Recognition: unknown
ONOTE: Benchmarking Omnimodal Notation Processing for Expert-level Music Intelligence
Pith reviewed 2026-05-09 23:00 UTC · model grok-4.3
The pith
The ONOTE benchmark shows omnimodal models achieve perceptual accuracy on music notation yet lack music-theoretic comprehension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
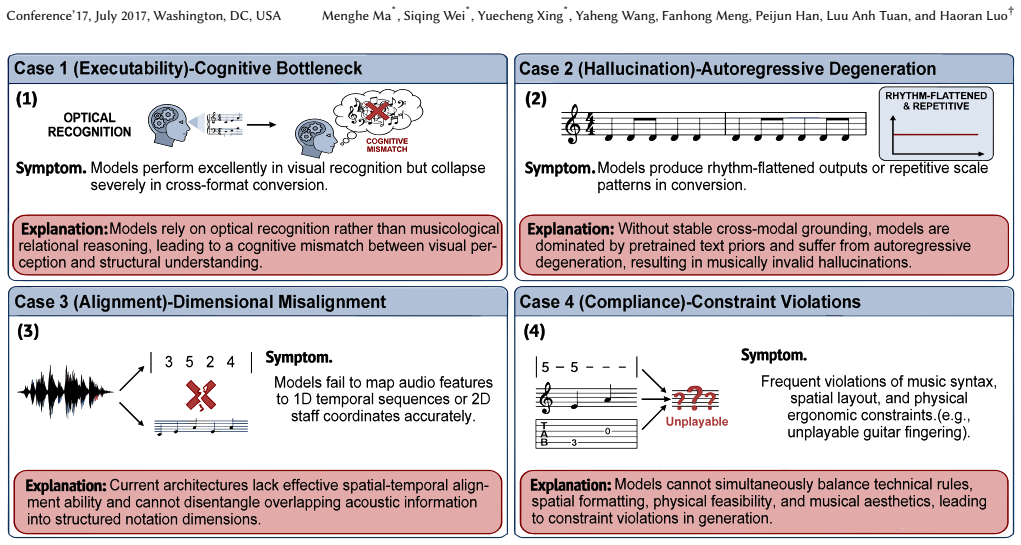
Omnimodal Notation Processing requires alignment across auditory, visual, and symbolic domains, yet existing models remain limited to isolated transcription tasks that do not capture musical logic. The ONOTE benchmark applies a deterministic pipeline grounded in canonical pitch projection to remove subjective scoring biases and test diverse notation systems. Evaluation of leading models demonstrates a consistent disconnect between high perceptual accuracy and weak music-theoretic comprehension, supplying an objective diagnostic for reasoning failures in rule-constrained settings.
What carries the argument
ONOTE, a multi-format benchmark that applies a deterministic pipeline grounded in canonical pitch projection to measure music-theoretic comprehension objectively across notation systems.
If this is right
- Future model development can target the specific gap between perception and rule application in structured domains.
- Evaluation standards for omnimodal AI shift from subjective LLM judges to deterministic pipelines in expert tasks.
- The benchmark framework can be adapted to diagnose reasoning limits in other rule-heavy fields such as formal logic or chemistry.
- Training data and objectives can be redesigned to emphasize logical consistency over perceptual fidelity alone.
Where Pith is reading between the lines
- The same objective-pipeline approach could expose similar perception-versus-comprehension gaps in non-music domains that use multiple representation formats.
- If the disconnect persists, it suggests current scaling methods improve surface recognition faster than rule internalization.
- Integration of ONOTE-style testing into model training loops could produce systems that generate notation while obeying theoretical constraints.
Load-bearing premise
A deterministic pipeline based on canonical pitch projection can remove subjective biases and accurately measure genuine music-theoretic comprehension rather than surface pattern recognition.
What would settle it
A controlled test in which models that score low on ONOTE nevertheless correctly answer expert-level music-theory questions about the same scores, or models that score high on ONOTE fail those same theory questions.
