Whose Name Comes Up? III: Persona Prompting Effects in LLM-Based Scholar Recommendation
Pith reviewed 2026-06-29 09:57 UTC · model grok-4.3
The pith
Persona prompts in LLMs alter which scholars get recommended as experts, with location and context driving separate effects on factuality and diversity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
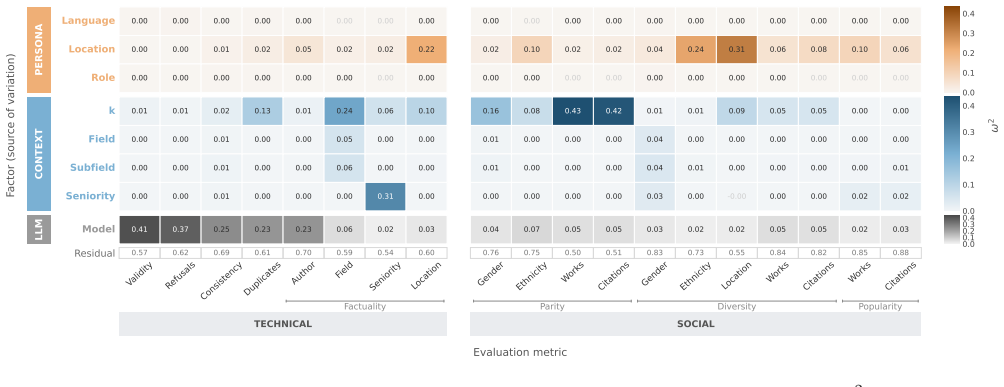
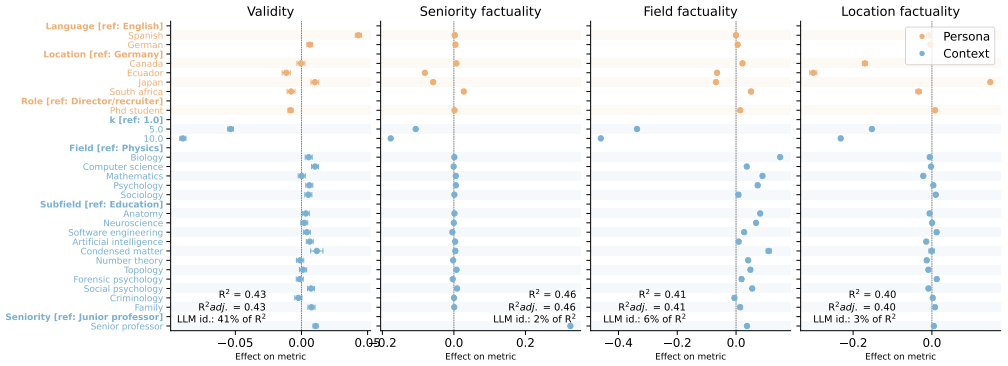
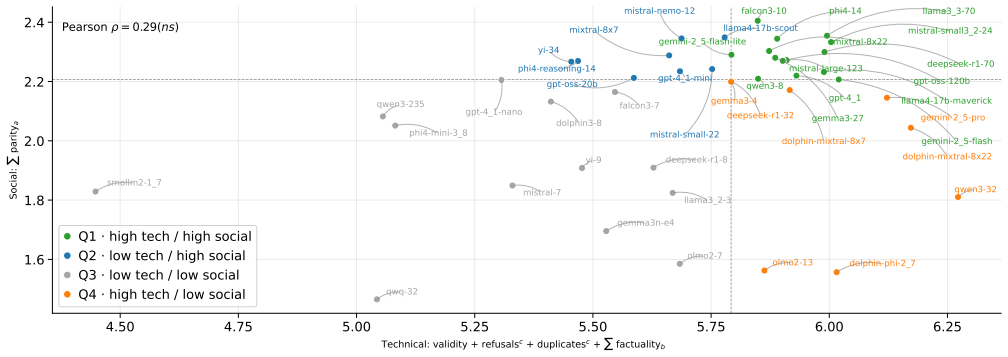
The authors develop a benchmark that isolates the effects of model choice from those of persona prompts (language, location, role-and-task) and context (field, seniority, k) when LLMs recommend scholars. They evaluate outputs from 43 models across six disciplines against Semantic Scholar on technical quality measures (factuality, coverage) and social representativeness measures (diversity, parity). Basic technical quality tracks model choice, factuality and parity track context, and diversity tracks location. South Africa persona prompts produce less factual lists while Japan persona prompts produce factual lists that are homogeneous and favor highly productive scholars.
