LLM-Based Educational Simulation: Evaluating Temporal Student Persona Stability Across ADHD Profiles
Pith reviewed 2026-05-25 06:02 UTC · model grok-4.3
The pith
LLM student simulations maintain stable self-reported ADHD traits at high intensities but show behavioral drift in unscripted talks unless explicit task prompts are used.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
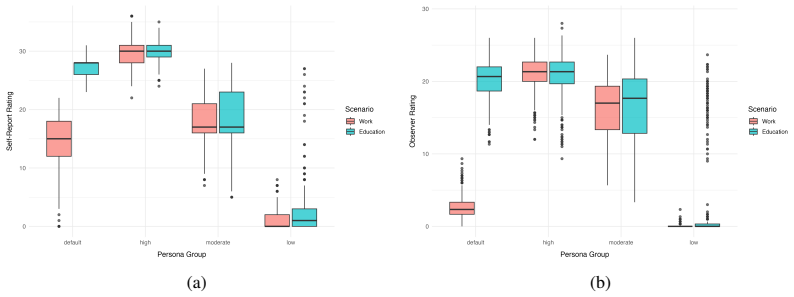
Across two experiments covering four clinically grounded ADHD persona conditions, five LLMs, and three prompt designs, self-reported characteristics remained stable for high intensities and thereby satisfied a necessary prerequisite for valid behavioral simulation. Observer-rated behavioral expressions instead exhibited selective instability, with within-conversation drift appearing in unscripted dialog for high and moderate ADHD personas. The same drift vanished entirely when interactions were scripted with explicit task prompts, indicating that stable, persona-aligned simulated learners require structured interaction design to preserve behavioral coherence.
What carries the argument
The dual-assessment framework that separately measures self-reported characteristics and observer-rated behavioral expressions across between-conversation and within-conversation time scales.
If this is right
- Stable simulated learners for teacher training and adaptive tutoring require structured, task-explicit interaction designs.
- Unscripted free-form dialog is unsuitable for maintaining behavioral coherence in moderate or high ADHD personas.
- High-intensity ADHD profiles already satisfy the self-report stability condition needed for simulation validity.
- Any application that needs sustained, path-dependent learner interactions benefits from the same prompt structure.
Where Pith is reading between the lines
- The same stability pattern may appear in simulations of other clinical or demographic profiles if similar dual assessment is applied.
- Hybrid designs that begin with scripted tasks and then allow limited free response could balance realism with coherence.
- Repeated testing across new model releases would show whether the observed drift pattern persists as base models improve.
Load-bearing premise
The combination of self-reports and observer ratings accurately captures genuine persona stability without being distorted by how the LLM generates text or how raters interpret it.
What would settle it
A follow-up study that still finds within-conversation behavioral drift for high and moderate ADHD personas even when every exchange uses explicit task prompts would falsify the claim that structured prompts eliminate the drift.
Figures


read the original abstract
Student simulation with Large language models (LLMs) offers a scalable alternative for educational research and teacher training. Yet, its validity depends on whether models maintain stable personas across extended interactions. We test this prerequisite using a dual-assessment framework measuring self-reported characteristics and observer-rated behavioral expressions. Across two experiments testing four clinically-grounded ADHD persona conditions, five LLMs, and three prompt designs, we quantify between-conversation stability (N=4,968) and within-conversation stability (N=3,952 across 9 turns). Self-reported characteristics remain stable for high intensities, constituting a necessary prerequisite for valid behavioral simulation. Observer-rated behavioral expression reveals selective instability: within-conversation drift occurs in unscripted dialog for high and moderate ADHD personas. Scripted interactions with explicit task prompts eliminate this drift entirely. Stable, persona-aligned simulated learners benefit from a structured interaction design to maintain behavioral coherence, which holds significant implications for teacher training, adaptive tutoring, and any application requiring sustained, path-dependent learner interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates temporal stability of LLM-simulated student personas across ADHD intensity profiles using a dual-assessment framework (self-reported characteristics and observer-rated behavioral expressions). Across five LLMs, four persona conditions, and three prompt designs, it reports between-conversation stability (N=4968) and within-conversation stability (N=3952 over 9 turns), concluding that self-reports remain stable at high intensities (a prerequisite for valid simulation) while observer-rated behaviors show selective within-conversation drift in unscripted dialog that is eliminated by scripted task prompts.
