Recognition: unknown
SpeechParaling-Bench: A Comprehensive Benchmark for Paralinguistic-Aware Speech Generation
Pith reviewed 2026-05-10 00:35 UTC · model grok-4.3
The pith
A benchmark of over 100 paralinguistic features shows current LALMs cannot reliably control or adapt them in generated speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
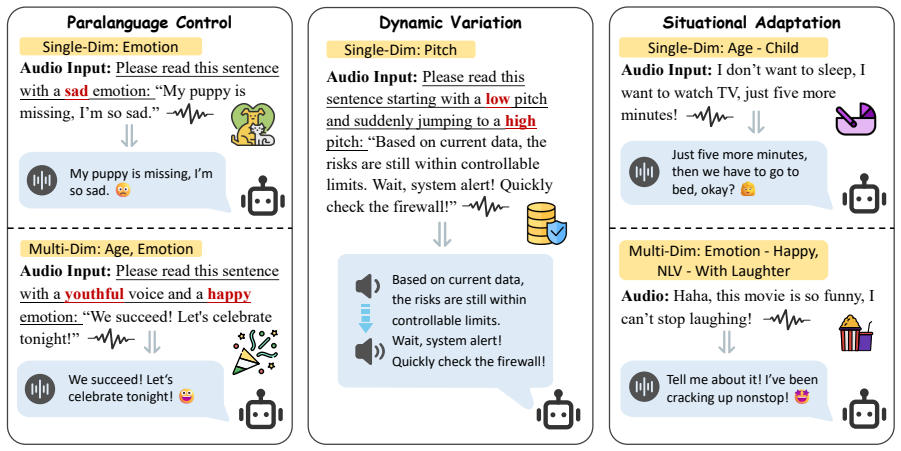
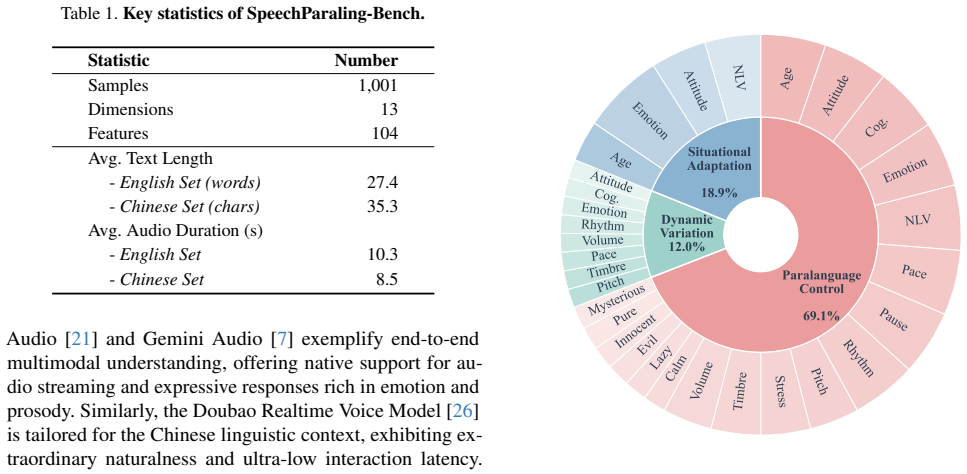
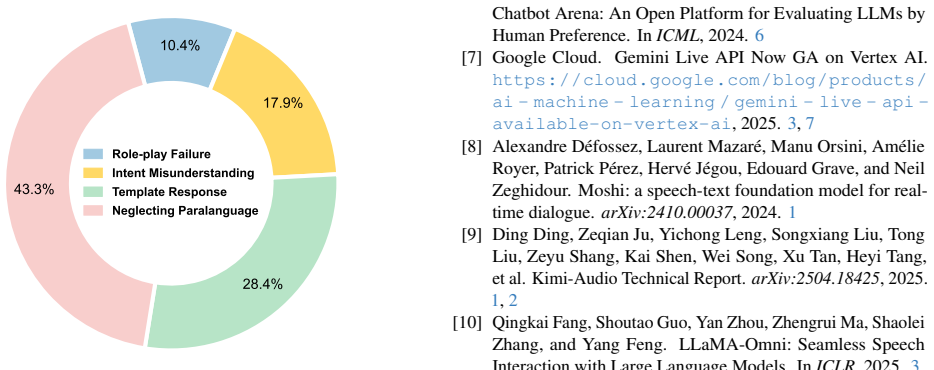
SpeechParaling-Bench expands feature coverage from under 50 to over 100 fine-grained paralinguistic elements supported by more than 1,000 English-Chinese parallel queries and structures evaluation around three tasks of rising complexity: fine-grained control, intra-utterance variation, and context-aware adaptation. Its LALM-based pairwise comparison pipeline frames assessment as relative preference against a fixed baseline, yielding stable judgments without subjective absolute scoring. Results demonstrate that leading models cannot achieve comprehensive static control or dynamic modulation of these features, and that failure to interpret paralinguistic cues accounts for 43.3 percent of all L
What carries the argument
SpeechParaling-Bench benchmark together with its LALM pairwise comparison pipeline that evaluates responses relative to a fixed baseline.
If this is right
- Models must incorporate explicit mechanisms for both static feature setting and intra-utterance dynamic shifts to reach acceptable performance.
- Context-aware adaptation remains the hardest task, indicating that situational understanding is a separate bottleneck from low-level acoustic control.
- Pairwise LALM judging can scale evaluation to new languages or feature sets without repeated human annotation.
- The 43.3 percent error share from cue misinterpretation identifies a high-leverage target for future training data or architectural changes.
Where Pith is reading between the lines
- Adoption of the benchmark could standardize testing across research groups and accelerate progress on voice assistants that sound natural in varied social settings.
- The parallel English-Chinese design makes it feasible to check whether the observed limitations are language-specific or general.
- If models trained on the underlying queries improve on the three tasks, the same data could serve as a diagnostic set for other audio-language systems.
Load-bearing premise
