A Systematic Study of Behavioral Cloning for Scientific Data Annotation
Pith reviewed 2026-06-29 16:20 UTC · model grok-4.3
The pith
Behavioral cloning on nine synthetic scientific annotation tasks shows models learn GUI mechanics before decisions, reduce errors relative to training data, and transfer via multi-task pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
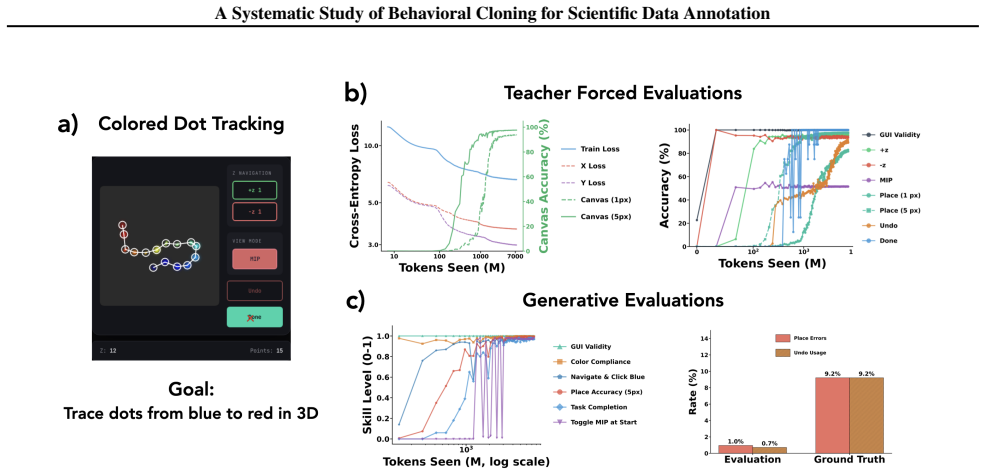
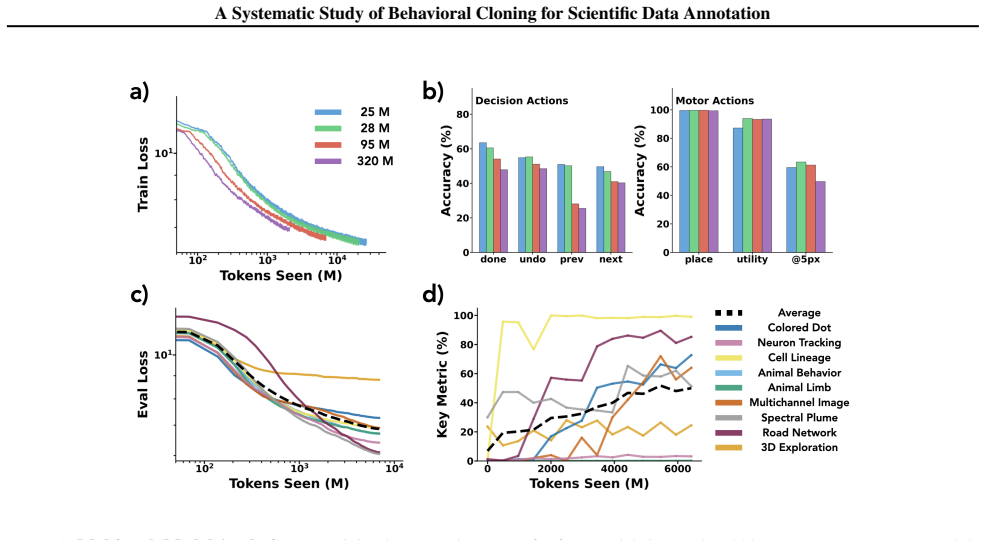
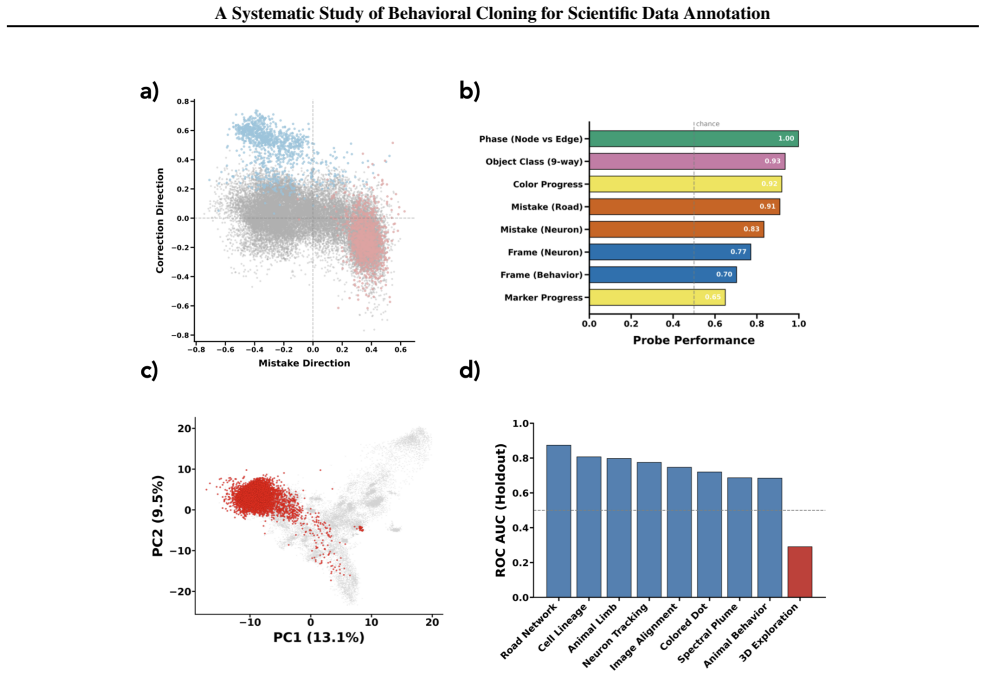
A framework of nine synthetic tasks with synthetic annotations that simulate realistic human strategies reveals that behavioral cloning produces hierarchical skill emergence in which models master interface mechanics before task-critical decisions, generate fewer mistakes than the training distribution while preserving error-correction ability, exhibit improved data efficiency with scale, succeed at few-shot adaptation only after multi-task pretraining, and encode latent variables such as task phase and a shared mistake representation detectable by linear probes.
