How Mobile World Model Guides GUI Agents?
Pith reviewed 2026-05-25 05:57 UTC · model grok-4.3
The pith
Renderable code reconstruction in mobile world models achieves high in-distribution fidelity and provides effective multimodal supervision for GUI agent data construction, while text-based feedback is more robust for online out-of-distribut
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
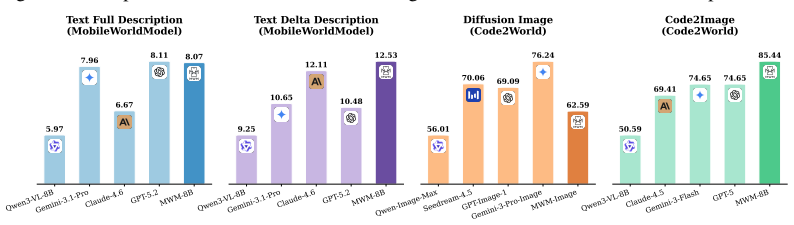
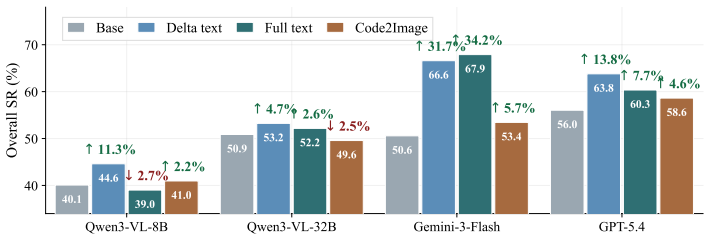
By filtering and annotating mobile world-model data and training models across delta text, full text, diffusion-based images, and renderable code, these models reach state-of-the-art on MobileWorldBench and Code2WorldBench. Downstream tests on AITZ, AndroidControl, and AndroidWorld show renderable code reconstruction achieves high in-distribution fidelity and supplies effective multimodal supervision for data construction, while text-based feedback is more robust for online out-of-distribution execution. World-model-generated trajectories supply transferable interaction experience that improves agents' end-to-end task performance although the data do not preserve the original distribution.
What carries the argument
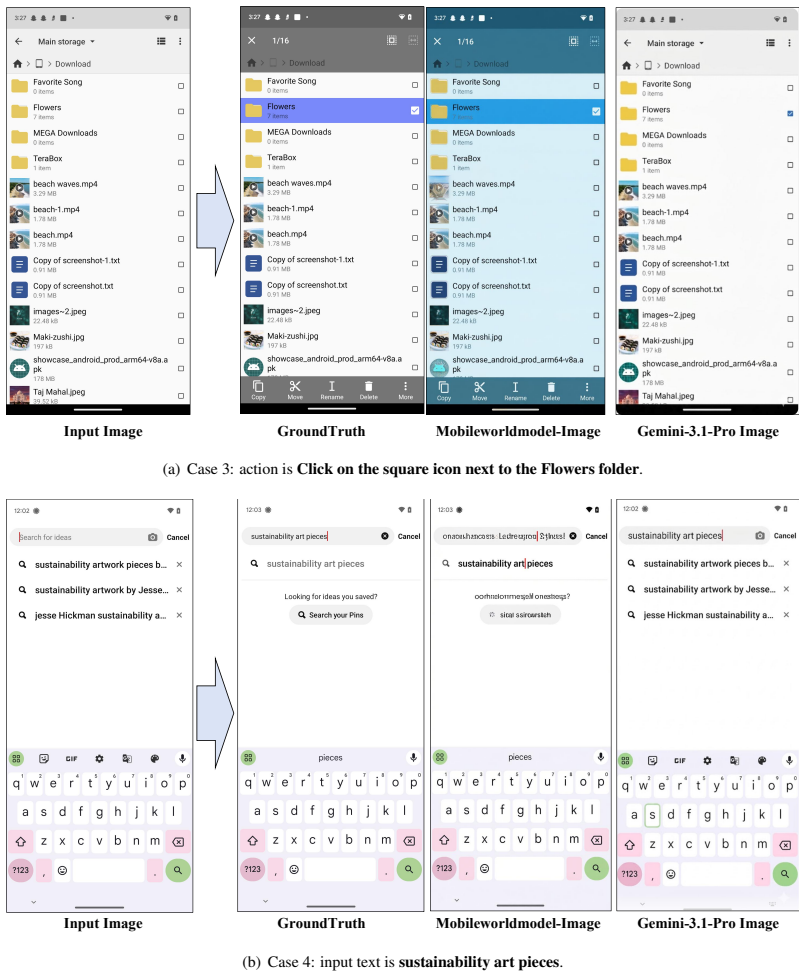
Mobile world models in four modalities (delta text, full text, diffusion images, renderable code) that predict future states to supply either prior perception, training supervision, or post-hoc verification for GUI agents.
