A Large-Scale Multi-Source Benchmark for Agricultural Visual Grounding
AgroVG is a new multi-source benchmark for agricultural visual grounding formulated as generalized set prediction, with protocols for box and mask grounding across single-target, multi-target, and target-absent querie...
-
UHR-Micro: Diagnosing and Mitigating the Resolution Illusion in Earth Observation VLMs
VLMs show a resolution illusion on UHR Earth observation imagery where higher resolution does not improve micro-target perception; UHR-Micro benchmark and MAP-Agent address this via evidence-centered active inspection.
-
Think in Latent Thoughts: A New Paradigm for Gloss-Free Sign Language Translation
A new SLT framework uses latent thoughts as a middle reasoning layer and plan-then-ground decoding to improve coherence and faithfulness in gloss-free sign language translation.
Reference graph
Works this paper leans on
-
[1]
Generalizable disaster damage assessment via change detection with vision foun- dation model
Kyeongjin Ahn, Sungwon Han, Sungwon Park, Jihee Kim, Sangyoon Park, and Meeyoung Cha. Generalizable disaster damage assessment via change detection with vision foun- dation model. InProceedings of the AAAI Conference on Artificial Intelligence, pages 27784–27792, 2025. 1
work page 2025
-
[2]
Skyscapes fine-grained se- mantic understanding of aerial scenes
Seyed Majid Azimi, Corentin Henry, Lars Sommer, Arne Schumann, and Eleonora Vig. Skyscapes fine-grained se- mantic understanding of aerial scenes. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 7393–7403, 2019. 3
work page 2019
-
[3]
Mohammad R Bayanlou and Mehdi Khoshboresh- Masouleh. Multi-task learning from fixed-wing uav images for 2d/3d city modeling.arXiv preprint arXiv:2109.00918,
-
[4]
Yoshua Bengio, J ´erˆome Louradour, Ronan Collobert, and Ja- son Weston. Curriculum learning. InProceedings of the 26th annual international conference on machine learning, pages 41–48, 2009. 6
work page 2009
-
[5]
Hanbo Bi, Yingchao Feng, Yongqiang Mao, Jianning Pei, Wenhui Diao, Hongqi Wang, and Xian Sun. Agmtr: Agent mining transformer for few-shot segmentation in remote sensing.International Journal of Computer Vision, 133(4): 1780–1807, 2025. 1
work page 2025
-
[6]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al. Deepseek llm: Scaling open- source language models with longtermism.arXiv preprint arXiv:2401.02954, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, et al. Internlm2 technical report.arXiv preprint arXiv:2403.17297, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Javiera Castillo-Navarro, Bertrand Le Saux, Alexandre Boulch, Nicolas Audebert, and S ´ebastien Lef `evre. Semi- supervised semantic segmentation in earth observation: The minifrance suite, dataset analysis and multi-task network study.Machine Learning, 111(9):3125–3160, 2022. 3, 1, 8
work page 2022
-
[9]
Keyan Chen, Jiafan Zhang, Chenyang Liu, Zhengxia Zou, and Zhenwei Shi. Rsrefseg: Referring remote sensing im- age segmentation with foundation models.arXiv preprint arXiv:2501.06809, 2025. 1
-
[10]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 10
work page 2024
-
[11]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022. 6
work page 2022
-
[12]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023. 10
work page 2023
-
[13]
Gordon Christie, Neil Fendley, James Wilson, and Ryan Mukherjee. Functional map of the world. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6172–6180, 2018. 3
work page 2018
-
[14]
Deepglobe 2018: A challenge to parse the earth through satellite images
