Recognition: unknown
MDN: Parallelizing Stepwise Momentum for Delta Linear Attention
Pith reviewed 2026-05-09 15:25 UTC · model grok-4.3
The pith
Geometrically reordering momentum coefficients turns sequential stepwise updates into a chunkwise parallel algorithm for linear attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
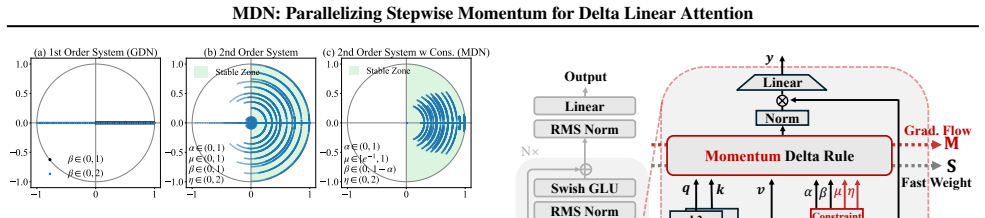
By geometrically reordering the coefficients of the stepwise momentum rule, the linear recurrence of delta attention can be executed in parallel chunks. The same reordering yields a second-order dynamical system whose complex conjugate eigenvalues guide the choice of gating constraints that keep training stable. The resulting model runs at throughput comparable to other linear attention methods and shows consistent gains on downstream tasks for models at the 400M and 1.3B scale.
What carries the argument
The geometrically reordered stepwise momentum update rule, which converts the original sequential momentum recurrence into an equivalent chunkwise parallel form while preserving the second-order eigenvalue structure.
If this is right
- The parallel form delivers measurable accuracy gains over standard linear attention baselines on diverse language-modeling tasks at both 400M and 1.3B scale.
- Training throughput remains comparable to other linear attention implementations when implemented with fused kernels.
- The eigenvalue analysis supplies explicit constraints on the gating parameters that keep the second-order system stable during training.
Where Pith is reading between the lines
- The same geometric reordering idea may extend to other higher-order optimizers expressed as linear recurrences.
- The eigenvalue perspective could be used to derive stability conditions for momentum-augmented variants of other linear attention families.
- If the reordered rule truly matches sequential dynamics, it opens the possibility of hybrid training schedules that alternate between sequential and chunkwise momentum phases without changing the learned weights.
Load-bearing premise
Geometrically reordering the momentum update coefficients preserves the intended optimization dynamics and stability properties of the original stepwise momentum rule while enabling efficient parallel execution.
What would settle it
A direct side-by-side run of the sequential stepwise momentum rule versus the geometrically reordered version on the same data and architecture that shows materially different convergence speed or final loss would falsify the preservation claim.
Figures





read the original abstract
Linear Attention (LA) offers a promising paradigm for scaling large language models (LLMs) to long sequences by avoiding the quadratic complexity of self-attention. Recent LA models such as Mamba2 and GDN interpret linear recurrences as closed-form online stochastic gradient descent (SGD), but naive SGD updates suffer from rapid information decay and suboptimal convergence in optimization. While momentum-based optimizers provide a natural remedy, they pose challenges in simultaneously achieving training efficiency and effectiveness. To address this, we develop a chunkwise parallel algorithm for LA with a stepwise momentum rule by geometrically reordering the update coefficients. Further, from a dynamical systems perspective, we analyze the momentum-based recurrence as a second-order system that introduces complex conjugate eigenvalues. This analysis guides the design of stable gating constraints. The resulting model, Momentum DeltaNet (MDN), leverages Triton kernels to achieve comparable training throughput with competitive linear models such as Mamba2 and KDA. Extensive experiments on the 400M and 1.3B parameter models demonstrate consistent performance improvements over strong baselines, including Transformers, Mamba2 and GDN, across diverse downstream evaluation benchmarks. Code: https://github.com/HuuYuLong/MomentumDeltaNet .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Momentum DeltaNet (MDN), a linear attention architecture that incorporates a stepwise momentum rule into Delta Linear Attention. It develops a chunkwise parallel algorithm obtained by geometrically reordering the momentum update coefficients, analyzes the resulting recurrence from a dynamical-systems perspective as a second-order system with complex conjugate eigenvalues to derive stable gating constraints, and reports consistent performance gains on 400M and 1.3B parameter models over Transformers, Mamba2, and GDN across downstream benchmarks while maintaining comparable training throughput via Triton kernels.