What carries the argument
A benchmark that varies persona prompts and context while holding model fixed, then scores recommended scholars against Semantic Scholar on factuality, coverage, diversity, and parity.
If this is right
- Model choice sets the baseline technical quality of scholar lists.
- Context details such as field and seniority control how factual and balanced the lists are.
- Location specified in the prompt controls how diverse the recommended scholars are.
- South Africa persona prompts lower the factuality of the output lists.
- Japan persona prompts raise factuality but reduce diversity and skew toward high-productivity scholars.
Where Pith is reading between the lines
- Users in different countries could receive systematically different pictures of who counts as an expert through the same LLM.
- Prompt templates might need region-specific adjustments to avoid uneven visibility for scholars from certain locations.
- Auditing prompts could become a standard step when deploying LLMs for academic search tasks.
Load-bearing premise
Comparing LLM outputs to Semantic Scholar gives an unbiased standard for judging both technical quality and social representativeness of the recommendations.
What would settle it
If factuality, coverage, diversity, and parity scores stayed identical across all persona prompt variations in the benchmark, the claim that prompt design is a non-trivial factor would not hold.
Figures



read the original abstract
Large language models (LLMs) are increasingly used as scholar recommenders, shaping who is seen as an expert in academia. Existing audits remain English-centric, single discipline, and persona-agnostic, leaving the source of output variability poorly understood. To this end, we propose a benchmark that disentangles the effects of model choice and prompt design on recommendations. We audit 43 LLMs by varying persona prompts (language, location, role-and-task) and context (field, seniority, k). Recommended scholars are compared against Semantic Scholar over six scientific disciplines to measure technical quality (factuality, coverage) and social representativeness (diversity, parity). Basic technical quality is driven by model choice, factuality and parity by context, and diversity by location. South Africa prompts yield less factual lists, while Japan prompts yield highly factual but homogeneous lists skewed toward highly productive scholars. Prompt design is thus a non-trivial axis of LLM-based scholar discovery and should be systematically audited alongside model choice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript audits 43 LLMs for scholar recommendation by varying persona prompts (language, location, role-and-task) and context (field, seniority, k) across six disciplines. Recommended scholars are compared to Semantic Scholar to quantify technical quality (factuality, coverage) and social representativeness (diversity, parity). The central claims are that model choice drives basic technical quality, context drives factuality and parity, and location drives diversity, with South Africa prompts producing less factual lists and Japan prompts producing highly factual but homogeneous lists skewed toward high-productivity scholars. The conclusion is that prompt design is a non-trivial axis requiring systematic audit alongside model choice.
Significance. If the empirical results hold after addressing baseline validation, the work provides a scalable benchmark for disentangling prompt versus model effects in LLM-based academic search, with implications for fairness in who is surfaced as an expert. The audit's scale (43 models, multiple disciplines and contexts) and explicit separation of prompt axes are strengths that could support reproducible follow-up studies.
major comments (2)
- [Methods (comparison to Semantic Scholar)] The evaluation treats Semantic Scholar as the neutral reference for factuality (existence/correctness), coverage, diversity, and parity, yet the manuscript provides no validation that SS coverage or distributions are unbiased with respect to the location (South Africa, Japan) and language axes used in the persona prompts. This is load-bearing for the attribution of differences to prompts rather than baseline artifacts.
