Sympatheia: Emotionally Adaptive Voice Assistant with Continuous Affect Conditioning
Pith reviewed 2026-06-28 17:54 UTC · model grok-4.3
The pith
Sympatheia conditions voice assistant responses on continuous valence-arousal signals to ensure emotional appropriateness even with weak speech cues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
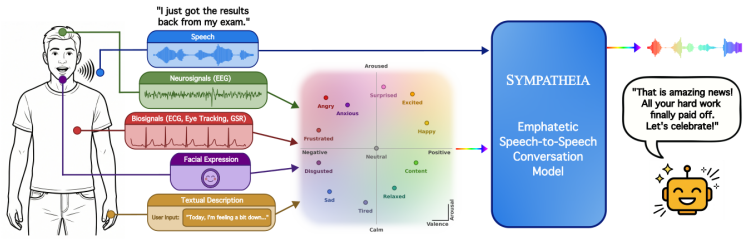
Sympatheia is a speech-to-speech dialogue framework conditioned on affect from the user's speech and, when available, an explicit continuous valence-arousal control signal. It is trained on the Sympatheia-18k corpus featuring 12 emotion anchors with emotional and neutral splits. The system generates responses whose semantic content and spoken delivery are emotionally appropriate, outperforming speech conversational baselines, and integrates emotion estimates from facial expression, biosignals, and textual descriptions to improve alignment when speech is limited.
What carries the argument
The continuous valence-arousal (VA) control signal used to condition the speech generation for emotional adaptation.
If this is right
- The generated responses align emotionally in both semantics and acoustics.
- Multimodal inputs enhance performance when speech affect is ambiguous.
- The VA interface allows flexible integration of different emotion sensing modules.
- Neutral query splits isolate the effect of explicit control on response choice.
Where Pith is reading between the lines
- Direct user specification of desired emotional tone could become a standard control in voice interfaces.
- The approach may extend naturally to text or visual output generation for consistent affect across modalities.
Load-bearing premise
Synthetic data from the 18k corpus transfers its emotional and acoustic properties to real-world user speech for effective conditioning.
What would settle it
A direct comparison of human ratings for emotional fit on outputs from the conditioned model versus baselines when tested on real ambiguous speech recordings.
Figures



read the original abstract
Empathetic spoken dialogue systems must infer a user's emotional state to respond appropriately, yet everyday speech often carries weak, neutral, or ambiguous affective cues. To address this, we introduce Sympatheia, a speech-to-speech dialogue framework conditioned on affect inferred from the user's speech and, when available, explicit affect specifications provided as a continuous valence--arousal (VA) control signal by a multimodal sensing module or user interface. To train our model, we construct Sympatheia-18k, an emotion-conditioned synthetic spoken dialogue corpus with 12 emotion anchors. This dataset includes an emotional split for learning affective speech behavior, and a neutral split that pairs emotionally neutral queries with multiple emotion-conditioned responses to isolate explicit emotion control in emotionally ambiguous cases. Empirical results show that Sympatheia outperforms speech conversational baselines in generating responses whose semantic content and spoken delivery are both emotionally appropriate. We further show that the same VA interface can integrate emotion estimates from diverse sensing modules, including facial expression, biosignals, and textual affect descriptions, improving response alignment when speech alone provides limited emotional evidence. These results suggest that continuous affect conditioning is an effective practical step for building emotionally adaptive voice assistants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sympatheia, a speech-to-speech dialogue framework conditioned on continuous valence-arousal (VA) affect signals inferred from user speech and, when available, explicit multimodal or UI-provided VA controls. It constructs the Sympatheia-18k synthetic corpus using 12 emotion anchors, with an emotional split for affective behavior and a neutral split pairing neutral queries with multiple emotion-conditioned responses. The central empirical claim is that the resulting model outperforms speech conversational baselines in producing responses that are emotionally appropriate in both semantic content and spoken delivery, and that the VA interface enables effective integration of emotion estimates from facial, biosignal, and textual sources to improve alignment when speech cues are weak or ambiguous.