Significance. If the reordering preserves the intended momentum dynamics and the stability analysis transfers, the work offers a principled route to mitigate rapid information decay in linear attention while retaining linear complexity and efficient parallel execution. The explicit use of dynamical-systems analysis to constrain gating and the scaling to 1.3B models are positive features; reproducible code is also provided.
major comments (2)
- [Section describing the chunkwise parallel algorithm and the subsequent dynamical-systems analysis] The central technical claim rests on the chunkwise parallel algorithm obtained by geometrically reordering the stepwise momentum coefficients. It is not shown whether this reordering yields a mathematically equivalent recurrence to the original sequential rule (or at least preserves the effective damping and accumulation order). Without an explicit equivalence proof or a demonstration that the second-order eigenvalue analysis remains valid under the reordering, the stability guarantees cannot be confidently linked to the reported performance gains.
- [Experimental results and ablation studies] The experimental section reports consistent improvements on 400M and 1.3B models, yet the manuscript provides no ablation isolating the contribution of the momentum rule versus the reordering itself, nor error bars or statistical significance tests across runs. This weakens the attribution of gains specifically to the proposed momentum mechanism.
minor comments (2)
- [Abstract] The abstract would be strengthened by including the key recurrence or a concise statement of the reordering operation.
- [Method section] Notation for the momentum coefficients and the chunk boundaries should be introduced earlier and used consistently in the algorithm description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. Below, we address each major comment in detail and indicate the revisions we plan to make to the manuscript.
read point-by-point responses
-
Referee: [Section describing the chunkwise parallel algorithm and the subsequent dynamical-systems analysis] The central technical claim rests on the chunkwise parallel algorithm obtained by geometrically reordering the stepwise momentum coefficients. It is not shown whether this reordering yields a mathematically equivalent recurrence to the original sequential rule (or at least preserves the effective damping and accumulation order). Without an explicit equivalence proof or a demonstration that the second-order eigenvalue analysis remains valid under the reordering, the stability guarantees cannot be confidently linked to the reported performance gains.
Authors: We agree that an explicit proof of equivalence would strengthen the presentation. The geometric reordering is constructed to ensure that the chunkwise parallel computation produces identical results to the sequential momentum updates for the same sequence of inputs, thereby preserving the damping factors and accumulation order. In the revised manuscript, we will include a formal proof demonstrating this equivalence by induction over the chunks, showing that the parallel form matches the sequential recurrence exactly. Furthermore, since the reordering does not change the local recurrence relation, the dynamical systems analysis and the resulting eigenvalue-based stability constraints remain valid. We will also add a brief discussion clarifying how this equivalence ensures the stability guarantees apply to the implemented model. revision: yes
-
Referee: [Experimental results and ablation studies] The experimental section reports consistent improvements on 400M and 1.3B models, yet the manuscript provides no ablation isolating the contribution of the momentum rule versus the reordering itself, nor error bars or statistical significance tests across runs. This weakens the attribution of gains specifically to the proposed momentum mechanism.
