Grounding Text Embeddings in Stakeholder Associations
Pith reviewed 2026-06-29 18:48 UTC · model grok-4.3
The pith
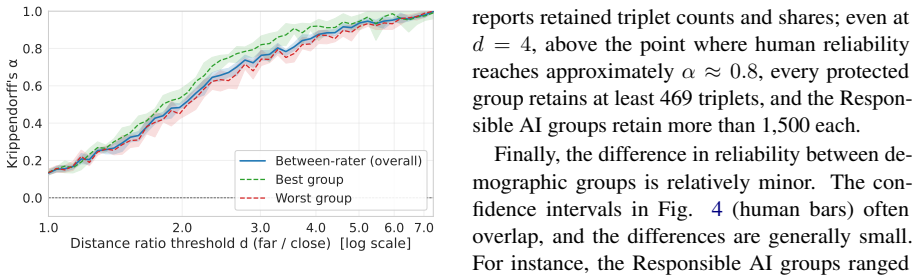
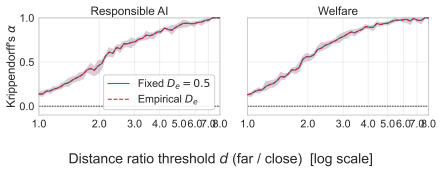
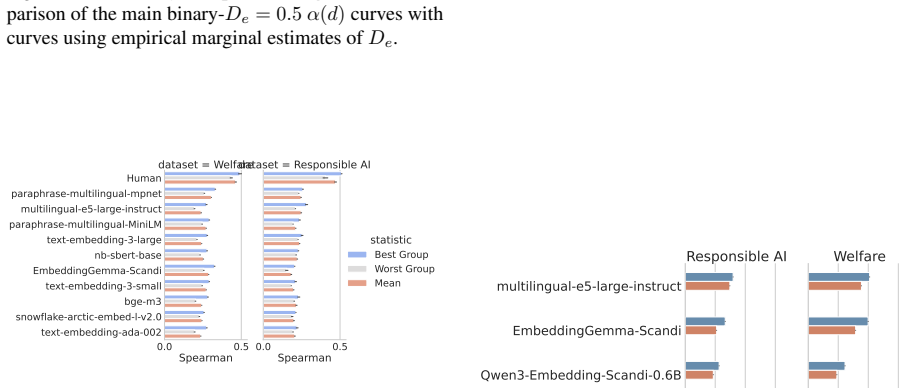
Neural text embeddings lag human experts by 19-26 points when associating meanings in policy texts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
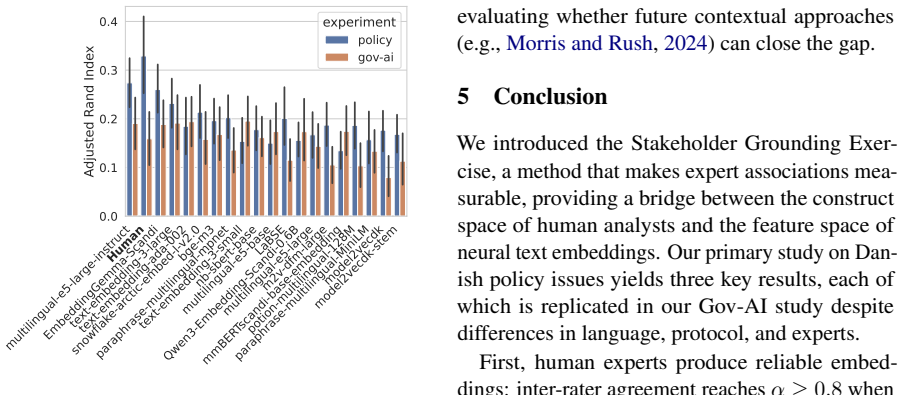
The Stakeholder Grounding Exercise shows that neural text embeddings are substantially less reliable than human experts at reproducing expert semantic associations, producing gaps of 19-26 percentage points on Danish policy texts and 16 points on US Federal AI use cases. This gap propagates to clustering: models that rank higher on the exercise also produce higher-quality clusters, with Spearman ρ = 0.9.
