Validity Threats for Foundation Model Research
Pith reviewed 2026-06-28 06:50 UTC · model grok-4.3
The pith
Savings in compute for foundation model research come at the cost of validity threats that can invalidate claims.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Savings in compute come at the cost of validity threats—hidden and sometimes untestable assumptions that, when violated, can invalidate research claims. The evaluation framework casts foundation model research as a causal inference problem and evaluates different research strategies through four types of validity adapted from the empirical social sciences: statistical, internal, external, and construct validity. Proxy experiments trade external and construct validity for statistical and internal validity; observational studies face confounding and effect heterogeneity; and single-run designs are strained by interference between treated units. This analysis reveals several validity threats th
What carries the argument
An evaluation framework that treats foundation model research as a causal inference problem and assesses each research strategy through four validity types (statistical, internal, external, construct) imported from empirical social sciences.
If this is right
- Proxy experiments trade external and construct validity for statistical and internal validity.
- Observational studies face confounding and effect heterogeneity.
- Single-run designs are strained by interference between treated units.
- Several validity threats have received insufficient attention in the literature.
Where Pith is reading between the lines
- The framework could be used to score specific published papers and flag which validity threats remain unaddressed in each.
- Combining two approximation strategies might offset some weaknesses of each, though the paper does not test this possibility.
- Widespread adoption would likely shift publication incentives toward designs that explicitly document their validity profile.
Load-bearing premise
The four validity types imported from empirical social sciences can be applied to foundation-model research strategies without substantial redefinition or loss of diagnostic power.
What would settle it
A side-by-side test in which conclusions drawn from a proxy experiment or observational study on a foundation model are directly compared against results from a full controlled experiment on the identical question; systematic disagreement would support the claimed validity threats while consistent agreement would falsify them.
Figures
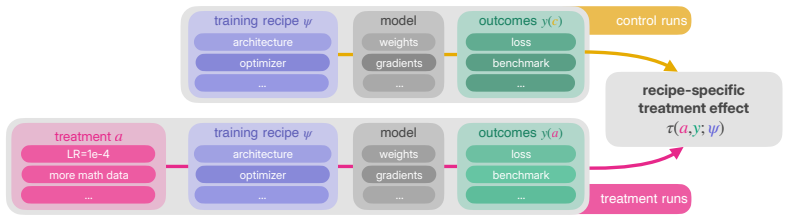
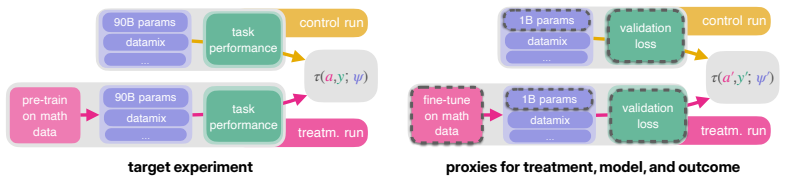

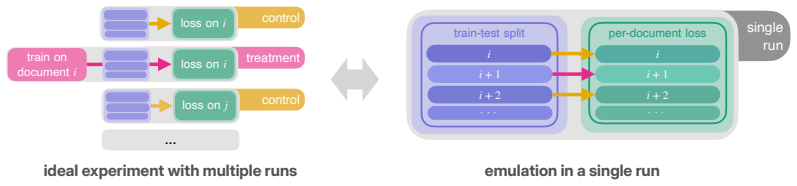

read the original abstract
Controlled experiments are the backbone of machine learning research, but at the scale of modern foundation models, they have become prohibitively expensive. Instead, the community increasingly relies on research strategies that approximate the ideal experiment at a fraction of the cost: proxy experiments and scaling laws, observational studies with publicly available models, and single-run designs that leverage variation within individual training runs. In this work, we argue that there is no free lunch when approximating large-scale experiments on a compute budget. Specifically, savings in compute come at the cost of validity threats -- hidden and sometimes untestable assumptions that, when violated, can invalidate research claims. To help navigate such threats, we propose an evaluation framework that casts foundation model research as a causal inference problem. Within this framework, we evaluate different research strategies through four types of validity adapted from the empirical social sciences -- statistical, internal, external, and construct validity. We find that each strategy comes with a characteristic validity profile: proxy experiments trade external and construct validity for statistical and internal validity; observational studies face confounding and effect heterogeneity; and single-run designs are strained by interference between treated units. This analysis reveals several validity threats that have received insufficient attention in the literature. Overall, our evaluation framework provides researchers with a practical toolkit for scrutinizing validity threats in foundation model research~designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that cost-saving approximations to controlled experiments in foundation model research—proxy experiments, observational studies, and single-run designs—introduce validity threats in the form of hidden assumptions that can invalidate claims. It proposes an evaluation framework that recasts foundation model research as a causal inference problem and applies four validity types (statistical, internal, external, and construct) adapted from empirical social sciences to produce characteristic validity profiles for each strategy, revealing several insufficiently addressed threats.