What carries the argument
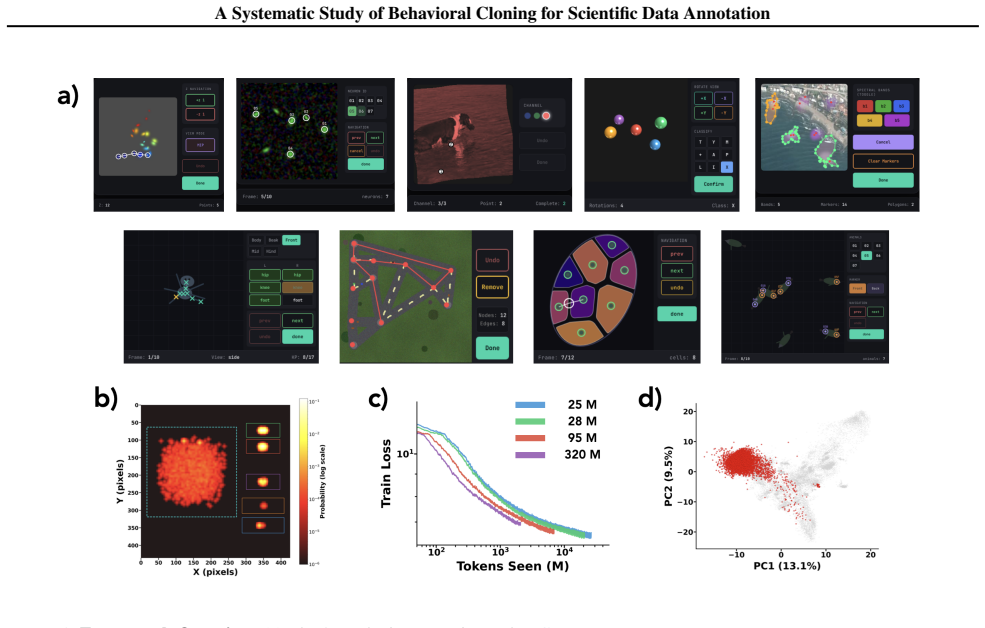
The framework of nine synthetic tasks paired with synthetic annotations that simulate human exploration, mistake correction, and strategic decision-making.
If this is right
- Models acquire GUI mechanics before task-critical decisions.
- Models commit fewer mistakes than the training data while retaining the ability to correct errors.
- Larger models are more data-efficient within the tested scale range.
- Multi-task pretraining enables efficient fine-tuning to new tasks while training from scratch fails.
- Linear probes recover internal representations of task phase, data position, and a mistake concept that generalizes across tasks.
Where Pith is reading between the lines
- If the synthetic trajectories capture the structure of real expert behavior, the same cloning approach could be applied directly to logged human sessions to reduce the verification burden in production annotation pipelines.
- The emergence of a shared mistake representation suggests it may be possible to train a single error-detection head that works across different annotation domains without task-specific retraining.
- The failure of scratch training on new tasks implies that any practical deployment would require a broad pretraining corpus before fine-tuning on domain-specific scientific data.
Load-bearing premise
