Inference-Time Scaling for Joint Audio-Video Generation
Pith reviewed 2026-06-28 07:47 UTC · model grok-4.3
The pith
A multi-verifier framework plus adaptive reward weighting enables effective inference-time scaling for joint audio-video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that inference-time scaling for joint audio-video generation requires a multi-verifier setup to avoid asymmetric trade-offs and verifier hacking, and that Adaptive Reward Weighting aggregates the resulting signals by treating reward balancing as an online optimization problem with learnable parameters that calibrate variances without prior distributional knowledge.
What carries the argument
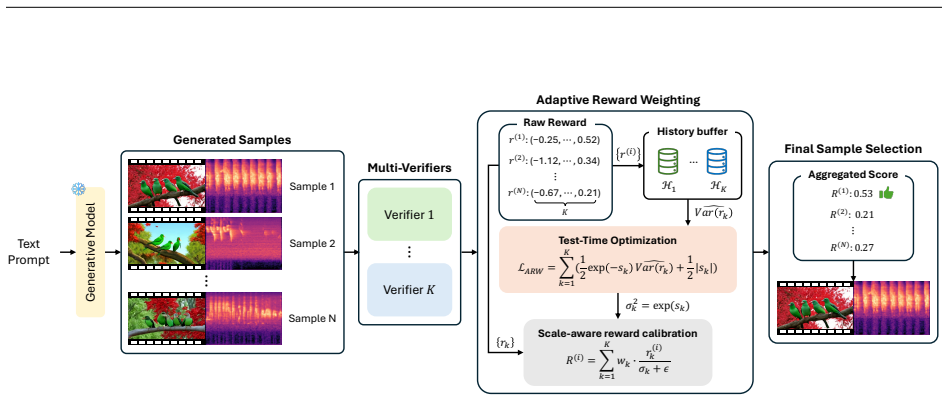
Adaptive Reward Weighting (ARW), a test-time algorithm that performs online optimization over learnable parameters to calibrate and combine multiple reward signals during generation.
If this is right
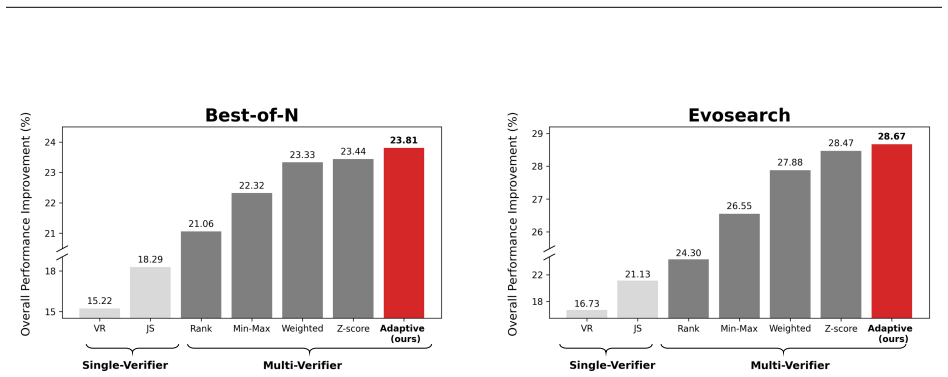
- The chosen multi-verifier combination produces balanced gains across semantic alignment, perceptual quality, and audio-visual synchronization.
- Adaptive Reward Weighting aggregates heterogeneous rewards without needing advance knowledge of their distributions.