Significance. If the generalization claims hold, the work offers a concrete, practical mechanism for explicit continuous affect control in voice assistants via synthetic data with designed splits, which could address a common limitation in empathetic dialogue systems. The multimodal VA integration is a clear strength for real-world deployment where speech alone is often insufficient. The synthetic corpus approach with neutral/emotional splits is a methodological contribution worth noting if accompanied by evidence of transfer.
major comments (2)
- [Empirical evaluation / results] The central empirical claim (abstract and results) that Sympatheia outperforms baselines in generating emotionally appropriate responses rests on evaluation using held-out portions of the synthetic Sympatheia-18k corpus. No cross-domain evaluation on real user speech is described, leaving the practical claim for voice-assistant scenarios where speech is ambiguous unsupported.
- [Dataset construction] Dataset section: The Sympatheia-18k corpus is generated with 12 emotion anchors and TTS-based synthesis for the emotional/neutral splits. The manuscript provides no analysis or ablation addressing potential systematic differences in prosody, timbre, or affect intensity between the synthetic data and natural speech, which directly affects whether the learned continuous VA conditioning transfers to the target use case.
minor comments (1)
- [Abstract] The abstract states outperformance without naming the specific metrics (e.g., semantic similarity, prosody measures, or human ratings) or the exact baselines; adding these would improve clarity even if full details appear later.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Empirical evaluation / results] The central empirical claim (abstract and results) that Sympatheia outperforms baselines in generating emotionally appropriate responses rests on evaluation using held-out portions of the synthetic Sympatheia-18k corpus. No cross-domain evaluation on real user speech is described, leaving the practical claim for voice-assistant scenarios where speech is ambiguous unsupported.
Authors: We agree that the reported results are obtained on held-out portions of the synthetic corpus. This evaluation was chosen to isolate the effects of the emotional and neutral splits under controlled conditions. We acknowledge that this leaves the generalization to real user speech untested and weakens the practical claims for ambiguous voice-assistant scenarios. We will revise the manuscript by adding a limitations subsection that explicitly qualifies the empirical claims and outlines the need for future cross-domain validation on natural speech data. revision: yes
-
Referee: [Dataset construction] Dataset section: The Sympatheia-18k corpus is generated with 12 emotion anchors and TTS-based synthesis for the emotional/neutral splits. The manuscript provides no analysis or ablation addressing potential systematic differences in prosody, timbre, or affect intensity between the synthetic data and natural speech, which directly affects whether the learned continuous VA conditioning transfers to the target use case.
Authors: The referee is correct that the manuscript contains no ablation or quantitative comparison of prosody, timbre, or affect intensity between the TTS-generated data and natural speech. Our dataset design emphasizes controllability via the 12 anchors and the neutral/emotional split structure. We will revise the dataset section to include a short discussion of known TTS-to-natural domain gaps, supported by references to prior work on synthetic speech transfer, and will add an explicit statement that transfer of the VA conditioning remains to be verified on natural recordings. revision: yes
Circularity Check
No circularity; empirical ML system paper with no derivation chain
full rationale