Figures







read the original abstract
Omnimodal Notation Processing (ONP) represents a unique frontier for omnimodal AI due to the rigorous, multi-dimensional alignment required across auditory, visual, and symbolic domains. Current research remains fragmented, focusing on isolated transcription tasks that fail to bridge the gap between superficial pattern recognition and the underlying musical logic. This landscape is further complicated by severe notation biases toward Western staff and the inherent unreliability of "LLM-as-a-judge" metrics, which often mask structural reasoning failures with systemic hallucinations. To establish a more rigorous standard, we introduce ONOTE, a multi-format benchmark that utilizes a deterministic pipeline--grounded in canonical pitch projection--to eliminate subjective scoring biases across diverse notation systems. Our evaluation of leading omnimodal models exposes a fundamental disconnect between perceptual accuracy and music-theoretic comprehension, providing a necessary framework for diagnosing reasoning vulnerabilities in complex, rule-constrained domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ONOTE, a multi-format benchmark for Omnimodal Notation Processing (ONP) that employs a deterministic pipeline grounded in canonical pitch projection to evaluate leading omnimodal models on music notation tasks across diverse systems. It claims this evaluation exposes a fundamental disconnect between perceptual accuracy and music-theoretic comprehension, providing a framework for diagnosing reasoning vulnerabilities in rule-constrained domains.
Significance. If the pipeline is validated to isolate higher-order music-theoretic reasoning (beyond low-level pitch matching) and the disconnect is substantiated with reproducible results, ONOTE could serve as a useful standardized tool for assessing AI capabilities in music and other structured domains, addressing limitations of fragmented transcription tasks and subjective LLM-as-a-judge metrics.
major comments (2)
- [Abstract] Abstract: The manuscript asserts that 'our evaluation of leading omnimodal models exposes a fundamental disconnect,' yet supplies no model names, performance metrics, error analyses, tables, or specific failure examples to support this finding. Without these, the central claim cannot be verified or assessed for soundness.
- [Abstract / Benchmark Description] Benchmark pipeline (as described in the abstract): The deterministic pipeline grounded in canonical pitch projection is presented as eliminating subjective biases and measuring music-theoretic comprehension, but this risks reducing evaluation to transposition-invariant pitch sequences. It does not clearly demonstrate probing of rule-constrained elements such as rhythmic hierarchy, voice leading, or harmonic function, undermining the distinction from perceptual pattern recognition.
minor comments (1)
- [Abstract] The abstract references 'severe notation biases toward Western staff' and 'non-Western or non-staff notations' but does not detail how the benchmark specifically incorporates or scores diverse notation systems beyond the pitch projection step.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point by point below, providing clarifications based on the full manuscript content and indicating where revisions have been made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts that 'our evaluation of leading omnimodal models exposes a fundamental disconnect,' yet supplies no model names, performance metrics, error analyses, tables, or specific failure examples to support this finding. Without these, the central claim cannot be verified or assessed for soundness.
Authors: The full manuscript provides these details in Sections 4 and 5, including the specific omnimodal models evaluated, quantitative metrics, error breakdowns, tables, and concrete failure examples that substantiate the disconnect between perceptual accuracy and music-theoretic comprehension. The abstract summarizes the overall finding at a high level due to length constraints. We have revised the abstract to include a concise summary of key models tested and aggregate metrics demonstrating the claimed disconnect. revision: yes
-
Referee: [Abstract / Benchmark Description] Benchmark pipeline (as described in the abstract): The deterministic pipeline grounded in canonical pitch projection is presented as eliminating subjective biases and measuring music-theoretic comprehension, but this risks reducing evaluation to transposition-invariant pitch sequences. It does not clearly demonstrate probing of rule-constrained elements such as rhythmic hierarchy, voice leading, or harmonic function, undermining the distinction from perceptual pattern recognition.
Authors: The canonical pitch projection serves as the deterministic core to normalize across notation systems and remove subjective biases, but the full pipeline integrates this with multi-format alignment tasks that explicitly require higher-order music-theoretic reasoning. The manuscript includes task designs and results showing model failures on rhythmic hierarchy, voice leading, and harmonic function even when pitch sequences match correctly. We agree the abstract description is brief and have expanded the benchmark pipeline section to more explicitly detail how these rule-constrained elements are probed beyond basic pitch matching. revision: partial
Circularity Check
No circularity: ONOTE is an externally introduced benchmark without self-referential derivations
full rationale
The paper introduces ONOTE as a new multi-format benchmark employing a deterministic pipeline grounded in canonical pitch projection to score model outputs across notation systems. No equations, fitted parameters, or predictions are derived that reduce by construction to the paper's own inputs or prior self-citations. The central claims about a disconnect between perceptual accuracy and music-theoretic comprehension rest on empirical evaluations of external models rather than any closed-loop construction or load-bearing self-reference. This is a standard benchmark contribution with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Canonical pitch projection supplies an objective ground truth for aligning auditory, visual, and symbolic music notation.