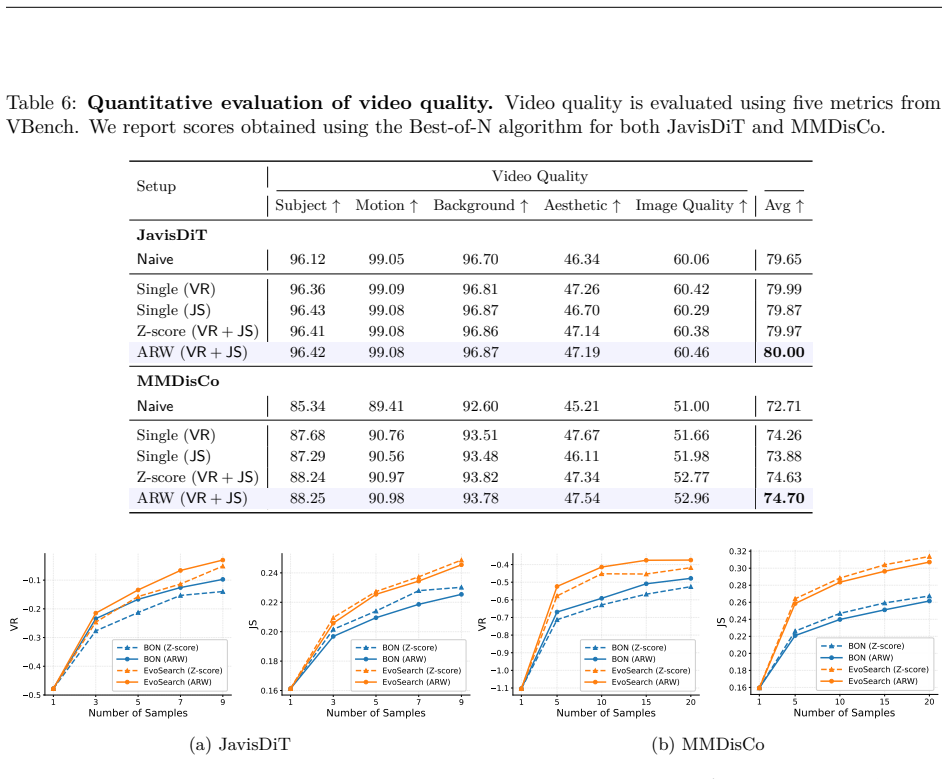
- The resulting outputs improve on VGGSound and JavisBench-mini relative to prior joint generation baselines.
- All improvements occur at inference time without additional model training.
Where Pith is reading between the lines
- The same multi-verifier structure could be tested on other pairs of modalities whose quality metrics conflict during generation.
- If ARW's learnable parameters converge reliably, the method may reduce the need for hand-tuned reward weights in future multimodal systems.
- The approach implies that test-time compute can substitute for some of the training compute currently spent on multimodal alignment.
Load-bearing premise
Single-objective guidance necessarily produces asymmetric performance trade-offs and verifier hacking, so multiple verifiers are required.
What would settle it
An experiment that applies single-verifier inference-time scaling to the same base model and benchmarks and measures equal or superior scores across semantic alignment, perceptual quality, and synchronization would falsify the necessity of the multi-verifier approach.
Figures










read the original abstract
Joint audio-video generation aims to synthesize realistic audio-video pairs that are both semantically aligned with text prompts and precisely synchronized. While existing joint audio-video generation models often require substantial training resources to improve fidelity, Inference-Time Scaling (ITS) has recently emerged as a promising training-free alternative in single-modality domains. However, extending ITS from a single modality to multimodal domains is non-trivial, as it requires balancing multiple heterogeneous objectives. In this paper, we present the first comprehensive study of ITS for joint audio-video generation. We first demonstrate that a multi-verifier framework is essential to address the limitations of single-objective guidance, including asymmetric performance trade-offs and verifier hacking. Through systematic analysis, we then identify an optimal multi-verifier combination that yields balanced improvements across all quality dimensions. Finally, to effectively aggregate diverse reward signals, we propose Adaptive Reward Weighting (ARW), a novel test-time optimization algorithm. ARW treats reward aggregation as an online optimization problem, utilizing learnable parameters to calibrate reward variances without requiring prior knowledge of reward distributions, thereby ensuring robust multi-objective selection. Experimental results on VGGSound and JavisBench-mini benchmarks demonstrate that our framework significantly enhances semantic alignment, perceptual quality, and audio-visual synchronization of generated outputs. Synthesized samples and code are available on the project page: https://jung-jaemin.github.io/ITS-AVGen-Proj.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts the first comprehensive study of Inference-Time Scaling (ITS) for joint audio-video generation. It argues that single-objective guidance leads to asymmetric performance trade-offs and verifier hacking, necessitating a multi-verifier framework. An optimal verifier combination is identified through systematic analysis, and Adaptive Reward Weighting (ARW) is introduced as a test-time optimization algorithm that treats reward aggregation as an online problem with learnable parameters to calibrate variances without prior distribution knowledge. Experiments on VGGSound and JavisBench-mini are claimed to show significant gains in semantic alignment, perceptual quality, and audio-visual synchronization.