The manuscript describes construction of a synthetic corpus (Sympatheia-18k with 12 emotion anchors and neutral/emotional splits), training of a speech-to-speech model conditioned on continuous valence-arousal, and empirical evaluation against baselines. No equations, first-principles derivations, or mathematical predictions appear in the provided text. Central claims rest on measured outperformance and multimodal integration rather than any reduction of a 'prediction' to fitted inputs or self-citation chains. No self-definitional, fitted-input, or uniqueness-theorem patterns are present. This is a standard empirical systems contribution whose validity hinges on data transfer assumptions, not circular logic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, 2020
2020
-
[2]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, 2022
2022
-
[3]
Towards empathetic open-domain conversation models: A new benchmark and dataset
Hannah Rashkin, Eric Michael Smith, Margaret Li, and Y-Lan Boureau. Towards empathetic open-domain conversation models: A new benchmark and dataset. InProceedings of ACL, 2019
2019
-
[4]
Klaus R. Scherer. V ocal communication of emotion: A review of research paradigms.Speech Communication, 40(1–2):227–256, 2003
2003
-
[5]
Roisman, and Thomas S
Zhihong Zeng, Maja Pantic, Glenn I. Roisman, and Thomas S. Huang. A survey of affect recognition methods: Audio, visual, and spontaneous expressions.IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(1):39–58, 2009
2009
-
[6]
James A. Russell. A circumplex model of affect.Journal of Personality and Social Psychology, 39(6):1161–1178, 1980
1980
-
[7]
Chang, Sungbok Lee, and Shrikanth S
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N. Chang, Sungbok Lee, and Shrikanth S. Narayanan. IEMOCAP: Interactive emotional dyadic motion capture database.Language Resources and Evaluation, 42(4):335– 359, 2008
2008
-
[8]
MELD: A multimodal multi-party dataset for emotion recognition in conversa- tions
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. MELD: A multimodal multi-party dataset for emotion recognition in conversa- tions. InProceedings of ACL, 2019
2019
-
[9]
MoEL: Mixture of empathetic listeners
Zhaojiang Lin, Andrea Madotto, Jamin Shin, Peng Xu, and Pascale Fung. MoEL: Mixture of empathetic listeners. InProceedings of EMNLP-IJCNLP, 2019
2019
-
[10]
MIME: MIMicking emotions for empathetic response generation
Navonil Majumder, Pengfei Hong, Shanshan Peng, Jiankun Lu, Deepanway Ghosal, Alexander Gelbukh, Rada Mihalcea, and Soujanya Poria. MIME: MIMicking emotions for empathetic response generation. InProceedings of EMNLP, 2020
2020
-
[11]
Reza Lotfian and Carlos Busso. Building naturalistic emotionally balanced speech corpus by retrieving emotional speech from existing podcast recordings.IEEE Transactions on Affective Computing, 10(4):471–483, 2019. doi: 10.1109/TAFFC.2017.2736999. 10
-
[12]
Carlos Busso, Reza Lotfian, Kusha Sridhar, Ali N. Salman, Wei-Cheng Lin, Lucas Goncalves, Srinivas Parthasarathy, Abinay Reddy Naini, Seong-Gyun Leem, Luz Martinez-Lucas, Huang- Cheng Chou, and Pravin Mote. The MSP-Podcast corpus.arXiv preprint arXiv:2509.09791, 2025
-
[13]
Ali Mollahosseini, Behzad Hasani, and Mohammad H. Mahoor. AffectNet: A database for facial expression, valence, and arousal computing in the wild.IEEE Transactions on Affective Computing, 10(1):18–31, 2019
2019
-
[14]
DEAP: A database for emotion analysis using physiological signals.IEEE Transactions on Affective Computing, 3(1): 18–31, 2012
Sander Koelstra, Christian Mühl, Mohammad Soleymani, Jong-Seok Lee, Ashkan Yazdani, Touradj Ebrahimi, Thierry Pun, Anton Nijholt, and Ioannis Patras. DEAP: A database for emotion analysis using physiological signals.IEEE Transactions on Affective Computing, 3(1): 18–31, 2012
2012
-
[15]
SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities,
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities.arXiv preprint arXiv:2305.11000, 2023
-