Load-bearing premise
The three downstream evaluation environments and the filtered training data are representative enough to support general claims about which modality works best for arbitrary mobile GUI agents and long-horizon tasks.
What would settle it
A controlled test on a new mobile environment outside the three evaluated ones in which text-based feedback loses its OOD advantage or generated trajectories cease to raise end-to-end agent performance.
Figures

























read the original abstract
Recent advances in vision-language models have enabled mobile GUI agents to perceive visual interfaces and execute user instructions, but reliable prediction of action consequences remains critical for long-horizon and high-risk interactions. Existing mobile world models provide either text-based or image-based future states, yet it remains unclear which representation is useful, whether generated rollouts can replace real environments, and how test-time guidance helps agents of different strengths. To answer the above questions, we filter and annotate mobile world-model data, then train world models across four modalities: delta text, full text, diffusion-based images, and renderable code. These models achieve SoTA performance on both MobileWorldBench and Code2WorldBench. Furthermore, by evaluating their downstream utility on AITZ, AndroidControl, and AndroidWorld, we obtain three findings. First, renderable code reconstruction achieves high in-distribution fidelity and provides effective multimodal supervision for data construction, while text-based feedback is more robust for online out-of-distribution (OOD) execution. Second, world-model-generated trajectories can provide transferable interaction experience in the training process and improve agents' end-to-end task performance, although these data do not preserve the original distribution. Last, for overconfident mobile agents with low action entropy, posterior self-reflection provides limited gains, suggesting that world models are more effective as prior perception or training supervision than as universal post-hoc verifiers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper filters and annotates mobile GUI data to train world models in four modalities (delta text, full text, diffusion images, renderable code). These achieve SOTA on MobileWorldBench and Code2WorldBench. Downstream evaluations on AITZ, AndroidControl, and AndroidWorld yield three findings: renderable code provides high in-distribution fidelity and effective multimodal supervision while text feedback is more robust for online OOD execution; generated trajectories improve end-to-end agent performance without preserving the original distribution; and world models are more effective as prior perception or training supervision than as post-hoc verifiers, especially for overconfident low-entropy agents.
Significance. If the empirical modality comparisons hold after proper controls, the work offers concrete guidance on representation choices for mobile world models and demonstrates that generated trajectories can transfer interaction experience. The multi-modality training and SOTA benchmark results are strengths; the downstream utility findings could inform design of long-horizon GUI agents if the in-distribution vs. OOD distinction is rigorously established.
major comments (2)
- [Downstream evaluation on AITZ, AndroidControl, and AndroidWorld] Downstream evaluation section: no explicit metric (action-sequence divergence, visual embedding distance, task-horizon statistics, or similar) is reported to quantify distribution shift between the filtered training trajectories and the three evaluation environments (AITZ, AndroidControl, AndroidWorld). This quantification is load-bearing for the central claim that text-based feedback is more robust specifically for online OOD execution versus renderable code for in-distribution fidelity.
- [Findings on generated trajectories] Findings paragraph and associated tables/figures: the reported improvements from generated trajectories on end-to-end task performance are presented without controls for multiple comparisons or statistical significance testing across the modality variants and environments, weakening the second finding.
minor comments (2)
- [Methods] Notation for the four modalities (delta text, full text, diffusion-based images, renderable code) should be introduced with consistent abbreviations in the methods section for clarity in later comparisons.
