StreamGaze: Gaze-Guided Temporal Reasoning and Proactive Understanding in Streaming Videos
Pith reviewed 2026-05-17 02:44 UTC · model grok-4.3
The pith
The StreamGaze benchmark shows state-of-the-art MLLMs lag humans substantially when using gaze signals for temporal and proactive reasoning in streaming videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
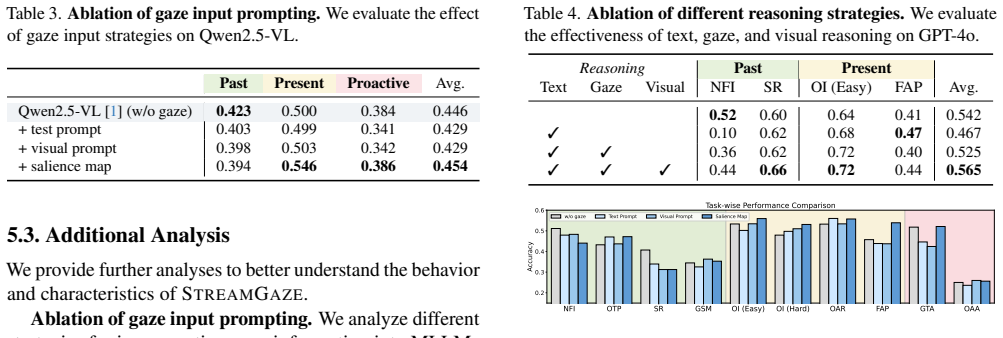
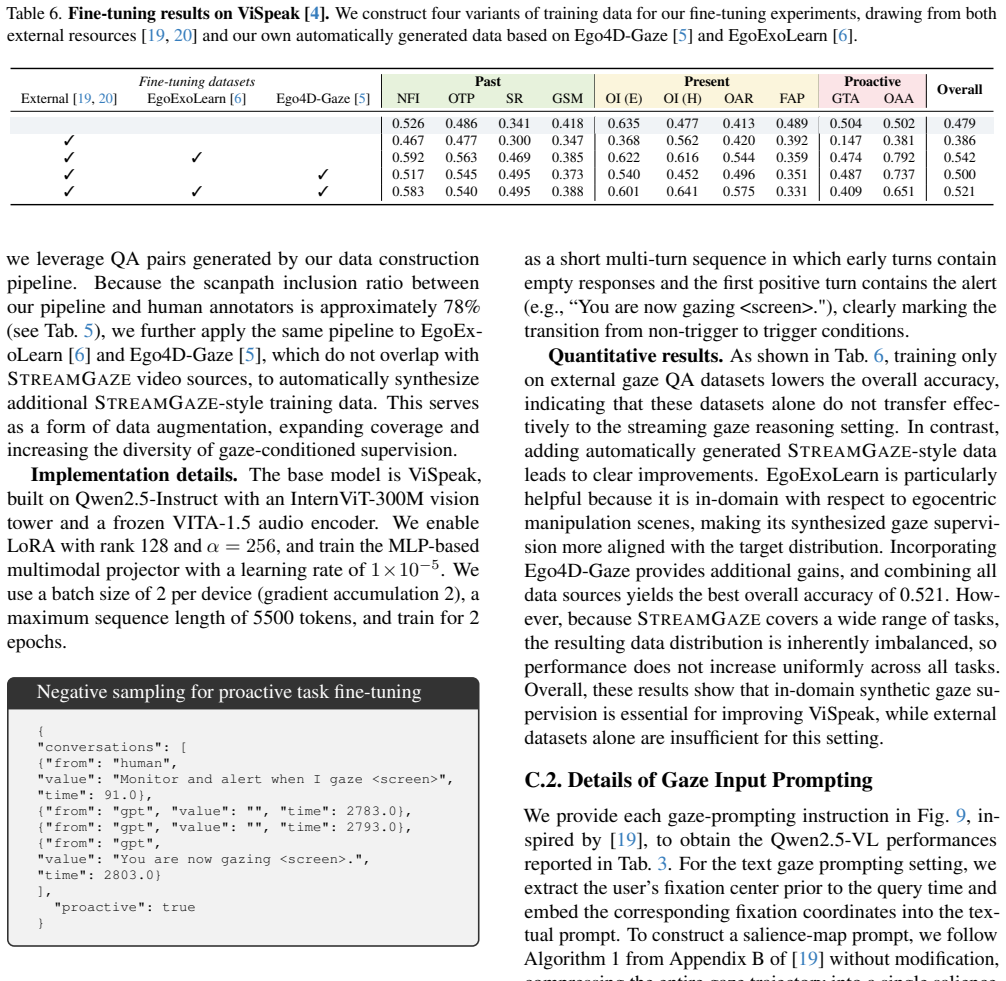
StreamGaze establishes gaze-guided past, present, and proactive tasks that measure how effectively MLLMs can leverage real-time gaze to follow shifting attention and infer user intentions from partially observed streaming video frames. The supporting QA generation pipeline aligns egocentric videos with gaze trajectories through fixation extraction, region-specific visual prompting, and scanpath construction, yielding spatio-temporally grounded evaluation data that reflects human perceptual dynamics. Benchmark results document substantial gaps between current MLLMs and human performance on all tasks, along with analyses of prompting strategies and task-specific failure modes.