- [Results (location-prompt findings)] The headline location-prompt effects (SA prompts reduce factuality; Japan prompts increase homogeneity) rest on the untested assumption that SS provides an unbiased ground truth across the tested persona axes; without explicit checks (e.g., coverage rates by region/language in the six disciplines), the causal link to prompt design cannot be isolated.
minor comments (2)
- [Abstract] The abstract states high-level findings but omits any description of experimental design, data processing, statistical tests, or error handling, which reduces immediate assessability even though the full methods are presumably present.
- [Methods] Ensure operational definitions and formulas for the four metrics (factuality, coverage, diversity, parity) are stated explicitly, including how ties or missing SS entries are handled.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to validate Semantic Scholar as a reference. The two major comments raise a single core issue regarding potential bias in the ground truth, which we address point by point below. We agree this assumption merits explicit discussion.
read point-by-point responses
-
Referee: [Methods (comparison to Semantic Scholar)] The evaluation treats Semantic Scholar as the neutral reference for factuality (existence/correctness), coverage, diversity, and parity, yet the manuscript provides no validation that SS coverage or distributions are unbiased with respect to the location (South Africa, Japan) and language axes used in the persona prompts. This is load-bearing for the attribution of differences to prompts rather than baseline artifacts.
Authors: We acknowledge that the manuscript does not provide explicit validation or coverage statistics for Semantic Scholar broken down by the location and language axes. Semantic Scholar was selected as the reference because it is the largest open academic graph with broad disciplinary coverage and is commonly used in similar recommendation audits. In the revision we will add a limitations subsection that (a) states the assumption explicitly, (b) discusses how regional or language biases in SS could affect absolute factuality scores, and (c) reports any readily available aggregate coverage indicators for the six disciplines. Comprehensive per-region validation would require external datasets not integrated in the current study. revision: partial
-
Referee: [Results (location-prompt findings)] The headline location-prompt effects (SA prompts reduce factuality; Japan prompts increase homogeneity) rest on the untested assumption that SS provides an unbiased ground truth across the tested persona axes; without explicit checks (e.g., coverage rates by region/language in the six disciplines), the causal link to prompt design cannot be isolated.
Authors: The reported location effects are differences relative to a fixed SS reference; therefore the comparative claims (SA prompts produce lower factuality scores than other locations, Japan prompts produce higher homogeneity) remain internally consistent even if SS itself has coverage skew. We agree, however, that the manuscript should qualify the interpretation by noting that absolute factuality attributions could be confounded by reference bias. The revision will insert clarifying language in the results and discussion sections stating that the findings demonstrate prompt-induced shifts relative to SS and that future work should cross-validate against additional sources. This does not change the core empirical patterns but strengthens the causal framing. revision: partial
Circularity Check
No circularity: empirical comparisons to external Semantic Scholar benchmark
full rationale
The paper conducts a purely empirical audit: 43 LLMs are prompted with varying persona (language, location, role) and context (field, seniority, k) settings; outputs are scored for factuality, coverage, diversity, and parity by direct comparison to Semantic Scholar records across six disciplines. No equations, fitted parameters, predictions, or derivations appear. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. All central claims (e.g., location prompts drive diversity; South Africa prompts reduce factuality) are measured against an independent external database rather than reducing to the paper's own inputs by construction. This is the standard case of a self-contained empirical study against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