Significance. If the adaptation holds, the framework supplies a practical, structured toolkit for scrutinizing validity in compute-constrained FM research. It explicitly maps strategies to threats such as confounding and effect heterogeneity in observational studies and interference in single-run designs, potentially improving the reliability of claims that rely on these approximations.
major comments (1)
- [Abstract] Abstract, paragraph introducing the evaluation framework: the claim that the four validity types transfer from empirical social sciences without substantial redefinition or loss of diagnostic power is load-bearing for the central argument that the framework provides a practical toolkit. The manuscript does not supply a detailed mapping or concrete demonstration that these criteria surface threats beyond those already identified in the ML literature on scaling laws and proxy tasks.
minor comments (1)
- [Abstract] The abstract states that the analysis 'reveals several validity threats that have received insufficient attention' but does not enumerate them; adding an explicit list or summary table early in the paper would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the positive assessment of the framework's potential utility. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph introducing the evaluation framework: the claim that the four validity types transfer from empirical social sciences without substantial redefinition or loss of diagnostic power is load-bearing for the central argument that the framework provides a practical toolkit. The manuscript does not supply a detailed mapping or concrete demonstration that these criteria surface threats beyond those already identified in the ML literature on scaling laws and proxy tasks.
Authors: We agree that an explicit demonstration of the transfer is important for the claim. The manuscript adapts the four validity definitions directly from the cited social-science sources (e.g., Shadish, Cook & Campbell) without redefinition and then applies them in Sections 3–5 to derive strategy-specific threat profiles. These applications identify threats such as interference between treated units in single-run designs and effect heterogeneity in observational studies of public checkpoints—issues that receive little attention in the scaling-law and proxy-task literature. To make the mapping more transparent and to strengthen the load-bearing claim, we will add a summary table in the revised manuscript that cross-tabulates each validity criterion against the three research strategies, with explicit contrasts to existing ML discussions. revision: yes
Circularity Check
No circularity: direct application of external social-science concepts with no self-referential derivations or fitted inputs
full rationale
The paper contains no equations, fitted parameters, or derivations. It proposes an evaluation framework by directly adapting four established validity types (statistical, internal, external, construct) from empirical social sciences to foundation-model research strategies, without any reduction of claims to self-citations, self-definitions, or renamed inputs. The central premise—that compute-saving strategies introduce validity threats—is presented as an application of external concepts rather than a result derived from the paper's own prior outputs. This is the most common honest non-finding for conceptual framework papers that import independent external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Foundation model research strategies can be treated as attempts to perform causal inference.
- domain assumption The four validity types from empirical social sciences apply directly to ML research designs.