What carries the argument
The gaze-video QA generation pipeline that aligns egocentric videos with raw gaze trajectories through fixation extraction, region-specific visual prompting, and scanpath construction to create spatio-temporally grounded question-answer pairs.
If this is right
- Gaze prompting strategies can be refined to better integrate real-time signals into streaming video models.
- Task-specific failure modes identify concrete areas for improving intention modeling and temporal reasoning.
- Public release of the data and code supports further work on gaze-guided streaming understanding.
- Applications such as AR glasses will require models that close the observed gaps in proactive prediction from partial observations.
Where Pith is reading between the lines
- Closing these gaps could enable AR systems that proactively assist users by anticipating what they will look at next.
- The same pipeline approach for turning sensor streams into grounded QA pairs might be adapted to other real-time signals such as hand tracking or audio.
- Architectures that process continuous video and auxiliary gaze data together may be needed before models match human performance on these tasks.
Load-bearing premise
The automatically generated QA pairs accurately reflect human perceptual dynamics and that gaze signals supply useful, non-redundant information for the past, present, and proactive tasks.
What would settle it
A follow-up experiment in which state-of-the-art MLLMs reach human-level accuracy on the proactive tasks when supplied with the same gaze data, or show no drop in performance when the gaze signal is removed, would indicate the claimed limitations do not hold.
Figures






















read the original abstract
Streaming video understanding requires models not only to process temporally incoming frames, but also to anticipate user intention for realistic applications such as Augmented Reality (AR) glasses. While prior streaming benchmarks evaluate temporal reasoning, none measure whether Multimodal Large Language Models (MLLMs) can interpret or leverage human gaze signals within a streaming setting. To fill this gap, we introduce StreamGaze, the first benchmark designed to evaluate how effectively MLLMs utilize gaze for temporal and proactive reasoning in streaming videos. StreamGaze introduces gaze-guided past, present, and proactive tasks that comprehensively assess streaming video understanding. These tasks evaluate whether models can use real-time gaze signals to follow shifting attention and infer user intentions based only on past and currently observed frames. To build StreamGaze, we develop a gaze-video Question Answering (QA) generation pipeline that aligns egocentric videos with raw gaze trajectories through fixation extraction, region-specific visual prompting, and scanpath construction. This pipeline produces spatio-temporally grounded QA pairs that reflect human perceptual dynamics. Across all StreamGaze tasks, we observe substantial performance gaps between state-of-the-art MLLMs and human performance, highlighting key limitations in gaze-based temporal reasoning, intention modeling, and proactive prediction. We further provide detailed analyses of gaze prompting strategies, reasoning behaviors, and task-specific failure modes, offering insights into current limitations and directions for future research. All data and code are publicly available to support continued research in gaze-guided streaming video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StreamGaze, the first benchmark for assessing how effectively Multimodal Large Language Models (MLLMs) utilize human gaze signals for gaze-guided past, present, and proactive reasoning in streaming videos. It presents a QA generation pipeline that aligns egocentric videos with raw gaze trajectories via fixation extraction, region-specific visual prompting, and scanpath construction to produce spatio-temporally grounded QA pairs, reports substantial performance gaps between SOTA MLLMs and humans across tasks, and provides analyses of prompting strategies and failure modes, with all data and code released publicly.