What carries the argument
The Stakeholder Grounding Exercise, a protocol that elicits explicit pairwise associations from domain experts and compares them to embedding similarity scores.
If this is right
- Embedding models intended for policy or domain analysis should be screened against expert associations before deployment.
- Clustering quality on complex texts improves when the embedding model better matches expert semantic distinctions.
- The exercise can be run with digital protocols across languages and expert communities without changing the observed gap.
- Downstream tasks that rely on semantic distances inherit the reliability gap between embeddings and experts.
Where Pith is reading between the lines
- Selection or fine-tuning of embeddings for a given domain could be guided by running the exercise on a small expert panel rather than relying on general benchmarks.
- The same grounding approach could be adapted to test embeddings on other tasks such as classification or retrieval where human intent matters.
- If the gap persists across many domains, it suggests that current training objectives for text embeddings do not prioritise the fine-grained distinctions that experts use.
Load-bearing premise
The associations that human experts produce in the exercise are the right target for what embeddings should represent.
What would settle it
A new embedding model that matches or exceeds expert reliability on the Stakeholder Grounding Exercise yet still yields low-quality clusters on the same texts, or a model that scores low on the exercise but produces high-quality clusters.
Figures









read the original abstract
Text embeddings are widely used to analyse large corpora of complex texts. However, it is unclear whether the embeddings capture the same semantic distances as the human experts using them. Ensuring alignment between embedding representations and human intentions is essential for valid analyses. We present the Stakeholder Grounding Exercise, a method for making expert associations explicit and grounding embedding model results in human understanding. In our primary case study on Danish policy issues, we find that neural text embeddings are substantially less reliable than human experts (19-26 pp gap), and that this misalignment propagates to downstream clustering performance (Spearman $\rho=0.9$ between exercise ranking and cluster quality). A secondary study on US Federal AI use cases replicates the gap (16pp) in English, using a digital protocol and a different community of experts -- demonstrating that the gap is not an artefact of a single instrument or domain. The Stakeholder Grounding Exercise offers a practical method for assessing whether embedding models capture the semantic distinctions that matter most to domain experts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Stakeholder Grounding Exercise as a method to elicit explicit expert associations and uses it to evaluate whether neural text embeddings capture the same semantic distinctions as domain experts. In a primary Danish policy-issues case study, it reports that embeddings are substantially less reliable than human experts (19-26 percentage point gap) and that this misalignment propagates to downstream clustering (Spearman ρ=0.9 between exercise ranking and cluster quality). A secondary replication on US Federal AI use cases confirms a 16pp gap using a digital protocol and different experts, arguing the gap is not an artifact of a single instrument or domain.
Significance. If the Stakeholder Grounding Exercise validly operationalizes the semantic distinctions that matter to experts, the work supplies a practical, replicable protocol for diagnosing embedding misalignment in applied text-analysis settings and demonstrates that such misalignment can materially degrade clustering quality. The cross-domain replication is a strength that increases the result's robustness.
major comments (2)
- [Abstract (method and primary case study)] The central empirical claim (19-26 pp reliability gap and its propagation to clustering) treats the associations elicited by the Stakeholder Grounding Exercise as the reference ground truth. The abstract provides no independent validation that these elicited associations recover the distinctions that embeddings are optimized to represent (i.e., corpus-level co-occurrence patterns), raising the possibility that the measured gap reflects elicitation mismatch rather than embedding deficiency.
- [Abstract (secondary study)] The secondary replication uses the same exercise protocol (albeit digitized) on a different expert community; because it does not introduce an independent criterion for what embeddings ought to capture, it cannot break the dependence on the exercise as ground truth and therefore does not fully address the concern that the gap may be protocol-specific.
minor comments (2)
- [Abstract] The abstract states the reliability gap and Spearman correlation but does not report sample sizes, number of experts, number of items, statistical procedures, or exclusion criteria; these details are required to evaluate whether the reported gaps and correlation are supported by the data.
