Chain of Evidence: Pixel-Level Visual Attribution for Iterative Retrieval-Augmented Generation
Pith reviewed 2026-05-09 14:42 UTC · model grok-4.3
The pith
Vision-language models can deliver pixel-level visual evidence chains for iterative retrieval-augmented generation by operating directly on document screenshots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Chain of Evidence is a retriever-agnostic framework in which a vision-language model reasons over raw document screenshots to output precise bounding boxes that visualize the complete chain of evidence supporting an answer to a complex question.
What carries the argument
Chain of Evidence (CoE), a retriever-agnostic visual attribution framework that leverages vision-language models to reason directly over screenshots and generate pixel-level bounding-box outputs.
If this is right
- The framework removes dependence on format-specific parsing tools for documents such as PDFs or slides.
- Users receive visual traces that show exactly which image regions support each step of the reasoning chain.
- Performance gains appear on tasks involving free-form layouts and complex diagrams where text conversion discards key cues.
- The method remains independent of whichever retriever supplies the candidate documents.
Where Pith is reading between the lines
- This approach could extend naturally to other image-rich sources such as scientific figures or scanned legal documents without new parsers.
- Widespread use might reduce the frequency of reasoning errors that arise from missing spatial relationships in text-only pipelines.
- The same screenshot-based attribution could be tested on video frames to handle dynamic evidence chains.
Load-bearing premise
Vision-language models applied to raw document screenshots can reliably recover the spatial logic and layout cues that are discarded when converting documents to text.
What would settle it
Run the model on SlideVQA screenshots that contain diagrams whose layout is essential to the correct answer; if the output bounding boxes fail to highlight the specific visual regions that supply the necessary spatial information, the central claim is falsified.
Figures




read the original abstract
Iterative Retrieval-Augmented Generation (iRAG) has emerged as a powerful paradigm for answering complex multi-hop questions by progressively retrieving and reasoning over external documents. However, current systems predominantly operate on parsed text, which creates two critical bottlenecks: (1) \textit{Coarse-grained attribution}, where users are burdened with manually locating evidence within lengthy documents based on vague text-level citations; and (2) \textit{Visual semantic loss}, where the conversion of visually rich documents (e.g., slides, PDFs with charts) into text discards spatial logic and layout cues essential for reasoning. To bridge this gap, we present \textbf{Chain of Evidence (CoE)}, a retriever-agnostic visual attribution framework that leverages Vision-Language Models to reason directly over screenshots of retrieved document candidates. CoE eliminates format-specific parsing and outputs precise bounding boxes, visualizing the complete reasoning chain within the retrieved candidate set. We evaluate CoE on two distinct benchmarks: \textbf{Wiki-CoE}, a large-scale dataset of structured web pages derived from 2WikiMultiHopQA, and \textbf{SlideVQA}, a challenging dataset of presentation slides featuring complex diagrams and free-form layouts. Experiments demonstrate that fine-tuned Qwen3-VL-8B-Instruct achieves robust performance, significantly outperforming text-based baselines in scenarios requiring visual layout understanding, while establishing a retriever-agnostic solution for pixel-level interpretable iRAG. Our code is available at https://github.com/PeiYangLiu/CoE.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Chain of Evidence (CoE), a retriever-agnostic visual attribution framework for iterative Retrieval-Augmented Generation (iRAG). It uses Vision-Language Models to directly process screenshots of retrieved document candidates, outputting precise bounding boxes for evidence rather than relying on parsed text. This addresses two bottlenecks in existing systems: coarse-grained attribution and visual semantic loss from text conversion of rich documents like slides and PDFs. The framework is evaluated on two new benchmarks—Wiki-CoE (structured web pages derived from 2WikiMultiHopQA) and SlideVQA (complex slide layouts with diagrams)—with the central result that fine-tuned Qwen3-VL-8B-Instruct achieves robust performance and significantly outperforms text-based baselines in scenarios requiring visual layout understanding, while providing pixel-level interpretable iRAG. Code is released at a GitHub repository.
Significance. If the empirical results hold with adequate verification, this could be a meaningful contribution to multimodal RAG and visual document reasoning. Preserving spatial and layout cues via direct screenshot processing offers a practical alternative to format-specific parsers, improving both accuracy and interpretability for complex documents. The retriever-agnostic design and pixel-level bounding box outputs enhance usability in iRAG pipelines. Introducing two distinct benchmarks adds reusable resources for the community, and the open code supports reproducibility.
major comments (2)
- [Abstract] Abstract: The central claim that 'fine-tuned Qwen3-VL-8B-Instruct achieves robust performance, significantly outperforming text-based baselines' is presented without any quantitative metrics, error bars, ablation studies, or specific performance numbers. This omission in the abstract, combined with unavailable full methods and data splits, makes the load-bearing empirical result difficult to assess or verify at the level required for a serious journal.