The LALM-based pairwise judge produces stable, unbiased evaluations that reliably stand in for human judgment without introducing its own systematic errors.
What would settle it
Human raters scoring the same set of model outputs on the benchmark tasks produce rankings that systematically differ from the LALM judge on more than a small fraction of cases.
Figures



read the original abstract
Paralinguistic cues are essential for natural human-computer interaction, yet their evaluation in Large Audio-Language Models (LALMs) remains limited by coarse feature coverage and the inherent subjectivity of assessment. To address these challenges, we introduce SpeechParaling-Bench, a comprehensive benchmark for paralinguistic-aware speech generation. It expands existing coverage from fewer than 50 to over 100 fine-grained features, supported by more than 1,000 English-Chinese parallel speech queries, and is organized into three progressively challenging tasks: fine-grained control, intra-utterance variation, and context-aware adaptation. To enable reliable evaluation, we further develop a pairwise comparison pipeline, in which candidate responses are evaluated against a fixed baseline by an LALM-based judge. By framing evaluation as relative preference rather than absolute scoring, this approach mitigates subjectivity and yields more stable and scalable assessments without costly human annotation. Extensive experiments reveal substantial limitations in current LALMs. Even leading proprietary models struggle with comprehensive static control and dynamic modulation of paralinguistic features, while failure to correctly interpret paralinguistic cues accounts for 43.3% of errors in situational dialogue. These findings underscore the need for more robust paralinguistic modeling toward human-aligned voice assistants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpeechParaling-Bench, a benchmark expanding paralinguistic feature coverage from under 50 to over 100 fine-grained attributes across more than 1,000 English-Chinese parallel queries. It defines three tasks (fine-grained control, intra-utterance variation, context-aware adaptation) and employs an LALM-based pairwise preference judge against a fixed baseline to evaluate leading models, concluding that proprietary systems struggle with static/dynamic paralinguistic control and that misinterpretation of cues accounts for 43.3% of errors in situational dialogue.
