CAST: Non-Privileged Clipped Asymmetric Self-Teaching with Advantage Flipping for GRPO
Pith reviewed 2026-06-28 22:23 UTC · model grok-4.3
The pith
CAST improves GRPO training for language model reasoning by using stop-gradient self-teaching and bidirectional advantage flipping to align token signals with verifier correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAST keeps the verifier-grounded GRPO objective but augments it with answer-free self-distillation that applies bidirectional local advantage sign reversal to the self-teacher log-probability gap, so teacher-negative tokens in correct trajectories receive negative token advantages and teacher-positive tokens in incorrect trajectories receive bounded positive advantages; for zero-variance groups it assigns bounded sign-constrained base advantages so these groups can still contribute verifier-signed token feedback.
What carries the argument
Clipped asymmetric self-teaching with advantage flipping, which uses a stop-gradient self-teacher to shape token-level advantages from the log-probability gap according to trajectory correctness via bidirectional sign reversal.
If this is right
- Zero-variance all-correct and all-wrong groups contribute verifier-signed token feedback instead of producing zero gradients.
- Token preferences become aligned with trajectory outcome rather than exhibiting the mismatched noise profiles seen in prior self-distillation.
- The self-teacher remains active throughout training without needing reference solutions for scoring.
- The overall objective stays a lightweight trajectory-level verifier signal plus the shaped token advantages.
Where Pith is reading between the lines
- The same sign-reversal logic could be applied to other on-policy reinforcement learning algorithms that suffer from all-correct or all-wrong sampling batches.
- Reducing the minimum group size needed to avoid zero-variance cases might become feasible if advantage flipping reliably supplies signal.
- Testing whether the alignment between shaped advantages and correctness holds on non-mathematical tasks would show how domain-specific the benefit is.
Load-bearing premise
The self-teacher log-probability gap, once shaped by trajectory correctness through advantage flipping, produces token-level advantages more aligned with final verifier correctness than the original signals.
What would settle it
Measuring whether token advantages under CAST training correlate more strongly with trajectory correctness than baseline signals, or running the method on math reasoning benchmarks and finding no accuracy gain over standard GRPO.
Figures

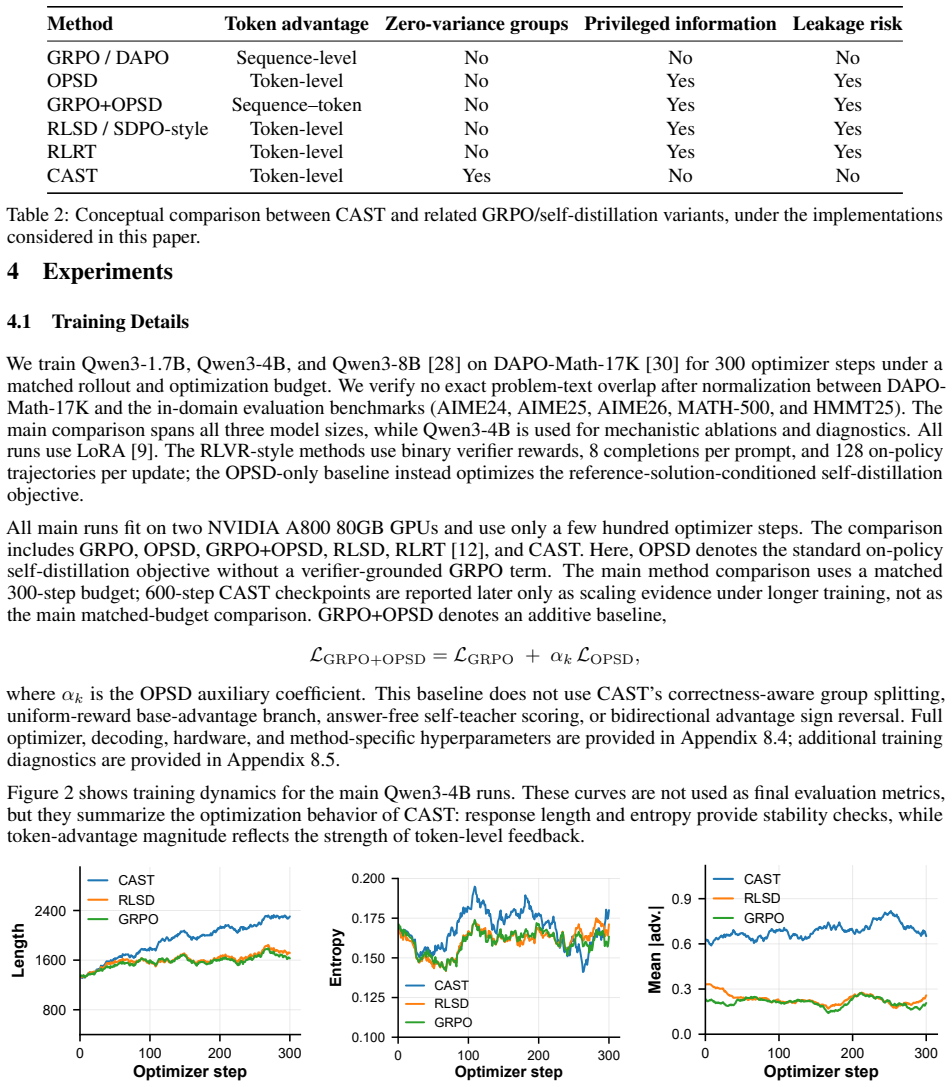
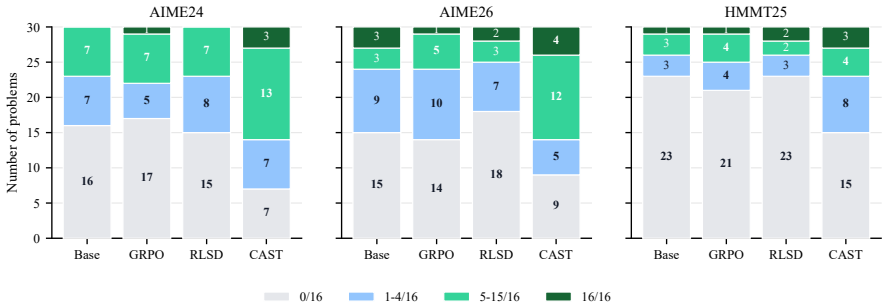