Ilke Demir, Krzysztof Koperski, David Lindenbaum, Guan Pang, Jing Huang, Saikat Basu, Forest Hughes, Devis Tuia, and Ramesh Raskar. Deepglobe 2018: A challenge to parse the earth through satellite images. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 172–181, 2018. 3, 1, 8
work page 2018
-
[15]
Cross-Modal Bidi- rectional Interaction Model for Referring Remote Sensing Image Segmentation, 2025
Zhe Dong, Yuzhe Sun, Tianzhu Liu, Wangmeng Zuo, and Yanfeng Gu. Cross-modal bidirectional interaction model for referring remote sensing image segmentation.arXiv preprint arXiv:2410.08613, 2024. 3
-
[16]
Visdrone-det2019: The vision meets drone ob- ject detection in image challenge results
Dawei Du, Pengfei Zhu, Longyin Wen, Xiao Bian, Haibin Lin, Qinghua Hu, Tao Peng, Jiayu Zheng, Xinyao Wang, Yue Zhang, et al. Visdrone-det2019: The vision meets drone ob- ject detection in image challenge results. InProceedings of the IEEE/CVF international conference on computer vision workshops, pages 0–0, 2019. 3
work page 2019
-
[17]
Tianyi Gao, Wei Ao, Xing-ao Wang, Yuanhao Zhao, Ping Ma, Mengjie Xie, Hang Fu, Jinchang Ren, and Zhi Gao. Enrich distill and fuse: Generalized few-shot semantic seg- mentation in remote sensing leveraging foundation model’s assistance. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2771– 2780, 2024. 1
work page 2024
-
[18]
Anatol Garioud, Nicolas Gonthier, Loic Landrieu, Apolline De Wit, Marion Valette, Marc Poup ´ee, S´ebastien Giordano, et al. Flair: a country-scale land cover semantic segmen- tation dataset from multi-source optical imagery.Advances in Neural Information Processing Systems, 36:16456–16482,
-
[19]
Seg- mentation from natural language expressions
Ronghang Hu, Marcus Rohrbach, and Trevor Darrell. Seg- mentation from natural language expressions. InEuropean conference on computer vision, pages 108–124. Springer,
-
[20]
Yuan Hu, Jianlong Yuan, Congcong Wen, Xiaonan Lu, Yu Liu, and Xiang Li. Rsgpt: A remote sensing vision language model and benchmark.ISPRS Journal of Photogrammetry and Remote Sensing, 224:272–286, 2025. 2
work page 2025
-
[21]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Segment anything in high quality
Lei Ke, Mingqiao Ye, Martin Danelljan, Yifan Liu, Yu-Wing Tai, Chi-Keung Tang, and Fisher Yu. Segment anything in high quality. InNeurIPS, 2023. 8
work page 2023
-
[23]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- 9 head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 1, 2
work page 2023
-
[24]
Geochat: Grounded large vision-language model for remote sensing
Kartik Kuckreja, Muhammad Sohail Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and Fahad Shahbaz Khan. Geochat: Grounded large vision-language model for remote sensing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27831– 27840, 2024. 2, 8
work page 2024
-
[25]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9579–9589, 2024. 2, 4, 6, 7, 8, 10
work page 2024
-
[26]
Ke Li, Gang Wan, Gong Cheng, Liqiu Meng, and Junwei Han. Object detection in optical remote sensing images: A survey and a new benchmark.ISPRS journal of photogram- metry and remote sensing, 159:296–307, 2020. 3, 2, 8
work page 2020
-
[27]
Segearth-ov: Towards training-free open-vocabulary segmentation for remote sens- ing images
Kaiyu Li, Ruixun Liu, Xiangyong Cao, Xueru Bai, Feng Zhou, Deyu Meng, and Zhi Wang. Segearth-ov: Towards training-free open-vocabulary segmentation for remote sens- ing images. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 10545–10556, 2025. 2
work page 2025
-
[28]