Significance. If the empirical results hold after addressing measurement details, the work offers practical guidance on interaction design for stable educational simulations, with direct relevance to teacher training and adaptive tutoring systems. The scale of the experiments (multiple LLMs and large N) and the distinction between self-report and behavioral measures represent a useful empirical contribution to persona consistency research.
major comments (2)
- [Abstract/Methods] Abstract and Methods: The reported directional findings on stability and drift are presented without any statistical tests, inter-rater reliability metrics, exact prompt wording, or exclusion criteria. This prevents verification that the data support the central claims about self-report stability as a prerequisite and selective behavioral drift.
- [Experimental Setup] Prompt Design (implied in experimental setup): If self-report assessment queries re-supply the original persona description or intensity cue at each measurement point (rather than relying solely on conversation history), the reported stability for high-intensity personas becomes expected by construction and does not demonstrate genuine temporal maintenance across turns. This directly weakens the interpretation that self-report stability constitutes an independent prerequisite for valid behavioral simulation.
minor comments (1)
- [Abstract] The abstract states N values but does not clarify how between- and within-conversation samples were derived or whether they overlap.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight opportunities to improve the verifiability of our results. We address each major comment below with clarifications drawn directly from our experimental design and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract/Methods] Abstract and Methods: The reported directional findings on stability and drift are presented without any statistical tests, inter-rater reliability metrics, exact prompt wording, or exclusion criteria. This prevents verification that the data support the central claims about self-report stability as a prerequisite and selective behavioral drift.
Authors: We agree that the abstract and condensed methods description omit explicit statistical tests, inter-rater metrics, full prompt text, and exclusion criteria, which limits immediate verification. The full methods section describes the dual-assessment protocol and data collection (N=4968 between-conversation, N=3952 within-conversation), but we will revise the manuscript to add: (1) statistical tests (e.g., repeated-measures ANOVA or Wilcoxon tests with effect sizes for stability across turns and conditions), (2) inter-rater reliability (Cohen’s kappa and percentage agreement for the two independent observers on behavioral ratings), (3) exact prompt templates and self-report query wording in a new appendix, and (4) explicit exclusion criteria (e.g., responses failing basic coherence checks). The abstract will be updated to reference these additions. These changes directly address the concern and enable readers to confirm support for the self-report stability and selective behavioral drift claims. revision: yes
-
Referee: [Experimental Setup] Prompt Design (implied in experimental setup): If self-report assessment queries re-supply the original persona description or intensity cue at each measurement point (rather than relying solely on conversation history), the reported stability for high-intensity personas becomes expected by construction and does not demonstrate genuine temporal maintenance across turns. This directly weakens the interpretation that self-report stability constitutes an independent prerequisite for valid behavioral simulation.