Reference graph
Works this paper leans on
-
[1]
One-shot empirical privacy estimation for federated learning
Galen Andrew, Peter Kairouz, Sewoong Oh, Alina Oprea, H Brendan McMahan, and Vinith M Suriyakumar. One-shot empirical privacy estimation for federated learning. InInternational Conference on Learning Representations, 2024
2024
-
[2]
If influence functions are the answer, then what is the question?Advances in Neural Information Processing Systems, 35:17953–17967, 2022
Juhan Bae, Nathan Ng, Alston Lo, Marzyeh Ghassemi, and Roger B Grosse. If influence functions are the answer, then what is the question?Advances in Neural Information Processing Systems, 35:17953–17967, 2022
2022
-
[3]
Juhan Bae, Wu Lin, Jonathan Lorraine, and Roger Grosse. Training data attribution via approximate unrolled differentiation.arXiv preprint arXiv:2405.12186, 2024
-
[4]
Measuring what matters: Construct validity in large language model benchmarks
Andrew M Bean, Ryan Othniel Kearns, Angelika Romanou, Franziska Sofia Hafner, Harry Mayne, Jan Batzner, Negar Foroutan, Chris Schmitz, Karolina Korgul, Hunar Batra, et al. Measuring what matters: Construct validity in large language model benchmarks. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[5]
Shane Bergsma, Nolan Dey, Gurpreet Gosal, Gavia Gray, Daria Soboleva, and Joel Hestness. Power lines: Scaling laws for weight decay and batch size in llm pre-training.arXiv preprint arXiv:2505.13738, 2025
-
[6]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al. Deepseek llm: Scaling open-source language models with longtermism.arXiv preprint arXiv:2401.02954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International conference on machine learning, pages 2397–2430. PMLR, 2023
2023
-
[8]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Train once, answer all: Many pretraining experiments for the cost of one
Sebastian Bordt and Martin Pawelczyk. Train once, answer all: Many pretraining experiments for the cost of one. InICLR, 2026
2026
-
[10]
Data taggants: Dataset owner- ship verification via harmless targeted data poisoning
Wassim Bouaziz, Nicolas Usunier, and El-Mahdi El-Mhamdi. Data taggants: Dataset owner- ship verification via harmless targeted data poisoning. 2025
2025
-
[11]
Accounting for variance in machine learning benchmarks.Proceedings of machine learning and systems, 2021
Xavier Bouthillier, Pierre Delaunay, Mirko Bronzi, Assya Trofimov, Brennan Nichyporuk, Justin Szeto, Nazanin Mohammadi Sepahvand, Edward Raff, Kanika Madan, Vikram V oleti, et al. Accounting for variance in machine learning benchmarks.Proceedings of machine learning and systems, 2021
2021
-
[12]
Samuel Bowman and George Dahl. What will it take to fix benchmarking in natural lan- guage understanding? InConference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4843–4855, 2021
2021
-
[13]
Language models are few-shot learners.NeurIPS, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.NeurIPS, 2020
2020
-
[14]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Kather- ine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21), pages 2633–2650, 2021. 10
2021
-
[15]
Chatbot arena: An open platform for evaluating llms by human preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. Chatbot arena: An open platform for evaluating llms by human preference. InForty-first International Conference on Machine Learning, 2024
2024
-
[16]
A hitchhiker’s guide to scaling law estimation.arXiv preprint arXiv:2410.11840, 2024
Leshem Choshen, Yang Zhang, and Jacob Andreas. A hitchhiker’s guide to scaling law estimation.arXiv preprint arXiv:2410.11840, 2024
-
[17]
Provably robust watermarks for open-source language models.TMLR, 2026
Miranda Christ, Sam Gunn, Tal Malkin, and Mariana Raykova. Provably robust watermarks for open-source language models.TMLR, 2026
2026
-
[18]
The variety-of-evidence thesis: A bayesian exploration of its surprising failures.Synthese, 2019