read the original abstract
Reinforcement learning with verifiable rewards (RLVR), especially Group Relative Policy Optimization (GRPO), has been widely used to improve reasoning in large language models. However, outcome-level rewards provide only sparse supervision, and group-relative advantages vanish when all sampled trajectories for a prompt are either correct or incorrect. On-Policy Self-Distillation (OPSD) offers dense token-level guidance, but its token preferences are not necessarily aligned with trajectory correctness; empirical diagnostics show that OPSD signals behave differently on correct and incorrect rollouts, with teacher-positive and teacher-negative gap signals exhibiting different noise profiles. These diagnostics are conducted under an OPSD-style privileged teacher context for analysis only, whereas CAST training uses answer-free self-teacher scoring.Motivated by these observations, this work proposes CAST, an answer-free self-distillation method for GRPO-style RLVR. CAST keeps the verifier-grounded GRPO objective, but uses a stop-gradient self-teacher to shape token-level advantages according to trajectory correctness. Unlike prior self-distilled RLVR methods, CAST does not require reference-solution-conditioned teacher scoring, keeps the self-teacher log-probability gap active throughout training, and applies bidirectional local advantage sign reversal: teacher-negative tokens in correct trajectories can receive negative token-level advantages, while teacher-positive tokens in incorrect trajectories can receive bounded positive local advantages. For zero-variance all-correct and all-wrong groups, CAST assigns bounded sign-constrained base advantages, so these otherwise zero-gradient groups can contribute verifier-signed token feedback. Experiments on mathematical reasoning show that CAST improves RLVR training while retaining a lightweight, verifier-grounded trajectory-level objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CAST, a non-privileged clipped asymmetric self-teaching method with advantage flipping for GRPO in RLVR. It retains the verifier-grounded trajectory-level objective while using a stop-gradient answer-free self-teacher to shape token-level advantages via bidirectional local advantage sign reversal (teacher-negative tokens in correct trajectories receive negative advantages; teacher-positive in incorrect receive bounded positive). This is motivated by observations that OPSD token preferences misalign with trajectory correctness and exhibit different noise on correct/incorrect rollouts, with special handling for zero-variance groups. The paper claims this yields improvements on mathematical reasoning tasks.