- [Abstract] The phrase 'substantially less reliable' is used without defining the reliability metric or providing the raw agreement rates; a table or equation showing how the percentage-point gap is computed would improve transparency.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on the validation of the Stakeholder Grounding Exercise. We address each major comment below, clarifying the intended role of expert associations as the reference and noting revisions we will make to improve transparency.
read point-by-point responses
-
Referee: [Abstract (method and primary case study)] The central empirical claim (19-26 pp reliability gap and its propagation to clustering) treats the associations elicited by the Stakeholder Grounding Exercise as the reference ground truth. The abstract provides no independent validation that these elicited associations recover the distinctions that embeddings are optimized to represent (i.e., corpus-level co-occurrence patterns), raising the possibility that the measured gap reflects elicitation mismatch rather than embedding deficiency.
Authors: The Stakeholder Grounding Exercise is explicitly designed to operationalize the semantic distinctions that matter to domain experts in applied text-analysis settings, rather than to recover corpus-level co-occurrence patterns. Embeddings are trained on co-occurrence, yet the paper's motivating question is whether they align with the distinctions experts use when interpreting results; misalignment with experts can invalidate downstream analyses even if co-occurrence is captured. The reported Spearman ρ=0.9 correlation between exercise-derived rankings and clustering quality supplies direct evidence that the measured gap has practical consequences for a standard embedding use case. We did not include a direct comparison against corpus co-occurrence statistics because that is not the reference the exercise targets. In revision we will expand the abstract and methods to state this rationale more explicitly and add a limitations paragraph acknowledging that an auxiliary co-occurrence analysis could further contextualize the results. revision: partial
-
Referee: [Abstract (secondary study)] The secondary replication uses the same exercise protocol (albeit digitized) on a different expert community; because it does not introduce an independent criterion for what embeddings ought to capture, it cannot break the dependence on the exercise as ground truth and therefore does not fully address the concern that the gap may be protocol-specific.
Authors: The secondary study employs a distinct expert population (US Federal AI policy experts versus Danish policy experts) and a fully digital protocol, thereby replicating the reliability gap across domains, languages, and elicitation formats. This provides evidence that the gap is not an artifact of one specific group or paper-based instrument. We agree, however, that it retains dependence on the exercise as the reference criterion and does not introduce an orthogonal benchmark such as corpus co-occurrence. In the revised manuscript we will update the abstract and discussion to more precisely describe the replication's contribution while acknowledging this remaining dependence. revision: partial
- Direct, independent validation of the elicited associations against corpus-level co-occurrence statistics that does not rely on the Stakeholder Grounding Exercise itself.
Circularity Check
Empirical comparison with independent replication; no derivation chain or fitted inputs presented as predictions
full rationale
The paper introduces the Stakeholder Grounding Exercise to elicit explicit human associations and reports an empirical reliability gap (19-26 pp) between embeddings and experts, plus a Spearman correlation to downstream clustering. No equations, parameter fits, or first-principles derivations are described. The secondary replication uses a different protocol, language, and expert community, supplying independent support rather than a self-citation chain. The central claim is a measured performance difference against the elicited associations; this is a methodological benchmark choice, not a reduction of outputs to inputs by construction. Concerns about whether the exercise supplies the 'correct' ground truth fall under validity, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Charu C. Aggarwal and ChengXiang Zhai. 2012. https://doi.org/10.1007/978-1-4614-3223-4_4 A survey of text clustering algorithms . In Charu C. Aggarwal and ChengXiang Zhai, editors, Mining Text Data, pages 77--128. Springer US, Boston, MA
-
[2]
Adnan El Assadi, Isaac Chung, Roman Solomatin, Niklas Muennighoff, and Kenneth Enevoldsen. 2025. https://openreview.net/forum?id=rcmfu1ydAf HUME : Measuring the human-model performance gap in text embedding tasks . In The Fourteenth International Conference on Learning Representations
2025
-
[3]
Andrew M. Bean, Ryan Othniel Kearns, Angelika Romanou, Franziska Sofia Hafner, Harry Mayne, Jan Batzner, Negar Foroutan, Chris Schmitz, Karolina Korgul, Hunar Batra, Oishi Deb, Emma Beharry, Cornelius Emde, Thomas Foster, Anna Gausen, Mar \'i a Grandury, Simeng Han, Valentin Hofmann, Lujain Ibrahim, and 23 others. 2025. https://openreview.net/forum?id=mdA...