Authors: Our self-report queries do not re-supply the original persona description or intensity cue. At each measurement point the model is prompted only to “reflect on your current characteristics based on the preceding conversation” with no restatement of the initial ADHD profile, intensity level, or diagnostic criteria; the query relies exclusively on conversation history. This design was chosen precisely to test maintenance rather than cueing. We will revise the Methods section to include verbatim self-report query text and an explicit statement confirming the absence of re-supply, thereby preserving the interpretation that high-intensity self-report stability is an independent prerequisite. No change to the experimental results or conclusions is required. revision: partial
Circularity Check
Empirical measurement study with no derivations or fitted predictions
full rationale
The paper is a purely empirical evaluation reporting stability metrics from controlled experiments across LLMs, persona conditions, and prompt designs. No equations, parameter fitting, predictions, or first-principles derivations are present that could reduce to inputs by construction. Outcomes are measured directly via self-report and observer ratings on generated interactions, with no self-citation load-bearing on uniqueness theorems or ansatzes. The dual-assessment framework is a methodological design choice whose validity is open to external critique but does not create circularity in any claimed derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Clinically-grounded ADHD persona conditions can be instantiated reliably through LLM prompting
- domain assumption The dual-assessment framework (self-report plus observer ratings) captures genuine persona stability
Reference graph
Works this paper leans on
-
[1]
Consistently Simulating Human Personas with Multi-Turn Reinforcement Learning
Abdulhai, M., Cheng, R., Clay, D., Althoff, T., Levine, S., and Jaques, N. Consistently Simulating Human Personas with Multi-Turn Reinforcement Learning. InThe Thirty-ninth Conference on Neural Information Processing Systems, 2025
work page 2025
-
[2]
American Psychiatric Association - APA.Diagnostisches und statistisches Manual psychischer Störungen – Textrevision – DSM-5-TR®. Hogrefe Verlag GmbH & Co. KG, Göttingen, 1. auflage edition, 2025
work page 2025
-
[3]
Anthis, J. R., Liu, R., Richardson, S. M., Kozlowski, A. C., Koch, B., Evans, J., Brynjolfsson, E., and Bernstein, M. Position: LLM Social Simulations Are a Promising Research Method. In Proceedings of the 42nd International Conference on Machine Learning, Vancouver, Canada, 2025
work page 2025
-
[4]
Argyle, L. P., Busby, E. C., Fulda, N., Gubler, J. R., Rytting, C., and Wingate, D. Out of One, Many: Using Language Models to Simulate Human Samples.Political Analysis, 31(3):337–351,
-
[5]
doi: 10.1017/pan.2023.2
-
[6]
Binz, M., Akata, E., Bethge, M., Brändle, F., Callaway, F., Coda-Forno, J., Dayan, P., Demircan, C., Eckstein, M. K., Éltet˝o, N., Griffiths, T. L., Haridi, S., Jagadish, A. K., Ji-An, L., Kipnis, A., Kumar, S., Ludwig, T., Mathony, M., Mattar, M., Modirshanechi, A., Nath, S. S., Peterson, J. C., Rmus, M., Russek, E. M., Saanum, T., Schubert, J. A., Schul...
-
[7]
K., Erhardt, D., and Sparrow, E
Conners, C. K., Erhardt, D., and Sparrow, E. Conners’ Adult ADHD Rating Scales [Database record], n.d. https://doi.org/10.1037/t04961-000
-
[8]
The threat of analytic flexibility in using large language models to simulate human data
Cummins, J., 2025. The threat of analytic flexibility in using large language models to simulate human data. 10.48550/arXiv.2509.13397
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.13397 2025
-
[9]
Danielson, M. L., Claussen, A. H., Bitsko, R. H., Katz, S. M., Newsome, K., Blumberg, S. J., Kogan, M. D., and Ghandour, R. ADHD Prevalence Among U.S. Children and Adolescents in 2022: Diagnosis, Severity, Co-Occurring Disorders, and Treatment.Journal of Clinical Child & Adolescent Psychology, 53(3):343–360, 2024. doi: 10.1080/15374416.2024.2335625
