Chat2Workflow: A Benchmark for Generating Executable Visual Workflows with Natural Language
Pith reviewed 2026-05-10 02:51 UTC · model grok-4.3
The pith
Large language models capture high-level intent but struggle to produce correct, stable, executable visual workflows from natural language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
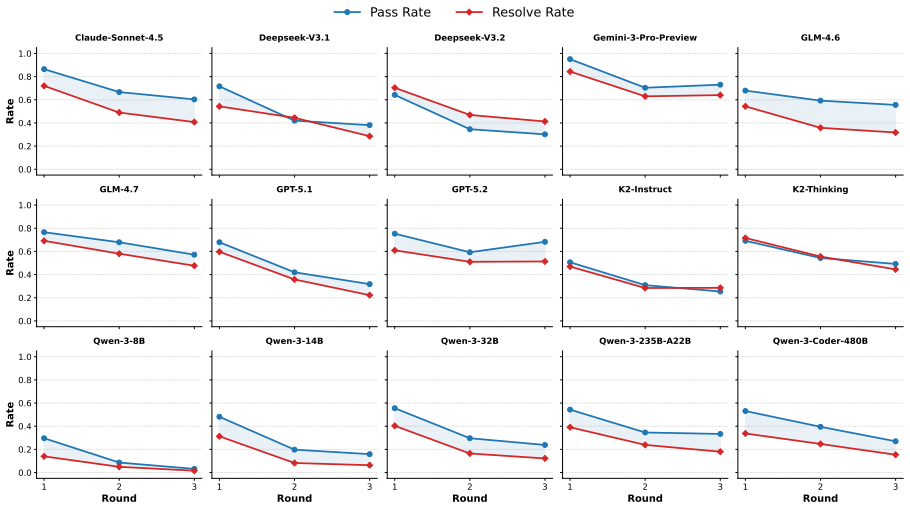
While state-of-the-art language models can often capture high-level intent, they struggle to generate correct, stable, and executable workflows, especially under complex or changing requirements. Although the proposed agentic framework yields up to 5.34% resolve rate gains, the remaining real-world gap positions Chat2Workflow as a foundation for advancing industrial-grade automation.
What carries the argument
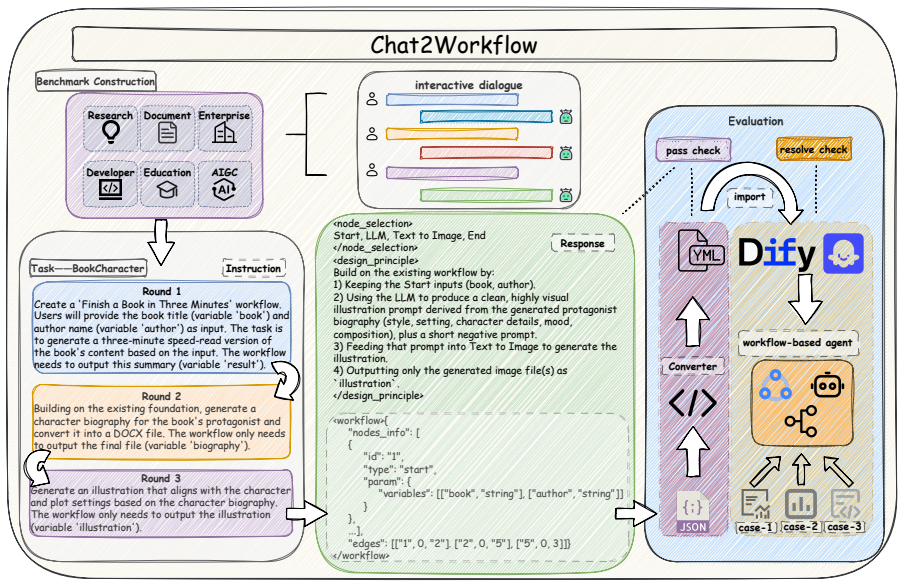
The Chat2Workflow benchmark, consisting of real-world business workflow instances that can be transformed and deployed directly to platforms such as Dify and Coze, paired with an agentic framework that iteratively corrects execution errors.
If this is right
- Improved techniques will be required to handle multi-round revisions and stability checks for complex workflows.
- The benchmark supplies a concrete evaluation set for measuring progress in automated workflow generation.
- Agentic iteration provides partial relief from execution errors but does not close the gap for industrial use.
- Development of visual workflows will remain manual and costly until models improve on the identified failure modes.
Where Pith is reading between the lines
- The benchmark could accelerate specialized model training for workflow tasks in the same way coding benchmarks advanced code generation.
- Similar evaluation setups might apply to other automation areas such as robotic process automation or business process modeling.
- Persistent execution gaps point to the need for tighter integration between language models and workflow execution environments during generation.
Load-bearing premise
The collected real-world business workflows are representative of practical industrial needs and that generated workflows can be transformed and directly deployed to platforms such as Dify and Coze without loss of intended functionality.