Ke Li, Di Wang, Ting Wang, Fuyu Dong, Yiming Zhang, Luyao Zhang, Xiangyu Wang, Shaofeng Li, and Quan Wang. Rsvg-zeroov: Exploring a training-free framework for zero- shot open-vocabulary visual grounding in remote sensing im- ages.arXiv preprint arXiv:2509.18711, 2025. 8
-
[29]
SegEarth-R1: Geospatial Pixel Reasoning via Large Language Model, 2025
Kaiyu Li, Zepeng Xin, Li Pang, Chao Pang, Yupeng Deng, Jing Yao, Guisong Xia, Deyu Meng, Zhi Wang, and Xiangy- ong Cao. Segearth-r1: Geospatial pixel reasoning via large language model.arXiv preprint arXiv:2504.09644, 2025. 1, 2, 3, 4, 5, 6, 7, 8, 10, 11
-
[30]
Referring image seg- mentation via recurrent refinement networks
Ruiyu Li, Kaican Li, Yi-Chun Kuo, Michelle Shu, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia. Referring image seg- mentation via recurrent refinement networks. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5745–5753, 2018. 2
work page 2018
-
[31]
Textbooks Are All You Need II: phi-1.5 technical report
Yuanzhi Li, S ´ebastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. Textbooks are all you need ii: phi-1.5 technical report.arXiv preprint arXiv:2309.05463, 2023. 6, 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, and Jun Zhou. Re- moteclip: A vision language foundation model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 62:1–16, 2024. 10
work page 2024
-
[33]
Rotated multi-scale interaction network for referring remote sensing image seg- mentation
Sihan Liu, Yiwei Ma, Xiaoqing Zhang, Haowei Wang, Ji- ayi Ji, Xiaoshuai Sun, and Rongrong Ji. Rotated multi-scale interaction network for referring remote sensing image seg- mentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26658– 26668, 2024. 1, 2, 3, 4, 8, 10, 11
work page 2024
-
[34]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 6, 9, 10
work page 2021
-
[35]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Xiaoqiang Lu, Long Sun, Lingling Li, Licheng Jiao, Yuting Yang, Zhongjian Huang, Jinming Chai, Xu Liu, Fang Liu, Wenping Ma, et al. Rrsecs: Referring remote sensing expres- sion comprehension and segmentation.IEEE Geoscience and Remote Sensing Magazine, 2025. 1, 2
work page 2025
-
[37]
Junwei Luo, Zhen Pang, Yongjun Zhang, Tingzhu Wang, Linlin Wang, Bo Dang, Jiangwei Lao, Jian Wang, Jingdong Chen, Yihua Tan, et al. Skysensegpt: A fine-grained in- struction tuning dataset and model for remote sensing vision- language understanding.arXiv preprint arXiv:2406.10100,
-
[38]
Lhrs-bot: Empowering remote sensing with vgi-enhanced large multimodal language model
Dilxat Muhtar, Zhenshi Li, Feng Gu, Xueliang Zhang, and Pengfeng Xiao. Lhrs-bot: Empowering remote sensing with vgi-enhanced large multimodal language model. In European Conference on Computer Vision, pages 440–457. Springer, 2024. 2
work page 2024
-
[39]
Sayan Nag, Koustava Goswami, and Srikrishna Karanam. Safari: Adaptive s equence tr a ns f ormer for we a kly su- pervised r eferring expression segmentat i on. InEuropean Conference on Computer Vision, pages 485–503. Springer,
-
[40]
Ruizhe Ou, Yuan Hu, Fan Zhang, Jiaxin Chen, and Yu Liu. Geopix: A multimodal large language model for pixel-level image understanding in remote sensing.IEEE Geoscience and Remote Sensing Magazine, 2025. 2, 4, 6, 10
work page 2025
-
[41]
Locate anything on earth: Advancing open-vocabulary ob- ject detection for remote sensing community
Jiancheng Pan, Yanxing Liu, Yuqian Fu, Muyuan Ma, Jiahao Li, Danda Pani Paudel, Luc Van Gool, and Xiaomeng Huang. Locate anything on earth: Advancing open-vocabulary ob- ject detection for remote sensing community. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 6281–6289, 2025. 2
work page 2025
-