Significance. If substantiated, this would represent a notable advance by extending training-free ITS methods to the multimodal AV domain, where balancing heterogeneous objectives is challenging. The ARW approach is a distinct contribution for distribution-agnostic reward aggregation via online learning. The release of code and samples supports reproducibility and allows direct verification of the framework.
major comments (2)
- [Abstract] Abstract: The central claim that 'our framework significantly enhances semantic alignment, perceptual quality, and audio-visual synchronization of generated outputs' is asserted without any quantitative results, metric values, baseline comparisons, ablation details, or error analysis. This directly undermines evaluation of whether the data support the empirical conclusions.
- [Abstract] Abstract: The assertion that 'a multi-verifier framework is essential' due to asymmetric trade-offs and verifier hacking is presented as demonstrated, but the systematic analysis, specific evidence, or data showing these limitations (and the optimality of the chosen combination) are not provided in the text.
minor comments (1)
- [Abstract] Abstract: The project page is referenced but without enumeration of available assets (e.g., specific generated samples, code release details, or benchmark subsets).
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We agree that the abstract can be strengthened by incorporating key quantitative highlights and brief references to supporting analysis from the body of the paper. We will revise the abstract accordingly while preserving its summary nature. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'our framework significantly enhances semantic alignment, perceptual quality, and audio-visual synchronization of generated outputs' is asserted without any quantitative results, metric values, baseline comparisons, ablation details, or error analysis. This directly undermines evaluation of whether the data support the empirical conclusions.
Authors: We acknowledge that the abstract presents high-level claims without specific numbers. The full manuscript provides these details in Section 4 (Experiments), including tables with metric values (e.g., improvements in semantic alignment, perceptual quality, and AV synchronization on VGGSound and JavisBench-mini), baseline comparisons, and ablations. To address the concern, we will revise the abstract to include concise quantitative highlights from the main results. revision_made: yes revision: yes
-
Referee: [Abstract] Abstract: The assertion that 'a multi-verifier framework is essential' due to asymmetric trade-offs and verifier hacking is presented as demonstrated, but the systematic analysis, specific evidence, or data showing these limitations (and the optimality of the chosen combination) are not provided in the text.
Authors: The abstract summarizes our finding that a multi-verifier framework is essential. The systematic analysis demonstrating asymmetric trade-offs, verifier hacking, and the optimal combination is presented in Section 3, supported by figures and tables. We will revise the abstract to briefly note the key evidence from this analysis (e.g., reference to observed trade-offs). revision_made: yes revision: yes
Circularity Check
No significant circularity; empirical framework validated by benchmarks
full rationale
The paper presents an empirical study of inference-time scaling for joint audio-video generation. It demonstrates limitations of single-objective guidance via analysis, identifies an optimal multi-verifier combination, and proposes ARW as a test-time optimization method using learnable parameters. All central claims (improved semantic alignment, perceptual quality, and synchronization) are supported by experimental results on VGGSound and JavisBench-mini benchmarks rather than any derivation chain. No equations, fitted predictions, self-citations, or ansatzes are described that reduce the outputs to the paper's own inputs by construction. The argument is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable parameters in ARW
invented entities (1)
-
Adaptive Reward Weighting (ARW)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Haoran He, Jiajun Liang, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, and Ling Pan. Scaling image and video generation via test-time evolutionary search.arXiv preprint arXiv:2505.17618, 2025a. Xuan He, Dongfu Jiang, Ping Nie, Minghao Liu, Zhengxuan Jiang, Mingyi Su, Wentao Ma, Junru Lin, Chun Ye, Yi Lu, et al. Videoscore2: Think before you score in genera...