François Claveau and Olivier Grenier. The variety-of-evidence thesis: A bayesian exploration of its surprising failures.Synthese, 2019
2019
-
[19]
The rising costs of training frontier AI models.arXiv preprint arXiv:2405.21015, 2024
Ben Cottier, Robi Rahman, Loredana Fattorini, Nestor Maslej, Tamay Besiroglu, and David Owen. The rising costs of training frontier ai models.arXiv preprint arXiv:2405.21015, 2024
-
[20]
The benchmark lottery.arXiv preprint arXiv:2107.07002, 2021
Mostafa Dehghani, Yi Tay, Alexey A Gritsenko, Zhe Zhao, Neil Houlsby, Fernando Diaz, Donald Metzler, and Oriol Vinyals. The benchmark lottery.arXiv preprint arXiv:2107.07002, 2021
-
[21]
Constat: Performance-based contamina- tion detection in large language models.Advances in Neural Information Processing Systems, 37:92420–92464, 2024
Jasper Dekoninck, Mark Müller, and Martin Vechev. Constat: Performance-based contamina- tion detection in large language models.Advances in Neural Information Processing Systems, 37:92420–92464, 2024
2024
-
[22]
Nolan Dey, Gurpreet Gosal, Hemant Khachane, William Marshall, Ribhu Pathria, Marvin Tom, Joel Hestness, et al. Cerebras-gpt: Open compute-optimal language models trained on the cerebras wafer-scale cluster.arXiv preprint arXiv:2304.03208, 2023
-
[23]
Training on the test task confounds evaluation and emergence.arXiv preprint arXiv:2407.07890, 2024
Ricardo Dominguez-Olmedo, Florian E Dorner, and Moritz Hardt. Training on the test task confounds evaluation and emergence.arXiv preprint arXiv:2407.07890, 2024
-
[24]
Gaussian differential privacy.Journal of the Royal Statistical Society Series B: Statistical Methodology, 84(1):3–37, 2022
Jinshuo Dong, Aaron Roth, and Weijie J Su. Gaussian differential privacy.Journal of the Royal Statistical Society Series B: Statistical Methodology, 84(1):3–37, 2022
2022
-
[25]
Vineeth Dorna, Anmol Mekala, Wenlong Zhao, Andrew McCallum, Zachary C Lipton, J Zico Kolter, and Pratyush Maini. Openunlearning: Accelerating llm unlearning via unified bench- marking of methods and metrics.arXiv preprint arXiv:2506.12618, 2025
-
[26]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
2024
-
[27]
Yanai Elazar, Nora Kassner, Shauli Ravfogel, Amir Feder, Abhilasha Ravichander, Marius Mosbach, Yonatan Belinkov, Hinrich Schütze, and Yoav Goldberg. Measuring causal effects of data statistics on language model’sfactual’predictions.arXiv preprint arXiv:2207.14251, 2022
-
[28]
Data on AI models, 3 2026
Epoch AI. Data on AI models, 3 2026. URL https://epoch.ai/data/ai-models. Ac- cessed: 21 Mar 2026
2026
-
[29]
What neural networks memorize and why: Discovering the long tail via influence estimation.Advances in Neural Information Processing Systems, 33: 2881–2891, 2020
Vitaly Feldman and Chiyuan Zhang. What neural networks memorize and why: Discovering the long tail via influence estimation.Advances in Neural Information Processing Systems, 33: 2881–2891, 2020
2020
-
[30]
Open llm leaderboard v2
Clémentine Fourrier, Nathan Habib, Alina Lozovskaya, Konrad Szafer, and Thomas Wolf. Open llm leaderboard v2. https://huggingface.co/spaces/open-llm-leaderboard/ open_llm_leaderboard, 2024
2024
-
[31]
Timo Freiesleben and Sebastian Zezulka. The benchmarking epistemology: Construct validity for evaluating machine learning models.arXiv preprint arXiv:2510.23191, 2025
-
[32]
A swiss army infinitesimal jackknife
Ryan Giordano, William Stephenson, Runjing Liu, Michael Jordan, and Tamara Broderick. A swiss army infinitesimal jackknife. InThe 22nd International Conference on Artificial Intelligence and Statistics, pages 1139–1147. PMLR, 2019. 11
2019
-
[33]
Scaling laws for data filtering–data curation cannot be compute agnostic
Sachin Goyal, Pratyush Maini, Zachary C Lipton, Aditi Raghunathan, and J Zico Kolter. Scaling laws for data filtering–data curation cannot be compute agnostic. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22702–22711, 2024
2024
-
[34]
Olmo: Accelerating the science of language models