Significance. If the results hold, CAST would offer a lightweight extension to GRPO-style RLVR that adds dense token feedback without reference solutions or privileged context, addressing sparsity and zero-gradient issues while staying verifier-grounded. The explicit retention of the trajectory-level objective and the stop-gradient self-teacher are strengths that keep the method simple and falsifiable.
major comments (1)
- [Abstract] Abstract: The diagnostics showing OPSD signal misalignment (different behavior of teacher-positive vs. teacher-negative gaps on correct vs. incorrect rollouts) are explicitly stated to have been conducted under an OPSD-style privileged teacher context for analysis only. CAST training instead uses an answer-free self-teacher, so the claimed benefit of bidirectional local advantage sign reversal in producing advantages more aligned with verifier correctness has not been verified in the non-privileged regime actually used at training time. This is load-bearing for the central mechanism.
minor comments (1)
- [Abstract] Abstract: The claim that 'experiments on mathematical reasoning show that CAST improves RLVR training' is made without any reported numbers, baselines, ablation details, or error bars, which limits assessment of effect size even at the summary level.
Simulated Author's Rebuttal
We thank the referee for highlighting this important distinction regarding the verification of the central mechanism. We address the comment directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The diagnostics showing OPSD signal misalignment (different behavior of teacher-positive vs. teacher-negative gaps on correct vs. incorrect rollouts) are explicitly stated to have been conducted under an OPSD-style privileged teacher context for analysis only. CAST training instead uses an answer-free self-teacher, so the claimed benefit of bidirectional local advantage sign reversal in producing advantages more aligned with verifier correctness has not been verified in the non-privileged regime actually used at training time. This is load-bearing for the central mechanism.
Authors: We agree that the misalignment diagnostics were performed exclusively under the privileged OPSD-style teacher (as stated in the abstract) and that identical token-gap diagnostics cannot be run under the answer-free self-teacher used at training time. The bidirectional sign reversal is motivated by those privileged observations but is applied at training time using only verifier correctness to determine the target sign for each token advantage, with the self-teacher providing the magnitude. While we have not directly measured alignment of the resulting advantages with verifier correctness in the non-privileged regime, the end-to-end gains on mathematical reasoning benchmarks provide indirect support for the mechanism. We will revise the abstract and method section to clarify that the alignment benefit is inferred from performance rather than from a direct non-privileged diagnostic, and we will add a short discussion of this limitation. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's derivation proceeds from empirical diagnostics (under privileged-teacher context) to motivation for a new non-privileged self-teacher mechanism with advantage flipping, then to experimental claims of improvement on math reasoning tasks. No step reduces by construction to its own inputs: there are no self-definitional equations, no fitted parameters relabeled as predictions, no load-bearing self-citations, and no ansatz or uniqueness imported from prior author work. The method introduces explicit new components (stop-gradient answer-free teacher, bidirectional sign reversal, bounded base advantages for zero-variance groups) whose behavior is evaluated externally via verifier-grounded outcomes rather than tautologically.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-Policy Distillation of Language Models: Learning from Self-Generated Mis- takes
Rishabh Agarwal et al. “On-Policy Distillation of Language Models: Learning from Self-Generated Mis- takes”. In:International Conference on Learning Representations. Ed. by B. Kim et al. V ol. 2024. 2024, pp. 21246–21263.URL: https : / / proceedings . iclr . cc / paper _ files / paper / 2024 / file / 5be69a584901a26c521c2b51e40a4c20-Paper-Conference.pdf
2024
- [2]
-
[3]
Karl Cobbe et al.Training Verifiers to Solve Math Word Problems. 2021. arXiv:2110.14168 [cs.LG].URL: https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
DeepSeek-AI et al.DeepSeek-V3 Technical Report. 2025. arXiv: 2412.19437 [cs.CL].URL: https://arxiv. org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
Caglar Gulcehre et al.Reinforced Self-Training (ReST) for Language Modeling. 2023. arXiv: 2308.08998 [cs.CL].URL:https://arxiv.org/abs/2308.08998