-
[4]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Inference-time scaling for diffusion-based audio super-resolution.arXiv preprint arXiv:2508.02391,
Yizhu Jin, Zhen Ye, Zeyue Tian, Haohe Liu, Qiuqiang Kong, Yike Guo, and Wei Xue. Inference-time scaling for diffusion-based audio super-resolution.arXiv preprint arXiv:2508.02391,
-
[6]
Voicedit: Dual-condition diffusion transformer for environment-aware speech synthesis
Jaemin Jung, Junseok Ahn, Chaeyoung Jung, Tan Dat Nguyen, Youngjoon Jang, and Joon Son Chung. Voicedit: Dual-condition diffusion transformer for environment-aware speech synthesis. InProc. ICASSP, 2025a. Jaemin Jung, Jaehun Kim, Inkyu Shin, and Joon Son Chung. Score: Scaling audio generation using stan- dardized composite rewards.arXiv preprint arXiv:2509...
-
[7]
Adam: A Method for Stochastic Optimization
Jaihoon Kim, Taehoon Yoon, Jisung Hwang, and Minhyuk Sung. Inference-time scaling for flow models via stochastic generation and rollover budget forcing. InProc. NeurIPS, 2025a. Sunwoo Kim, Minkyu Kim, and Dongmin Park. Test-time alignment of diffusion models without reward over-optimization. InProc. ICLR, 2025b. Diederik P Kingma and Jimmy Ba. Adam: A met...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Haohe Liu, Gael Le Lan, Xinhao Mei, Zhaoheng Ni, Anurag Kumar, Varun Nagaraja, Wenwu Wang, Mark D Plumbley, Yangyang Shi, and Vikas Chandra. Syncflow: Toward temporally aligned joint audio-video generation from text.arXiv preprint arXiv:2412.15220,
-
[9]
Improving Video Generation with Human Feedback
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Wenyu Qin, Menghan Xia, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025b. Kai Liu, Wei Li, Lai Chen, Shengqiong Wu, Yanhao Zheng, Jiayi Ji, Fan Zhou, Rongxin Jiang, Jiebo Luo, Hao Fei, et al. Javisdit: Joint audio-v...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
Yexiang Liu, Zekun Li, Zhi Fang, Nan Xu, Ran He, and Tieniu Tan. Rethinking the role of prompting strategies in llm test-time scaling: A perspective of probability theory. InProc. ACL, 2025c. Chetwin Low, Weimin Wang, and Calder Katyal. Ovi: Twin backbone cross-modal fusion for audio-video generation.arXiv preprint arXiv:2510.01284,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-YaoMa, Ching-YaoChuang, etal. Moviegen: Acastofmediafoundationmodels.arXiv preprint arXiv:2410.13720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Kai Wang, Shijian Deng, Jing Shi, Dimitrios Hatzinakos, and Yapeng Tian. Av-dit: Efficient audio-visual diffusion transformer for joint audio and video generation.arXiv preprint arXiv:2406.07686, 2024a. Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-la...
-
[13]
16 Lei Zhao, Linfeng Feng, Dongxu Ge, Rujin Chen, Fangqiu Yi, Chi Zhang, Xiao-Lei Zhang, and Xuelong Li. Uniform: A unified multi-task diffusion transformer for audio-video generation.arXiv preprint arXiv:2502.03897,
-
[14]
Transfusion: Predict the next token and diffuse images with one multi-modal model
Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. Transfusion: Predict the next token and diffuse images with one multi-modal model. InProc. ICLR, 2025a. Zikai Zhou, Shitong Shao, Lichen Bai, Shufei Zhang, Zhiqiang Xu, Bo Han, and Zeke Xie. Golden noise for diffus...