Significance. If the central claim holds after verification that the tasks isolate gaze-based reasoning deficits rather than generation artifacts, the work would be significant for streaming video understanding and AR applications by highlighting specific MLLM limitations in intention modeling and proactive prediction. The public data and code release is a clear strength supporting reproducibility and follow-on research.
major comments (2)
- [§3 (QA Generation Pipeline)] §3 (QA Generation Pipeline): The headline claim of substantial gaps highlighting limitations in gaze-based temporal reasoning rests on the assumption that fixation extraction + region-specific prompting + scanpath construction produces QA pairs whose difficulty is attributable to gaze utilization. The manuscript should include an ablation or control experiment comparing model performance on the same questions with vs. without gaze signals (or with randomized gaze) to rule out incidental properties of the generation process such as unnatural phrasing or region boundaries.
- [§4 (Task Definitions and Human Baselines)] §4 (Task Definitions and Human Baselines): It is unclear whether the past/present/proactive task formulations avoid future-frame leakage in the streaming setting and whether human baselines control for gaze visibility (i.e., do humans see the raw gaze overlay or only the video frames). These details are load-bearing for attributing the observed gaps specifically to missing gaze-temporal reasoning capacity rather than task construction.
minor comments (2)
- [Abstract and §5] Abstract and §5: The specific gaze prompting strategies analyzed could be enumerated more explicitly (e.g., raw coordinates vs. region masks) to aid reader understanding of the reported insights.
- [Results tables] Table 1 or equivalent results table: Ensure all evaluated MLLMs are listed with exact model versions, input resolutions, and whether gaze is provided as text coordinates, visual overlays, or both.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects for strengthening the attribution of performance gaps to gaze utilization and for improving clarity on task construction. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: §3 (QA Generation Pipeline): The headline claim of substantial gaps highlighting limitations in gaze-based temporal reasoning rests on the assumption that fixation extraction + region-specific prompting + scanpath construction produces QA pairs whose difficulty is attributable to gaze utilization. The manuscript should include an ablation or control experiment comparing model performance on the same questions with vs. without gaze signals (or with randomized gaze) to rule out incidental properties of the generation process such as unnatural phrasing or region boundaries.
Authors: We agree that a direct control experiment is necessary to isolate the contribution of gaze signals from potential artifacts in the QA generation pipeline. While the current manuscript analyzes multiple gaze prompting strategies and failure modes, it does not include an explicit ablation with randomized gaze or no-gaze conditions on identical QA pairs. In the revised version, we will add this experiment, reporting model performance across the three conditions (original gaze, randomized gaze, and no gaze) to confirm that the observed gaps stem from challenges in gaze-guided temporal reasoning. revision: yes
-
Referee: §4 (Task Definitions and Human Baselines): It is unclear whether the past/present/proactive task formulations avoid future-frame leakage in the streaming setting and whether human baselines control for gaze visibility (i.e., do humans see the raw gaze overlay or only the video frames). These details are load-bearing for attributing the observed gaps specifically to missing gaze-temporal reasoning capacity rather than task construction.
Authors: We appreciate the need for explicit clarification on these design choices. The task formulations are strictly streaming: models receive only frames up to the current timestamp with no access to future frames, preventing leakage by construction. Human baselines were collected with participants viewing the egocentric video frames overlaid with the raw gaze trajectory to match the multimodal input given to MLLMs. We will expand §4 with a dedicated subsection detailing the streaming protocol, frame access constraints, and human evaluation setup to remove any ambiguity. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper introduces StreamGaze as a new benchmark with a gaze-video QA generation pipeline based on fixation extraction, region-specific prompting, and scanpath construction applied to egocentric videos. No mathematical derivations, equations, or fitted parameters are presented as predictions. Central claims rest on empirical performance gaps between MLLMs and humans on the newly constructed tasks, without reduction to self-citations, self-definitions, or ansatzes from prior author work. The pipeline is described as a novel contribution that produces the evaluation data, making the work self-contained against external benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Raw gaze trajectories from egocentric videos can be processed via fixation extraction and scanpath construction to produce spatio-temporally grounded QA pairs that reflect human perceptual dynamics.