Authors: We acknowledge that the current experimental section lacks ablations separating the momentum rule from the reordering and does not include error bars or significance tests. In the revision, we will add ablation experiments comparing MDN with a variant that uses the same reordering but without the momentum term (i.e., reducing to standard DeltaNet). We will also rerun the main experiments with multiple random seeds to report mean and standard deviation, and include statistical significance tests (e.g., paired t-tests) against baselines to better attribute the performance gains to the momentum mechanism. revision: yes
Circularity Check
No significant circularity; derivation is self-contained design and analysis
full rationale
The paper's core steps—developing a chunkwise parallel algorithm by geometrically reordering stepwise momentum coefficients, then analyzing the recurrence as a second-order dynamical system with complex conjugate eigenvalues to guide stable gating—are presented as independent technical contributions. No equations reduce by construction to fitted inputs or prior self-citations; the reordering is a deliberate algorithmic transformation for parallelism, and the eigenvalue analysis supplies constraints rather than being retrofitted to performance numbers. Experiments on 400M/1.3B models provide external validation, keeping the chain non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xiang Liu and Zhenheng Tang and Peijie Dong and Zeyu Li and Liuyue and Bo Li and Xuming Hu and Xiaowen Chu , booktitle=. Chunk. 2026 , url=
2026
-
[2]
DiffAdapt: Difficulty-Adaptive Reasoning for Token-Efficient
Xiang Liu and Xuming Hu and Xiaowen Chu and Eunsol Choi , booktitle=. DiffAdapt: Difficulty-Adaptive Reasoning for Token-Efficient. 2026 , url=
2026
-
[3]
Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Networks , year=
Schmidhuber, Jürgen , journal=. Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Networks , year=
-
[4]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Griffin: Mixing gated linear recurrences with local attention for efficient language models , author=. arXiv preprint arXiv:2402.19427 , year=
work page internal anchor Pith review arXiv
-
[5]
Advances in Neural Information Processing Systems , volume=
xlstm: Extended long short-term memory , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
RWKV: Reinventing RNNs for the Transformer Era
Rwkv: Reinventing rnns for the transformer era , author=. arXiv preprint arXiv:2305.13048 , year=
work page internal anchor Pith review arXiv
-
[7]
Transformers are
Tri Dao and Albert Gu , booktitle=. Transformers are. 2024 , url=
2024
-
[8]
Advances in Neural Information Processing Systems , volume=
Hierarchically gated recurrent neural network for sequence modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Eagle and finch: Rwkv with matrix-valued states and dynamic recurrence
Eagle and finch: Rwkv with matrix-valued states and dynamic recurrence , author=. arXiv preprint arXiv:2404.05892 , year=
-
[10]
Rethinking Attention with Performers
Rethinking attention with performers , author=. arXiv preprint arXiv:2009.14794 , year=
work page internal anchor Pith review arXiv 2009
-
[11]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[12]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Boolq: Exploring the surprising difficulty of natural yes/no questions , author=. arXiv preprint arXiv:1905.10044 , year=
work page internal anchor Pith review arXiv 1905
-
[13]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Can a suit of armor conduct electricity? a new dataset for open book question answering , author=. arXiv preprint arXiv:1809.02789 , year=
work page internal anchor Pith review arXiv
-
[14]
Scientific Reports , year=
The SciQA Scientific Question Answering Benchmark for Scholarly Knowledge , author=. Scientific Reports , year=
-
[15]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[17]
HellaSwag: Can a Machine Really Finish Your Sentence?
Hellaswag: Can a machine really finish your sentence? , author=. arXiv preprint arXiv:1905.07830 , year=
work page internal anchor Pith review arXiv 1905
-
[18]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[19]
Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
The LAMBADA dataset: Word prediction requiring a broad discourse context , author=. Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[20]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Advances in neural information processing systems , volume=
Root mean square layer normalization , author=. Advances in neural information processing systems , volume=
-
[22]
GLU Variants Improve Transformer
Glu variants improve transformer , author=. arXiv preprint arXiv:2002.05202 , year=
work page internal anchor Pith review arXiv 2002
-