2023
-
[15]
Despite these advances in training strategies, the ability to adaptively refine generation at inference time without costly retraining remains underexplored
further prioritizes fine-grained spatio-temporal synchronization by injecting hierarchical priors directly into DiT blocks. Despite these advances in training strategies, the ability to adaptively refine generation at inference time without costly retraining remains underexplored. Inference-Time Scaling for Diffusion Models.Inspired by the success of Larg...
2025
-
[16]
For instance, the latent beam search (Oshima et al.,
or iteratively optimizing latent frequency components (Wu et al., 2024; Yuan et al., 2025); and (ii) search-based selection, which explores multiple candidates to identify the optimal output according to a specific scoring function. For instance, the latent beam search (Oshima et al.,
2024
-
[17]
maintains a set of promising latent candidates at each denoising step and prunes lower-quality paths to concentrate compute on high-reward trajectories. On the other hand, the evolutionary search (He et al., 2025a) reformulates the sampling process as an evolution- ary optimization problem, applying selection and mutation mechanisms to intermediate denois...
2018
-
[18]
Despite their effectiveness, these approaches require access to the model’s internal parameters and involve computationally heavy gradient calculations over a training dataset
dynamically weights loss functions during training based on task-specific uncertainty. Despite their effectiveness, these approaches require access to the model’s internal parameters and involve computationally heavy gradient calculations over a training dataset. In contrast, our proposed ARW introduces an inference-time paradigm that does not require upd...
2018
-
[19]
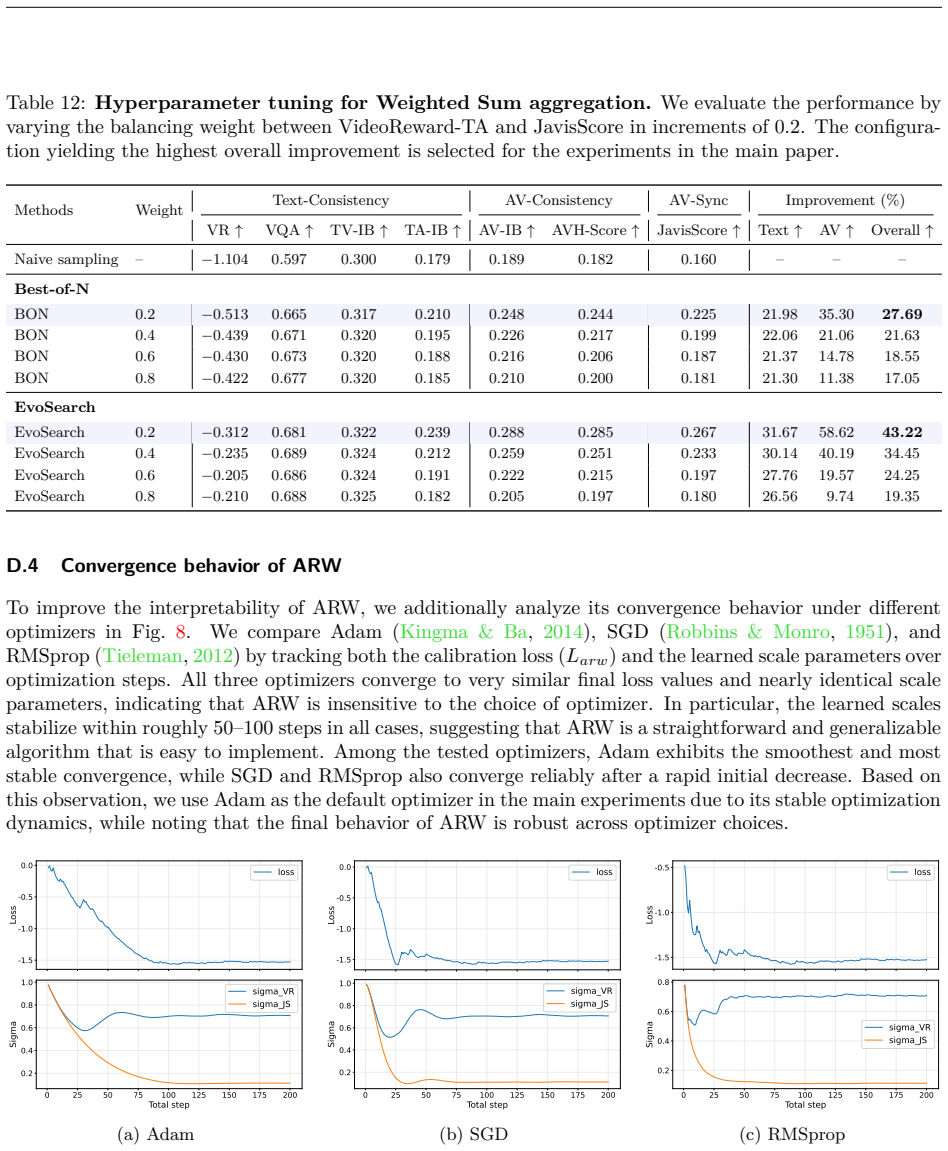