- domain assumption Gaze signals provide non-redundant information that enables models to follow shifting attention and infer user intentions from past and current frames alone.
Forward citations
Cited by 1 Pith paper
-
Object Referring-Guided Scanpath Prediction with Perception-Enhanced Vision-Language Models
ScanVLA uses a vision-language model with a history-enhanced decoder and frozen segmentation LoRA to outperform prior methods on object-referring scanpath prediction.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Videollm-online: Online video large language model for streaming video
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, and Mike Zheng Shou. Videollm-online: Online video large language model for streaming video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18407–18418, 2024. 2, 6, 7
work page 2024
-
[3]
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Chaoyou Fu, Haojia Lin, Xiong Wang, Yi-Fan Zhang, Yun- hang Shen, Xiaoyu Liu, Yangze Li, Zuwei Long, Heting Gao, Ke Li, et al. Vita-1.5: Towards gpt-4o level real-time vision and speech interaction.arXiv preprint arXiv:2501.01957,
work page internal anchor Pith review arXiv
-
[4]
Vispeak: Visual instruction feedback in streaming videos.arXiv preprint arXiv:2503.12769, 2025
Shenghao Fu, Qize Yang, Yuan-Ming Li, Yi-Xing Peng, Kun- Yu Lin, Xihan Wei, Jian-Fang Hu, Xiaohua Xie, and Wei-Shi Zheng. Vispeak: Visual instruction feedback in streaming videos.arXiv preprint arXiv:2503.12769, 2025. 2, 3, 6, 7, 5
-
[5]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18995–19012, 2022. 2, 6
work page 2022
-
[6]
Yifei Huang, Guo Chen, Jilan Xu, Mingfang Zhang, Lijin Yang, Baoqi Pei, Hongjie Zhang, Lu Dong, Yali Wang, Limin Wang, et al. Egoexolearn: A dataset for bridging asyn- chronous ego-and exo-centric view of procedural activities in real world. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22072– 22086, 2024. 3, 2, 5, 6
work page 2024
-
[7]
Gazevqa: a video question answering dataset for multiview eye-gaze task- oriented collaborations
Muhammet Ilaslan, Chenan Song, Joya Chen, Difei Gao, Weixian Lei, Qianli Xu, Joo Lim, and Mike Shou. Gazevqa: a video question answering dataset for multiview eye-gaze task- oriented collaborations. InProceedings of the 2023 Confer- ence on Empirical Methods in Natural Language Processing, pages 10462–10479, 2023. 2, 3, 4, 5, 6, 7
work page 2023
-
[8]
Shun Inadumi, Seiya Kawano, Akishige Yuguchi, Yasutomo Kawanishi, and Koichiro Yoshino. A gaze-grounded visual question answering dataset for clarifying ambiguous japanese questions.arXiv preprint arXiv:2403.17545, 2024. 4
-
[9]
Foveal vision anticipates defining features of eye movement targets.Elife, 11:e78106,
Lisa M Kroell and Martin Rolfs. Foveal vision anticipates defining features of eye movement targets.Elife, 11:e78106,
-
[10]
Listen to look into the future: Audio-visual egocentric gaze anticipation
Bolin Lai, Fiona Ryan, Wenqi Jia, Miao Liu, and James M Rehg. Listen to look into the future: Audio-visual egocentric gaze anticipation. InEuropean Conference on Computer Vision, pages 192–210. Springer, 2024. 2
work page 2024
-
[11]
Yin Li, Miao Liu, and James M Rehg. In the eye of the beholder: Gaze and actions in first person video.IEEE trans- actions on pattern analysis and machine intelligence, 45(6): 6731–6747, 2021. 2, 3, 5
work page 2021
-
[12]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Bin Zhu, Yang Ye, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual represen- tation by alignment before projection.arXiv preprint arXiv:2311.10122, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Junming Lin, Zheng Fang, Chi Chen, Zihao Wan, Fuwen Luo, Peng Li, Yang Liu, and Maosong Sun. Streamingbench: Assessing the gap for mllms to achieve streaming video un- derstanding.arXiv preprint arXiv:2411.03628, 2024. 3, 5, 6
-
[14]