[23]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[24]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Going deeper with image transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[25]
Zoology: Measuring and improving recall in efficient language models
Zoology: Measuring and improving recall in efficient language models , author=. arXiv preprint arXiv:2312.04927 , year=
-
[26]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Tc-lif: A two-compartment spiking neuron model for long-term sequential modelling , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[27]
Nature communications , volume=
A solution to the learning dilemma for recurrent networks of spiking neurons , author=. Nature communications , volume=. 2020 , publisher=
2020
-
[28]
Neural computation , volume=
Superspike: Supervised learning in multilayer spiking neural networks , author=. Neural computation , volume=. 2018 , publisher=
2018
-
[29]
The Twelfth International Conference on Learning Representations , year=
A Progressive Training Framework for Spiking Neural Networks with Learnable Multi-hierarchical Model , author=. The Twelfth International Conference on Learning Representations , year=
-
[30]
Advances in neural information processing systems , volume=
Combining recurrent, convolutional, and continuous-time models with linear state space layers , author=. Advances in neural information processing systems , volume=
-
[31]
FLA: A Triton-Based Library for Hardware-Efficient Implementations of Linear Attention Mechanism , author =
-
[32]
Proceedings of ICLR , year =
Gated Delta Networks: Improving Mamba2 with Delta Rule , author =. Proceedings of ICLR , year =
-
[33]
Proceedings of NeurIPS , year =
Parallelizing Linear Transformers with the Delta Rule over Sequence Length , author =. Proceedings of NeurIPS , year =
-
[34]
Proceedings of NeurIPS , year =
Gated Slot Attention for Efficient Linear-Time Sequence Modeling , author =. Proceedings of NeurIPS , year =
-
[35]
Proceedings of COLM , year =
HGRN2: Gated Linear RNNs with State Expansion , author =. Proceedings of COLM , year =
-
[36]
Proceedings of ICML , year =
Gated Linear Attention Transformers with Hardware-Efficient Training , author =. Proceedings of ICML , year =
-
[37]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author=. arXiv preprint arXiv:2312.00752 , year=
work page internal anchor Pith review arXiv
-
[38]
Transformers are
Dao, Tri and Gu, Albert , booktitle=. Transformers are
-
[39]
Test-time training done right.arXiv preprint arXiv:2505.23884, 2025
Test-time training done right , author=. arXiv preprint arXiv:2505.23884 , year=
-
[40]
Atlas: Learning to optimally memorize the context at test time, 2025
Atlas: Learning to optimally memorize the context at test time , author=. arXiv preprint arXiv:2505.23735 , year=
-
[41]
ArXiv , year =
Learning to (Learn at Test Time): RNNs with Expressive Hidden States , author =. ArXiv , year =
-
[42]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Titans: Learning to Memorize at Test Time , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[43]
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training , author=. arXiv preprint arXiv:2506.05233 , year=
-
[44]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Improving Bilinear RNN with Closed-loop Control , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[45]
RWKV-7 “Goose” with expressive dynamic state evolution, 2025
Rwkv-7" goose" with expressive dynamic state evolution , author=. arXiv preprint arXiv:2503.14456 , year=
-
[46]
International conference on machine learning , pages=
Transformers are rnns: Fast autoregressive transformers with linear attention , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[47]
Proceedings of the ninth annual conference of the Cognitive Science Society , pages=
Using fast weights to deblur old memories , author=. Proceedings of the ninth annual conference of the Cognitive Science Society , pages=
-
[48]
Neural Computation , volume=
Learning to control fast-weight memories: An alternative to dynamic recurrent networks , author=. Neural Computation , volume=. 1992 , publisher=
1992
-
[49]
Advances in neural information processing systems , volume=
Using fast weights to attend to the recent past , author=. Advances in neural information processing systems , volume=
-
[50]
International Conference on Learning Representations , year=
Random Feature Attention , author=. International Conference on Learning Representations , year=
-
[51]
Finetuning Pretrained Transformers into RNN s
Kasai, Jungo and Peng, Hao and Zhang, Yizhe and Yogatama, Dani and Ilharco, Gabriel and Pappas, Nikolaos and Mao, Yi and Chen, Weizhu and Smith, Noah A. Finetuning Pretrained Transformers into RNN s. Association for Computational Linguistics. 2021
2021
-
[52]
Retentive Network: A Successor to Transformer for Large Language Models