[42]
Jerome Quenum, Wen-Han Hsieh, Tsung-Han Wu, Ritwik Gupta, Trevor Darrell, and David M Chan. Lisat: Language- instructed segmentation assistant for satellite imagery.arXiv preprint arXiv:2505.02829, 2025. 4, 6, 10
-
[43]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2, 10
work page 2021
-
[44]
Sam 2: Seg- ment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Seg- ment anything in images and videos. InThe Thirteenth In- ternational Conference on Learning Representations, 2024. 8
work page 2024
-
[45]
Pixellm: Pixel reasoning with large multimodal model
Zhongwei Ren, Zhicheng Huang, Yunchao Wei, Yao Zhao, Dongmei Fu, Jiashi Feng, and Xiaojie Jin. Pixellm: Pixel reasoning with large multimodal model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26374–26383, 2024. 4, 6, 7, 10
work page 2024
-
[46]
Large scale high-resolution land cover mapping with multi- resolution data
Caleb Robinson, Le Hou, Kolya Malkin, Rachel Soobit- sky, Jacob Czawlytko, Bistra Dilkina, and Nebojsa Jojic. Large scale high-resolution land cover mapping with multi- resolution data. InProceedings of the IEEE/CVF Conference 10 on Computer Vision and Pattern Recognition, pages 12726– 12735, 2019. 3, 1, 8
work page 2019
-
[47]
Antonis Savva, Christos Kyrkou, Panayiotis Kolios, and Theocharis Theocharides. Advances in remote sensing and ai for vegetation monitoring in power line corridors: A re- view and future directions: A review and future directions. IEEE Geoscience and Remote Sensing Magazine, 2025. 1
work page 2025
-
[48]
Geopixel: Pixel grounding large multimodal model in remote sens- ing
Akashah Shabbir, Mohammed Zumri, Mohammed Ben- namoun, Fahad Shahbaz Khan, and Salman Khan. Geopixel: Pixel grounding large multimodal model in remote sens- ing. InForty-second International Conference on Machine Learning, 2025. 2, 4, 6, 7, 10
work page 2025
-
[49]
Haozhan Shen, Tiancheng Zhao, Mingwei Zhu, and Jian- wei Yin. Groundvlp: Harnessing zero-shot visual ground- ing from vision-language pre-training and open-vocabulary object detection. InProceedings of the AAAI Conference on Artificial Intelligence, pages 4766–4775, 2024. 8
work page 2024
-
[50]
Key-word-aware network for referring expression image seg- mentation
Hengcan Shi, Hongliang Li, Fanman Meng, and Qingbo Wu. Key-word-aware network for referring expression image seg- mentation. InProceedings of the European Conference on Computer Vision (ECCV), pages 38–54, 2018. 2
work page 2018
-
[51]
Qian Shi, Da He, Zhengyu Liu, Xiaoping Liu, and Jingqian Xue. Globe230k: A benchmark dense-pixel annotation dataset for global land cover mapping.Journal of Remote Sensing, 3:0078, 2023. 3, 1, 8
work page 2023
-
[52]
Earthmind: Towards multi-granular and multi- sensor earth observation with large multimodal models,
Yan Shu, Bin Ren, Zhitong Xiong, Danda Pani Paudel, Luc Van Gool, Begum Demir, Nicu Sebe, and Paolo Rota. Earth- mind: Towards multi-granular and multi-sensor earth ob- servation with large multimodal models.arXiv preprint arXiv:2506.01667, 2025. 4, 6, 10
-
[53]
Earthdial: Turning multi-sensory earth observations to interactive dialogues
Sagar Soni, Akshay Dudhane, Hiyam Debary, Mustansar Fiaz, Muhammad Akhtar Munir, Muhammad Sohail Danish, Paolo Fraccaro, Campbell D Watson, Levente J Klein, Fa- had Shahbaz Khan, et al. Earthdial: Turning multi-sensory earth observations to interactive dialogues. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14303–14313, 2025. 2
work page 2025
-
[54]