-
[10]
FACET: Multi-Agent AI Supporting Teachers in Scaling Differentiated Learning for Diverse Students
Gonnermann-Müller, J., Haase, J., Leins, N., Igel, M., Fackeldey, K., and Pokutta, S., 2026. FACET: Multi-Agent AI Supporting Teachers in Scaling Differentiated Learning for Diverse Students. 10.48550/arxiv.2601.22788. 10
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.22788 2026
-
[11]
Stable Personas: Dual-Assessment of Temporal Stability in LLM-Based Human Simulation
Gonnermann-Müller, J., Haase, J., Leins, N., Kosch, T., and Pokutta, S., 2026. Sta- ble Personas: Dual-Assessment of Temporal Stability in LLM-Based Human Simulation. 10.48550/arXiv.2601.22812
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.22812 2026
-
[12]
SimBench: Benchmarking the Ability of Large Language Models to Simulate Human Behaviors
Hu, T., Baumann, J., Lupo, L., Collier, N., Hovy, D., and Röttger, P. SimBench: Benchmarking the Ability of Large Language Models to Simulate Human Behaviors. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[13]
Jebb, A. T., Ng, V ., and Tay, L. A Review of Key Likert Scale Development Advances: 1995–2019.Frontiers in Psychology, 12:637547, 2021. doi: 10.3389/fpsyg.2021.637547
-
[14]
Li, M., Chen, H., Xiao, Y ., Chen, J., Jiao, H., and Zhou, T., 2025. Can LLMs Estimate Student Struggles? Human-AI Difficulty Alignment with Proficiency Simulation for Item Difficulty Prediction. 10.48550/arXiv.2512.18880
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.18880 2025
-
[15]
Can LLMs Effectively Simulate Human Learners? Teachers’ Insights from Tutoring LLM Students
Martynova, D., Macina, J., Daheim, N., Yalcin, N., Zhang, X., and Sachan, M. Can LLMs Effectively Simulate Human Learners? Teachers’ Insights from Tutoring LLM Students. In Kochmar, E., Alhafni, B., Bexte, M., Burstein, J., Horbach, A., Laarmann-Quante, R., Tack, A., Yaneva, V ., and Yuan, Z. (eds.),Proceedings of the 20th Workshop on Innovative Use of NL...
-
[16]
Matza, L. S., Van Brunt, D. L., Cates, C., and Murray, L. T. Test–Retest Reliability of Two Patient-Report Measures for Use in Adults With ADHD.Journal of Attention Disorders, 15(7): 557–563, 2011. doi: 10.1177/1087054710372488
-
[17]
Mörstedt, B., Corbisiero, S., Bitto, H., and Stieglitz, R.-D. Attention-Deficit/Hyperactivity Disorder (ADHD) in Adulthood: Concordance and Differences between Self- and Informant Perspectives on Symptoms and Functional Impairment.PLOS ONE, 10(11):e0141342, 2015. doi: 10.1371/journal.pone.0141342
-
[18]
Olino, T. M. and Klein, D. N. Psychometric Comparison of Self- and Informant-Reports of Personality.Assessment, 22(6):655–664, 2015. doi: 10.1177/1073191114567942
-
[19]
R., Cheng, N., Durmus, E., Hatfield-Dodds, Z., Johnston, S
Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S. R., Cheng, N., Durmus, E., Hatfield-Dodds, Z., Johnston, S. R., Kravec, S., Maxwell, T., McCandlish, S., Ndousse, K., Rausch, O., Schiefer, N., Yan, D., Zhang, M., and Perez, E. Towards Understanding Sycophancy in Language Models. InThe Twelfth International Conference on Learning Repr...
work page 2024
-
[20]
International Classification of Diseases (ICD), 2025
World Health Organisation (WHO). International Classification of Diseases (ICD), 2025. https://icd.who.int/browse/2025-01/mms/en#821852937, Accessed: 2025-10-01
work page 2025
-
[21]
Embracing Imperfection: Simulating Students with Diverse Cognitive Levels Using LLM-based Agents
Wu, T., Chen, J., Lin, W., Li, M., Zhu, Y ., Li, A., Kuang, K., and Wu, F. Embracing Imperfection: Simulating Students with Diverse Cognitive Levels Using LLM-based Agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 9887–9908, Vienna, Austria, 2025. Association for Computational L...