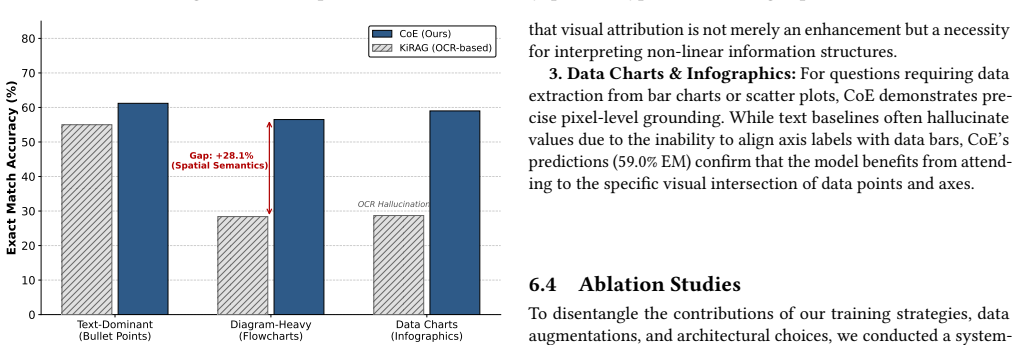
- [Evaluation] Evaluation section (implied by benchmark descriptions): The paper positions the VLM-on-screenshot approach as reliably recovering spatial logic and layout cues without format-specific parsing or extra supervision, but provides no ablations or failure-case analysis on when this assumption breaks (e.g., for low-contrast slides or dense charts). This is load-bearing for the claim of retriever-agnostic robustness on SlideVQA.
minor comments (2)
- [Benchmarks] Ensure all benchmark construction details, including data splits and annotation protocols for Wiki-CoE and SlideVQA, are fully documented in the main text or appendix to support reproducibility.
- [Abstract and Introduction] The abstract and introduction use 'CoE' for both the framework and the Wiki-CoE benchmark; clarify the distinction in notation to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and evaluation. We address each major comment below and will incorporate revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'fine-tuned Qwen3-VL-8B-Instruct achieves robust performance, significantly outperforming text-based baselines' is presented without any quantitative metrics, error bars, ablation studies, or specific performance numbers. This omission in the abstract, combined with unavailable full methods and data splits, makes the load-bearing empirical result difficult to assess or verify at the level required for a serious journal.
Authors: We agree that the abstract would benefit from including key quantitative metrics to better support the central claim. The full manuscript details the experimental setup, methods, and data splits in Sections 3 and 4, with all code and datasets released at the provided GitHub repository for verification. The Experiments section contains performance tables with specific metrics, standard deviations across runs, and baseline comparisons. In the revised manuscript, we will update the abstract to incorporate representative quantitative results (e.g., accuracy gains on Wiki-CoE and SlideVQA) while maintaining conciseness. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by benchmark descriptions): The paper positions the VLM-on-screenshot approach as reliably recovering spatial logic and layout cues without format-specific parsing or extra supervision, but provides no ablations or failure-case analysis on when this assumption breaks (e.g., for low-contrast slides or dense charts). This is load-bearing for the claim of retriever-agnostic robustness on SlideVQA.
Authors: We acknowledge that explicit ablations and failure-case analysis would further substantiate the robustness claims, particularly for challenging cases on SlideVQA. The current evaluation demonstrates consistent outperformance on visual-layout tasks through direct screenshot processing, but does not include dedicated breakdowns for edge cases such as low-contrast elements or dense charts. In the revision, we will add a new subsection to the evaluation discussing limitations and providing qualitative examples of failure modes, along with expanded comparisons to support the retriever-agnostic design. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an applied engineering system (CoE) that applies a fine-tuned VLM directly to document screenshots for bounding-box attribution in iRAG. All load-bearing claims rest on empirical results from two held-out benchmarks (Wiki-CoE derived from 2WikiMultiHopQA and SlideVQA) rather than any derivation, equation, or fitted quantity that reduces to its own inputs. No self-definitional loops, predictions that are statistically forced by construction, or load-bearing self-citations appear in the abstract or method outline. The retriever-agnostic positioning and visual-layout recovery are presented as independent contributions evaluated externally to the training data, rendering the reported performance self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can identify and localize supporting evidence regions in document screenshots at pixel level without format-specific parsing
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.