2025
-
[4]
Simon J. Blanchard and Ishani Banerji. 2016. https://doi.org/10.3758/s13428-015-0644-6 Evidence-based recommendations for designing free-sorting experiments . Behavior Research Methods, 48(4):1318--1336
-
[5]
Tolga Bolukbasi, Kai-Wei Chang, James Zou, Venkatesh Saligrama, and Adam Kalai. 2016. https://dl.acm.org/doi/10.5555/3157382.3157584 Man is to computer programmer as woman is to homemaker? debiasing word embeddings . In Proceedings of the 30th International Conference on Neural Information Processing Systems , NIPS '16, pages 4356--4364, Red Hook, NY, USA...
-
[6]
Samuel R. Bowman and George Dahl. 2021. https://doi.org/10.18653/v1/2021.naacl-main.385 What will it take to fix benchmarking in natural language understanding? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics : Human Language Technologies , pages 4843--4855, Online. Association for Compu...
-
[7]
Gary Bradski. 2000. https://elibrary.ru/item.asp?id=4934581 The opencv library . Dr. Dobb's Journal: Software Tools for the Professional Programmer, 25(11):120--123
2000
-
[8]
Mikael Brunila. 2025. https://doi.org/10.1177/20539517251386055 Cosine capital: Large language models and the embedding of all things . Big Data & Society, 12(4):20539517251386055
-
[9]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. https://doi.org/10.18653/v1/2024.findings-acl.137 M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation . In Findings of the Association for Computational Linguistics : ACL 2024 , pages 2318--2335, Bangkok...
-
[10]
Isaac Chung, Imene Kerboua, M \'a rton Kardos, Roman Solomatin, and Kenneth Enevoldsen. 2025. https://openreview.net/forum?id=qcPJs0KRZW Maintaining MTEB : Towards long term usability and reproducibility of embedding benchmarks . In Championing Open-source DEvelopment in ML Workshop @ ICML25
2025
-
[11]
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzm \'a n, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. https://doi.org/10.18653/v1/2020.acl-main.747 Unsupervised cross-lingual representation learning at scale . In Proceedings of the 58th Annual Meeting of the Association for Comp...
-
[12]
Psychological Bulletin , author =
Lee J. Cronbach and Paul E. Meehl. 1955. https://doi.org/10.1037/h0040957 Construct validity in psychological tests . Psychological bulletin, 52(4):281
-
[13]
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, M \'a rton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemi \'n ski, Genta Indra Winata, Saba Sturua, Saiteja Utpala, Mathieu Ciancone, Marion Schaeffer, Diganta Misra, Shreeya Dhakal, Jonathan Rystr m, Roman Solomatin, \"O mer Veysel C a g atan, and 63 others. 2025. https://openre...
2025
-
[14]
Kenneth Enevoldsen, M \'a rton Kardos, Niklas Muennighoff, and Kristoffer Nielbo. 2024. https://openreview.net/forum?id=2WbuKAfOxP#discussion The scandinavian embedding benchmarks: Comprehensive assessment of multilingual and monolingual text embedding . In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2024
-
[15]
Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, and Wei Wang. 2022. https://doi.org/10.18653/v1/2022.acl-long.62 Language-agnostic BERT sentence embedding . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 878--891, Dublin, Ireland. Association for Computational Linguistics
-
[16]
Natalia Flechas Manrique, Wanqian Bao, Aurelie Herbelot, and Uri Hasson. 2023. https://doi.org/10.18653/v1/2023.blackboxnlp-1.13 Enhancing interpretability using human similarity judgements to prune word embeddings . In Proceedings of the 6th BlackboxNLP Workshop : Analyzing and Interpreting Neural Networks for NLP , pages 169--179, Singapore. Association...