I.; Gunasekar, S.; Chandrasekaran, V.; Li, J.; Yuksekgonul, M.; Peshawaria, R.; Naik, R.; and Nushi, B
Abdin, M. I.; Gunasekar, S.; Chandrasekaran, V.; Li, J.; Yuksekgonul, M.; Peshawaria, R.; Naik, R.; and Nushi, B. 2024. Kitab: Evaluating llms on constraint satisfaction for information retrieval. In International Conference on Learning Representations, volume 2024, 30664--30686
2024
-
[4]
Anonymous. 2025. Anonymous Repository for Auditing LLMs as People Recommender Systems Across Languages and Countries. https://anonymous.4open.science/r/PersonasScholarRec. Anonymous repository for double-blind review
2025
- [5]
-
[6]
S.; and Jayagopi, D
Awasthi, D.; Rao, P. S.; and Jayagopi, D. B. 2025. ResumeGenAI: Supporting Job Seekers with LLM-Driven Resume Feedback. In Proceedings of the 7th ACM Conference on Conversational User Interfaces, 1--9
2025
-
[7]
Barolo, D.; Valentin, C.; Karimi, F.; Gal \'a rraga, L.; M \'e ndez, G. G.; and Esp \' n-Noboa, L. 2025. Whose Name Comes Up? Auditing LLM-Based Scholar Recommendations. arXiv preprint arXiv:2506.00074
-
[8]
Benjamini, Y.; and Hochberg, Y. 1995. Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal statistical society: series B (Methodological), 57(1): 289--300
1995
-
[9]
S.; and Pagan, A
Breusch, T. S.; and Pagan, A. R. 1979. A simple test for heteroscedasticity and random coefficient variation. Econometrica: Journal of the econometric society, 1287--1294
1979
-
[10]
S.; Zhang, Y.; Kejriwal, M.; and Calyam, P
Cheng, X.; Edara, L. S.; Zhang, Y.; Kejriwal, M.; and Calyam, P. 2024. Influence Role Recognition and LLM-Based Scholar Recommendation in Academic Social Networks. In 2024 IEEE 11th International Conference on Data Science and Advanced Analytics (DSAA), 1--11. IEEE
2024
-
[11]
De Araujo, P. H. L.; R \"o ttger, P.; Hovy, D.; and Roth, B. 2025. Principled personas: Defining and measuring the intended effects of persona prompting on task performance. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 26845--26874
2025
-
[12]
Towards Measuring the Representation of Subjective Global Opinions in Language Models
Durmus, E.; Nguyen, K.; Liao, T. I.; Schiefer, N.; Askell, A.; Bakhtin, A.; Chen, C.; Hatfield-Dodds, Z.; Hernandez, D.; Joseph, N.; et al. 2023. Towards measuring the representation of subjective global opinions in language models. arXiv preprint arXiv:2306.16388
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Espin-Noboa, L.; and Mendez, G. G. 2026. Whose Name Comes Up? Benchmarking and Intervention-Based Auditing of LLM-Based Scholar Recommendation. arXiv preprint arXiv:2602.08873
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
L.; Bonchi, F.; and Castillo, C
Fabbri, F.; Croci, M. L.; Bonchi, F.; and Castillo, C. 2022. Exposure inequality in people recommender systems: The long-term effects. In Proceedings of the international AAAI conference on web and social media, volume 16, 194--204
2022
-
[15]
Hanusz, Z.; Tarasinska, J.; and Zielinski, W. 2016. Shapiro--Wilk test with known mean. REVSTAT-statistical Journal, 14(1): 89--100
2016
- [16]
-
[17]
M.; Macedo, M.; Oliveira, M.; Karimi, F.; and Menezes, R
Jaramillo, A. M.; Macedo, M.; Oliveira, M.; Karimi, F.; and Menezes, R. 2025. Systematic comparison of gender inequality in scientific rankings across disciplines. arXiv preprint arXiv:2501.13061
-
[18]
Jiao, J.; Afroogh, S.; Xu, Y.; and Phillips, C. 2025. Navigating llm ethics: Advancements, challenges, and future directions. AI and Ethics, 1--25
2025
-
[19]
Karimi, F.; Wagner, C.; Lemmerich, F.; Jadidi, M.; and Strohmaier, M. 2016. Inferring Gender from Names on the Web: A Comparative Evaluation of Gender Detection Methods. In Proceedings of the 25th International Conference Companion on World Wide Web, WWW '16 Companion, 53--54. New York, New York, USA: ACM Press
2016
-
[20]
Kim, J.; Yang, N.; and Jung, K. 2025. Persona is a Double-Edged Sword: Rethinking the Impact of Role-play Prompts in Zero-shot Reasoning Tasks. In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, 848--862
2025
-
[21]
Kinney, R. M.; Anastasiades, C.; Authur, R.; Beltagy, I.; Bragg, J.; Buraczynski, A.; Cachola, I.; Candra, S.; Chandrasekhar, Y.; Cohan, A.; Crawford, M.; Downey, D.; Dunkelberger, J.; Etzioni, O.; Evans, R.; Feldman, S.; Gorney, J.; Graham, D. W.; Hu, F.; Huff, R.; King, D.; Kohlmeier, S.; Kuehl, B.; Langan, M.; Lin, D.; Liu, H.; Lo, K.; Lochner, J.; Mac...
