Recognition: unknown
Diversity Collapse in Multi-Agent LLM Systems: Structural Coupling and Collective Failure in Open-Ended Idea Generation
Pith reviewed 2026-05-10 03:49 UTC · model grok-4.3
The pith
Multi-agent LLM systems for idea generation experience diversity collapse primarily from interaction structures rather than model weaknesses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
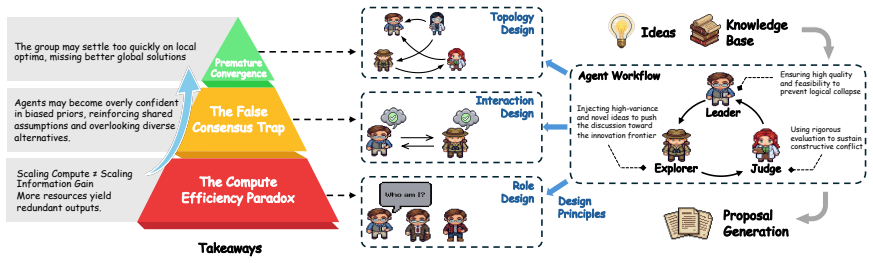
Our analysis shows that this collapse arises primarily from the interaction structure rather than inherent model insufficiency, highlighting the importance of preserving independence and disagreement when designing MAS for creative tasks. We characterize these outcomes as collective failures emerging from structural coupling, a process where interaction inadvertently contracts agent exploration and triggers diversity collapse.
What carries the argument
Structural coupling, the mechanism by which agent interactions inadvertently limit each agent's exploration range and cause the group to converge on similar ideas prematurely.
If this is right
- Stronger and more aligned models provide less additional diversity benefit per unit of compute despite producing higher quality individual samples.
- Groups where higher-authority agents dominate exhibit reduced semantic diversity compared to groups dominated by lower-authority agents.
- Larger group sizes yield progressively smaller diversity gains, while more densely connected communication patterns hasten the loss of variety.
- Collective failures in creative tasks stem from how the system is structured to link agents rather than from limitations in the underlying language models.
Where Pith is reading between the lines
- Designs for multi-agent systems could incorporate forced periods of independent thinking or mechanisms that penalize agreement to counteract the coupling effect.
- Similar diversity issues may appear in other multi-agent applications such as collaborative problem solving or planning, suggesting broader design principles.
- Testing alternative topologies like sparse connections or rotating leadership could be a direct way to validate the role of interaction density.
Load-bearing premise
The experimental setups, diversity metrics, and task prompts used across the model, cognition, and system levels successfully isolate the effects of structural coupling without being skewed by particular model quirks or measurement choices.
What would settle it
If isolated agents with no inter-agent communication produce substantially higher diversity on the same idea-generation tasks than connected agents using identical models and prompts, this would support the claim that interaction structure is the main driver of collapse.
Figures











read the original abstract
Multi-agent systems (MAS) are increasingly used for open-ended idea generation, driven by the expectation that collective interaction will broaden the exploration diversity. However, when and why such collaboration truly expands the solution space remains unclear. We present a systematic empirical study of diversity in MAS-based ideation across three bottom-up levels: model intelligence, agent cognition, and system dynamics. At the model level, we identify a compute efficiency paradox, where stronger, highly aligned models yield diminishing marginal diversity despite higher per-sample quality. At the cognition level, authority-driven dynamics suppress semantic diversity compared to junior-dominated groups. At the system level, group-size scaling yields diminishing returns and dense communication topologies accelerate premature convergence. We characterize these outcomes as collective failures emerging from structural coupling, a process where interaction inadvertently contracts agent exploration and triggers diversity collapse. Our analysis shows that this collapse arises primarily from the interaction structure rather than inherent model insufficiency, highlighting the importance of preserving independence and disagreement when designing MAS for creative tasks. Our code is available at https://github.com/Xtra-Computing/MAS_Diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic empirical study of semantic diversity in multi-agent LLM systems for open-ended idea generation, organized across three levels: model intelligence (identifying a compute-efficiency paradox where stronger aligned models yield diminishing diversity returns), agent cognition (showing authority-driven groups suppress diversity relative to junior-dominated ones), and system dynamics (reporting diminishing returns with group size and accelerated premature convergence under dense communication topologies). The authors introduce the concept of 'structural coupling' to explain how interaction structures contract agent exploration, leading to collective diversity collapse. They conclude that this collapse stems primarily from the interaction structure rather than inherent model limitations, and recommend preserving independence and disagreement in MAS design for creative tasks. Reproducible code is provided via GitHub.