The nine synthetic tasks paired with synthetic annotations accurately simulate realistic human strategies including exploration, mistake correction, and strategic decision-making in actual scientific annotation workflows.
What would settle it
Record real human annotation sessions on the same scientific tasks used to generate the synthetic data, then test whether the same hierarchical learning order, error-reduction pattern, and shared mistake representation appear in models trained on the real trajectories.
Figures




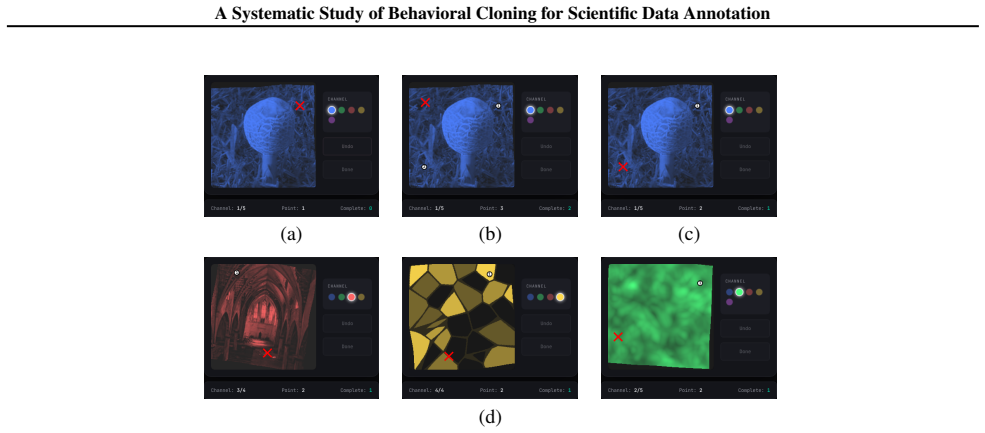



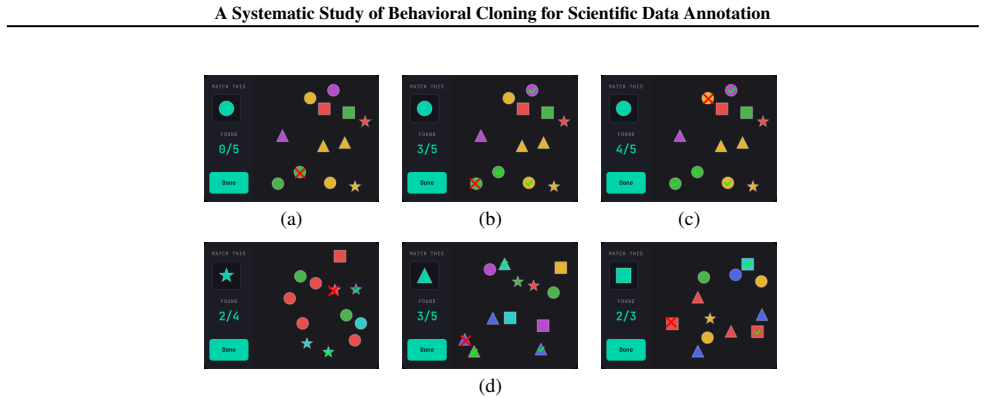
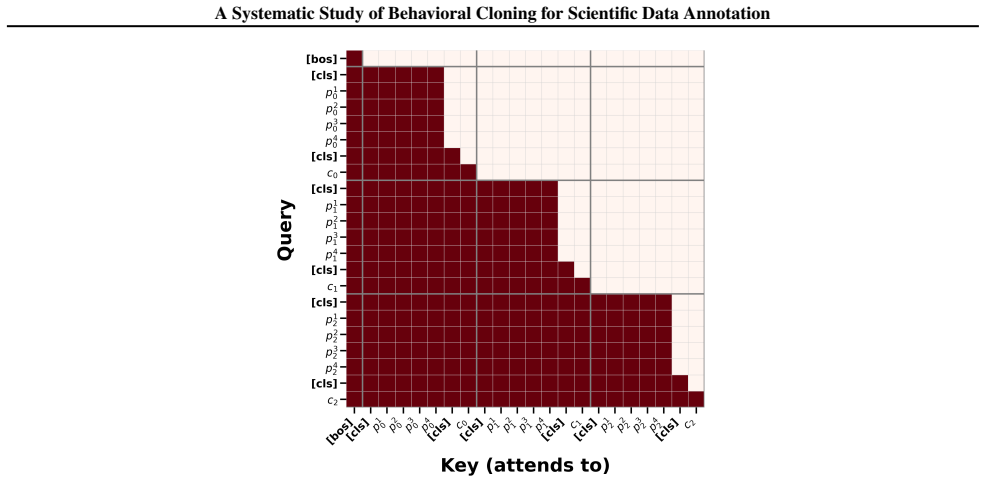
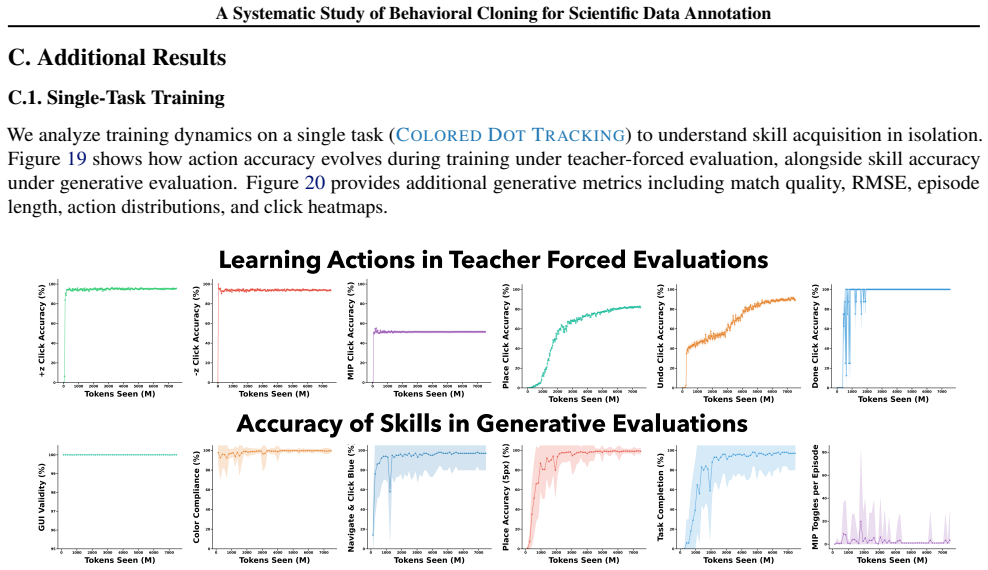

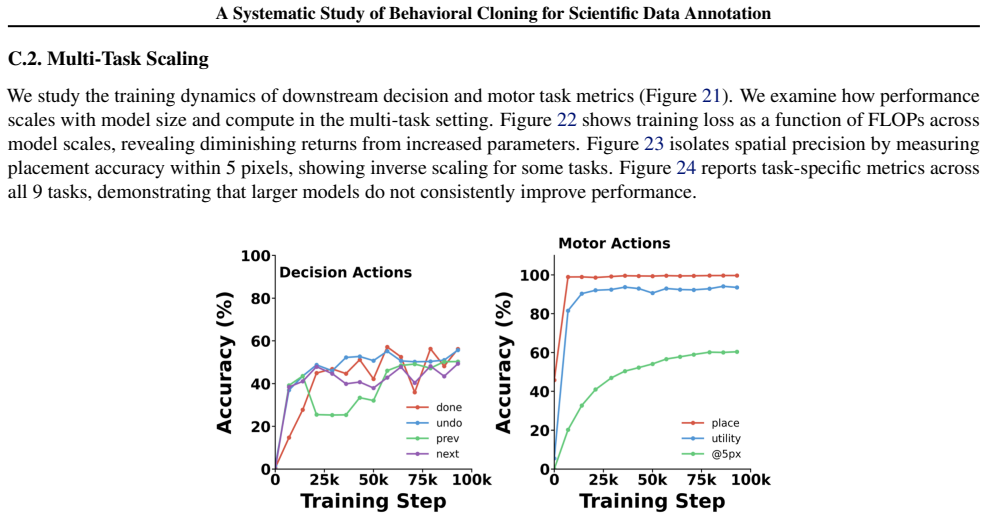
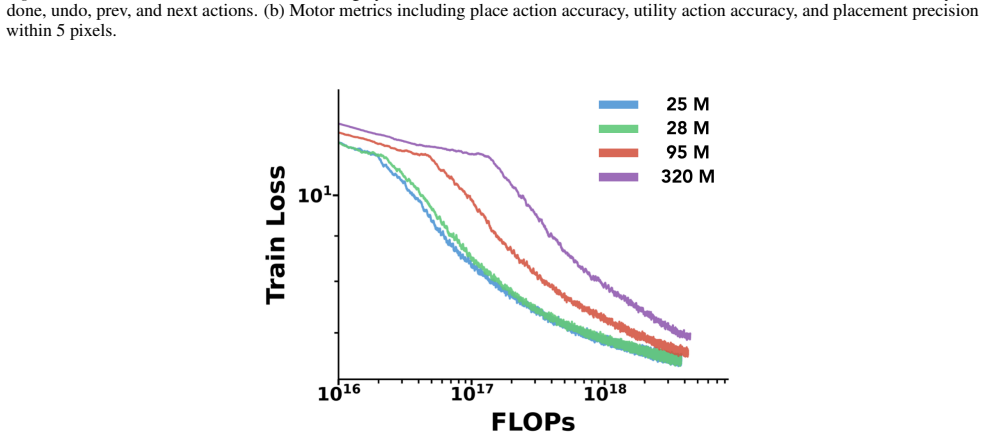
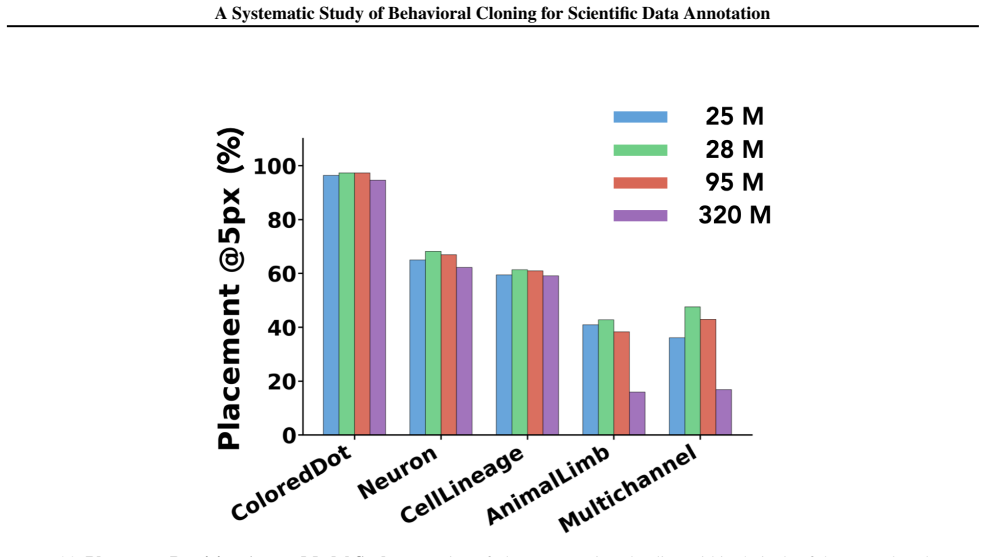
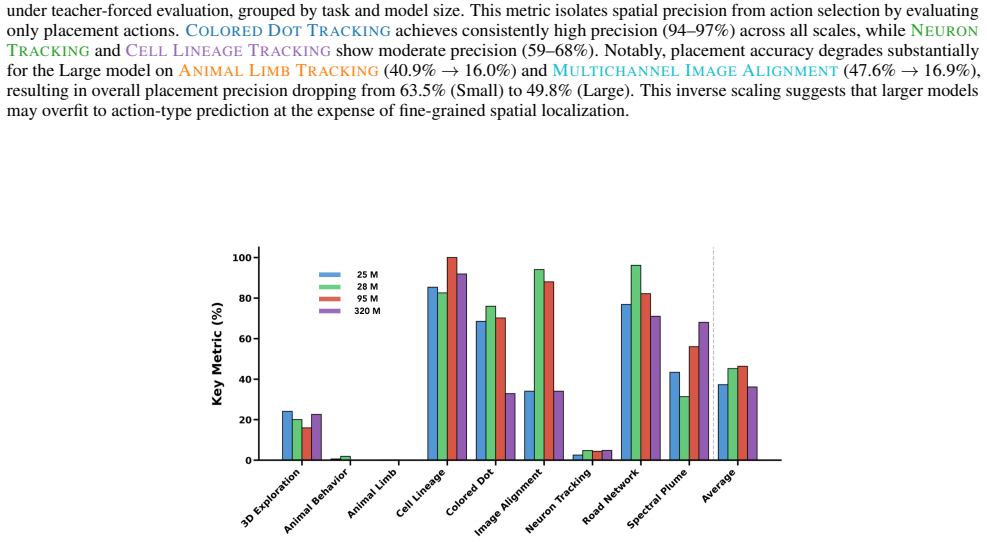
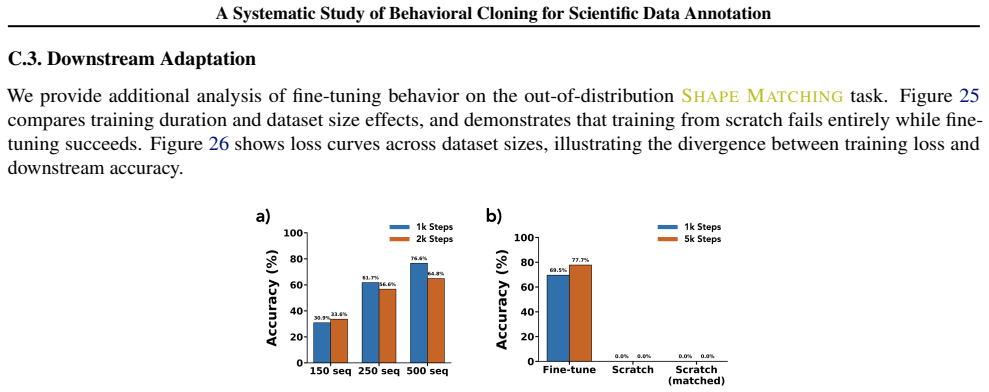
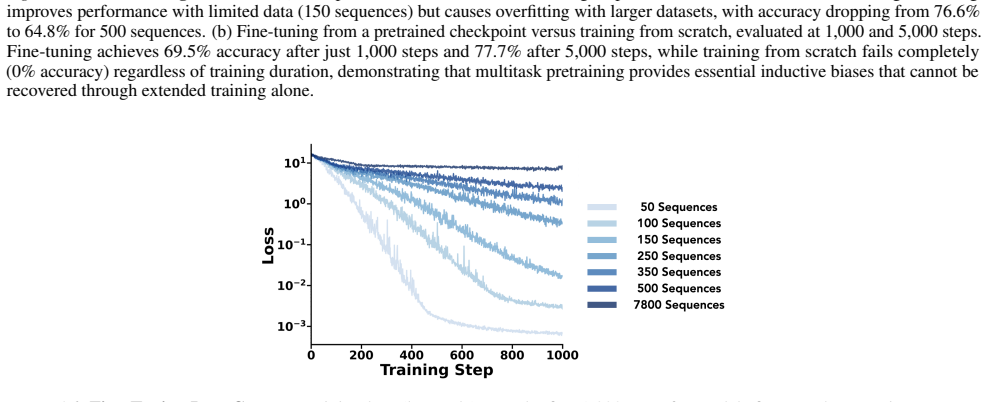
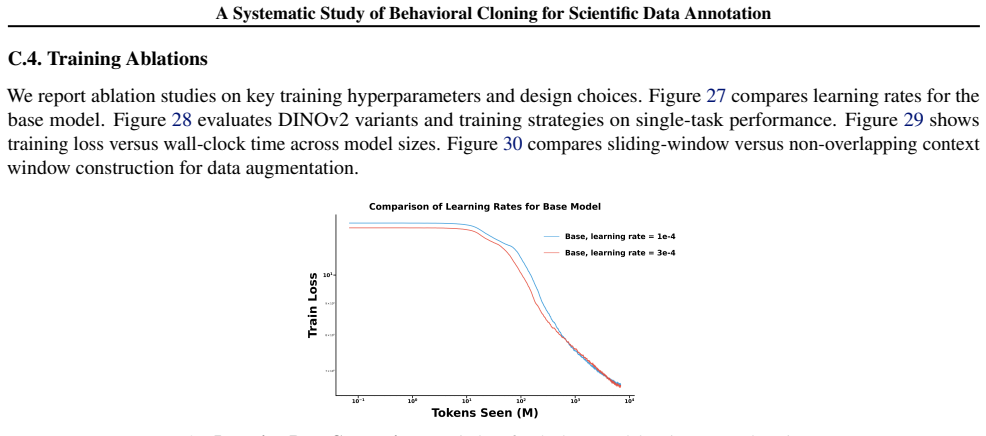
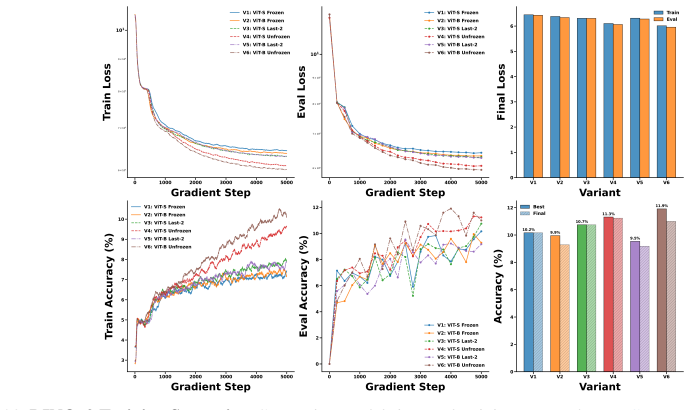
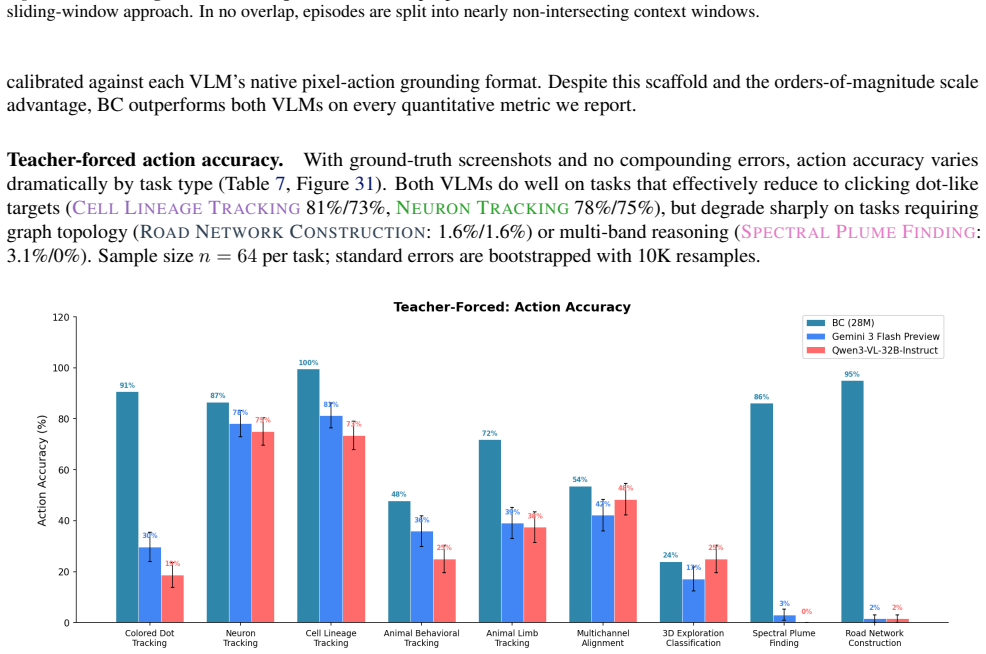
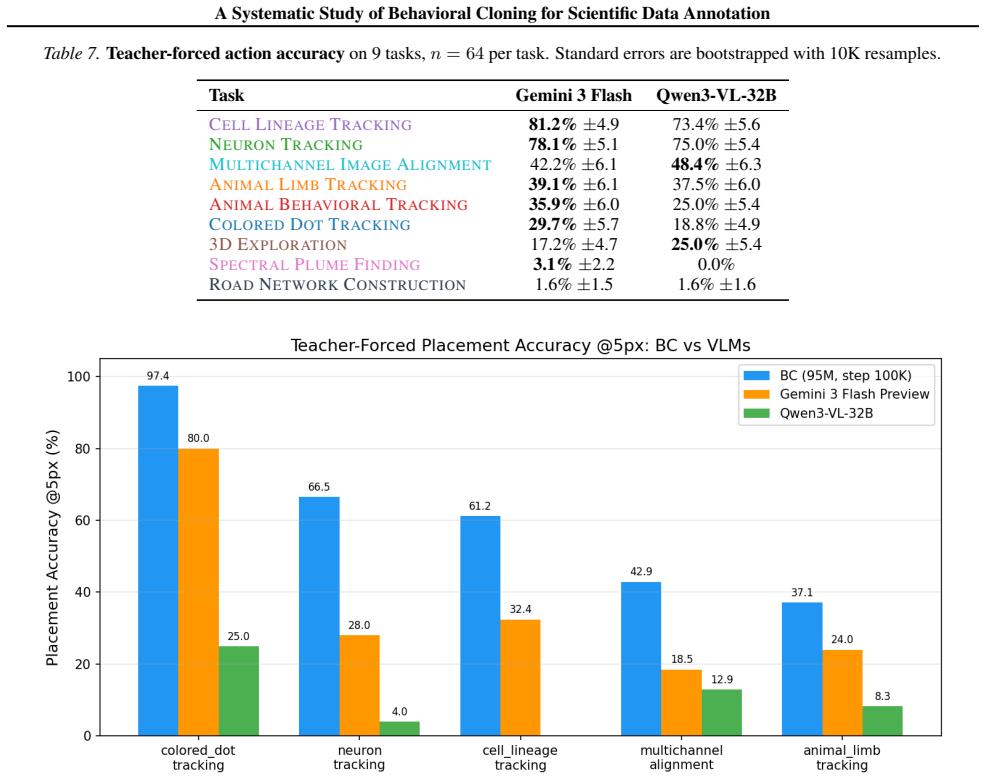





read the original abstract
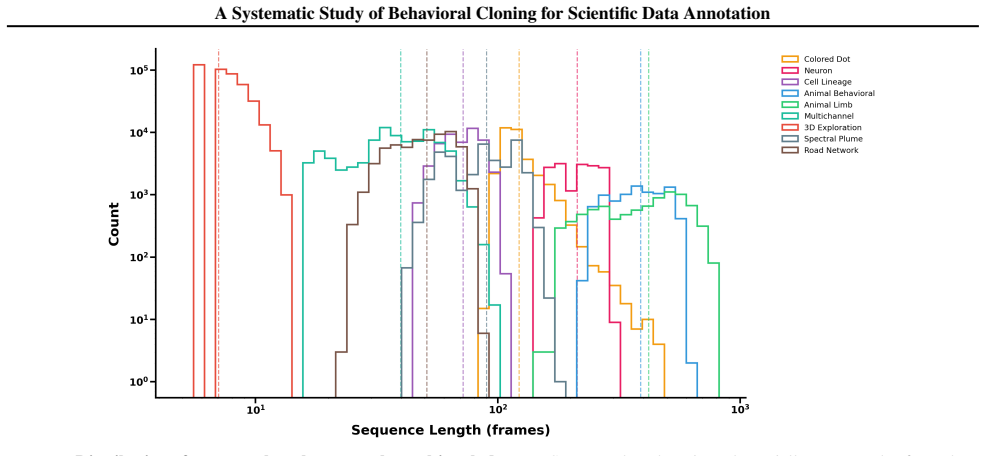
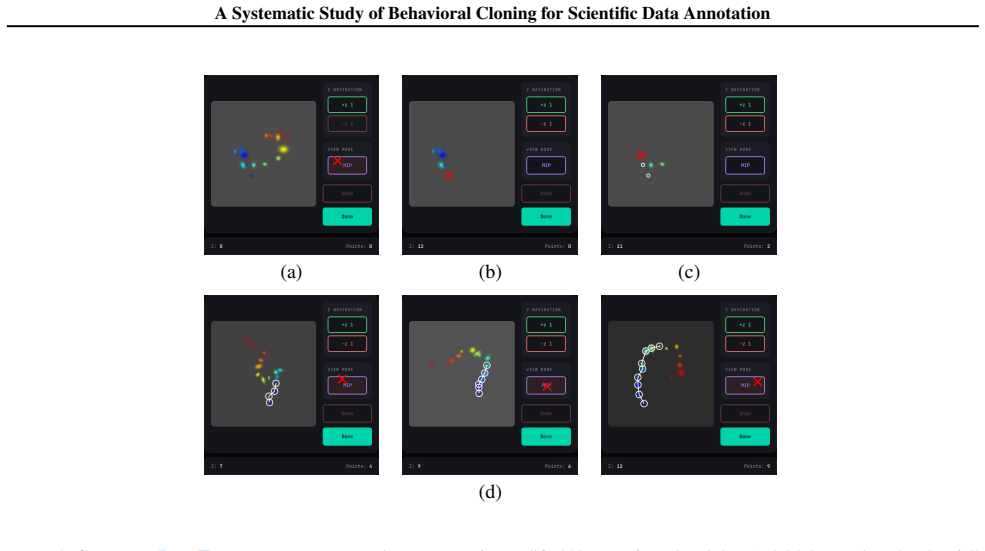
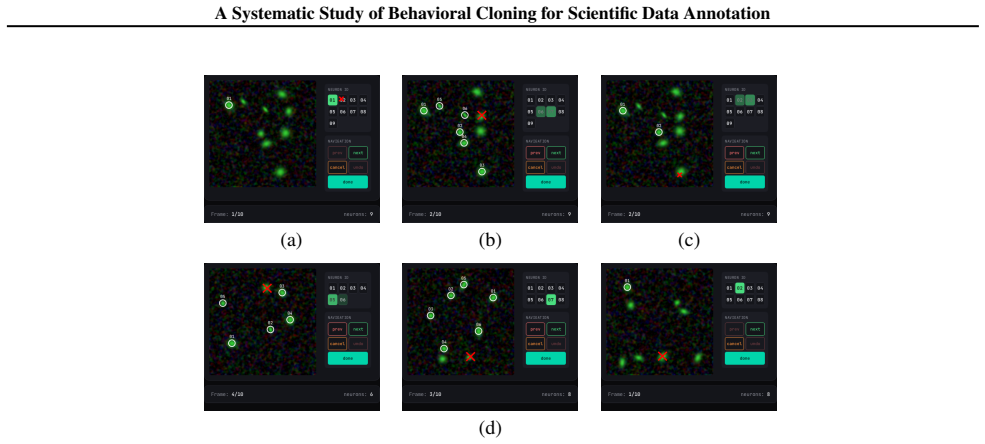
Scientific data annotation, such as tracking animals in video or proofreading neural reconstructions, remains bottlenecked by the "last mile" problem: even with strong automation, verification and correction consume substantial human effort. Standard