Reference graph
Works this paper leans on
-
[1]
Rana L Abdulazeez and Fattah Alizadeh. 2024. Deep Learning-Based Optical Music Recognition for Semantic Representation of Non-overlap and Overlap Music Notes.ARO-THE SCIENTIFIC JOURNAL OF KOYA UNIVERSITY12, 1 (2024), 79–87
2024
-
[2]
MusicLM: Generating Music From Text
Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, An- toine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, and Christian Frank. 2023. MusicLM: Generating Music From Text. arXiv:2301.11325 [cs.SD] https://arxiv.org/abs/2301.11325
work page internal anchor Pith review arXiv 2023
-
[3]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and J Qwen-VL Zhou. 2023. A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.129666 (2023), 3
work page internal anchor Pith review arXiv 2023
-
[4]
Arnau Baró, Pau Riba, Jorge Calvo-Zaragoza, and Alicia Fornés. 2017. Optical Music Recognition by Recurrent Neural Networks.. InGREC@ ICDAR. 25–26
2017
-
[5]
Keshav Bhandari and Simon Colton. 2024. Motifs, phrases, and beyond: The modelling of structure in symbolic music generation. InInternational Conference on Computational Intelligence in Music, Sound, Art and Design (Part of EvoStar). Springer, 33–51
2024
-
[6]
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, and Neil Zeghidour. 2023. AudioLM: A Language Modeling Ap- proach to Audio Generation.IEEE/ACM Transactions on Audio, Speech, and Language Processing31 (2023), 2523–2533. doi:10.1109/TASLP.2...
-
[7]
Martinez-Sevilla, Carlos Penarrubia, and Antonio Rios-Vila
Jorge Calvo-Zaragoza, Juan C. Martinez-Sevilla, Carlos Penarrubia, and Antonio Rios-Vila. 2023. Optical Music Recognition: Recent Advances, Current Chal- lenges, and Future Directions. InDocument Analysis and Recognition – ICDAR 2023 Workshops, Mickael Coustaty and Alicia Fornés (Eds.). Springer Nature Switzerland, Cham, 94–104
2023
-
[8]
Jorge Calvo-Zaragoza and David Rizo. 2018. End-to-end neural optical music recognition of monophonic scores.Applied Sciences8, 4 (2018), 606
2018
-
[9]
Luca Casini and Bob Sturm. 2022. Tradformer: A transformer model of traditional music transcriptions. InInternational Joint Conference on Artificial Intelligence IJCAI 2022, Vienna, Austria, 23-29 July 2022. 4915–4920
2022
- [10]
-
[11]
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. 2023. Qwen-Audio: Advancing Univer- sal Audio Understanding via Unified Large-Scale Audio-Language Models. arXiv:2311.07919 [eess.AS] https://arxiv.org/abs/2311.07919
work page internal anchor Pith review arXiv 2023
-
[12]
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. 2023. Simple and controllable music generation. Advances in neural information processing systems36 (2023), 47704–47720
2023
- [13]
-
[14]
Carlos Garrido-Munoz, Antonio Rios-Vila, and Jorge Calvo-Zaragoza. 2022. A holistic approach for image-to-graph: application to optical music recognition: C. Garrido-Munoz et al.International Journal on Document Analysis and Recognition (IJDAR)25, 4 (2022), 293–303
2022
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
- [17]
-
[18]
Wen-Yi Hsiao, Jen-Yu Liu, Yin-Cheng Yeh, and Yi-Hsuan Yang. 2021. Compound word transformer: Learning to compose full-song music over dynamic directed hypergraphs. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 178–186
2021
- [19]
-
[20]
Yu-Siang Huang and Yi-Hsuan Yang. 2020. Pop music transformer: Beat-based modeling and generation of expressive pop piano compositions. InProceedings of the 28th ACM international conference on multimedia. 1180–1188
2020
-
[21]
Jinjing Jiang, Nicole Teo, Haibo Pen, Seng-Beng Ho, and Zhaoxia Wang. 2024. Converting vocal performances into sheet music leveraging large language mod- els. In2024 IEEE International Conference on Data Mining Workshops (ICDMW). IEEE, 445–452
2024
-
[22]
Qiuqiang Kong, Bochen Li, Xuchen Song, Yuan Wan, and Yuxuan Wang. 2021. High-resolution piano transcription with pedals by regressing onset and offset times.IEEE/ACM Transactions on Audio, Speech, and Language Processing29 (2021), 3707–3717