Significance. If the empirical patterns hold after controls, the work would be significant for multi-agent AI research by providing concrete evidence that collaboration can reduce rather than expand solution diversity in ideation tasks, with direct implications for system design. The three-level bottom-up structure and public code are strengths that support falsifiability and extension.
major comments (2)
- Abstract and §3 (experimental design): the central claim that collapse 'arises primarily from the interaction structure rather than inherent model insufficiency' requires a quantitative decomposition (e.g., variance partitioning or ablation showing structure accounts for more variance than model choice or prompt wording). No such decomposition or effect-size reporting is visible in the provided abstract, leaving the attribution vulnerable to confounding.
- §4 (cognition and system levels): the authority vs. junior-group comparison and topology scaling results must demonstrate that the same models and prompts produce measurably higher diversity under altered structures while holding model parameters, temperature, and evaluation metrics fixed. Without explicit controls or statistical tests isolating topology from model-specific output distributions, the 'structural coupling' mechanism cannot be cleanly separated from metric or model artifacts.
minor comments (2)
- The term 'structural coupling' is introduced without a formal definition or contrast to existing concepts in multi-agent systems literature (e.g., consensus dynamics or homophily); a brief related-work paragraph would clarify novelty.
- Diversity metrics and task prompts should be listed with exact formulations and sensitivity analyses in the main text or appendix to allow replication of the semantic-contraction findings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the causal attribution in our study of diversity collapse. We address each major comment below and will incorporate revisions to provide the requested quantitative support and explicit controls.
read point-by-point responses
-
Referee: Abstract and §3 (experimental design): the central claim that collapse 'arises primarily from the interaction structure rather than inherent model insufficiency' requires a quantitative decomposition (e.g., variance partitioning or ablation showing structure accounts for more variance than model choice or prompt wording). No such decomposition or effect-size reporting is visible in the provided abstract, leaving the attribution vulnerable to confounding.
Authors: We agree that the abstract and main text would benefit from an explicit quantitative decomposition to support the attribution. Our §3 design isolates factors by holding models, prompts, and metrics fixed while varying structure (and vice versa across levels), but we did not perform a formal variance partitioning or report effect sizes. In the revised manuscript we will add an ablation analysis and variance decomposition (e.g., via linear models or ANOVA on diversity scores) to quantify the relative contribution of structural variables versus model choice and prompt wording. revision: yes
-
Referee: §4 (cognition and system levels): the authority vs. junior-group comparison and topology scaling results must demonstrate that the same models and prompts produce measurably higher diversity under altered structures while holding model parameters, temperature, and evaluation metrics fixed. Without explicit controls or statistical tests isolating topology from model-specific output distributions, the 'structural coupling' mechanism cannot be cleanly separated from metric or model artifacts.
Authors: All §4 experiments already employ identical model back-ends, temperature settings, prompts, and evaluation metrics across structural conditions; the only manipulated variables are role assignments (authority vs. junior) and communication topology. We will revise the section to state these controls explicitly, add statistical tests (e.g., paired t-tests or ANOVA with post-hoc corrections) for the reported diversity differences, and include per-model baseline distributions to further isolate structural effects from model-specific artifacts. revision: yes
Circularity Check
No circularity; purely empirical observational study
full rationale
The paper conducts a bottom-up empirical study of diversity in MAS ideation across model intelligence, agent cognition, and system dynamics levels, reporting observed patterns such as compute efficiency paradoxes, authority-driven suppression, and topology effects on convergence. No mathematical derivations, equations, first-principles predictions, or fitted parameters are present in the abstract or described structure. Claims attributing collapse to structural coupling rest on experimental observations rather than any self-referential definitions, self-citation chains, or renamings that reduce to inputs by construction. The analysis is self-contained against external benchmarks via code release and does not invoke uniqueness theorems or ansatzes.