Significance. If the evaluation protocol proves reliable, the benchmark would address a clear gap in coarse and subjective assessments of paralinguistic awareness in LALMs, providing a scalable resource for future model development in human-aligned speech interfaces. The reported performance gaps could usefully guide research priorities, though the absence of judge validation limits immediate impact.
major comments (3)
- [Evaluation Pipeline] The evaluation pipeline relies on an LALM-based pairwise judge framed as reducing subjectivity, yet no human correlation coefficients, inter-rater agreement statistics, or bias ablation across judge models are reported. This is load-bearing because the headline claims (model struggles and the precise 43.3% cue-interpretation error rate) are derived entirely from the judge's relative preferences.
- [Experiments and Analysis] The 43.3% error attribution in situational dialogue and the feature-selection process for the >100 attributes lack details on query construction, judge prompt templates, or statistical tests for significance. Without these, it is impossible to rule out post-hoc choices or circularity in how errors are categorized.
- [Evaluation Pipeline] No ablation or sensitivity analysis is provided on the fixed baseline used in pairwise comparisons, nor on whether the judge model itself exhibits paralinguistic weaknesses that could systematically bias results against or for certain features.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from explicit statements on benchmark release (data, code, prompts) to enable reproducibility.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We value the constructive criticism provided, which helps strengthen the paper. Below, we address each major comment in detail, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Evaluation Pipeline] The evaluation pipeline relies on an LALM-based pairwise judge framed as reducing subjectivity, yet no human correlation coefficients, inter-rater agreement statistics, or bias ablation across judge models are reported. This is load-bearing because the headline claims (model struggles and the precise 43.3% cue-interpretation error rate) are derived entirely from the judge's relative preferences.
Authors: We agree that empirical validation of the judge is important to support the reliability of our findings. The pairwise preference design was chosen specifically to mitigate the subjectivity inherent in absolute scoring by anchoring comparisons to a fixed baseline. However, we did not report human correlation or inter-rater statistics in the initial submission. In the revised manuscript, we will include a new section with human evaluation results on a representative subset of queries, reporting Pearson and Spearman correlations between the LALM judge and human raters, as well as inter-rater agreement (e.g., Cohen's kappa). We will also perform bias ablation by testing multiple judge models. revision: yes
-
Referee: [Experiments and Analysis] The 43.3% error attribution in situational dialogue and the feature-selection process for the >100 attributes lack details on query construction, judge prompt templates, or statistical tests for significance. Without these, it is impossible to rule out post-hoc choices or circularity in how errors are categorized.
Authors: We appreciate this observation and acknowledge that additional methodological details are necessary for reproducibility and to address concerns about post-hoc analysis. The >100 attributes were selected through a comprehensive literature review of paralinguistic features in speech, and queries were constructed in parallel English-Chinese to ensure linguistic consistency. The 43.3% figure comes from categorizing cases where the judge preferred the baseline due to misinterpretation of contextual cues. In the revision, we will expand the Experiments section to provide: (1) detailed description of the query construction process, (2) the full judge prompt templates, and (3) statistical tests (e.g., chi-square for error category distributions) to confirm significance. This will clarify the categorization process and reduce any perception of circularity. revision: yes
-
Referee: [Evaluation Pipeline] No ablation or sensitivity analysis is provided on the fixed baseline used in pairwise comparisons, nor on whether the judge model itself exhibits paralinguistic weaknesses that could systematically bias results against or for certain features.