Xian Sun, Peijin Wang, Zhiyuan Yan, Feng Xu, Ruiping Wang, Wenhui Diao, Jin Chen, Jihao Li, Yingchao Feng, Tao Xu, et al. Fair1m: A benchmark dataset for fine- grained object recognition in high-resolution remote sens- ing imagery.ISPRS Journal of Photogrammetry and Remote Sensing, 184:116–130, 2022. 3, 2, 8
work page 2022
-
[55]
Visual grounding in remote sensing images
Yuxi Sun, Shanshan Feng, Xutao Li, Yunming Ye, Jian Kang, and Xu Huang. Visual grounding in remote sensing images. InProceedings of the 30th ACM International con- ference on Multimedia, pages 404–412, 2022. 3
work page 2022
-
[56]
Xin-Yi Tong, Gui-Song Xia, Qikai Lu, Huangfeng Shen, Shengyang Li, Shucheng You, and Liangpei Zhang. Land- cover classification with high-resolution remote sensing im- ages using transferable deep models.Remote Sensing of En- vironment, 2020. 3, 1, 8
work page 2020
-
[57]
Xin-Yi Tong, Gui-Song Xia, and Xiao Xiang Zhu. Enabling country-scale land cover mapping with meter-resolution satellite imagery.ISPRS Journal of Photogrammetry and Re- mote Sensing, 196:178–196, 2023. 3, 1, 8
work page 2023
-
[58]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Ov-vg: A benchmark for open-vocabulary visual grounding.Neurocomputing, 591:127738, 2024
Chunlei Wang, Wenquan Feng, Xiangtai Li, Guangliang Cheng, Shuchang Lyu, Binghao Liu, Lijiang Chen, and Qi Zhao. Ov-vg: A benchmark for open-vocabulary visual grounding.Neurocomputing, 591:127738, 2024. 8
work page 2024
-
[60]
Di Wang, Jing Zhang, Bo Du, Minqiang Xu, Lin Liu, Dacheng Tao, and Liangpei Zhang. Samrs: Scaling-up re- mote sensing segmentation dataset with segment anything model.Advances in Neural Information Processing Systems, 36:8815–8827, 2023. 1, 6, 2, 8
work page 2023
-
[61]
Fengxiang Wang, Hongzhen Wang, Zonghao Guo, Di Wang, Yulin Wang, Mingshuo Chen, Qiang Ma, Long Lan, Wenjing Yang, Jing Zhang, et al. Xlrs-bench: Could your multimodal llms understand extremely large ultra-high-resolution remote sensing imagery? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14325–14336,
-
[62]
Junjue Wang, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zhong. Loveda: A remote sensing land-cover dataset for domain adaptive semantic segmentation.arXiv preprint arXiv:2110.08733, 2021. 3, 1, 8
-
[63]
Diffusion model is secretly a training-free open vocabulary semantic segmenter
Jinglong Wang, Xiawei Li, Jing Zhang, Qingyuan Xu, Qin Zhou, Qian Yu, Lu Sheng, and Dong Xu. Diffusion model is secretly a training-free open vocabulary semantic segmenter. IEEE Transactions on Image Processing, 2025. 8
work page 2025
-
[64]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 3, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Holitracer: Holistic vectorization of geographic objects from large-size remote sensing imagery
Yu Wang, Bo Dang, Wanchun Li, Wei Chen, and Yansheng Li. Holitracer: Holistic vectorization of geographic objects from large-size remote sensing imagery. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 8482–8491, 2025. 1
work page 2025
-
[66]
Jianzong Wu, Xiangtai Li, Xia Li, Henghui Ding, Yunhai Tong, and Dacheng Tao. Toward robust referring image seg- mentation.IEEE Transactions on Image Processing, 33: 1782–1794, 2024. 2
work page 2024
-
[67]
Gui-Song Xia, Jingwen Hu, Fan Hu, Baoguang Shi, Xiang Bai, Yanfei Zhong, Liangpei Zhang, and Xiaoqiang Lu. Aid: A benchmark data set for performance evaluation of aerial scene classification.IEEE Transactions on Geoscience and Remote Sensing, 55(7):3965–3981, 2017. 3
work page 2017
-
[68]
Dota: A large-scale dataset for object detection in aerial images