Dirk Groeneveld, Iz Beltagy, Evan Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, et al. Olmo: Accelerating the science of language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15789–15809, 2024
2024
-
[35]
Roger Grosse, Juhan Bae, Cem Anil, Nelson Elhage, Alex Tamkin, Amirhossein Tajdini, Benoit Steiner, Dustin Li, Esin Durmus, Ethan Perez, et al. Studying large language model generalization with influence functions.arXiv preprint arXiv:2308.03296, 2023
-
[36]
Moritz Haas, Sebastian Bordt, Ulrike von Luxburg, and Leena Chennuru Vankadara. On the surprising effectiveness of large learning rates under standard width scaling.arXiv preprint arXiv:2505.22491, 2025
-
[37]
The influence curve and its role in robust estimation.Journal of the american statistical association, 69(346):383–393, 1974
Frank R Hampel. The influence curve and its role in robust estimation.Journal of the american statistical association, 69(346):383–393, 1974
1974
-
[38]
The emerging science of machine learning benchmarks.Manuscript
Moritz Hardt. The emerging science of machine learning benchmarks.Manuscript. https://mlbenchmarks.org, 2025
2025
-
[39]
Using big data to emulate a target trial when a randomized trial is not available.American journal of epidemiology, 183(8):758–764, 2016
Miguel A Hernán and James M Robins. Using big data to emulate a target trial when a randomized trial is not available.American journal of epidemiology, 183(8):758–764, 2016
2016
-
[40]
Position: Why we must rethink empirical research in machine learning
Moritz Herrmann, F Julian D Lange, Katharina Eggensperger, Giuseppe Casalicchio, Marcel Wever, Matthias Feurer, David Rügamer, Eyke Hüllermeier, Anne-Laure Boulesteix, and Bernd Bischl. Position: Why we must rethink empirical research in machine learning. In International Conference on Machine Learning (ICML), 2024
2024
-
[41]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Algorithmic progress in language models
Anson Ho, Tamay Besiroglu, Ege Erdil, David Owen, Robi Rahman, Zifan C Guo, David Atkinson, Neil Thompson, and Jaime Sevilla. Algorithmic progress in language models. Advances in Neural Information Processing Systems, 37:58245–58283, 2024
2024
-
[43]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. Minicpm: Unveiling the potential of small language models with scalable training strategies.arXiv preprint arXiv:2404.06395, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Abigail Z. Jacobs and Hanna Wallach. Measurement and fairness. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT), pages 375–385. ACM, 2021. doi: 10.1145/3442188.3445901
-
[46]
Measuring forgetting of memorized training examples
Matthew Jagielski, Om Thakkar, Florian Tramer, Daphne Ippolito, Katherine Lee, Nicholas Carlini, Eric Wallace, Shuang Song, Abhradeep Guha Thakurta, Nicolas Papernot, and Chiyuan Zhang. Measuring forgetting of memorized training examples. InICLR, 2023
2023
-
[47]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[48]
How well can differential privacy be audited in one run?arXiv preprint arXiv:2503.07199, 2025
Amit Keinan, Moshe Shenfeld, and Katrina Ligett. How well can differential privacy be audited in one run?arXiv preprint arXiv:2503.07199, 2025. 12
-
[49]
Pre-training under infinite compute.arXiv preprint arXiv:2509.14786, 2025
Konwoo Kim, Suhas Kotha, Percy Liang, and Tatsunori Hashimoto. Pre-training under infinite compute.arXiv preprint arXiv:2509.14786, 2025
-
[50]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. InInternational conference on machine learning, pages 1885–1894. PMLR, 2017
2017
-
[51]
Predicting llm reasoning performance with small proxy model
Woosung Koh, Juyoung Suk, Sungjun Han, Se-Young Yun, and Jamin Shin. Predicting llm reasoning performance with small proxy model. 2026
2026
-
[52]
Revisiting the scaling properties of downstream metrics in large language model training
Jakub Krajewski, Amitis Shidani, Dan Busbridge, Sam Wiseman, and Jason Ramapuram. Revisiting the scaling properties of downstream metrics in large language model training. arXiv preprint arXiv:2512.08894, 2025