2021
-
[23]
Vladimir I Levenshtein et al. 1966. Binary codes capable of correcting deletions, insertions, and reversals. InSoviet physics doklady, Vol. 10. Soviet Union, 707–710
1966
-
[24]
Dichucheng Li, Yongyi Zang, and Qiuqiang Kong. 2025. Piano Transcription by Hierarchical Language Modeling with Pretrained Roll-based Encoders. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
-
[25]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
2023
-
[26]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
- [27]
-
[28]
Peiling Lu, Xin Xu, Chenfei Kang, Botao Yu, Chengyi Xing, Xu Tan, and Jiang Bian
-
[29]
Musecoco: Generating symbolic music from text,
MuseCoco: Generating Symbolic Music from Text. arXiv:2306.00110 [cs.SD] https://arxiv.org/abs/2306.00110
-
[30]
Haoran Luo, Haihong E, Guanting Chen, Qika Lin, Yikai Guo, Fangzhi Xu, Zemin Kuang, Meina Song, Xiaobao Wu, Yifan Zhu, and Luu Anh Tuan. 2025. Graph-R1: Towards Agentic GraphRAG Framework via End-to-end Reinforcement Learning. arXiv:2507.21892 [cs.CL] https://arxiv.org/abs/2507.21892
-
[31]
Haoran Luo, Haihong E, Guanting Chen, Yandan Zheng, Xiaobao Wu, Yikai Guo, Qika Lin, Yu Feng, Zemin Kuang, Meina Song, Yifan Zhu, and Luu Anh Tuan. 2025. HyperGraphRAG: Retrieval-Augmented Generation via Hypergraph-Structured Knowledge Representation. arXiv:2503.21322 [cs.AI] https://arxiv.org/abs/2503. 21322
-
[32]
Haoran Luo, Haihong E, Yikai Guo, Qika Lin, Xiaobao Wu, Xinyu Mu, Wenhao Liu, Meina Song, Yifan Zhu, and Anh Tuan Luu. 2025. KBQA-o1: Agentic Knowl- edge Base Question Answering with Monte Carlo Tree Search. InProceedings of the 42nd International Conference on Machine Learning (Proceedings of Ma- chine Learning Research, Vol. 267), Aarti Singh, Maryam Fa...
2025
-
[33]
Ethan Manilow, Gordon Wichern, Prem Seetharaman, and Jonathan Le Roux
-
[34]
In2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (W ASPAA)
Cutting music source separation some Slakh: A dataset to study the impact of training data quality and quantity. In2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (W ASPAA). IEEE, 45–49
-
[35]
1996.MIDI 1.0 Detailed Specification
MIDI Manufacturers Association. 1996.MIDI 1.0 Detailed Specification. MIDI Manufacturers Association, Los Angeles, CA
1996
-
[36]
MuseScore BVBA. 2024. MuseScore: Create, play and print beautiful sheet music. https://musescore.org/
2024
-
[37]
OpenAI. 2024. Hello GPT-4o. https://openai.com/index/hello-gpt-4o/
2024
-
[38]
Alexander Pacha, Jan Hajič Jr, and Jorge Calvo-Zaragoza. 2018. A baseline for general music object detection with deep learning.Applied Sciences8, 9 (2018), 1488
2018
- [39]
-
[40]
2016.Learning-Based Methods for Comparing Sequences, with Appli- cations to Audio-to-MIDI Alignment and Matching
Colin Raffel. 2016.Learning-Based Methods for Comparing Sequences, with Appli- cations to Audio-to-MIDI Alignment and Matching. Ph. D. Dissertation. Columbia University
2016
-
[41]
Paul K Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, et al. 2023. Audiopalm: A large language model that can speak and listen.arXiv preprint arXiv:2306.12925(2023)
- [42]
- [43]
- [44]
-
[45]
Gemini Team. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. (2024). arXiv:2403.05530 [cs.CL] https://arxiv.org/ abs/2403.05530
work page internal anchor Pith review arXiv 2024
-
[46]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Chris Walshaw. 2011. The abc music standard 2.1.URL: http://abcnotation. com/wiki/abc: standard: v21 (2011). Conference’17, July 2017, Washington, DC, USA Menghe Ma *, Siqing Wei*, Yuecheng Xing*, Yaheng Wang, Fanhong Meng, Peijun Han, Luu Anh Tuan, and Haoran Luo †
2011
- [48]
-
[49]
Andrew Wiggins and Youngmoo E Kim. 2019. Guitar Tablature Estimation with a Convolutional Neural Network.. InISMIR. 284–291
2019
-
[50]
Jiayang Wu, Wensheng Gan, Zefeng Chen, Shicheng Wan, and Philip S Yu
-
[51]
In2023 IEEE International Conference on Big Data (BigData)