-
[22]
S.; Bell, A.; Hulsey, W.; Larivière, V.; Monroe-White, T.; and Sugimoto, C
Kozlowski, D.; Murray, D. S.; Bell, A.; Hulsey, W.; Larivière, V.; Monroe-White, T.; and Sugimoto, C. R. 2022. Avoiding bias when inferring race using name-based approaches. PLOS ONE
2022
-
[23]
D.; and Finley, J
Kroes, A. D.; and Finley, J. R. 2023. Demystifying omega squared: Practical guidance for effect size in common analysis of variance designs. Psychological Methods
2023
-
[24]
R.; and Koch, G
Landis, J. R.; and Koch, G. G. 1977. The measurement of observer agreement for categorical data. biometrics, 159--174
1977
-
[25]
Letteri, I.; and Vittorini, P. 2024. Exploring the Impact of LLM-Generated Feedback: Evaluation from Professors and Students in Data Science Courses. In International Conference in Methodologies and intelligent Systems for Techhnology Enhanced Learning, 11--20. Springer
2024
- [26]
-
[27]
Liang, L.; and Acuna, D. 2021. demographicx: A Python package for estimating gender and ethnicity using deep learning transformers. Zenodo https://doi. org/10.5281/zenodo, 4898367
-
[28]
Lin, A.; Wang, J.; Zhu, Z.; and Caverlee, J. 2022. Quantifying and mitigating popularity bias in conversational recommender systems. In Proceedings of the 31st ACM international conference on information & knowledge management, 1238--1247
2022
-
[29]
Liu, Y.; Elekes, \'A .; Lu, J.; Dorantes-Gilardi, R.; and Barab \'a si, A.-L. 2025. Unequal Scientific Recognition in the Age of LLMs. In Findings of the Association for Computational Linguistics: EMNLP 2025, 23558--23568
2025
-
[30]
P.-W.; Qiu, J.; Wang, Z.; Yu, H.; Chen, Y.; Zhang, G.; and Lo, B
Lo, F. P.-W.; Qiu, J.; Wang, Z.; Yu, H.; Chen, Y.; Zhang, G.; and Lo, B. 2025. AI Hiring with LLMs: A Context-Aware and Explainable Multi-Agent Framework for Resume Screening. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 4223--4232
2025
-
[31]
Lutz, M.; Sen, I.; Ahnert, G.; Rogers, E.; and Strohmaier, M. 2025. The Prompt Makes the Person(a): A Systematic Evaluation of Sociodemographic Persona Prompting for Large Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2025, 23212--23237. Suzhou, China: Association for Computational Linguistics
2025
-
[32]
Pava, J.; Meinhardt, C.; Zaman, H. B. U.; Friedman, T.; Truong, S. T.; Zhang, D.; Marivate, V.; and Koyejo, S. 2025. Mind the (Language) Gap: Mapping the Challenges of LLM Development in Low-Resource Language Contexts
2025
-
[33]
Polonioli, A. 2021. The ethics of scientific recommender systems. Scientometrics, 126(2): 1841--1848
2021
-
[34]
Priem, J.; Piwowar, H.; and Orr, R. 2022. OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts. arXiv preprint arXiv:2205.01833
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
K.; and Bijoy Das, A
Sakib, S. K.; and Bijoy Das, A. 2024. Challenging Fairness: A Comprehensive Exploration of Bias in LLM-Based Recommendations. In 2024 IEEE International Conference on Big Data (BigData), 1585--1592
2024
-
[36]
Sandnes, F. E. 2024. Can we identify prominent scholars using ChatGPT? Scientometrics, 129(1): 713--718
2024
- [37]
-
[38]
Tonneau, M.; Sehgal, N. K. R.; Malhotra, N.; Kazemi, S.; Orozco-Olvera, V.; Mu \ n oz Boudet, A. M.; Subramanian, L.; Fraiberger, S. P.; Guntuku, S. C.; and Hofmann, V. 2026. Different Demographic Cues Yield Inconsistent Conclusions About LLM Personalization and Bias . arXiv preprint arXiv:2601.18486v2