Axiom & Free-Parameter Ledger
invented entities (1)
-
structural coupling
no independent evidence
Forward citations
Cited by 3 Pith papers
-
Social Theory Should Be a Structural Prior for Agentic AI: A Formal Framework for Multi-Agent Social Systems
Agentic AI needs social theory as a structural prior, formalized via the MASS dynamical system framework with four priors: strategic heterogeneity, networked-constrained dependence, co-evolution, and distributional in...
-
Social Theory Should Be a Structural Prior for Agentic AI: A Formal Framework for Multi-Agent Social Systems
Agentic AI requires social theory as a structural prior in the proposed MASS framework to model emergent outcomes from agent interactions and influence.
-
Social Theory Should Be a Structural Prior for Agentic AI: A Formal Framework for Multi-Agent Social Systems
Agentic AI needs social theory as structural priors in the MASS framework to model emergent dynamics from multi-agent interactions.
Reference graph
Works this paper leans on
-
[1]
Patrick R
Many hands make light the work: The causes and consequences of social loafing.Journal of Per- sonality and Social Psychology, 37(6):822–832. Patrick R. Laughlin. 1980. Social combination pro- cesses of cooperative problem-solving groups on verbal intellective tasks. In Martin Fishbein, edi- tor,Progress in Social Psychology, volume 1, pages 127–155. Lawre...
1980
-
[2]
Homogenizing effect of large language models (llms) on creative diversity: An empirical comparison of human and chatgpt writing.Computers in Human Behavior: Artificial Humans, 6:100207. Brian Mullen, Craig Johnson, and Eduardo Salas. 1991. Productivity loss in brainstorming groups: A meta- analytic integration.Basic and Applied Social Psy- chology, 12(1):...
-
[3]
https://web.stanford.edu/class/ cs326/research.html. Haoyang Su, Renqi Chen, Shixiang Tang, Zhenfei Yin, Xinzhe Zheng, Jinzhe Li, Biqing Qi, Qi Wu, Hui Li, Wanli Ouyang, Philip Torr, Bowen Zhou, and Nan- qing Dong. 2025. Many heads are better than one: Improved scientific idea generation by a llm-based multi-agent system.Preprint, arXiv:2410.09403. James ...
-
[4]
Background & Motivation:The specific gap in existing literature the proposal aims to ad- dress
-
[5]
The use of con- trasting agents reduces hallucination
Core Hypothesis:The central scientific claim or mechanism proposed (e.g., "The use of con- trasting agents reduces hallucination")
-
[6]
Methodology Sketch
Methodology Sketch:A high-level descrip- tion of the experimental design or algorithm. A.3 Why this Structure Facilitates Diversity Analysis This semi-structured format serves two crucial pur- poses for our evaluation: • Separating Style from Substance:By en- forcing a standard format, we minimize the impact of stylistic variations (e.g., format- ting dif...
2023
-
[7]
Round 1: generate diverse high-level ideas
A human-specified description of the phase is defined (for example, “Round 1: generate diverse high-level ideas” or “Round 2: identify potential weaknesses”)
-
[8]
This random grouping is re- peated independently in each round, so that agents are likely to interact with different part- ners across rounds
The set of participating agents is randomly partitioned into disjoint subgroups of a pre- specified size. This random grouping is re- peated independently in each round, so that agents are likely to interact with different part- ners across rounds
-
[9]
For each subgroup, an internal speaker order is defined (e.g., a fixed or randomly chosen permutation of the subgroup members). The subgroup then proceeds in that order: (a) When it is an agent’s turn to speak, the system constructs a prompt using the ele- ments listed above: task description, cur- rent phase description, that agent’s role, the agent’s pe...
-
[10]
Selection of recent discussion for the leaderAf- ter the last round of subgroup interaction, the sys- tem prepares input for the leader agent
After all subgroups have completed their turn for this round, a brief human-readable log en- try is created summarizing the round, includ- ing which agents were grouped together in each subgroup. Selection of recent discussion for the leaderAf- ter the last round of subgroup interaction, the sys- tem prepares input for the leader agent. To control context...