-
[53]
Gaussian membership inference privacy.Advances in Neural Information Processing Systems, 36:73866–73878, 2023
Tobias Leemann, Martin Pawelczyk, and Gjergji Kasneci. Gaussian membership inference privacy.Advances in Neural Information Processing Systems, 36:73866–73878, 2023
2023
-
[54]
Causal estimation of memorisation profiles.arXiv preprint arXiv:2406.04327, 2024
Pietro Lesci, Clara Meister, Thomas Hofmann, Andreas Vlachos, and Tiago Pimentel. Causal estimation of memorisation profiles.arXiv preprint arXiv:2406.04327, 2024
-
[55]
Causal estimation of tokenisation bias.arXiv preprint arXiv:2506.03149, 2025
Pietro Lesci, Clara Meister, Thomas Hofmann, Andreas Vlachos, and Tiago Pimentel. Causal estimation of tokenisation bias.arXiv preprint arXiv:2506.03149, 2025
-
[56]
Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity
Bojie Li. Incompressible knowledge probes: Estimating black-box llm parameter counts via factual capacity, 2026. URLhttps://arxiv.org/abs/2604.24827
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Active evaluation acquisition for efficient llm benchmarking.arXiv preprint arXiv:2410.05952, 2024
Yang Li, Jie Ma, Miguel Ballesteros, Yassine Benajiba, and Graham Horwood. Active evaluation acquisition for efficient llm benchmarking.arXiv preprint arXiv:2410.05952, 2024
-
[58]
Do influence functions work on large language models.arXiv preprint arXiv:2409.19998, 3, 2024
Zhe Li, Wei Zhao, Yige Li, and Jun Sun. Do influence functions work on large language models.arXiv preprint arXiv:2409.19998, 3, 2024
-
[59]
Are we learning yet? a meta review of evaluation failures across machine learning
Thomas Liao, Rohan Taori, Inioluwa Deborah Raji, and Ludwig Schmidt. Are we learning yet? a meta review of evaluation failures across machine learning. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[60]
Not-just- scaling laws: Towards a better understanding of the downstream impact of language model design decisions
Emmy Liu, Amanda Bertsch, Lintang Sutawika, Lindia Tjuatja, Patrick Fernandes, Lara Marinov, Michael Chen, Shreya Singhal, Carolin Lawrence, Aditi Raghunathan, et al. Not-just- scaling laws: Towards a better understanding of the downstream impact of language model design decisions. InProceedings of the 2025 Conference on Empirical Methods in Natural Langu...
2025
-
[61]
Atlas: Adaptive transfer scaling laws for multilingual pretraining, finetuning, and decoding the curse of multilinguality
Shayne Longpre, Sneha Kudugunta, Niklas Muennighoff, I Hsu, Isaac Caswell, Alex Pentland, Sercan Arik, Chen-Yu Lee, Sayna Ebrahimi, et al. Atlas: Adaptive transfer scaling laws for multilingual pretraining, finetuning, and decoding the curse of multilinguality. InICLR, 2026
2026
-
[62]
Nicholas Lourie, Michael Y Hu, and Kyunghyun Cho. Scaling laws are unreliable for downstream tasks: A reality check.arXiv preprint arXiv:2507.00885, 2025
-
[63]
Lovish Madaan, Aaditya K. Singh, Rylan Schaeffer, Andrew Poulton, Sanmi Koyejo, Pon- tus Stenetorp, Sharan Narang, and Dieuwke Hupkes. Quantifying variance in evaluation benchmarks.arXiv preprint arXiv:2406.10229, 2024
-
[64]
Ian Magnusson, Nguyen Tai, Ben Bogin, David Heineman, Jena D Hwang, Luca Soldaini, Akshita Bhagia, Jiacheng Liu, Dirk Groeneveld, Oyvind Tafjord, et al. Datadecide: How to predict best pretraining data with small experiments.arXiv preprint arXiv:2504.11393, 2025
-
[65]
TOFU: A Task of Fictitious Unlearning for LLMs
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C Lipton, and J Zico Kolter. Tofu: A task of fictitious unlearning for llms.arXiv preprint arXiv:2401.06121, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Llms on the line: Data determines loss-to-loss scaling laws
Prasanna Mayilvahanan, Thaddäus Wiedemer, Sayak Mallick, Matthias Bethge, and Wieland Brendel. Llms on the line: Data determines loss-to-loss scaling laws. InICML, 2025
2025
-
[67]
Is there "Secret Sauce'' in Large Language Model Development?