What would settle it
An LLM or agentic system that achieves a high resolve rate on complex or changing-requirement instances in Chat2Workflow, with the resulting workflows executing correctly and stably after deployment to Dify or Coze.
Figures







read the original abstract
At present, executable visual workflows have emerged as a mainstream paradigm in real-world industrial deployments, offering strong reliability and controllability. However, in current practice, such workflows are almost entirely constructed through manual engineering: developers must carefully design workflows, write prompts for each step, and repeatedly revise the logic as requirements evolve -- making development costly, time-consuming, and error-prone. To study whether large language models can automate this multi-round interaction process, we introduce Chat2Workflow, a benchmark for generating executable visual workflows directly from natural language, and propose a robust agentic baseline to improve performance. The benchmark is built from a large collection of real-world business workflows, with each instance designed so that the generated workflow can be transformed and directly deployed to practical workflow platforms such as Dify and Coze. Experimental results show that while state-of-the-art language models can often capture high-level intent, they struggle to generate correct, stable, and executable workflows, especially given complex and evolving requirements. Although our agentic baseline yields up to 6.05% resolve rate gains, the remaining real-world gap positions Chat2Workflow as a foundation for advancing industrial-grade automation. Code is available at https://github.com/zjunlp/Chat2Workflow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Chat2Workflow benchmark for generating executable visual workflows from natural language, constructed from real-world business workflows deployable to platforms like Dify and Coze. It demonstrates that state-of-the-art LLMs struggle to produce correct, stable, and executable workflows, particularly with complex or evolving requirements, and proposes an agentic framework achieving up to 5.34% improvement in resolve rate, while noting a persistent gap for industrial applications. The code is made publicly available.
Significance. If the benchmark is representative of industrial workflows and the evaluation is rigorous with verifiable lossless deployment, this work would be significant for advancing research in LLM-based automation of visual workflows. It provides a new benchmark targeting a practical gap in manual workflow engineering and highlights limitations of current models, with the open-sourced code supporting reproducibility and community extension.
major comments (2)
- [Abstract] The central claim regarding LLM struggles and the 'remaining real-world gap' depends on the benchmark being representative of practical industrial workflows and generated outputs being transformable without loss of functionality. However, the abstract provides no details on the collection protocol, benchmark size, diversity statistics, coverage of requirement changes, or empirical deployment success rates to Dify and Coze.
- [§5 (Experiments)] The reported 5.34% resolve rate gains and 'concrete struggles' are presented without specifying the benchmark size, exact definition and computation of resolve rate, evaluation protocol, or categorization of errors. This prevents a robust assessment of whether the agentic framework's improvements and the identified limitations are statistically meaningful and generalizable.
minor comments (1)
- [Abstract] Clarification on the definition of 'resolve rate' and how the agentic framework is implemented would improve the abstract's standalone readability.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address each of the major comments below and commit to revising the manuscript accordingly to enhance clarity and provide the requested details.
read point-by-point responses
-
Referee: [Abstract] The central claim regarding LLM struggles and the 'remaining real-world gap' depends on the benchmark being representative of practical industrial workflows and generated outputs being transformable without loss of functionality. However, the abstract provides no details on the collection protocol, benchmark size, diversity statistics, coverage of requirement changes, or empirical deployment success rates to Dify and Coze.
Authors: We agree that the abstract would benefit from additional context to substantiate the central claims. Although the manuscript body (Sections 3 and 4) provides comprehensive details on the benchmark construction from real-world workflows, the collection protocol, size, diversity, and deployment verification, we will revise the abstract to concisely incorporate key statistics and assurances regarding representativeness and lossless transformation to platforms like Dify and Coze. revision: yes
-
Referee: [§5 (Experiments)] The reported 5.34% resolve rate gains and 'concrete struggles' are presented without specifying the benchmark size, exact definition and computation of resolve rate, evaluation protocol, or categorization of errors. This prevents a robust assessment of whether the agentic framework's improvements and the identified limitations are statistically meaningful and generalizable.
Authors: We acknowledge the need for greater explicitness in the experimental section. In the revised manuscript, we will update §5 to clearly specify the benchmark size, provide the exact definition and computation method for the resolve rate, outline the full evaluation protocol, and detail the error categorization scheme. This will allow readers to better assess the statistical significance and generalizability of the results, including the 5.34% gains from the agentic framework. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical benchmark constructed from a collection of external real-world business workflows, with public code release, and reports experimental results on LLM performance plus modest gains from an agentic framework. No equations, fitted parameters renamed as predictions, self-definitional claims, or load-bearing self-citations appear in the abstract or described structure; the central claims about LLM limitations and remaining gaps rest on the benchmark instances themselves rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world business workflows can be systematically collected and converted into a format that allows direct deployment to practical platforms such as Dify and Coze.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.