- [Benchmark results] The abstract states 'SoTA performance' on the two benchmarks; the main text should include the exact prior baselines and margins for each modality to allow direct verification.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight important aspects of rigor in the downstream evaluation and statistical presentation. We address each below.
read point-by-point responses
-
Referee: [Downstream evaluation on AITZ, AndroidControl, and AndroidWorld] Downstream evaluation section: no explicit metric (action-sequence divergence, visual embedding distance, task-horizon statistics, or similar) is reported to quantify distribution shift between the filtered training trajectories and the three evaluation environments (AITZ, AndroidControl, AndroidWorld). This quantification is load-bearing for the central claim that text-based feedback is more robust specifically for online OOD execution versus renderable code for in-distribution fidelity.
Authors: We agree that explicit quantification of distribution shift is necessary to rigorously support the ID versus OOD distinction in our modality findings. In the revision we will add metrics including action-sequence edit distance and cosine distances in a shared visual embedding space between the filtered training trajectories and each of the three evaluation environments. revision: yes
-
Referee: [Findings on generated trajectories] Findings paragraph and associated tables/figures: the reported improvements from generated trajectories on end-to-end task performance are presented without controls for multiple comparisons or statistical significance testing across the modality variants and environments, weakening the second finding.
Authors: We acknowledge the absence of formal statistical controls. In the revised manuscript we will include paired statistical tests (with multiple-comparison correction) across modality variants and environments and report the resulting p-values alongside the performance numbers. revision: yes
Circularity Check
No circularity: empirical evaluation chain is self-contained against external benchmarks
full rationale
The paper filters and annotates data, trains four modality-specific world models, reports SoTA on MobileWorldBench and Code2WorldBench, then measures downstream effects on the independent environments AITZ, AndroidControl, and AndroidWorld. No equations, fitted parameters, or self-citations are shown to reduce any reported gain (in-distribution fidelity, OOD robustness, or end-to-end improvement) to a quantity defined by the paper's own inputs. The modality ranking and trajectory-transfer claims rest on observable benchmark outcomes rather than definitional or self-referential reductions, satisfying the default expectation of an empirical study with low circularity burden.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Rui Yang, Qianhui Wu, Zhaoyang Wang, Hanyang Chen, Ke Yang, Hao Cheng, Huaxiu Yao, Baoling Peng, Huan Zhang, Jianfeng Gao, et al. Gui-libra: Training native gui agents to reason and act with action-aware supervision and partially verifiable rl.arXiv preprint arXiv:2602.22190, 2026
work page internal anchor Pith review arXiv 2026
-
[6]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxi- ang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Hyungjoo Chae, Namyoung Kim, Kai Tzu-iunn Ong, Minju Gwak, Gwanwoo Song, Jihoon Kim, Sunghwan Kim, Dongha Lee, and Jinyoung Yeo. Web agents with world models: Learning and leveraging environment dynamics in web navigation.arXiv preprint arXiv:2410.13232, 2024
-
[8]
Yu Gu, Kai Zhang, Yuting Ning, Boyuan Zheng, Boyu Gou, Tianci Xue, Cheng Chang, Sanjari Srivastava, Yanan Xie, Peng Qi, et al. Is your llm secretly a world model of the internet? model-based planning for web agents.arXiv preprint arXiv:2411.06559, 2024
-
[9]