-
[11]
Round 1”, “Round 2
All utterance records are first grouped by their round labels. If round labels contain in- dices (for example, “Round 1”, “Round 2”, etc.), these indices are used to sort the rounds chronologically; otherwise, a default ordering is used
-
[12]
The last few rounds according to this ordering are selected as the “recent” rounds
-
[13]
All utterance records belonging to these re- cent rounds are concatenated into a textual transcript for the leader. Each entry in the tran- script includes the round label, the agent iden- tity, and the corresponding text, with simple formatting (such as headers and blank lines) to maintain readability
-
[14]
text-only
In parallel, the round-level logs created dur- ing the discussion are filtered so that only logs from the selected recent rounds are re- tained. This yields a concise summary of which agents interacted in which subgroups in the recent part of the discussion. Leader prompting and synthesisThe leader agent is prompted once at the end of the process. Its inp...
-
[15]
Absence of counter-claims: no turn contains an explicit critique, disagreement marker, or alternative proposal branch (defined as an ex- plicit proposal of a different research direction from the one assigned by the Leader)
-
[16]
Absence of independent sub-problems: no Collaborator turn introduces a research ques- tion or sub-problem not already present in the Leader’s framing
-
[17]
Building on. . . ,
Final-proposal alignment: the final proposal title and abstract recombine keywords and di- rections from the Leader’s Round 1 assign- ment without introducing new thematic an- chors. Deference and Pushback Markers.We define two complementary marker vocabularies applied to the opening sentence of each Collaborator turn: • Deference markers(agreement-first ...
-
[18]
Multi-Scale Computational Modeling of Synaptic Plas- ticity: Bridging Molecular Dynamics to Cognitive Func- tion
“Multi-Scale Computational Modeling of Synaptic Plas- ticity: Bridging Molecular Dynamics to Cognitive Func- tion”
-
[19]
Multi-Scale Computational Modeling of Synaptic Plas- ticity Mechanisms for Precision Cognitive Therapeu- tics
“Multi-Scale Computational Modeling of Synaptic Plas- ticity Mechanisms for Precision Cognitive Therapeu- tics”
-
[20]
Multi-Scale Graph Neural Networks for Modeling Synaptic Plasticity in Neuropsychiatric Disorders
“Multi-Scale Graph Neural Networks for Modeling Synaptic Plasticity in Neuropsychiatric Disorders”
-
[21]
Biologically-Constrained Computational Models for Enhanced Clinical Neuroscience Applications
“Biologically-Constrained Computational Models for Enhanced Clinical Neuroscience Applications”
-
[22]
Bridging Molecular Plasticity Mechanisms with Com- putational Models for Clinical Translation
“Bridging Molecular Plasticity Mechanisms with Com- putational Models for Clinical Translation” Horizontal (Neuroscience) — representative ti- tles:
-
[23]
Bridging the Gap in Temporal Processing: Biologically Inspired Modifications to ANNs
“Bridging the Gap in Temporal Processing: Biologically Inspired Modifications to ANNs”
-
[24]
Exploring Transformer Attention Mechanisms as Mod- els of Hippocampal Memory Processes
“Exploring Transformer Attention Mechanisms as Mod- els of Hippocampal Memory Processes”
-
[25]
Comparing Artificial and Biological Attention Mecha- nisms in Simple Cognitive Tasks
“Comparing Artificial and Biological Attention Mecha- nisms in Simple Cognitive Tasks”
-
[26]
Investigating the Relationship Between Hippocampal Replay Fidelity and Memory Consolidation
“Investigating the Relationship Between Hippocampal Replay Fidelity and Memory Consolidation”
-
[27]
Exploring Biologically Plausible Alternatives to Back- propagation in Neural Networks
“Exploring Biologically Plausible Alternatives to Back- propagation in Neural Networks”
-
[28]
Exploring Neural Heterogeneity and Temporal Dynam- ics in Bio-Inspired ANNs
“Exploring Neural Heterogeneity and Temporal Dynam- ics in Bio-Inspired ANNs”
-
[29]
Investigating Parallels Between Self-Supervised Learn- ing and Predictive Coding
“Investigating Parallels Between Self-Supervised Learn- ing and Predictive Coding” The Interdisciplinary titles recombine three an- chors (multi-scale modeling,synaptic plasticity, clinical translation) with minor variation. The Horizontal titles span at least five distinct sub- directions (temporal processing, attention mech- anisms, hippocampal replay, ...