-
[17]
Miranda Fricker. 2007. https://doi.org/10.1093/acprof:oso/9780198237907.003.0008 Hermeneutical Injustice , 1 edition, pages 147--175. Oxford University PressOxford
work page doi:10.1093/acprof:oso/9780198237907.003.0008 2007
-
[18]
Miranda Fricker. 2017. Evolving concepts of epistemic injustice. In The Routledge Handbook of Epistemic Injustice. Routledge
2017
-
[19]
Friedler, Carlos Scheidegger, and Suresh Venkatasubramanian
Sorelle A. Friedler, Carlos Scheidegger, and Suresh Venkatasubramanian. 2021. https://doi.org/10.1145/3433949 The (im)possibility of fairness: Different value systems require different mechanisms for fair decision making . Commun. ACM, 64(4):136--143
-
[20]
Vahid Ghafouri, Jose Such, and Guillermo Suarez-Tangil . 2024. https://doi.org/10.18653/v1/2024.emnlp-main.1171 I love pineapple on pizza != I hate pineapple on pizza: Stance-aware sentence transformers for opinion mining . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 21046--21058, Miami, Florida, USA. ...
-
[21]
Robert Goldstone. 1994. https://doi.org/10.3758/BF03204653 An efficient method for obtaining similarity data . Behavior Research Methods, Instruments, & Computers, 26(4):381--386
-
[22]
Casper Hansen, Christian Hansen, Lucas Maystre, Rishabh Mehrotra, Brian Brost, Federico Tomasi, and Mounia Lalmas. 2020. https://doi.org/10.1145/3383313.3412248 Contextual and sequential user embeddings for large-scale music recommendation . In Fourteenth ACM Conference on Recommender Systems , pages 53--62, Virtual Event Brazil. ACM
-
[23]
Joseph Henrich, Steven J. Heine, and Ara Norenzayan. 2010. https://doi.org/10.1038/466029a Most people are not WEIRD . Nature, 466(7302):29--29
-
[24]
Michael C. Hout and Stephen D. Goldinger. 2016. https://doi.org/10.1037/xge0000144 SpAM is convenient but also satisfying: Reply to verheyen et al. (2016) . Journal of Experimental Psychology: General, 145(3):383--387
-
[25]
Michael C. Hout, Stephen D. Goldinger, and Ryan W. Ferguson. 2013. https://doi.org/10.1037/a0028860 The versatility of SpAM : A fast, efficient, spatial method of data collection for multidimensional scaling . Journal of Experimental Psychology: General, 142(1):256--281
-
[26]
Anastasiia Hrytsyna and Rodrigo Alves. 2025. https://doi.org/10.1145/3709148 From representation to response: Assessing the alignment of large language models with human judgment patterns . ACM Trans. Intell. Syst. Technol., 16(6):136:1--136:23
-
[27]
Gunay Y. Iskandarli. 2020. https://doi.org/10.5815/ijitcs.2020.06.01 Applying clustering and topic modeling to automatic analysis of citizens' comments in EGovernment . International Journal of Information Technology and Computer Science, 12(6):1--10
-
[28]
Abigail Z. Jacobs and Hanna Wallach. 2021. https://doi.org/10.1145/3442188.3445901 Measurement and fairness . In Proceedings of the 2021 ACM Conference on Fairness , Accountability , and Transparency , FAccT '21, pages 375--385, New York, NY, USA. Association for Computing Machinery
-
[29]
Yanrong Ji, Zhihan Zhou, Han Liu, and Ramana V Davuluri. 2021. https://doi.org/10.1093/bioinformatics/btab083 DNABERT : Pre-trained bidirectional encoder representations from transformers model for DNA-language in genome . Bioinformatics, 37(15):2112--2120
-
[30]
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. 2020. https://proceedings.neurips.cc/paper/2020/hash/d89a66c7c80a29b1bdbab0f2a1a94af8-Abstract.html Supervised contrastive learning . In Advances in Neural Information Processing Systems , volume 33, pages 18661--18673. Curran...