Kangaroo: A powerful video-language model supporting long-context video input
Jiajun Liu, Yibing Wang, Hanghang Ma, Xiaoping Wu, Xi- aoqi Ma, Xiaoming Wei, Jianbin Jiao, Enhua Wu, and Jie Hu. Kangaroo: A powerful video-language model supporting long-context video input.arXiv preprint arXiv:2408.15542,
-
[15]
Junbo Niu, Yifei Li, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, et al. Ovo-bench: How far is your video-llms from real-world online video understanding? InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18902–18913, 2025. 3, 5, 6, 7, 4
work page 2025
-
[16]
Antje Nuthmann and Teresa Canas-Bajo. Visual search in naturalistic scenes from foveal to peripheral vision: A compar- ison between dynamic and static displays.Journal of Vision, 22(1):10–10, 2022. 2, 4
work page 2022
- [17]
-
[18]
Anthropic PBC. Introducing claude 4. Online blog post, 2025. https://www.anthropic.com/news/claude- 4 (accessed 2025-11-14). 6, 7
work page 2025
-
[19]
Taiying Peng, Jiacheng Hua, Miao Liu, and Feng Lu. In the eye of mllm: Benchmarking egocentric video intent un- derstanding with gaze-guided prompting.arXiv preprint arXiv:2509.07447, 2025. 2, 3, 4, 6, 8, 5
-
[20]
Hd-epic: A highly-detailed egocentric video dataset
Toby Perrett, Ahmad Darkhalil, Saptarshi Sinha, Omar Emara, Sam Pollard, Kranti Kumar Parida, Kaiting Liu, Prajwal Gatti, Siddhant Bansal, Kevin Flanagan, et al. Hd-epic: A highly-detailed egocentric video dataset. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23901–23913, 2025. 5, 6
work page 2025
-
[21]
Rui Qian, Shuangrui Ding, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Dahua Lin, and Jiaqi Wang. Dispider: Enabling video llms with active real-time interaction via dis- entangled perception, decision, and reaction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24045–24055, 2025. 6, 7
work page 2025
-
[22]
Nisreen I. Radwan, Nancy M. Salem, and Mohamed I. El Adawy. Histogram correlation for video scene change de- tection. InAdvances in Computer Science, Engineering & Applications: Proceedings of the Second International Con- ference on Computer Science, Engineering and Applications (ICCSEA 2012), May 25–27, 2012, New Delhi, India, Volume 1, pages 647–655, B...
work page 2012
-
[23]
Gazellm: Multimodal llms incorporating human visual attention, 2025
Jun Rekimoto. Gazellm: Multimodal llms incorporating human visual attention, 2025. 4
work page 2025
-
[24]
A review of interactions between peripheral and foveal vision.Journal of vision, 20(12):2–2, 2020
Emma EM Stewart, Matteo Valsecchi, and Alexander C Schütz. A review of interactions between peripheral and foveal vision.Journal of vision, 20(12):2–2, 2020. 2, 4
work page 2020
-
[25]
Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, 2024
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, 2024. 7
work page 2024
-
[26]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 2, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Xin Wang, Taein Kwon, Mahdi Rad, Bowen Pan, Ishani Chakraborty, Sean Andrist, Dan Bohus, Ashley Feniello, Bu- gra Tekin, Felipe Vieira Frujeri, et al. Holoassist: an egocen- tric human interaction dataset for interactive ai assistants in the real world. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20270–20281, 2023. 3, 1, 2, 5
work page 2023
-
[28]
Omnimmi: A comprehensive multi- modal interaction benchmark in streaming video contexts
Yuxuan Wang, Yueqian Wang, Bo Chen, Tong Wu, Dongyan Zhao, and Zilong Zheng. Omnimmi: A comprehensive multi- modal interaction benchmark in streaming video contexts. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 18925–18935, 2025. 2, 3
work page 2025
-
[29]
Haomiao Xiong, Zongxin Yang, Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Jiawen Zhu, and Huchuan Lu. Streaming video under- standing and multi-round interaction with memory-enhanced knowledge.arXiv preprint arXiv:2501.13468, 2025. 2, 3
-