Authors: We thank the referee for highlighting the need for sensitivity analysis. The fixed baseline was selected as a strong, publicly available model to provide a consistent reference point across all evaluations. To address potential biases, we will add an ablation study in the revised version where we vary the baseline model and re-run key evaluations. Additionally, we will include an analysis of the judge model's own paralinguistic capabilities by testing it on a held-out set of controlled paralinguistic tasks, reporting any systematic weaknesses that could influence the results. revision: yes
Circularity Check
No circularity: benchmark construction and LALM-judge evaluation are independent of reported results
full rationale
The paper's core contribution is the creation of SpeechParaling-Bench (expanded feature set, 1000+ queries, three tasks) plus a pairwise LALM-based judge framed as relative preference. No equations, fitted parameters, self-citations, or uniqueness theorems are invoked to derive the quantitative claims (e.g., 43.3% error attribution). The reported model limitations are direct empirical outputs of applying the proposed protocol; the judge is an explicit methodological choice, not a self-referential fit or renamed input. This matches the default non-circular case for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LALM-based pairwise judge can produce stable and scalable evaluations that mitigate subjectivity without costly human annotation.
Reference graph
Works this paper leans on
-
[1]
Deep Speech 2 : End-to-End Speech Recognition in English and Mandarin
Dario Amodei, Sundaram Ananthanarayanan, Rishita Anub- hai, Jingliang Bai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro, Qiang Cheng, Guoliang Chen, et al. Deep Speech 2 : End-to-End Speech Recognition in English and Mandarin. InICML, 2016. 1
2016
-
[2]
SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words
Junyi Ao, Yuancheng Wang, Xiaohai Tian, Dekun Chen, Jun Zhang, Lu Lu, Yuxuan Wang, Haizhou Li, and Zhizheng Wu. SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words. InNeurIPS, 2024. 5
2024
-
[3]
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. InNeurIPS, 2020. 1
2020
-
[4]
Listen, attend and spell: A neural network for large vocabulary conversational speech recognition
William Chan, Navdeep Jaitly, Quoc Le, and Oriol Vinyals. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. InICASSP, 2016. 1
2016
-
[5]
Yiming Chen, Xianghu Yue, Chen Zhang, Xiaoxue Gao, Robby T Tan, and Haizhou Li. V oiceBench: Benchmark- ing LLM-Based V oice Assistants.arXiv:2410.17196, 2024. 3
-
[6]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anasta- sios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference. InICML, 2024. 6
2024
-
[7]
Gemini Live API Now GA on Vertex AI
Google Cloud. Gemini Live API Now GA on Vertex AI. https://cloud.google.com/blog/products/ ai - machine - learning / gemini - live - api - available-on-vertex-ai, 2025. 3, 7
2025
-
[8]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real- time dialogue.arXiv:2410.00037, 2024. 1
work page internal anchor Pith review arXiv 2024
-
[9]
Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, et al. Kimi-Audio Technical Report.arXiv:2504.18425, 2025. 1, 2
work page internal anchor Pith review arXiv 2025
-
[10]
LLaMA-Omni: Seamless Speech Interaction with Large Language Models
Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, and Yang Feng. LLaMA-Omni: Seamless Speech Interaction with Large Language Models. InICLR, 2025. 3
2025
-
[11]
Eduardo Fonseca, Xavier Favory, Jordi Pons, Frederic Font, and Xavier Serra
Qingkai Fang, Yan Zhou, Shoutao Guo, Shaolei Zhang, and Yang Feng. LLaMA-Omni2: LLM-based Real-time Spoken Chatbot with Autoregressive Streaming Speech Synthesis. arXiv:2505.02625, 2025. 3