2020
-
[31]
Nikolaus Kriegeskorte and Marieke Mur. 2012. https://doi.org/10.3389/fpsyg.2012.00245 Inverse MDS : Inferring dissimilarity structure from multiple item arrangements . Frontiers in Psychology, 3
-
[32]
Klaus Krippendorff. 2011. https://repository.upenn.edu/handle/20.500.14332/2089 Computing krippendorff's alpha-reliability
2011
-
[33]
Ida Marie S Lassen, Jens Christian Bjerring, and Kristoffer L Nielbo. 2025. https://doi.org/10.1177/20539517251365228 Silencing in data science practices . Big Data & Society, 12(3):20539517251365228
-
[34]
Minghao Li, Tengchao Lv, Jingye Chen, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, and Furu Wei. 2023. https://doi.org/10.1609/aaai.v37i11.26538 TrOCR : Transformer-based optical character recognition with pre-trained models . In Proceedings of the Thirty-seventh AAAI Conference on Artificial Intelligence and Thirty-fifth Conference on Inno...
-
[35]
Qian Li, Hao Peng, Jianxin Li, Congying Xia, Renyu Yang, Lichao Sun, Philip S. Yu, and Lifang He. 2022. https://doi.org/10.1145/3495162 A survey on text classification: From traditional to deep learning . ACM Trans. Intell. Syst. Technol., 13(2):31:1--31:41
-
[36]
Tao Li, Daniel Khashabi, Tushar Khot, Ashish Sabharwal, and Vivek Srikumar. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.311 UNQOVERing stereotyping biases via underspecified questions . In Findings of the Association for Computational Linguistics : EMNLP 2020 , pages 3475--3489, Online. Association for Computational Linguistics
-
[37]
Xianming Li and Jing Li. 2024. https://doi.org/10.18653/v1/2024.acl-long.101 AoE : Angle-optimized embeddings for semantic textual similarity . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 1825--1839, Bangkok, Thailand. Association for Computational Linguistics
- [38]
-
[39]
Anders Koed Madsen, Johan Irving S ltoft, and Anne-Sofie Klitgaard-Sofie . 2025. Datafantasi: Fra styring til l ring i en verden af vilde problemer. In Organisatorisk L ring Og Forandring: Individer, Grupper Og Processer, 1 edition, pages 137--155. Samfundslitteratur, K benhavn
2025
-
[40]
I. McLean. 1990. https://doi.org/10.1007/BF01560577 The borda and condorcet principles: Three medieval applications . Social Choice and Welfare, 7(2):99--108
-
[41]
John Xavier Morris and Alexander M. Rush. 2024. https://openreview.net/forum?id=Wqsk3FbD6D Contextual document embeddings . In The Thirteenth International Conference on Learning Representations
2024
-
[42]
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. 2023. https://doi.org/10.18653/v1/2023.eacl-main.148 MTEB : Massive text embedding benchmark . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages 2014--2037, Dubrovnik, Croatia. Association for Computational Linguistics
-
[43]
OpenAI, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, A. J. Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander M a dry, Alex Baker-Whitcomb , Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, and 400 others. 2024. https://doi.org/10.48550/arXiv.2410.21276 GPT-4o system card . ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.21276 2024
-
[44]
Bender, Emily Denton, and Alex Hanna
Amandalynne Paullada, Inioluwa Deborah Raji, Emily M. Bender, Emily Denton, and Alex Hanna. 2021. https://doi.org/10.1016/j.patter.2021.100336 Data and its (dis)contents: A survey of dataset development and use in machine learning research . Patterns, 2(11)
-
[45]
Uwe Peters. 2022. https://doi.org/10.1007/s13347-022-00512-8 Algorithmic political bias in artificial intelligence systems . Philosophy & Technology, 35(2):25
-
[46]
William M. Rand. 1971. https://doi.org/10.1080/01621459.1971.10482356 Objective criteria for the evaluation of clustering methods . Journal of the American Statistical Association, 66(336):846--850
-
[47]
Maribeth Rauh, John Mellor, Jonathan Uesato, Po-Sen Huang, Johannes Welbl, Laura Weidinger, Sumanth Dathathri, Amelia Glaese, Geoffrey Irving, Iason Gabriel, William Isaac, and Lisa Anne Hendricks. 2022. Characteristics of harmful text: Towards rigorous benchmarking of language models. In Proceedings of the 36th International Conference on Neural Informat...