-
[30]
By contrast, the Vendi Score range is 4.65–8.08 (a 74% relative difference)
Quality differences are modest.The Overall Quality range across all five structures is 7.88– 8.50 (a 0.62-point spread on a 10-point scale, or 6%). By contrast, the Vendi Score range is 4.65–8.08 (a 74% relative difference). Quality variation is an order of magnitude smaller than diversity variation
-
[31]
6.40–6.43 for authority-weighted structures; p <10 −10, Cohen’sd >1.0 )
Horizontal achieves the highest Workabil- ity.Despite scoring lowest on Overall Qual- ity, Horizontal proposals are rated signifi- cantly more feasible (Workability = 7.95 vs. 6.40–6.43 for authority-weighted structures; p <10 −10, Cohen’sd >1.0 ). This suggests that the diversity in Horizontal proposals is not noise but reflects a broader range ofac- tio...
-
[32]
The marginal quality gain does not compensate for the substantial di- versity loss
The quality–diversity tradeoff is asymmet- ric.Authority-weighted structures gain ∼0.5 points in Overall Quality but lose ∼3.4 points in Vendi Score. The marginal quality gain does not compensate for the substantial di- versity loss
-
[33]
low-hanging fruit
Specificity, Rigor, and Cohesion are structure-invariant.These three dimensions show η2 <0.06 , indicating that the structural quality of proposals (how specific, rigorous, and coherent they are) is largely independent of persona structure. Statistical tests.One-way ANOV A confirms sig- nificant differences for Overall Quality (F= 31.1 , p <0.001 , η2 = 0...
1975
-
[34]
This confirms that communi- cation topology has a real causal effect on within-topic diversity, independent of persona
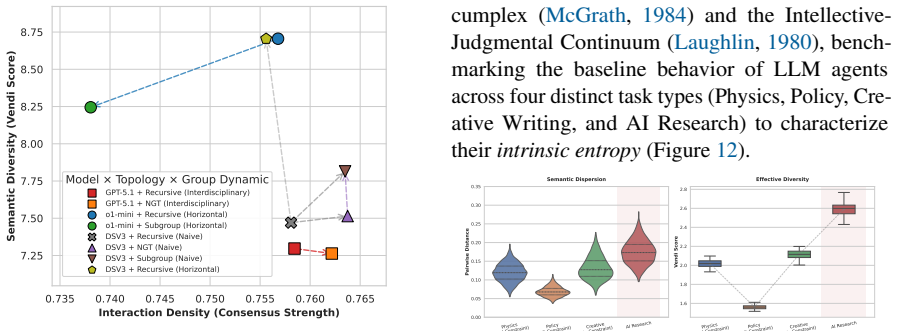
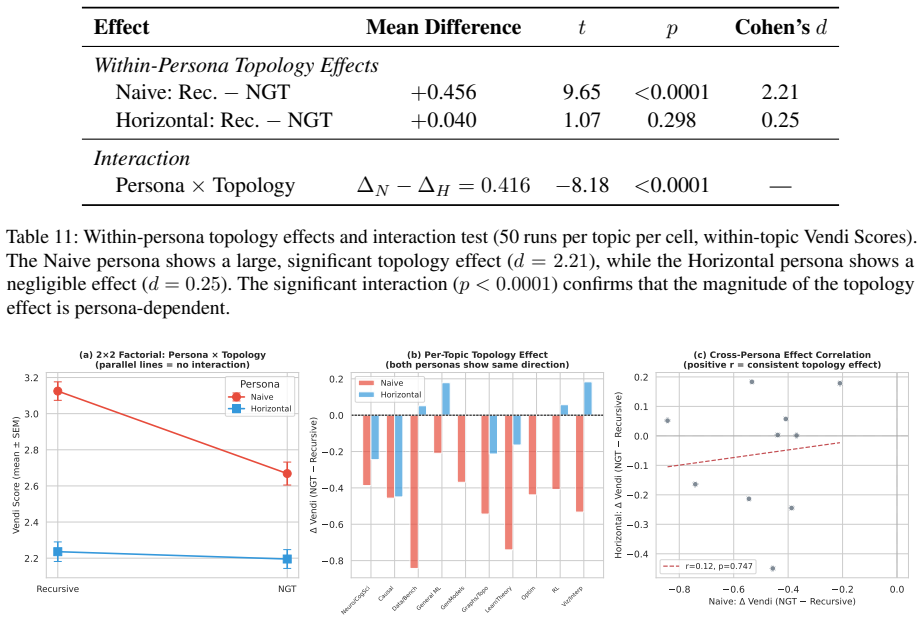
Topology is a genuine structural lever.Un- der the Naive persona, switching between Re- cursive and NGT produces a large, consistent within-topic diversity difference ( d= 2.21 , all 20 topics). This confirms that communi- cation topology has a real causal effect on within-topic diversity, independent of persona
-
[35]
The significant interaction (p <0.0001 ) con- firms that persona modulates the topology effect size
Persona moderates topology magnitude. The significant interaction (p <0.0001 ) con- firms that persona modulates the topology effect size. Under the Horizontal persona, the within-topic topology effect is negligible (d= 0.25,p= 0.298)
-
[36]
The Naive persona (senior researchers with stronger priors) is more susceptible to coupling-induced convergence, making topol- ogy a more effective lever