Mobiledreamer: Generative sketch world model for gui agent
Yilin Cao, Yufeng Zhong, Zhixiong Zeng, Liming Zheng, Jing Huang, Haibo Qiu, Peng Shi, Wenji Mao, and Wan Guanglu. Mobiledreamer: Generative sketch world model for gui agent. arXiv preprint arXiv:2601.04035, 2026
-
[10]
Vimo: A generative visual gui world model for app agents
Dezhao Luo, Bohan Tang, Kang Li, Georgios Papoudakis, Jifei Song, Shaogang Gong, Jianye Hao, Jun Wang, and Kun Shao. Vimo: A generative visual gui world model for app agents. arXiv preprint arXiv:2504.13936, 2025
-
[11]
Generative visual code mobile world models.arXiv preprint arXiv:2602.01576, 2026
Woosung Koh, Sungjun Han, Segyu Lee, Se-Young Yun, and Jamin Shin. Generative visual code mobile world models.arXiv preprint arXiv:2602.01576, 2026
work page internal anchor Pith review arXiv 2026
-
[12]
Code2world: A gui world model via renderable code generation
Yuhao Zheng, Li’an Zhong, Yi Wang, Rui Dai, Kaikui Liu, Xiangxiang Chu, Linyuan Lv, Philip Torr, and Kevin Qinghong Lin. Code2world: A gui world model via renderable code generation. arXiv preprint arXiv:2602.09856, 2026
-
[13]
Mobilevlm: A vision-language model for better intra-and inter-ui understanding
Qinzhuo Wu, Weikai Xu, Wei Liu, Tao Tan, Liujian Liujianfeng, Ang Li, Jian Luan, Bin Wang, and Shuo Shang. Mobilevlm: A vision-language model for better intra-and inter-ui understanding. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 10231–10251, 2024
work page 2024
-
[14]
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. An- droidinthewild: A large-scale dataset for android device control.Advances in Neural Information Processing Systems, 36:59708–59728, 2023
work page 2023
-
[15]
Amex: Android multi-annotation expo dataset for mobile gui agents
Yuxiang Chai, Siyuan Huang, Yazhe Niu, Han Xiao, Liang Liu, Guozhi Wang, Dingyu Zhang, Shuai Ren, and Hongsheng Li. Amex: Android multi-annotation expo dataset for mobile gui agents. InFindings of the Association for Computational Linguistics: ACL 2025, pages 2138–2156, 2025. 13
work page 2025
-
[16]
Android in the zoo: Chain-of-action-thought for gui agents
Jiwen Zhang, Jihao Wu, Teng Yihua, Minghui Liao, Nuo Xu, Xiao Xiao, Zhongyu Wei, and Duyu Tang. Android in the zoo: Chain-of-action-thought for gui agents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 12016–12031, 2024
work page 2024
-
[17]
Wei Li, William Bishop, Alice Li, Chris Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on ui control agents.Advances in Neural Information Processing Systems, 37:92130–92154, 2024
work page 2024
-
[18]
Guiodyssey: A comprehensive dataset for cross-app gui navigation on mobile devices
Quanfeng Lu, Wenqi Shao, Zitao Liu, Lingxiao Du, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, and Ping Luo. Guiodyssey: A comprehensive dataset for cross-app gui navigation on mobile devices. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22404–22414, 2025
work page 2025
-
[19]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Yusuke Kato, Kazuki Kozuka, and Aditya Grover. Mobileworldbench: Towards semantic world modeling for mobile agents.arXiv preprint arXiv:2512.14014, 2025
-
[22]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alab- dulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Hanzhang Zhou, Xu Zhang, Panrong Tong, Jianan Zhang, Liangyu Chen, Quyu Kong, Chenglin Cai, Chen Liu, Yue Wang, Jingren Zhou, et al. Mai-ui technical report: Real-world centric foundation gui agents.arXiv preprint arXiv:2512.22047, 2025
-
[25]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Mary- beth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Androidworld: A dynamic benchmarking environment for autonomous agents.arXiv preprint arXiv:2405.14573, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Haiyang Xu, Xi Zhang, Haowei Liu, Junyang Wang, Zhaozai Zhu, Shengjie Zhou, Xuhao Hu, Feiyu Gao, Junjie Cao, Zihua Wang, et al. Mobile-agent-v3. 5: Multi-platform fundamental gui agents.arXiv preprint arXiv:2602.16855, 2026