2022
-
[48]
Nils Reimers and Iryna Gurevych. 2019. https://doi.org/10.18653/v1/D19-1410 Sentence- BERT : Sentence embeddings using siamese BERT-networks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing ( EMNLP-IJCNLP ) , pages 3982--3992, Hong Kong, Ch...
-
[49]
Philip Resnik and Jimmy Lin. 2010. https://doi.org/10.1002/9781444324044.ch11 Evaluation of NLP systems . In The Handbook of Computational Linguistics and Natural Language Processing, chapter 11, pages 271--295. John Wiley & Sons, Ltd
-
[50]
Russell Richie, Bryan White, Sudeep Bhatia, and Michael C. Hout. 2020. https://doi.org/10.3758/s13428-020-01362-y The spatial arrangement method of measuring similarity can capture high-dimensional semantic structures . Behavior Research Methods, 52(5):1906--1928
-
[51]
Paul R \"o ttger, Valentin Hofmann, Valentina Pyatkin, Musashi Hinck, Hannah Kirk, Hinrich Schuetze, and Dirk Hovy. 2024. https://doi.org/10.18653/v1/2024.acl-long.816 Political compass or spinning arrow? Towards more meaningful evaluations for values and opinions in large language models . In Proceedings of the 62nd Annual Meeting of the Association for ...
-
[52]
Jonathan Hvithamar Rystr m, Hannah Rose Kirk, and Scott Hale. 2025. https://aclanthology.org/2025.ommm-1.9/ Multilingual != multicultural: Evaluating gaps between multilingual capabilities and cultural alignment in LLMs . In Proceedings of Interdisciplinary Workshop on Observations of Misunderstood , Misguided and Malicious Use of Language Models , pages ...
2025
-
[53]
Ahmed, Suhana Bedi, Zachary Robertson, Sudharsan Sundar, Benjamin W
Olawale Elijah Salaudeen, Anka Reuel, Ahmed M. Ahmed, Suhana Bedi, Zachary Robertson, Sudharsan Sundar, Benjamin W. Domingue, Angelina Wang, and Sanmi Koyejo. 2025. https://openreview.net/forum?id=2Bw6uC49QF&referrer= In NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle : Benchmarks , Emergent Abilities , and Scaling
2025
-
[54]
James C. Scott. 2020. https://books.google.com/books?hl=en&lr=&id=Qe_RDwAAQBAJ&oi=fnd&pg=PP1&dq=seeing+like+a+state+jc+scott&ots=FA5E2LC-8p&sig=S64GLxV1q6dxcdtD9YHbFXz_io0 Seeing like a State: How Certain Schemes to Improve the Human Condition Have Failed . yale university Press
2020
-
[55]
Mona Sloane, Emanuel Moss, Olaitan Awomolo, and Laura Forlano. 2022. https://doi.org/10.1145/3551624.3555285 Participation is not a design fix for machine learning . In Equity and Access in Algorithms , Mechanisms , and Optimization , pages 1--6, Arlington VA USA. ACM
-
[56]
C. Spearman. 1904. https://doi.org/10.2307/1412159 The proof and measurement of association between two things . The American Journal of Psychology, 15(1):72--101
-
[57]
Smith, Luke Zettlemoyer, and Tao Yu
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A. Smith, Luke Zettlemoyer, and Tao Yu. 2023. https://doi.org/10.18653/v1/2023.findings-acl.71 One embedder, any task: Instruction-finetuned text embeddings . In Findings of the Association for Computational Linguistics : ACL 2023 , pages 1102--1121, Toronto, Ca...