[30]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Zhenyu Yang, Yuhang Hu, Zemin Du, Dizhan Xue, Sheng- sheng Qian, Jiahong Wu, Fan Yang, Weiming Dong, and Changsheng Xu. Svbench: A benchmark with temporal multi-turn dialogues for streaming video understanding.arXiv preprint arXiv:2502.10810, 2025. 2, 3
-
[32]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024. 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding.arXiv preprint arXiv:2306.02858, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Flash-vstream: Memory- based real-time understanding for long video streams, 2024
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, and Xiaojie Jin. Flash-vstream: Memory- based real-time understanding for long video streams, 2024. 2, 6, 7
work page 2024
-
[35]
Deep future gaze: Gaze anticipation on egocen- tric videos using adversarial networks
Mengmi Zhang, Keng Teck Ma, Joo Hwee Lim, Qi Zhao, and Jiashi Feng. Deep future gaze: Gaze anticipation on egocen- tric videos using adversarial networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4372–4381, 2017. 2
work page 2017
-
[36]
person wearing [clothing description]
Yichi Zhang, Xin Luna Dong, Zhaojiang Lin, Andrea Madotto, Anuj Kumar, Babak Damavandi, Joyce Chai, and Seungwhan Moon. Proactive assistant dialogue genera- tion from streaming egocentric videos.arXiv preprint arXiv:2506.05904, 2025. 2, 3, 6 10 STREAMGAZE: Gaze-Guided Temporal Reasoning and Proactive Understanding in Streaming Videos Supplementary Materia...
-
[37]
Only use visual evidence up to the given timestamp
-
[39]
{Question} Figure 19.Prompt for text-based reasoning
Give exactly ONE final choice (A/B/C/D) or yes/no with its short text inside <answer>...</answer>. {Question} Figure 19.Prompt for text-based reasoning. 14 Prompt for gaze-based reasoning You are an expert at gaze-conditioned streaming video reasoning. Rules:
-
[41]
Do your step-by-step reasoning ONLY inside <think>...</think>
-
[42]
Return exactly three tags in order: <gaze>...</gaze> <think>...</think> <answer>...</answer>
-
[43]
In <gaze>, estimate the most recent gaze center and FOV radius from the green dot and red circle in the frames up to the timestamp
-
[44]
If the green dot/Red circle is not visible, output "unknown" in <gaze> but still reason and answer using other available evidence
-
[45]
{Question} Figure 20.Prompt for gaze-based reasoning
In <answer>, give exactly ONE final choice (A/B/C/D) or Yes/No with a short text. {Question} Figure 20.Prompt for gaze-based reasoning. Prompt for visual-based reasoning You are an expert at gaze-conditioned streaming video reasoning. Rules:
-
[46]
Only use visual evidence up to the given timestamp (no future leakage)
-
[47]
Produce your reasoning ONLY inside <think>...</think> and never reveal reasoning outside the tag
-
[48]
Return exactly FOUR tags in this order: <gaze>...</gaze> <objects>...</objects> <think>...</think> <answer>...</answer>
-
[49]
In <gaze>, estimate the most recent gaze center and FOV radius from the green dot and red circle, or output "unknown" if not visible
-
[50]
In <objects>, ground the most relevant objects inside or closest to the gaze/FOV region; for each object provide: object_name, bbox_x1, bbox_y1, bbox_x2, bbox_y2 normalized to [0,1], or output "none" if no relevant object appears
-
[51]
In <think>, use the gaze and grounded objects to perform step-by-step reasoning and explain exclusion of irrelevant options
-
[52]
{Question} Figure 21.Prompt for visual-based reasoning
In <answer>, provide exactly ONE final label (A/B/C/D or Yes/No) with a short justification. {Question} Figure 21.Prompt for visual-based reasoning. 15 Figure 22.HTML for human verification of STREAMGAZEdata construction. 16 Figure 23.HTML for human oracle evaluation of STREAMGAZE. Figure 24.Instructions provided to human annotators. 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.