-
[27]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
work page 2024
-
[28]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37: 126544–126565, 2024
work page 2024
-
[29]
Huawen Shen, Chang Liu, Gengluo Li, Xinlong Wang, Yu Zhou, Can Ma, and Xiangyang Ji. Falcon-ui: Understanding gui before following user instructions.arXiv preprint arXiv:2412.09362, 2024
-
[30]
Appagent: Multimodal agents as smartphone users
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. Appagent: Multimodal agents as smartphone users. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–20, 2025. 14
work page 2025
-
[31]
Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception. arXiv preprint arXiv:2401.16158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Zhenhailong Wang, Haiyang Xu, Junyang Wang, Xi Zhang, Ming Yan, Ji Zhang, Fei Huang, and Heng Ji. Mobile-agent-e: Self-evolving mobile assistant for complex tasks.arXiv preprint arXiv:2501.11733, 2025
-
[33]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Run Luo, Lu Wang, Wanwei He, Longze Chen, Jiaming Li, and Xiaobo Xia. Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Yuqi Zhou, Sunhao Dai, Shuai Wang, Kaiwen Zhou, Qinglin Jia, and Jun Xu. Gui-g1: Understanding r1-zero-like training for visual grounding in gui agents.arXiv preprint arXiv:2505.15810, 2025
-
[35]
InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
Yuhang Liu, Pengxiang Li, Congkai Xie, Xavier Hu, Xiaotian Han, Shengyu Zhang, Hongxia Yang, and Fei Wu. Infigui-r1: Advancing multimodal gui agents from reactive actors to deliberative reasoners.arXiv preprint arXiv:2504.14239, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Ui-r1: Enhancing efficient action prediction of gui agents by reinforcement learning
Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Han Xiao, Shuai Ren, Pengxiang Zhao, Guangyi Liu, et al. Ui-r1: Enhancing efficient action prediction of gui agents by reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 17608–17616, 2026
work page 2026
-
[37]
Webworld: A large-scale world model for web agent training
Zikai Xiao, Jianhong Tu, Chuhang Zou, Yuxin Zuo, Zhi Li, Peng Wang, Bowen Yu, Fei Huang, Junyang Lin, and Zuozhu Liu. Webworld: A large-scale world model for web agent training. arXiv preprint arXiv:2602.14721, 2026
-
[38]
Mobile-bench: An evaluation benchmark for llm-based mobile agents
Shihan Deng, Weikai Xu, Hongda Sun, Wei Liu, Tao Tan, Liujianfeng Liujianfeng, Ang Li, Jian Luan, Bin Wang, Rui Yan, et al. Mobile-bench: An evaluation benchmark for llm-based mobile agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8813–8831, 2024
work page 2024
-
[39]
Weikai Xu, Zhizheng Jiang, Yuxuan Liu, Pengzhi Gao, Wei Liu, Jian Luan, Yunxin Liu, Yuanchun Li, Bin Wang, and Bo An. Sman-bench: A cross-system benchmark for mobile agents under single-and multi-path, ambiguous, and noisy tasks. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[40]
Cogagent: A visual language model for gui agents, 2023
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, and Jie Tang. Cogagent: A visual language model for gui agents, 2023
work page 2023
-
[41]
Yuxuan Liu, Hongda Sun, Wei Liu, Jian Luan, Bo Du, and Rui Yan. Mobilesteward: Integrating multiple app-oriented agents with self-evolution to automate cross-app instructions. InProceed- ings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 883–893, 2025
work page 2025
-
[42]
Kun Huang, Weikai Xu, Yuxuan Liu, Quandong Wang, Pengzhi Gao, Wei Liu, Jian Luan, Bin Wang, and Bo An. Mobileipl: Enhancing mobile agents thinking process via iterative preference learning.arXiv preprint arXiv:2505.12299, 2025
-
[43]