-
[58]
Stephan Tulkens and Thomas van Dongen . 2024. https://doi.org/10.5281/zenodo.17270888 Model2Vec : Fast state-of-the-art static embeddings
-
[59]
Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, Daniel Cer, Alice Lisak, Min Choi, Lucas Gonzalez, Omar Sanseviero, Glenn Cameron, Ian Ballantyne, Kat Black, Kaifeng Chen, and 70 others. 2025. https://doi.org/10.48550/arXiv.2509.20354 EmbeddingGemma : Powe...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.20354 2025
-
[60]
Daniela Vianna, Edleno Silva de Moura , and Altigran Soares da Silva . 2024. https://doi.org/10.1007/s10506-023-09371-w A topic discovery approach for unsupervised organization of legal document collections . Artificial Intelligence and Law, 32(4):1045--1074
-
[61]
Voorhees
Ellen M. Voorhees. 1999. http://trec.nist.gov/pubs/trec8/papers/qa_report.pdf The trec-8 question answering track report . In Trec, volume 99, pages 77--82
1999
-
[62]
Voorhees and Donna K
Ellen M. Voorhees and Donna K. Harman. 2005. https://aclanthology.org/anthology-files/anthology-files/pdf/J/J06/J06-4008.pdf TREC : Experiment and Evaluation in Information Retrieval , volume 63. MIT press Cambridge
2005
-
[63]
Sandra Wachter, Brent Mittelstadt, and Chris Russell. 2021. https://doi.org/10.2139/ssrn.3792772 Bias preservation in machine learning: The legality of fairness metrics under EU non-discrimination law . West Virginia Law Review
-
[64]
Feder Cooper, Angelina Wang, Chad Atalla, Solon Barocas, Su Lin Blodgett, Alexandra Chouldechova, Emily Corvi, P
Hanna Wallach, Meera Desai, A. Feder Cooper, Angelina Wang, Chad Atalla, Solon Barocas, Su Lin Blodgett, Alexandra Chouldechova, Emily Corvi, P. Alex Dow, Jean Garcia-Gathright , Alexandra Olteanu, Nicholas J. Pangakis, Stefanie Reed, Emily Sheng, Dan Vann, Jennifer Wortman Vaughan, Matthew Vogel, Hannah Washington, and Abigail Z. Jacobs. 2025. https://op...
2025
-
[65]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. https://doi.org/10.48550/arXiv.2402.05672 Multilingual E5 text embeddings: A technical report . Preprint, arXiv:2402.05672
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.05672 2024
-
[66]
Joe H. Ward. 1963. https://doi.org/10.1080/01621459.1963.10500845 Hierarchical grouping to optimize an objective function . Journal of the American Statistical Association, 58(301):236--244
-
[67]
Sigge Winther Nielsen. 2025. The Puzzle State: How to Govern Wicked Problems in Western Democracies, 1. printing edition. Gad Publishers, Copenhagen
2025
-
[68]
Ledell Wu, Adam Fisch, Sumit Chopra, Keith Adams, Antoine Bordes, and Jason Weston. 2018. https://doi.org/10.1609/aaai.v32i1.11996 StarSpace : Embed all the things! Proceedings of the AAAI Conference on Artificial Intelligence, 32(1)
-
[69]
Weiai Wayne Xu, Jean Marie Tshimula, \`E ve Dub \'e , Janice E. Graham, Devon Greyson, Noni E. MacDonald, and Samantha B. Meyer. 2022. https://doi.org/10.2196/41198 Unmasking the Twitter discourses on masks during the COVID-19 pandemic: User cluster--based BERT topic modeling approach . JMIR Infodemiology, 2(2):e41198
-
[70]
Puxuan Yu, Luke Merrick, Gaurav Nuti, and Daniel Campos. 2024. https://doi.org/10.48550/arXiv.2412.04506 Arctic-embed 2.0: Multilingual retrieval without compromise . Preprint, arXiv:2412.04506
-
[71]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. https://doi.org/10.48550/arXiv.2506.05176 Qwen3 embedding: Advancing text embedding and reranking through foundation models . Preprint, arXiv:2506.05176
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176 2025
-
[72]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[73]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.