Multimodal large language models: A survey. In2023 IEEE International Conference on Big Data (BigData). IEEE, 2247–2256
-
[52]
Jun Wu and Wanshan Guo. 2026. Autoregressive ConvNeXt-transformer fusion framework for polyphonic optical music recognition with focal loss optimization. Acoustical Science and Technology47, 2 (2026), 86–96
2026
- [53]
-
[54]
Qingyang Xi, Rachel M Bittner, Johan Pauwels, Xuzhou Ye, and Juan Pablo Bello
-
[55]
Proceedings of the 19th International Society for Music Information
GuitarSet: A Dataset for Guitar Transcription. Proceedings of the 19th International Society for Music Information
-
[56]
Yujia Yan and Zhiyao Duan. 2024. Measure by measure: Measure-based automatic music composition with modern staff notation.Transactions of the International Society for Music Information Retrieval(2024)
2024
-
[57]
Ruibin Yuan, Hanfeng Lin, Yi Wang, Zeyue Tian, Shangda Wu, Tianhao Shen, Ge Zhang, Yuhang Wu, Cong Liu, Ziya Zhou, et al. 2024. Chatmusician: Under- standing and generating music intrinsically with llm. (2024), 6252–6271
2024
-
[58]
Shenghua Yuan, Xing Tang, Jiatao Chen, Tianming Xie, Jing Wang, and Bing Shi
- [59]
-
[60]
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, et al . 2024. Anygpt: Unified multimodal llm with discrete sequence modeling. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 9637–9662. ONOTE: Benchmarking Omnimodal Notat...
2024
-
[61]
The sum of rhythmic values between two| symbols must equal 4.0
Rhythmic Verification:A correct score contains exactly 4.0 beats per measure. The sum of rhythmic values between two| symbols must equal 4.0. (Score 5: All correct; Score 3: Half correct; Score 1: All incorrect)
-
[62]
(Score 5: Complete motif and beautiful melody; Score 3: Discernible motif; Score 1: Lacks motif, unappealing)
Aesthetic Analysis:Motif development, melodic contour, and rhythmic groove should be rich and logical. (Score 5: Complete motif and beautiful melody; Score 3: Discernible motif; Score 1: Lacks motif, unappealing). Output Constraints:Output ONLY the final scores without analysis. Format:Technical Score: [ ]/5, Aesthetic Score: [ ]/5, Average Score: [ ]/5. ...
-
[63]
(Score 5: All correct; Score 3: Half correct; Score 1: All incorrect)
Rhythmic Verification:Exactly 4.0 beats per measure between|symbols. (Score 5: All correct; Score 3: Half correct; Score 1: All incorrect)
-
[64]
(Score 5: Rich and logical; Score 1: Does not constitute actual music)
Aesthetic Analysis:Evaluate motif, melodic contour (rise/fall of notation numbers), and rhythmic groove. (Score 5: Rich and logical; Score 1: Does not constitute actual music). Output Constraints:Output ONLY the scores without analysis. Format:Technical Score: [ ]/5, Aesthetic Score: [ ]/5, Average Score: [ ]/5. Critic C: ASCII Guitar Tablature Evaluation...
-
[65]
Assuming 4/4 time, characters on each string between two bar lines (|) must be identical, exactly 16 characters per measure
Layout and Timing:The 6 strings must align perfectly vertically. Assuming 4/4 time, characters on each string between two bar lines (|) must be identical, exactly 16 characters per measure. (Score 5: Layout correct, exactly 16 chars/measure; Score 3: Partial errors; Score 1: Mostly incorrect)
-
[66]
(Score 5: Rich range/rhythm; Score 3: Monotonous; Score 1: Illogical)
Musicality Analysis:Voicing should have distinct layers (bass root, middle harmony, high melody). (Score 5: Rich range/rhythm; Score 3: Monotonous; Score 1: Illogical)
-
[67]
A reasonable stretch is a maximum span of 7 frets
Fingering Feasibility:Analyze simultaneous notes in the same column. A reasonable stretch is a maximum span of 7 frets. (Score 5: Logical, rarely ¿7 frets; Score 3: Frequent unreasonable stretches; Score 1: Physically impossible). Output Constraints:Output ONLY the scores without analysis. Format:Technical Layout Score: [ ]/5, Fingering Score: [ ]/5, Musi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.