-
[12]
A new era of intelligence with Gemini 3
Google Gemini Team. A new era of intelligence with Gemini 3. https://blog.google/products-and- platforms/products/gemini/gemini- 3/ , 2025. 6
2025
-
[13]
Xuelong Geng, Qijie Shao, Hongfei Xue, Shuiyuan Wang, Hanke Xie, Zhao Guo, Yi Zhao, Guojian Li, Wenjie Tian, Chengyou Wang, et al. OSUM-EChat: Enhancing End-to- End Empathetic Spoken Chatbot via Understanding-Driven Spoken Dialogue.arXiv:2508.09600, 2025. 3, 5
- [14]
-
[15]
S2S-Arena: Evaluating Paralinguistic Instruction Following in Speech-to-Speech Models
Feng Jiang, Zhiyu Lin, Fan Bu, Yuhao Du, Benyou Wang, and Haizhou Li. S2S-Arena, Evaluating Speech2Speech Proto- cols on Instruction Following with Paralinguistic Information. arXiv:2503.05085, 2025. 3, 5
work page internal anchor Pith review arXiv 2025
-
[16]
Televal: A dynamic benchmark designed for spoken language models in chinese interactive sce- narios,
Zehan Li, Hongjie Chen, Yuxin Zhang, Jing Zhou, Xuening Wang, Hang Lv, Mengjie Du, Yaodong Song, Jie Lian, Jian Kang, et al. TELEV AL: A Dynamic Benchmark Designed for Spoken Language Models in Chinese Interactive Scenarios. arXiv:2507.18061, 2025. 5
-
[17]
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
Ziyang Ma, Yinghao Ma, Yanqiao Zhu, Chen Yang, Yi-Wen Chao, Ruiyang Xu, Wenxi Chen, Yuanzhe Chen, Zhuo Chen, Jian Cong, et al. MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix. In NeurIPS, 2025. 3
2025
-
[18]
EmergentTTS-Eval: Evaluating TTS Models on Complex Prosodic, Expressiveness, and Linguistic Chal- lenges Using Model-as-a-Judge
Ruskin Raj Manku, Yuzhi Tang, Xingjian Shi, Mu Li, and Alex Smola. EmergentTTS-Eval: Evaluating TTS Models on Complex Prosodic, Expressiveness, and Linguistic Chal- lenges Using Model-as-a-Judge. InNeurIPS, 2025. 3, 6, 8
2025
-
[19]
Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM
Eliya Nachmani, Alon Levkovitch, Roy Hirsch, Julian Salazar, Chulayuth Asawaroengchai, Soroosh Mariooryad, Ehud Rivlin, RJ Skerry-Ryan, and Michelle Tadmor Ramanovich. Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM. InICLR, 2024. 3 9
2024
-
[20]
ChatGPT can now see, hear, and speak
OpenAI. ChatGPT can now see, hear, and speak. https: //openai.com/index/chatgpt- can- now- see- hear-and-speak/, 2023. 1
2023
-
[21]
Introducing gpt-realtime and realtime api updates for production voice agents
OpenAI. Introducing gpt-realtime and realtime api updates for production voice agents. https://openai.com/ index/introducing-gpt-realtime/, 2025. 3, 7
2025
-
[22]
Qwen3-Omni-Flash-2025-12-01: Hear You
Alibaba Qwen Team. Qwen3-Omni-Flash-2025-12-01: Hear You. See You. Follow Smarter! https://qwen.ai/ blog?id=qwen3-omni-flash-20251201, 2025. 7
2025
-
[23]
FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. FastSpeech 2: Fast and High-Quality End-to-End Text to Speech. InICLR, 2021. 1
2021
-
[24]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
S Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ra- maneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark. InICLR, 2024. 3
2024
-
[25]
wav2vec: Unsupervised pre-training for speech recognition
Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli. wav2vec: Unsupervised pre-training for speech recognition. InInterspeech, 2019. 1
2019
-
[26]
Doubao Realtime V oice Model
Bytedance Seed. Doubao Realtime V oice Model. https: //seed.bytedance.com/en/realtime_voice/ ,
-
[27]
Mmsu: A massive multi-task spoken language understanding and reasoning benchmark, 2025
Dingdong Wang, Jincenzi Wu, Junan Li, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, and Helen Meng. MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark.arXiv:2506.04779, 2025. 3
-
[28]
Freeze-Omni: A Smart and Low Latency Speech-to-speech Dialogue Model with Frozen LLM