Mechanistic reading.The Horizontal per- sona (less directive, exploratory agents) is more robust to topology changes, suggesting that when agents are less constrained by au- thority priors, the communication structure has less marginal impact on within-topic di- versity. The Naive persona (senior researchers with stronger priors) is more susceptible to co...
-
[37]
Uniform improvementacross all conditions when switching to heterogeneous models
-
[38]
Instead, we observe a strong interaction: authority-weighted structures show large gains (+34%, +15%) while Horizontal structures show no gain (−4%)
No interactionbetween model heterogeneity and persona structure. Instead, we observe a strong interaction: authority-weighted structures show large gains (+34%, +15%) while Horizontal structures show no gain (−4%). This demonstrates that:
-
[39]
The diversity collapse under authority struc- tures is astructural property of the interaction dynamics, not an artifact of single-model per- sona prompting
-
[40]
polite con- sensus collapse
Model heterogeneity breaks the “polite con- sensus collapse” in authority structures be- cause different models have genuinely differ- ent priors, knowledge distributions, and rea- soning styles
-
[41]
focus on X
Horizontal structures already maximize diver- sity through exploratory interaction dynamics, so model heterogeneity provides no additional benefit. Limitations.We tested only three models (DeepSeek-V3, GPT-4o, Claude-Sonnet-4) with fixed agent-to-model assignment. Future work should explore a broader range of models, random- ized model assignments, and he...
-
[42]
exploratory instructions produce statistically indistinguishable diversity under flat topol- ogy (η2 = 0.023)
Prompt tone is not a confound.Directive vs. exploratory instructions produce statistically indistinguishable diversity under flat topol- ogy (η2 = 0.023). The diversity collapse in authority-weighted structures cannot be at- tributed to directive prompt design
-
[43]
Authority-induced collapse is structural, not prompt-driven.When Senior personas interact in a flat topology, they producehigher diversity than Junior personas. The diversity collapse occurs only when expertise is com- bined with hierarchical authority structures (Leader-Led, Interdisciplinary), confirming that the interaction topology—not the iden- tity ...
-
[44]
LLM-as-a-Judge
The total prompt-level variance is small. Identity and Tone together explain only 9.2% of total variance (η2 Identity+η2 Tone+η2 Interaction = 0.058+0.023+0.011 ). By contrast, the struc- tural effect (persona structure with topology) explains 42% of variance in the temperature sensitivity analysis (Appendix L). Interaction structure dominates prompt-leve...