Yuxuan Liu, Weikai Xu, Kun Huang, Changyu Chen, Jiankun Zhao, Pengzhi Gao, Wei Liu, Jian Luan, Shuo Shang, Bo Du, et al. Come: Empowering channel-of-mobile-experts with informative hybrid-capabilities reasoning.arXiv preprint arXiv:2602.24142, 2026
-
[44]
Llm-based agents for tool learning: A survey: W
Weikai Xu, Chengrui Huang, Shen Gao, and Shuo Shang. Llm-based agents for tool learning: A survey: W. xu et al.Data Science and Engineering, pages 1–31, 2025
work page 2025
-
[45]
Weikai Xu, Zhizheng Jiang, Yuxuan Liu, Pengzhi Gao, Wei Liu, Jian Luan, Yuanchun Li, Yunxin Liu, Bin Wang, and Bo An. Mobile-bench-v2: A more realistic and comprehensive benchmark for vlm-based mobile agents.arXiv preprint arXiv:2505.11891, 2025. 15
-
[46]
Yucheng Shi, Wenhao Yu, Zaitang Li, Yonglin Wang, Hongming Zhang, Ninghao Liu, Haitao Mi, and Dong Yu. Mobilegui-rl: Advancing mobile gui agent through reinforcement learning in online environment.arXiv preprint arXiv:2507.05720, 2025
-
[47]
Yuhan Chen, Yuxuan Liu, Long Zhang, Pengzhi Gao, Jian Luan, and Wei Liu. Step: Success- rate-aware trajectory-efficient policy optimization.arXiv preprint arXiv:2511.13091, 2025
-
[48]
Computer-using world model.arXiv preprint arXiv:2602.17365, 2026
Yiming Guan, Rui Yu, John Zhang, Lu Wang, Chaoyun Zhang, Liqun Li, Bo Qiao, Si Qin, He Huang, Fangkai Yang, et al. Computer-using world model.arXiv preprint arXiv:2602.17365, 2026
-
[49]
Zhizheng Jiang, Kang Zhao, Weikai Xu, Xinkui Lin, Wei Liu, Jian Luan, Shuo Shang, and Peng Han. Rˆ 3: Replay, reflection, and ranking rewards for llm reinforcement learning.arXiv preprint arXiv:2601.19620, 2026
-
[50]
Determlr: Augmenting llm-based logical reasoning from indeterminacy to determinacy
Hongda Sun, Weikai Xu, Wei Liu, Jian Luan, Bin Wang, Shuo Shang, Ji-Rong Wen, and Rui Yan. Determlr: Augmenting llm-based logical reasoning from indeterminacy to determinacy. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9828–9862, 2024
work page 2024
-
[51]
Yixia Li, Hongru Wang, Jiahao Qiu, Zhenfei Yin, Dongdong Zhang, Cheng Qian, Zeping Li, Pony Ma, Guanhua Chen, and Heng Ji. From word to world: Can large language models be implicit text-based world models?arXiv preprint arXiv:2512.18832, 2025. 16 A Full Related Work A.1 Mobile GUI Agents The evolution of mobile GUI agents marks a paradigm shift from rule-...
-
[52]
Result: Page navigation, popup opens, toggle switches, or focus change
click: A tap on a button, icon, or link. Result: Page navigation, popup opens, toggle switches, or focus change
-
[53]
Result: Context menu appears or item selection mode triggers
long_press: A sustained touch. Result: Context menu appears or item selection mode triggers
-
[54]
(New content appears, old content moves off-screen)
scroll: The content shifts vertically or horizontally. (New content appears, old content moves off-screen). 4.input_text: Text appears in an input field (without an explicit enter press)
-
[55]
open_app: The screen transitions from a launcher/home screen to a specific app interface. 6.navigate_home: Returns to the device home screen/launcher. 7.navigate_back: Returns to the previous screen (reverse navigation). 8.wait: No significant visual change, or a loading spinner continues spinning. 9.none: The transition is hallucinated, broken, illogical...
-
[56]
Goal progress first: does this action move the task toward completion at this specific step?
-
[57]
Prediction reliability second: is the predicted next page trustworthy enough to support that progress judgment? 26 Treat textual realism as evidence quality, not the objective. If realism is high but progress is weak, do not mark valid. Now provide your judgment on the selected action in JSON format. Your response must include: • Reason: Explain primarily...
-
[58]
Therefore, participant risks, risk disclosure, and IRB approval are not applicable
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.