We compare Adam (Kingma & Ba, 2014), SGD (Robbins & Monro, 1951), and RMSprop (Tieleman,
2014
-
[20]
two pigeons
by tracking both the calibration loss (Larw) and the learned scale parameters over optimization steps. All three optimizers converge to very similar final loss values and nearly identical scale parameters, indicating that ARW is insensitive to the choice of optimizer. In particular, the learned scales stabilize within roughly 50–100 steps in all cases, su...
2026
-
[21]
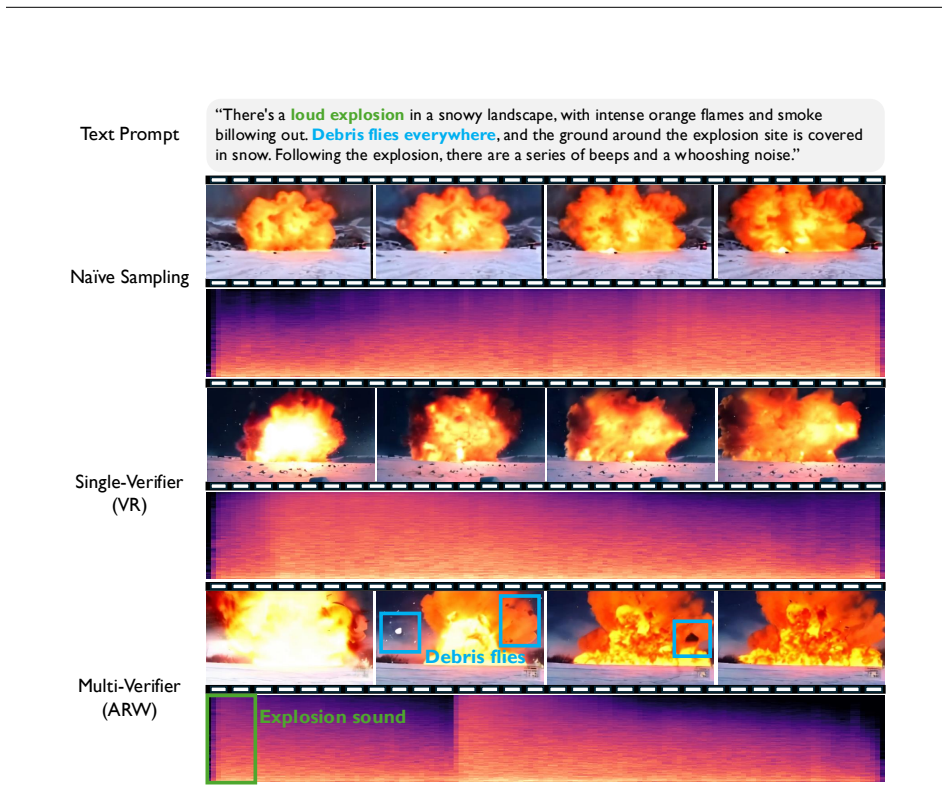
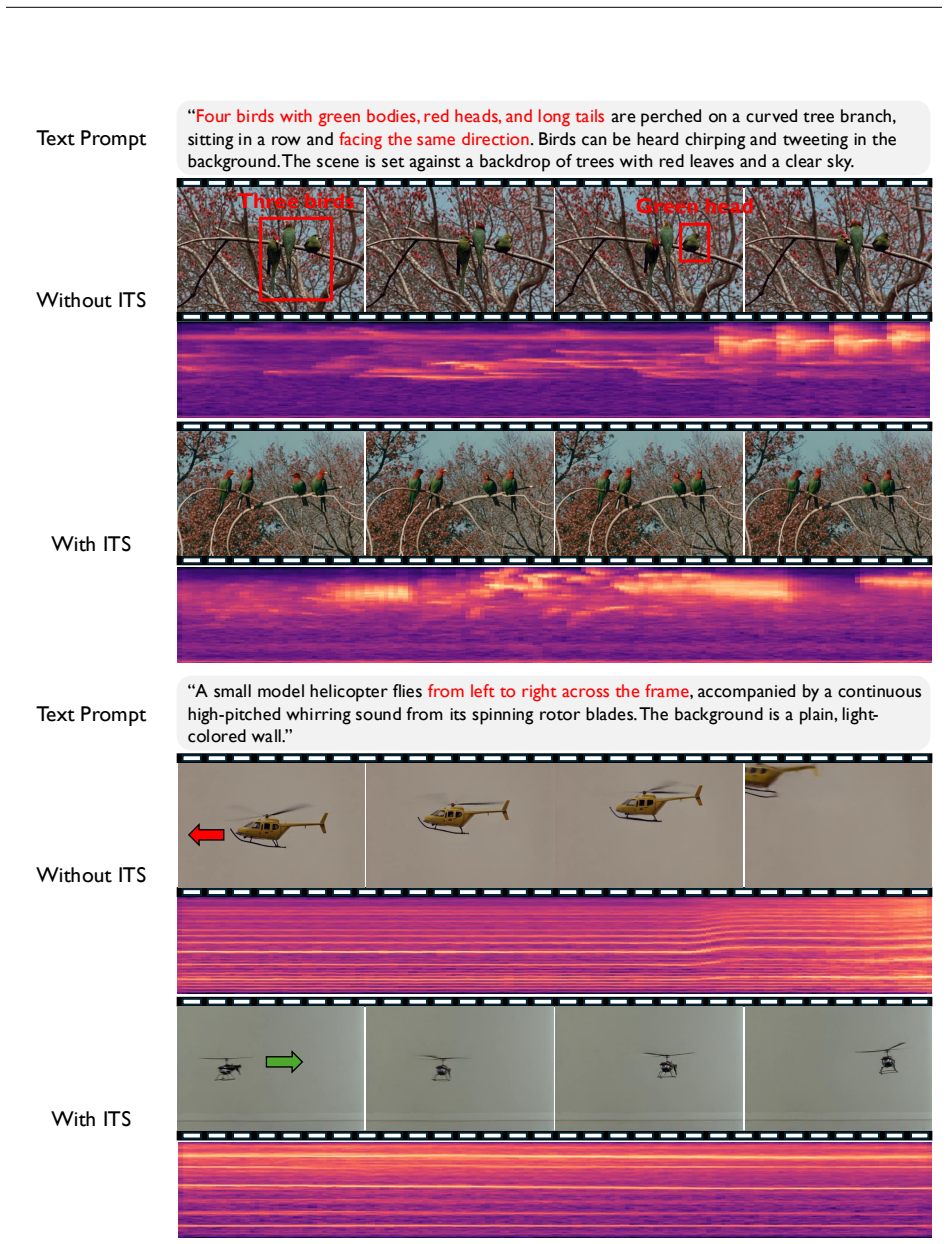
First,physical plausibility is still not guaranteed. In the upper example, ITS improves the overall prompt alignment by generating a hummingbird feeding from the feeder, but the bird’s wings still unrealistically pass through the feeder, indicating a violation of basic physics. Second,unstable temporal consistency remains an issue. In the lower example, n...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.