[16]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: A speech-text foundation model for real-time dialogue.arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
Aohan Zeng, Zhengxiao Du, Mingdao Liu, Kedong Wang, Shengmin Jiang, Lei Zhao, Yuxiao Dong, and Jie Tang. GLM-4-V oice: Towards intelligent and human-like end-to-end spoken chatbot.arXiv preprint arXiv:2412.02612, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, et al. Qwen3-Omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
KimiTeam, Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, et al. Kimi-Audio technical report.arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
BLSP-Emo: Towards empathetic large speech-language models
Chen Wang, Minpeng Liao, Zhongqiang Huang, Junhong Wu, Chengqing Zong, and Jiajun Zhang. BLSP-Emo: Towards empathetic large speech-language models. InProceedings of EMNLP, 2024
2024
-
[21]
Chen Wang, Tianyu Peng, Wen Yang, Yinan Bai, Guangfu Wang, Jun Lin, Lanpeng Jia, Lingxi- ang Wu, Jinqiao Wang, Chengqing Zong, and Jiajun Zhang. OpenS2S: Advancing fully open- source end-to-end empathetic large speech language model.arXiv preprint arXiv:2507.05177, 2025
-
[22]
Haoyu Wang, Guangyan Zhang, Jiale Chen, Jingyu Li, Yuehai Wang, and Yiwen Guo. Empathy Omni: Enabling empathetic speech response generation through large language models.arXiv preprint arXiv:2508.18655, 2025
-
[23]
Xuelong Geng, Qijie Shao, Hongfei Xue, Shuiyuan Wang, Hanke Xie, Zhao Guo, Yi Zhao, Guojian Li, Wenjie Tian, Chengyou Wang, Zhixian Zhao, Kangxiang Xia, Ziyu Zhang, Zhennan Lin, Tianlun Zuo, Mingchen Shao, Yuang Cao, Guobin Ma, Longhao Li, Yuhang Dai, Dehui Gao, Dake Guo, and Lei Xie. OSUM-EChat: Enhancing end-to-end empathetic spoken chatbot via understa...
-
[24]
Robust Speech Recognition via Large-Scale Weak Supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision.arXiv preprint arXiv:2212.04356, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In Proceedings of ICLR, 2022. 11
2022
-
[26]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, et al. Qwen3-TTS technical report.arXiv preprint arXiv:2601.15621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Savchenko
Andrey V . Savchenko. HSEmotion: High-speed emotion recognition library.Software Impacts, 14:100433, 2022
2022
-
[29]
SEED-VII: A multimodal dataset of six basic emotions with continuous labels for emotion recognition.IEEE Transactions on Affective Computing, 16(2):969–985, 2025
Wei-Bang Jiang, Xuan-Hao Liu, Wei-Long Zheng, and Bao-Liang Lu. SEED-VII: A multimodal dataset of six basic emotions with continuous labels for emotion recognition.IEEE Transactions on Affective Computing, 16(2):969–985, 2025
2025
-
[30]
YAAD: Young adult’s affective data using wearable ECG and GSR sensors
Muhammad Najam Dar, Amna Rahim, Muhammad Usman Akram, Sajid Gul Khawaja, and Aqsa Rahim. YAAD: Young adult’s affective data using wearable ECG and GSR sensors. In2022 2nd International Conference on Digital Futures and Transformative Technologies (ICoDT2), pages 1–7. IEEE, 2022
2022
-
[31]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of CVPR, 2016
2016
-
[32]
Scherer and Harald G
Klaus R. Scherer and Harald G. Wallbott. Evidence for universality and cultural variation of differential emotion response patterning.Journal of Personality and Social Psychology, 66(2): 310–328, 1994
1994
-
[33]
Emotion English DistilRoBERTa-base
Jochen Hartmann. Emotion English DistilRoBERTa-base. https://huggingface.co/ j-hartmann/emotion-english-distilroberta-base/, 2022
2022
-
[34]
URO-Bench: Towards comprehensive evaluation for end-to-end spoken dialogue models
Ruiqi Yan, Xiquan Li, Wenxi Chen, Zhikang Niu, Chen Yang, Ziyang Ma, Kai Yu, and Xie Chen. URO-Bench: Towards comprehensive evaluation for end-to-end spoken dialogue models. InFindings of the Association for Computational Linguistics: EMNLP, 2025
2025
-
[35]
VoiceBench: Benchmarking LLM-Based Voice Assistants