Gui-Song Xia, Xiang Bai, Jian Ding, Zhen Zhu, Serge Be- longie, Jiebo Luo, Mihai Datcu, Marcello Pelillo, and Liang- pei Zhang. Dota: A large-scale dataset for object detection in aerial images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3974–3983,
-
[69]
Exploring phrase- level grounding with text-to-image diffusion model
Danni Yang, Ruohan Dong, Jiayi Ji, Yiwei Ma, Haowei Wang, Xiaoshuai Sun, and Rongrong Ji. Exploring phrase- level grounding with text-to-image diffusion model. InEu- ropean Conference on Computer Vision, pages 161–180. Springer, 2024. 8 11
work page 2024
-
[70]
Lavt: Language-aware vision transformer for referring image segmentation
Zhao Yang, Jiaqi Wang, Yansong Tang, Kai Chen, Heng- shuang Zhao, and Philip HS Torr. Lavt: Language-aware vision transformer for referring image segmentation. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18155–18165, 2022. 2
work page 2022
-
[71]
Remotesam: Towards segment anything for earth observa- tion
Liang Yao, Fan Liu, Delong Chen, Chuanyi Zhang, Yijun Wang, Ziyun Chen, Wei Xu, Shimin Di, and Yuhui Zheng. Remotesam: Towards segment anything for earth observa- tion. InProceedings of the 33rd ACM International Confer- ence on Multimedia, pages 3027–3036, 2025. 3, 4, 6, 7, 8, 2, 11
work page 2025
-
[72]
Remotereasoner: Towards unifying geospatial reasoning workflow.arXiv preprint arXiv:2507.19280, 2025
Liang Yao, Fan Liu, Hongbo Lu, Chuanyi Zhang, Rui Min, Shengxiang Xu, Shimin Di, and Pai Peng. Remotereasoner: Towards unifying geospatial reasoning workflow.arXiv preprint arXiv:2507.19280, 2025. 2, 7
-
[73]
Modeling context in referring expres- sions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expres- sions. InEuropean conference on computer vision, pages 69–85. Springer, 2016. 6
work page 2016
-
[74]
Rrsis: Referring remote sensing image segmentation.arXiv preprint arXiv:2306.08625, 2023
Zhenghang Yuan, Lichao Mou, Yuansheng Hua, and Xiao Xiang Zhu. Rrsis: Referring remote sensing image segmentation.arXiv preprint arXiv:2306.08625, 2023. 2, 3
-
[75]
Rsvg: Exploring data and models for visual grounding on remote sensing data
Yang Zhan, Zhitong Xiong, and Yuan Yuan. Rsvg: Exploring data and models for visual grounding on remote sensing data. IEEE Transactions on Geoscience and Remote Sensing, 61: 1–13, 2023. 2, 6, 8
work page 2023
-
[76]
Next-chat: An lmm for chat, detection and segmen- tation
Ao Zhang, Yuan Yao, Wei Ji, Zhiyuan Liu, and Tat-Seng Chua. Next-chat: An lmm for chat, detection and segmen- tation. InInternational Conference on Machine Learning, pages 60116–60133. PMLR, 2024. 7
work page 2024
-
[77]
Wei Zhang, Miaoxin Cai, Tong Zhang, Yin Zhuang, Jun Li, and Xuerui Mao. Earthmarker: A visual prompting multi- modal large language model for remote sensing.IEEE Trans- actions on Geoscience and Remote Sensing, 2024. 1
work page 2024
-
[78]
Wei Zhang, Miaoxin Cai, Tong Zhang, Yin Zhuang, and Xuerui Mao. Earthgpt: A universal multimodal large lan- guage model for multisensor image comprehension in re- mote sensing domain.IEEE Transactions on Geoscience and Remote Sensing, 62:1–20, 2024. 2
work page 2024
-
[79]
Yuanlin Zhang, Yuan Yuan, Yachuang Feng, and Xiaoqiang Lu. Hierarchical and robust convolutional neural network for very high-resolution remote sensing object detection. IEEE Transactions on Geoscience and Remote Sensing, 57 (8):5535–5548, 2019. 3
work page 2019
-
[80]
Psalm: Pixelwise segmentation with large multi-modal model
Zheng Zhang, Yeyao Ma, Enming Zhang, and Xiang Bai. Psalm: Pixelwise segmentation with large multi-modal model. InEuropean Conference on Computer Vision, pages 74–91. Springer, 2024. 2, 4, 6, 7, 8, 10
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.