Xiong Wang, Yangze Li, Chaoyou Fu, Yunhang Shen, Lei Xie, Ke Li, Xing Sun, and Long Ma. Freeze-Omni: A Smart and Low Latency Speech-to-speech Dialogue Model with Frozen LLM. InICLR, 2025. 3
2025
-
[29]
Tacotron: Towards End- to-End Speech Synthesis
Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, et al. Tacotron: Towards End- to-End Speech Synthesis. InInterspeech, 2017. 1
2017
-
[30]
Step-audio 2 technical report, 2025
Boyong Wu, Chao Yan, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, et al. Step-Audio 2 Technical Report.arXiv:2507.16632,
-
[31]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, et al. Qwen2.5-Omni Technical Report.arXiv:2503.20215,
work page internal anchor Pith review arXiv
-
[32]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, Bin Zhang, Ziyang Ma, Xipin Wei, Shuai Bai, Keqin Chen, Xuejing Liu, Peng Wang, Mingkun Yang, Day- iheng Liu, Xingzhang Ren, B...
work page internal anchor Pith review arXiv
-
[33]
AIR-Bench: Benchmarking Large Audio- Language Models via Generative Comprehension
Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zhou Zhao, Chang Zhou, et al. AIR-Bench: Benchmarking Large Audio- Language Models via Generative Comprehension. InACL,
-
[34]
ParaS2S: Benchmarking and Aligning Spoken Language Models for Paralinguistic-aware Speech-to-Speech Interaction
Shu-wen Yang, Ming Tu, Andy T Liu, Xinghua Qu, Hung- yi Lee, Lu Lu, Yuxuan Wang, and Yonghui Wu. ParaS2S: Benchmarking and Aligning Spoken Language Models for Paralinguistic-aware Speech-to-Speech Interaction. InICLR,
-
[35]
A survey on multimodal large language models.National Science Review, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 2024. 1
2024
-
[36]
Aohan Zeng, Zhengxiao Du, Mingdao Liu, Kedong Wang, Shengmin Jiang, Lei Zhao, Yuxiao Dong, and Jie Tang. GLM- 4-V oice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot.arXiv:2412.02612, 2024. 1
-
[37]
VStyle: A benchmark for voice style adaptation with spoken instructions,
Jun Zhan, Mingyang Han, Yuxuan Xie, Chen Wang, Dong Zhang, Kexin Huang, Haoxiang Shi, DongXiao Wang, Tengtao Song, Qinyuan Cheng, et al. VStyle: A Bench- mark for V oice Style Adaptation with Spoken Instructions. arXiv:2509.09716, 2025. 5
-
[38]
Mimo-audio: Audio language models are few-shot learners
Dong Zhang, Gang Wang, Jinlong Xue, Kai Fang, Liang Zhao, Rui Ma, Shuhuai Ren, Shuo Liu, Tao Guo, Weiji Zhuang, et al. MiMo-Audio: Audio Language Models are Few-Shot Learners.arXiv:2512.23808, 2025. 1, 2
-
[39]
IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto- Regressive Zero-Shot Text-to-Speech
Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, and Jingchen Shu. IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto- Regressive Zero-Shot Text-to-Speech. InAAAI, 2026. 5 10 A. Descriptions of Paralinguistic Features We list paralinguistic dimensions, their descriptions, and possible values (i.e., paralinguis...
2026
-
[40]
Generate 3 sets of unique Chinese and English instructions for each element in the set. Each set must meet the generation requirements, have the exact same meaning (differing only in language), and include only one element from the set as the paralinguistic feature requirement
-
[41]
The sentences requested for repetition must match the required paralinguistic features to form a natural and credible expression
-
[42]
The sentences for the voice model to repeat should be approximately 50 characters/words long, without hint markers such as () or []
-
[43]
Scenarios should cover daily life scenes: •Daily routines (washing up, dressing/grooming, making the bed, morning skincare, bedtime relaxation) • Campus (dining in the canteen, self-study in the library, dormitory chatting, classroom interaction, club activities) • Workplace (office collaboration, meeting discussions, remote work, professional socializing...