Matthias Mertens, Natalia Fischl-Lanzoni, and Neil Thompson. Is there" secret sauce”in large language model development?arXiv preprint arXiv:2602.07238, 2026. 13
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[68]
Adding error bars to evals: A statistical approach to language model evaluations
Evan Miller. Adding error bars to evals: A statistical approach to language model evaluations. arXiv preprint arXiv:2411.00640, 2024
-
[69]
Distributional training data attribution: What do influence functions sample? 2025
Bruno Mlodozeniec, Isaac Reid, Sam Power, David Krueger, Murat Erdogdu, Richard E Turner, and Roger Grosse. Distributional training data attribution: What do influence functions sample? 2025
2025
-
[70]
Scaling data-constrained language models.Advances in Neural Information Processing Systems, 36:50358–50376, 2023
Niklas Muennighoff, Alexander Rush, Boaz Barak, Teven Le Scao, Nouamane Tazi, Alek- sandra Piktus, Sampo Pyysalo, Thomas Wolf, and Colin A Raffel. Scaling data-constrained language models.Advances in Neural Information Processing Systems, 36:50358–50376, 2023
2023
-
[71]
Deep ignorance: Filtering pretraining data builds tamper-resistant safeguards into open-weight llms
Kyle O’Brien, Stephen Casper, Quentin Anthony, Tomek Korbak, Robert Kirk, Xander Davies, Ishan Mishra, Geoffrey Irving, Yarin Gal, and Stella Biderman. Deep ignorance: Filtering pretraining data builds tamper-resistant safeguards into open-weight llms. InICLR 2026, 2026
2026
-
[72]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, et al. 2 olmo 2 furious.arXiv preprint arXiv:2501.00656, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
How predictable is language model benchmark performance?arXiv preprint arXiv:2401.04757, 2024
David Owen. How predictable is language model benchmark performance?arXiv preprint arXiv:2401.04757, 2024
-
[74]
Lorenzo Pacchiardi, Lucy G Cheke, and José Hernández-Orallo. 100 instances is all you need: predicting the success of a new llm on unseen data by testing on a few instances.arXiv preprint arXiv:2409.03563, 2024
-
[75]
Machine unlearning fails to remove data poisoning attacks
Martin Pawelczyk, Jimmy Z Di, Yiwei Lu, Gautam Kamath, Ayush Sekhari, and Seth Neel. Machine unlearning fails to remove data poisoning attacks. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[76]
Cambridge university press, 2009
Judea Pearl.Causality. Cambridge university press, 2009
2009
-
[77]
Improving reproducibility in machine learning research (a report from the neurips 2019 reproducibility program).Journal of machine learning research, 22(164):1–20, 2021
Joelle Pineau, Philippe Vincent-Lamarre, Koustuv Sinha, Vincent Larivière, Alina Beygelzimer, Florence d’Alché Buc, Emily Fox, and Hugo Larochelle. Improving reproducibility in machine learning research (a report from the neurips 2019 reproducibility program).Journal of machine learning research, 22(164):1–20, 2021
2019
-
[78]
tinybenchmarks: evaluating llms with fewer examples.arXiv preprint arXiv:2402.14992, 2024
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, and Mikhail Yurochkin. tinybenchmarks: evaluating llms with fewer examples.arXiv preprint arXiv:2402.14992, 2024
-
[79]
Bender, Amandalynne Paullada, Emily Denton, and Alex Hanna
Inioluwa Deborah Raji, Emily M. Bender, Amandalynne Paullada, Emily Denton, and Alex Hanna. AI and the everything in the whole wide world benchmark. InNeural Information Processing Systems(NeurIPS, 2021
2021
-
[80]
Kochenderfer
Anka Reuel, Amelia Hardy, Chandler Smith, Max Lamparth, Malcolm Hardy, and Mykel J. Kochenderfer. BetterBench: Assessing AI benchmarks, uncovering issues, and establishing best practices. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.