2026
-
[46]
CRITICAL REQUIREMENTS:
Step-by-Step Experiment Plan: Now write your topic_lower proposal in the EXACT same format, maybe shorter and focused to reflect self-discussion nature. CRITICAL REQUIREMENTS:
-
[47]
Title: 2
Use the exact numbering format: 1. Title: 2. Problem Statement: 3. Motivation & Hypothesis: 4. Proposed Method: 5. Step-by-Step Experiment Plan:
-
[48]
Focus on topic_lower research
-
[49]
Only include verified real papers
Use semantic_scholar_search tools to find, verify, and properly cite relevant literature which is mentioned in your discussion. Only include verified real papers
-
[50]
Include a References section at the end with proper citations
-
[51]
Remember: Your ENTIRE response must be:
Do NOT include any tool calls, actions, or meta-comments in the Action Input - the content must be pure proposal text. Remember: Your ENTIRE response must be:
-
[52]
Title: [your topic_lower research title]
-
[53]
Problem Statement: [detailed problem statement about topic_lower limitations]
-
[54]
Motivation & Hypothesis: [detailed motivation and central hypothesis]
-
[55]
Proposed Method: [detailed technical approach]
-
[56]
Step-by-Step Experiment Plan: [exactly experimental steps] References: [relevant citations from literature searches] Example of a Research Proposal of Paper (Gu and Dao, 2024), with formatting inspired by (Stanford University, 2024) and (Si et al., 2025) and (Ali and Kamraju, 2023)
2024
-
[57]
Title: Mamba: Exploring Linear-Time Sequence Modeling with Selective State Spaces
-
[58]
This makes scaling to very long sequences computationally prohibitive
Problem Statement: The Transformer architecture, while dominant, is fundamentally constrained by the quadratic complexity of its attention mechanism. This makes scaling to very long sequences computationally prohibitive. Current alternatives, such as linear attention or structured state space models (SSMs), achieve linear or near-linear scaling but have n...
-
[59]
Their core recurrence or convolution operations are fixed regardless of the input, which prevents them from dynamically adapting to the content of the sequence
Motivation & Hypothesis: We hypothesize that a key weakness of existing efficient models is their time-invariant nature. Their core recurrence or convolution operations are fixed regardless of the input, which prevents them from dynamically adapting to the content of the sequence. For example, they cannot easily "choose" to remember a specific token from ...
-
[60]
The plan is to tackle this in three parts: (1) Designing the Selection Mechanism:Our primary approach will be to modify the standard SSM formulation (‘A‘, ‘B‘, ‘C‘ parameters)
Proposed Method: We propose to develop a new class of models, which we’ll callSelective State Space Models. The plan is to tackle this in three parts: (1) Designing the Selection Mechanism:Our primary approach will be to modify the standard SSM formulation (‘A‘, ‘B‘, ‘C‘ parameters). We will make the ‘A‘, ‘B‘, and ‘C‘ parameters input-dependent by derivin...
-
[61]
Step-by-Step Experiment Plan:
-
[62]
We will create synthetic tasks where LTI models are known to fail but where selectivity should, in theory, succeed
Isolate and Validate the Selection Mechanism: First, we need to test if our core hypothesis is sound. We will create synthetic tasks where LTI models are known to fail but where selectivity should, in theory, succeed. • Selective Copying:Can our model learn to recall specific tokens while ignoring variable- length spans of "noise" tokens? • Induction Head...
-
[63]
• Genomics & Audio:We will train models on DNA and audio waveform data, with sequence lengths up to one million
Assess Performance on Long-Context Modalities: If the synthetic tasks show promise, we’ll move to real-world data where long-range dependencies are key. • Genomics & Audio:We will train models on DNA and audio waveform data, with sequence lengths up to one million. Our key metric will be whether model performance (e.g., perplexity, BPD) improves with long...
-
[64]
We will conduct a series of language modeling experiments on a standard dataset like The Pile
Challenge Transformers on Language Modeling: This is the ultimate test. We will conduct a series of language modeling experiments on a standard dataset like The Pile. • Scaling Laws:We’ll train models at several scales (e.g., ∼100M to ∼1B+ parameters) and plot their performance (perplexity) against compute to directly compare their scaling efficiency to a...