- [39]
-
[40]
V \'a s \'a rhelyi, O.; Zakhlebin, I.; Milojevi \'c , S.; and Horv \'a t, E.- \'A . 2021. Gender inequities in the online dissemination of scholars’ work. Proceedings of the National Academy of Sciences, 118(39): e2102945118
2021
-
[41]
Wald, A. 1943. Tests of statistical hypotheses concerning several parameters when the number of observations is large. Transactions of the American Mathematical society, 54(3): 426--482
1943
-
[42]
E.; and Koyejo, S
Wang, A.; Ho, D. E.; and Koyejo, S. 2025. The inadequacy of offline large language model evaluations: A need to account for personalization in model behavior. Patterns, 6(12)
2025
-
[43]
A.; Liu, F.; Georgiev, G
Wang, Y.; Wang, M.; Manzoor, M. A.; Liu, F.; Georgiev, G. N.; Das, R. J.; and Nakov, P. 2024. Factuality of Large Language Models: A Survey. In Al-Onaizan, Y.; Bansal, M.; and Chen, Y.-N., eds., Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 19519--19529. Miami, Florida, USA: Association for Computational Linguistics
2024
-
[44]
Weeber, F.; Neplenbroek, V.; Batzner, J.; and Pad \'o , S. 2026. One Persona , Many Cues , Different Results : How Sociodemographic Cues Impact LLM Personalization . arXiv preprint arXiv:2601.18572
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Whittle, R. 2024. Why Microsoft’s Copilot AI falsely accused court reporter of crimes he covered. The Conversation. Accessed: 2026-05-22
2024
-
[46]
Wilson, K.; Sim, M.; Gueorguieva, A.-M.; and Caliskan, A. 2025. No Thoughts Just AI: Biased LLM Hiring Recommendations Alter Human Decision Making and Limit Human Autonomy. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, 2692--2704
2025
-
[47]
B.; and Hu, G
Xu, S. B.; and Hu, G. 2025. Rethinking the author name ambiguity problem and beyond: The case of the Chinese context. Accountability in research, 32(6): 913--936
2025
-
[48]
Xu, Y.; Hu, L.; Zhao, J.; Qiu, Z.; Xu, K.; Ye, Y.; and Gu, H. 2025. A survey on multilingual large language models: Corpora, alignment, and bias. Frontiers of Computer Science, 19(11): 1911362
2025
-
[49]
Ye, W.; Zhang, Q.; Zhou, X.; Hu, W.; Tian, C.; and Cheng, J. 2024. Correcting Factual Errors in LLMs via Inference Paths Based on Knowledge Graph. In 2024 International Conference on Computational Linguistics and Natural Language Processing (CLNLP), 12--16. IEEE
2024
-
[50]
Ye, X.; and Durrett, G. 2022. The unreliability of explanations in few-shot prompting for textual reasoning. Advances in neural information processing systems, 35: 30378--30392
2022
-
[51]
Zhang, X.; Li, S.; Hauer, B.; Shi, N.; and Kondrak, G. 2023. Don’t Trust ChatGPT when your Question is not in English: A Study of Multilingual Abilities and Types of LLMs. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 7915--7927
2023
- [52]
-
[53]
Zheng, M.; Pei, J.; Logeswaran, L.; Lee, M.; and Jurgens, D. 2024. When” a helpful assistant” is not really helpful: Personas in system prompts do not improve performances of large language models. In Findings of the Association for Computational Linguistics: EMNLP 2024, 15126--15154
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.