Yiming Chen, Xianghu Yue, Chen Zhang, Xiaoxue Gao, Robby T. Tan, and Haizhou Li. V oiceBench: Benchmarking LLM-based voice assistants.arXiv preprint arXiv:2410.17196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Stefan Palan and Christian Schitter. Prolific.ac–a subject pool for online experiments.Journal of Behavioral and Experimental Finance, 17:22–27, 2018. doi: 10.1016/j.jbef.2017.12.004
-
[37]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. BERTScore: Evaluating text generation with BERT. InProceedings of ICLR, 2020
2020
-
[38]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summariza- tion Branches Out, pages 74–81, 2004
2004
-
[39]
Zhifei Xie and Changqiao Wu. Mini-Omni: Language models can hear, talk while thinking in streaming.arXiv preprint arXiv:2408.16725, 2024
-
[40]
UTMOS: UTokyo-SaruLab system for V oiceMOS challenge 2022
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. UTMOS: UTokyo-SaruLab system for V oiceMOS challenge 2022. In Proceedings of Interspeech, pages 4521–4525, 2022
2022
-
[41]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProceedings of ICLR, 2019
2019
-
[42]
DeepSpeed: System optimizations enable training deep learning models with over 100 billion parameters
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. DeepSpeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of KDD, 2020
2020
-
[43]
A dictionary of affect in language: I
Kevin Sweeney and Cynthia Whissell. A dictionary of affect in language: I. establishment and preliminary validation.Perceptual and Motor Skills, 59(3):695–698, 1984. doi: 10.2466/pms. 1984.59.3.695. 12
work page doi:10.2466/pms 1984
-
[44]
Harper & Row, New York, 1980
Robert Plutchik.Emotion: A Psychoevolutionary Synthesis. Harper & Row, New York, 1980
1980
-
[45]
Roddy Cowie, Ellen Douglas-Cowie, Nicolas Tsapatsoulis, George V otsis, Stefanos Kollias, Winfried Fellenz, and John G. Taylor. Emotion recognition in human-computer interaction. IEEE Signal Processing Magazine, 18(1):32–80, 2001. doi: 10.1109/79.911197
-
[46]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 3982–3992, 2019. doi: 10.18653/v1/D19-1410
-
[47]
MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. InAdvances in Neural Information Processing Systems, volume 33, pages 5776–5788, 2020
2020
-
[48]
Harris, K
Charles R. Harris, K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fer- nández del Río, Mark Wiebe, Pearu Peterson, Pierre Gérard-Marchant, Kevin She...
2020
-
[49]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-Omni technical report.arXiv preprint arXiv:2503.20215, 2025. A Societal Impact and Responsible Deployment SYMPATHEIAis intended to make spoken assistants more emotionally aware, supporti...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Acknowledges and addresses the user’s emotional state explicitly and warmly
-
[51]
Answers their actual question or addresses their request with real, useful content
-
[52]
Weaves the emotional support and the topic together
-
[53]
I don’t care how fancy this city looks on postcards — what’s the point of even trying to explore it if everything’s closed and no one knows where anything is?
A listener could tell WHAT EMOTION you’re responding to AND what the user asked about Output ONLY the response text -- no quotes, no explanation. B.7 Human Studies B.7.1 Emotion MOS Evaluation For the human evaluation study, we recruit 20 participants through Prolific [36] and compensate them at a competitive hourly rate. All recruited participants are na...
-
[54]
Hugging Face model-card terms; all- MiniLM-L6-v2 is Apache-2.0
and all-MiniLM- L6-v2 [46, 47] Text emotion classifier and query deduplication embed- dings. Hugging Face model-card terms; all- MiniLM-L6-v2 is Apache-2.0. UTMOS [ 40], BERTScore [ 37], ROUGE-L [38], LoRA [25], and DeepSpeed [42] Evaluation metrics and train- ing infrastructure. UTMOS and BERTScore are MIT Li- cense; ROUGE-score, LoRA/PEFT, and DeepSpeed...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.