-
[44]
prompt":
Ensure the text content is rich and diverse, avoiding repetitive scenarios and expressions. Generation Output Format: • JSONL format, one JSON object per line. Each set of instructions occupies two lines without breaks between sets: one line in Chinese and one line in English, identical in meaning, differing only in language, and both adhering to the corr...
-
[45]
You must strictly adhere to the evaluation criterion and scoring standard below
-
[46]
You are acting as a Model-as-a-Judge and should aim to **predict human preference**
-
[47]
Your analysis shall be assessed against the requirements specified in {demand} and {dims_str}
-
[48]
Your analysis must be grounded in the audio, using **precise timestamps** to justify your findings. 13
-
[49]
significant) between T1 and T2
Resolve borderline cases by articulating fine-grained distinctions (subtle vs. significant) between T1 and T2
-
[50]
**If the generated audio is extremely poor or the content is empty, you must assign a score of 0 to that LALM’s audio.** Required Reasoning Procedure (Strict): For each of T1 and T2, you must:
-
[51]
Identify which parts of the text prompt {demand} require emotional or stylistic expression
-
[52]
Provide **timestamps** for the key expressive segments
-
[53]
Analyze whether the expression matches the intended {dims_str}
-
[54]
For each dimension of {dims_str}, provide a **comparative analysis** highlighting key differences between T1 and T2, annotated as either subtle or significant
-
[55]
For each dimension of {dims_str}, give a final score (0–3) with justification
-
[56]
(Noticement) Anti-Bias Factors: You must **only** compare the two models based on the **Evaluation Dimensions**
The evaluation of each dimension in {dims_str} should be **mutually independent**. (Noticement) Anti-Bias Factors: You must **only** compare the two models based on the **Evaluation Dimensions**. This means you **must not** let the following types of bias influence your judgment:
-
[57]
The speaker’s gender and voice characteristics
-
[58]
Any other factor unrelated to the **evaluation_dimension**
-
[59]
Evaluations for each paralinguistic dimension must be **INDEPENDENT OF ONE ANOTHER**, which means judgments regarding the performance of the current dimension should not be influenced by the performance of other dimensions
-
[60]
(Criteria) The goal is to judge whether each large audio language model correctly and naturally expresses the required controllable characteristic(s): {dims_str}
Models exhibiting exaggerated expressiveness should **not** receive extra reward **unless** those features are relevant to the **evaluation_dimension**. (Criteria) The goal is to judge whether each large audio language model correctly and naturally expresses the required controllable characteristic(s): {dims_str}. You must evaluate or follow:
-
[61]
**Content Accuracy:** How perfectly the spoken content matches the required text script, without any errors (mispronunciations, omissions, additions, or ambiguous phonetics)
-
[62]
**Fluency and Naturalness:** How natural and human-like the pace, pauses, and prosody are, without electronic noise, stutters, or mechanical sounds
-
[63]
**Paralinguistic Compliance - CORE:** Whether the target characteristic/tone/emotion(s) in the feature dimen- sion: dims_str is(are) accurately conveyed
-
[64]
If {dims_str} contains multiple dimensions, please assign a **separate score** to each dimension
-
[65]
vivid and spot-on
If the first two points show no obvious flaws, the focus should be on evaluating **the third CORE point**. Detailed Scoring Standard (0–3): • 0 = Completely incorrect ·**Content Accuracy:** V oice content is clearly inconsistent with the script, or the meaning is completely changed due to major errors/omissions. ·**Fluency and Naturalness:** Obvious stutt...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.