-
[65]
• We will benchmark the raw speed of our selective scan kernel against optimized attention (FlashAttention-2) and convolution implementations
Quantify Efficiency Gains: We need to rigorously prove our computational claims. • We will benchmark the raw speed of our selective scan kernel against optimized attention (FlashAttention-2) and convolution implementations. • We will measure the end-to-end inference throughput (tokens/sec) and compare it against a Transformer of a similar size to demonstr...
-
[66]
Chen et al. 2023 Dynamic Sparsity for Efficient Deep Metric Learning
Conduct Ablation Studies: To understand what makes the model work, we’ll dissect it. • Which parameters (‘A‘, ‘B‘, ‘C‘) are most critical to make selective? • How does performance change as we increase the latent state dimension ‘N‘? • How does our simplified Mamba architecture compare to more complex hybrid designs? Prompt for Solitary Ideation <system_r...
2023
-
[67]
Motivation & Hypothesis:
-
[68]
Chen et al. 2023 Dynamic Sparsity for Efficient Deep Metric Learning
Step-by-Step Experiment Plan: [Proposal Generation Format Prompt] Example of Solitary Ideation <system_role> leader_prompt: &leader_prompt |- You are the Leader in a 5-round academic discussion on 'topic'. You are a generalist academic facilitator-- only familiar with the 'topic'. Prompt for Collective Ideation <system_role> prompt: &prompt |- You are par...
2023
-
[69]
Novelty (1-10) Definition: This metric assesses the degree to which the research proposal introduces an original idea that modifies existing paradigms in the field. It evaluates originality (how rare, ingenious, imaginative, or surprising the core insight is) and paradigm relatedness (whether the idea preserves the current paradigm or modifies it in a rad...
-
[70]
It considers acceptability (social, legal, or political feasibility) and implementability (ease of execution, including awareness of risks and mitigation strategies)
Workability (1-10) Definition: This metric evaluates the feasibility of the proposed research plan, assessing whether it can be easily implemented without violating known constraints (e.g., technical, ethical, or resource limitations). It considers acceptability (social, legal, or political feasibility) and implementability (ease of execution, including a...
-
[71]
It evaluates applicability (direct fit to the problem) and effectiveness (likelihood of achieving meaningful results or impact)
Relevance (1-10) Definition: This metric assesses how well the proposal applies to the stated research problem and its potential effectiveness in solving it. It evaluates applicability (direct fit to the problem) and effectiveness (likelihood of achieving meaningful results or impact). High relevance ensures the proposal addresses a genuine gap in a compe...
-
[72]
Specificity (1-10) Definition: This metric evaluates how clearly and thoroughly the proposal is articulated, assessing whether it is worked out in detail. It considers implicational explicitness (clear links between actions and outcomes), completeness (breadth of coverage across who, what, where, when, why, and how), and clarity (grammatical and communica...
-
[73]
It evaluates the ability to connect disparate elements, creating a whole that is greater than the sum of its parts
Integration Depth (1-10) Definition: This metric assesses how well the proposal integrates diverse concepts, methodologies, or data sources into a cohesive and synergistic framework. It evaluates the ability to connect disparate elements, creating a whole that is greater than the sum of its parts. High integration depth indicates a sophisticated, interdis...
-
[74]
Strategic Vision (1-10) Definition: This metric evaluates the long-term potential and forward- looking perspective of the proposal. It assesses whether the research addresses not just an immediate gap but also anticipates future trends, sets the stage for subsequent work, and has a clear vision for its broader impact on the field or society. High strategi...
-
[75]
It evaluates the quality of the experimental design, data collection procedures, analytical techniques, and validation strategies
Methodological Rigor (1-10) Definition: This metric assesses the soundness and appropriateness of the proposed research methods. It evaluates the quality of the experimental design, data collection procedures, analytical techniques, and validation strategies. High methodological rigor ensures that the research outcomes will be reliable, valid, and reprodu...
-
[76]
Argumentative Cohesion (1-10) Definition: This metric assesses the logical flow and coherence of the argument presented in the proposal. It evaluates how well different sections connect to form a unified narrative, the consistency of reasoning throughout, and the strength of the logical connections between claims and evidence. High argumentative cohesion ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.