-
[22]
Wåhlstedt, C., Thorell, L. B., and Bohlin, G. Heterogeneity in ADHD: Neuropsychological Pathways, Comorbidity and Symptom Domains.Journal of Abnormal Child Psychology, 37(4): 551–564, 2009. doi: 10.1007/s10802-008-9286-9
-
[23]
A LLM-Driven Multi-Agent Systems for Professional Development of Mathematics Teachers
Yang, K., Li, H., Chu, Y ., Han, A., Copur-Gencturk, Y ., Tang, J., and Liu, H., 2025. A LLM-Driven Multi-Agent Systems for Professional Development of Mathematics Teachers. 10.48550/arXiv.2507.05292
-
[24]
Zhang, Z., Zhang-Li, D., Yu, J., Gong, L., Zhou, J., Hao, Z., Jiang, J., Cao, J., Liu, H., Liu, Z., Hou, L., and Li, J. Simulating Classroom Education with LLM-Empowered Agents. In Chiruzzo, L., Ritter, A., and Wang, L. (eds.),Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human ...
-
[25]
I interrupt others when talking
-
[26]
I am always on the go as if driven by a motor
-
[27]
It’s hard for me to stay in one place very long
-
[28]
It’s hard for me to keep track of several things at once
-
[29]
I have a short fuse/hot temper
-
[30]
I still throw tantrums
-
[31]
I avoid new challenges because I lack faith in my abilities
-
[32]
I seek out fast paced, exciting activities
-
[33]
I feel restless inside even if I am sitting still
-
[34]
Things I hear or see distract me from what I’m doing
-
[35]
Many things set me off easily
-
[36]
I am an underachiever
-
[37]
I get down on myself
-
[38]
I act okay on the outside, but inside I’m unsure of myself
-
[39]
I can’t get things done unless there’s an absolute deadline
-
[40]
I have trouble getting started on a task
-
[41]
I intrude on others’ activities
-
[42]
My moods are unpredictable
-
[43]
I’m absent-minded in daily activities
-
[44]
Sometimes my attention narrows so much that I’m oblivious to everything else; other times it’s so broad that everything distracts me
-
[45]
I tend to squirm or fidget
-
[46]
I can’t keep my mind on something unless it’s really interesting
-
[47]
I wish I had greater confidence in my abilities
-
[48]
BEGIN when ready and output only the JSON
My past failures make it hard for me to believe in myself. BEGIN when ready and output only the JSON. Observer Prompt You are a trained observer conducting a behavioral assessment. You will receive a conversation of two individuals. Based on this conversation, rate each of the following assessment items using the scale below. Conversation between two indi...
-
[49]
Loses things necessary for tasks or activities (e.g., to-do lists, pencils, books, or tools). 16
-
[50]
Is always on the go as if driven by a motor
-
[51]
Gets rowdy or boisterous during leisure activities
-
[52]
Has a short fuse/hot temper
-
[53]
Leaves seat when not supposed to
-
[54]
Has trouble waiting in line or taking turns with others
-
[55]
Has trouble keeping attention focused when working or at leisure
-
[56]
Avoids new challenges because of lack of faith in his/her abilities
-
[57]
Appears restless inside even when sitting still
-
[58]
Is distracted by sights or sounds when trying to concentrate
-
[59]
Is forgetful in daily activities
-
[60]
Has trouble listening to what other people are saying
-
[61]
Can’t get things done unless there’s an absolute deadline
-
[62]
Fidgets (with hands or feet) or squirms in seat
-
[63]
Makes careless mistakes or has trouble paying close attention to detail
-
[64]
Intrudes on others’ activities
-
[65]
Doesn’t like academic studies/work projects where effort at thinking a lot is required
-
[66]
Is restless or overactive
-
[67]
Sometimes overfocuses on details, at other times appears distracted by everything going on around him/her
-
[68]
Can’t keep his/her mind on something unless it’s really interesting
-
[69]
Gives answers to questions before the questions have been completed
-
[70]
Has trouble finishing job tasks or schoolwork
-
[71]
Interrupts others when they are working or busy
-
[72]
Expresses lack of confidence in self because of past failures
-
[73]
Appears distracted when things are going on around him/her
-
[74]
Has problems organizing tasks and activities. INSTRUCTIONS: - Carefully review the conversation segment - Rate each item based solely on observable evidence in the conversation - Use your best clinical judgment when evidence is limited or ambiguous - Provide a rating (0-3) for every item Output your assessment strictly in the following JSON format: {{ "re...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.