Retentive network: A successor to transformer for large language models , author=. arXiv preprint arXiv:2307.08621 , year=
work page internal anchor Pith review arXiv
-
[53]
International conference on machine learning , pages=
Linear transformers are secretly fast weight programmers , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[54]
Advances in neural information processing systems , volume=
Going beyond linear transformers with recurrent fast weight programmers , author=. Advances in neural information processing systems , volume=
-
[55]
Kimi Linear: An Expressive, Efficient Attention Architecture
Kimi linear: An expressive, efficient attention architecture , author=. arXiv preprint arXiv:2510.26692 , year=
work page internal anchor Pith review arXiv
-
[56]
Advances in Neural Information Processing Systems , volume=
Gated slot attention for efficient linear-time sequence modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Advances in Neural Information Processing Systems , volume=
MetaLA: Unified optimal linear approximation to softmax attention map , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Zhihao He, Hang Yu, Zi Gong, Shizhan Liu, Jianguo Li, and Weiyao Lin
Rodimus*: Breaking the accuracy-efficiency trade-off with efficient attentions , author=. arXiv preprint arXiv:2410.06577 , year=
-
[59]
arXiv preprint arXiv:2502.01578 , year=
REGLA: Refining Gated Linear Attention , author=. arXiv preprint arXiv:2502.01578 , year=
-
[60]
2024 , eprint=
TransNormerLLM: A Faster and Better Large Language Model with Improved TransNormer , author=. 2024 , eprint=
2024
-
[61]
2024 , eprint=
Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models , author=. 2024 , eprint=
2024
-
[62]
ACM Transactions on Mathematical Software (TOMS) , volume=
Accumulating Householder transformations, revisited , author=. ACM Transactions on Mathematical Software (TOMS) , volume=. 2006 , publisher=
2006
-
[63]
and Loan, Charles Van , booktitle =
Bischof, Christian H. and Loan, Charles Van , booktitle =. The
-
[64]
Exact Flow Linear Attention: Exact Solution from Continuous-Time Dynamics
Error-Free Linear Attention is a Free Lunch: Exact Solution from Continuous-Time Dynamics , author=. arXiv preprint arXiv:2512.12602 , year=
work page internal anchor Pith review arXiv
-
[65]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[66]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[67]
2025 , eprint=
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free , author=. 2025 , eprint=
2025
-
[68]
Workshop on Efficient Systems for Foundation Models II@ ICML2024 , year=
Just read twice: closing the recall gap for recurrent language models , author=. Workshop on Efficient Systems for Foundation Models II@ ICML2024 , year=
-
[69]
Flame: Flash Language Modeling Made Easy , author =
-
[70]
Distill , year =
Goh, Gabriel , title =. Distill , year =
-
[71]
Unlocking State-Tracking in Linear
Riccardo Grazzi and Julien Siems and J. Unlocking State-Tracking in Linear. NeurIPS 2024 Workshop on Mathematics of Modern Machine Learning , year=
2024
-
[72]
DeltaProduct: Improving State-Tracking in Linear
Julien Siems and Timur Carstensen and Arber Zela and Frank Hutter and Massimiliano Pontil and Riccardo Grazzi , booktitle=. DeltaProduct: Improving State-Tracking in Linear. 2025 , url=
2025
-
[73]
Soboleva, Daria and Al-Khateeb, Faisal and Myers, Robert and Steeves, Jacob R and Hestness, Joel and Dey, Nolan , title =
-
[74]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[75]
MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, et al
Minimax-01: Scaling foundation models with lightning attention , author=. arXiv preprint arXiv:2501.08313 , year=
-
[76]
Jet-nemotron: Efficient language model with post neural architecture search, 2025
Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search , author=. arXiv preprint arXiv:2508.15884 , year=
-
[77]
RULER: What's the Real Context Size of Your Long-Context Language Models?
RULER: What's the Real Context Size of Your Long-Context Language Models? , author=. arXiv preprint arXiv:2404.06654 , year=
work page internal anchor Pith review arXiv
-
[78]
Jamba: A Hybrid Transformer-Mamba Language Model
Jamba: A hybrid transformer-mamba language model , author=. arXiv preprint arXiv:2403.19887 , year=
work page internal anchor Pith review arXiv
-
[79]
Forty-second International Conference on Machine Learning , year=
Understanding and Improving Length Generalization in Recurrent Models , author=. Forty-second International Conference on Machine Learning , year=
-
[80]
Proceedings of the 30th International Conference on Machine Learning , pages =
On the importance of initialization and momentum in deep learning , author =. Proceedings of the 30th International Conference on Machine Learning , pages =. 2013 , volume =
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.