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
doi: 10.1038/s41586-025-09422-z
Daya Guo et al. “DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning”. In:Nature 645.8081 (2025), pp. 633–638.ISSN: 1476-4687.DOI: 10 . 1038 / s41586 - 025 - 09422 - z.URL: http : //dx.doi.org/10.1038/s41586-025-09422-z
-
[8]
Dan Hendrycks et al.Measuring Mathematical Problem Solving With the MATH Dataset. 2021. arXiv: 2103. 03874 [cs.LG].URL:https://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu et al.LoRA: Low-Rank Adaptation of Large Language Models. 2021. arXiv:2106.09685 [cs.CL]. URL:https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Jonas Hübotter et al.Reinforcement Learning via Self-Distillation. 2026. arXiv: 2601.20802 [cs.LG].URL: https://arxiv.org/abs/2601.20802
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
OPSD Compresses What RLVR Teaches: A Post-RL Compaction Stage for Reasoning Models
Jaehoon Kim and Dongha Lee. “OPSD Compresses What RLVR Teaches: A Post-RL Compaction Stage for Reasoning Models”. In:arXiv preprint arXiv:2605.06188(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Jeonghye Kim et al.Rebellious Student: Reversing Teacher Signals for Reasoning Exploration with Self-Distilled RLVR. 2026. arXiv:2605.10781 [cs.LG].URL:https://arxiv.org/abs/2605.10781
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Thanh-Long V . Le et al.No Prompt Left Behind: Exploiting Zero-Variance Prompts in LLM Reinforcement Learning via Entropy-Guided Advantage Shaping. 2026. arXiv: 2509.21880 [cs.CL].URL: https://arxiv. org/abs/2509.21880
-
[14]
Aitor Lewkowycz et al.Solving Quantitative Reasoning Problems with Language Models. 2022. arXiv: 2206. 14858 [cs.CL].URL:https://arxiv.org/abs/2206.14858
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Hunter Lightman et al.Let’s Verify Step by Step. 2023. arXiv: 2305.20050 [cs.LG].URL: https://arxiv. org/abs/2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [16]
-
[17]
https://thinkingmachines.ai/blog/on-policy-distillation
Kevin Lu and Thinking Machines Lab. “On-Policy Distillation”. In:Thinking Machines Lab: Connectionism (2025). https://thinkingmachines.ai/blog/on-policy-distillation.DOI:10.64434/tml.20251026
-
[18]
Haipeng Luo et al.WizardMath: Empowering Mathematical Reasoning for Large Language Models via Rein- forced Evol-Instruct. 2023. arXiv:2308.09583 [cs.CL].URL:https://arxiv.org/abs/2308.09583
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
John Schulman et al.Proximal Policy Optimization Algorithms. 2017. arXiv: 1707.06347 [cs.LG] .URL: https://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Zhihong Shao et al.DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
-
[21]
arXiv:2402.03300 [cs.CL].URL:https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv
- [22]
-
[23]
Kimi Team et al.Kimi-VL Technical Report. 2025. arXiv: 2504.07491 [cs.CV].URL: https://arxiv.org/ abs/2504.07491
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Jonathan Uesato et al.Solving Math Word Problems with Process- and Outcome-based Feedback. 2022. arXiv: 2211.14275 [cs.LG].URL:https://arxiv.org/abs/2211.14275
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Xuezhi Wang et al.Self-Consistency Improves Chain of Thought Reasoning in Language Models. 2022. arXiv: 2203.11171 [cs.CL].URL:https://arxiv.org/abs/2203.11171. 11
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Yubo Wang et al.MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
-
[27]
arXiv:2406.01574 [cs.CL].URL:https://arxiv.org/abs/2406.01574
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Jason Wei et al.Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. 2022. arXiv: 2201.11903 [cs.CL].URL:https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [29]
-
[30]
An Yang et al.Qwen3 Technical Report. 2025. arXiv: 2505.09388 [cs.CL] .URL: https://arxiv.org/ abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Chenxu Yang et al.Self-Distilled RLVR. 2026. arXiv: 2604.03128 [cs.LG].URL: https://arxiv.org/abs/ 2604.03128
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Qiying Yu et al.DAPO: An Open-Source LLM Reinforcement Learning System at Scale. 2025. arXiv: 2503. 14476 [cs.LG].URL:https://arxiv.org/abs/2503.14476
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [33]
-
[34]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao et al.Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models. 2026. arXiv: 2601.18734 [cs.LG].URL:https://arxiv.org/abs/2601.18734. 12 8 Appendix Algorithm 1CAST: Non-Privileged Clipped Asymmetric Self-Teaching with Advantage Flipping for GRPO Require: Online policy πθ, rollout/reference policy πθold, stop-gradient self-...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.