approaches train models to directly predict annotations, discarding the rich supervision in how experts navigate, click, verify, and correct. We introduce a framework for studying behavioral cloning on scientific annotation: 9 synthetic tasks paired with synthetic annotations that simulate realistic human strategies including exploration, mistake correction, and strategic decision-making. Our experiments reveal several findings. First, skills emerge hierarchically: models learn GUI mechanics before task-critical decisions, and commit fewer mistakes than the training data while retaining the ability to correct errors when they occur. Second, scaling models on multi-task behavioral cloning shows that larger models are more data efficient within our scale range. Third, multi-task pretraining enables efficient fine-tuning to new tasks, while training from scratch fails entirely. Fourth, linear probes reveal that models internally represent latent variables of the annotation process such as task phase and data position; interestingly, we find a shared mistake representation that generalizes across different annotation tasks. Overall, our framework establishes systematic benchmarks and identifies key bottlenecks, providing a foundation for scaling behavioral cloning to real-world scientific data annotation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a framework for behavioral cloning in scientific data annotation using 9 synthetic tasks paired with synthetic annotations that simulate human strategies such as exploration, mistake correction, and strategic decision-making. Experiments report hierarchical skill emergence (GUI mechanics before task decisions, fewer mistakes than training data while retaining correction ability), greater data efficiency for larger models in multi-task settings, successful transfer from multi-task pretraining (vs. failure from scratch), and internal representations via linear probes for latent variables like task phase and data position, including a shared mistake representation across tasks. The work positions the framework as establishing benchmarks and identifying bottlenecks for scaling to real-world annotation.
Significance. If the synthetic setup proves representative, the controlled benchmarks and findings on hierarchical emergence, multi-task transfer, and shared internal representations could provide a useful testbed for advancing behavioral cloning methods beyond direct prediction in annotation workflows. The empirical nature of the study, with systematic multi-task experiments, offers a foundation for identifying practical bottlenecks in this domain.
major comments (2)
- [Abstract] Abstract: The central claim that the framework supplies usable benchmarks and transferable insights for real-world scientific annotation rests on the synthetic annotations faithfully reproducing human strategies (exploration, correction, strategic decisions). No quantitative alignment checks against real expert traces (e.g., click logs, error distributions, or phase transitions from actual annotation sessions) are reported, so reported phenomena such as hierarchical emergence and the shared mistake representation risk being artifacts of the generator rather than generalizable findings.
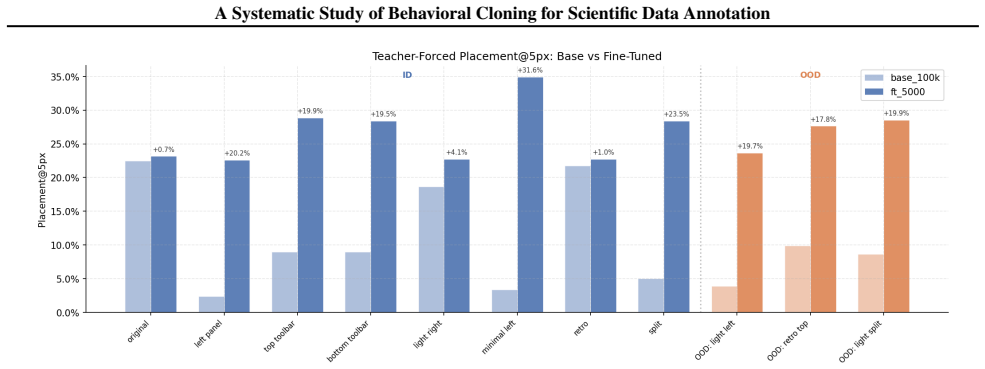
- [Abstract] Abstract and experiments description: The claim that models 'commit fewer mistakes than the training data while retaining the ability to correct errors' is load-bearing for the hierarchical emergence result, yet lacks specification of mistake metrics, per-task breakdowns, or comparison tables; without these, it is unclear whether the result holds uniformly across the 9 tasks or depends on particular synthetic generation choices.
minor comments (1)
- The abstract would benefit from brief mention of model sizes, training data volumes, and exact architectures to contextualize the scaling and efficiency claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to improve clarity and transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the framework supplies usable benchmarks and transferable insights for real-world scientific annotation rests on the synthetic annotations faithfully reproducing human strategies (exploration, correction, strategic decisions). No quantitative alignment checks against real expert traces (e.g., click logs, error distributions, or phase transitions from actual annotation sessions) are reported, so reported phenomena such as hierarchical emergence and the shared mistake representation risk being artifacts of the generator rather than generalizable findings.
Authors: We agree that the absence of quantitative alignment with real expert traces is a limitation for claims of direct transferability. The manuscript intentionally uses a fully synthetic setup to enable controlled, reproducible experiments that isolate specific behaviors (e.g., exploration, correction) across the nine tasks. We will revise the abstract and add an explicit limitations subsection clarifying that all reported phenomena are demonstrated within the synthetic generator and that future work is needed to validate against real annotation logs. This positions the contribution as establishing systematic benchmarks rather than claiming immediate generalizability. revision: yes
-
Referee: [Abstract] Abstract and experiments description: The claim that models 'commit fewer mistakes than the training data while retaining the ability to correct errors' is load-bearing for the hierarchical emergence result, yet lacks specification of mistake metrics, per-task breakdowns, or comparison tables; without these, it is unclear whether the result holds uniformly across the 9 tasks or depends on particular synthetic generation choices.
Authors: We will expand the experiments section (and associated figures/tables) to define the mistake metric explicitly, provide per-task breakdowns of mistake rates for both training data and model outputs, and include direct comparison tables. These additions will demonstrate that the reduction in mistakes while preserving correction ability holds across the task suite and is not an artifact of any single generator choice. revision: yes
Circularity Check
No circularity: empirical study with direct experimental outcomes
full rationale
The paper is an empirical investigation of behavioral cloning on 9 synthetic annotation tasks. It reports experimental findings on skill emergence, scaling, transfer, and internal representations without any mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations. All claims trace to direct results from the described synthetic setup rather than reducing to inputs by construction. The synthetic task design is an explicit modeling choice whose fidelity is an external validity question, not a circularity issue.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
OpenVLA: An Open-Source Vision-Language-Action Model , author=. 2024 , eprint=
2024
-
[2]
2023 , eprint=
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control , author=. 2023 , eprint=
2023
-
[3]
2021 , eprint=
Offline Reinforcement Learning as One Big Sequence Modeling Problem , author=. 2021 , eprint=
2021
-
[4]
2021 , eprint=
Decision Transformer: Reinforcement Learning via Sequence Modeling , author=. 2021 , eprint=
2021
-
[5]
2022 , eprint=
A Generalist Agent , author=. 2022 , eprint=
2022
-
[6]
2022 , eprint=
Flamingo: a Visual Language Model for Few-Shot Learning , author=. 2022 , eprint=
2022
-
[7]
2023 , eprint=
Visual Instruction Tuning , author=. 2023 , eprint=
2023
-
[8]
2024 , eprint=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. 2024 , eprint=
2024
-
[9]
2024 , eprint=
SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents , author=. 2024 , eprint=
2024
-
[10]
Nature methods , volume=
High-precision automated reconstruction of neurons with flood-filling networks , author=. Nature methods , volume=. 2018 , publisher=
2018
-
[11]
Advances in Neural Information Processing Systems , volume=
Video pretraining (vpt): Learning to act by watching unlabeled online videos , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[13]
2024 , eprint=
Vision Transformers Need Registers , author=. 2024 , eprint=
2024
-
[14]
2024 , eprint=
DINOv2: Learning Robust Visual Features without Supervision , author=. 2024 , eprint=
2024
-
[15]
2017 , eprint=
Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints , author=. 2017 , eprint=
2017
-
[16]
2024 , eprint=
The Quantization Model of Neural Scaling , author=. 2024 , eprint=
2024
-
[17]
2025 , eprint=
Hidden Breakthroughs in Language Model Training , author=. 2025 , eprint=
2025
-
[18]
2025 , eprint=
Hidden in plain sight: VLMs overlook their visual representations , author=. 2025 , eprint=
2025
-
[19]
2025 , eprint=
Just-in-time and distributed task representations in language models , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
Simple Mechanistic Explanations for Out-Of-Context Reasoning , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
Belief Dynamics Reveal the Dual Nature of In-Context Learning and Activation Steering , author=. 2025 , eprint=
2025
-
[22]
Neural computation , volume=
Long short-term memory , author=. Neural computation , volume=. 1997 , publisher=
1997
-
[23]
2024 , eprint=
Titans: Learning to Memorize at Test Time , author=. 2024 , eprint=
2024
-
[24]
2025 , eprint=
Gated Delta Networks: Improving Mamba2 with Delta Rule , author=. 2025 , eprint=
2025
-
[25]
2021 , eprint=
Linear Transformers Are Secretly Fast Weight Programmers , author=. 2021 , eprint=
2021
-
[26]
2025 , eprint=
Text-to-LoRA: Instant Transformer Adaption , author=. 2025 , eprint=
2025
-
[27]
2024 , eprint=
Generative Adapter: Contextualizing Language Models in Parameters with A Single Forward Pass , author=. 2024 , eprint=
2024
-
[28]
2025 , eprint=
Self-Adapting Language Models , author=. 2025 , eprint=
2025
-
[29]
2019 , eprint=
Critical Learning Periods in Deep Neural Networks , author=. 2019 , eprint=
2019
-
[30]
2024 , eprint=
Maintaining Plasticity in Deep Continual Learning , author=. 2024 , eprint=
2024
-
[31]
2025 , eprint=
Training Dynamics Underlying Language Model Scaling Laws: Loss Deceleration and Zero-Sum Learning , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
Transformers represent belief state geometry in their residual stream , author=. 2025 , eprint=
2025
-
[33]
2024 , eprint=
Sparse Autoencoders Reveal Temporal Difference Learning in Large Language Models , author=. 2024 , eprint=
2024
-
[34]
2025 , eprint=
Priors in Time: Missing Inductive Biases for Language Model Interpretability , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
What Has a Foundation Model Found? Using Inductive Bias to Probe for World Models , author=. 2025 , eprint=
2025
-
[36]
2016 , eprint=
Group Equivariant Convolutional Networks , author=. 2016 , eprint=
2016
-
[37]
2021 , eprint=
General E(2) -Equivariant Steerable CNNs , author=. 2021 , eprint=
2021
-
[38]
Distill , year =
Olah, Chris and Mordvintsev, Alexander and Schubert, Ludwig , title =. Distill , year =
-
[39]
2024 , eprint=
What needs to go right for an induction head? A mechanistic study of in-context learning circuits and their formation , author=. 2024 , eprint=
2024
-
[40]
2021 , eprint=
Muppet: Massive Multi-task Representations with Pre-Finetuning , author=. 2021 , eprint=
2021
-
[41]
Machine learning , volume=
Multitask learning , author=. Machine learning , volume=. 1997 , publisher=
1997
-
[42]
Psychology of learning and motivation , volume=
Catastrophic interference in connectionist networks: The sequential learning problem , author=. Psychology of learning and motivation , volume=. 1989 , publisher=
1989
-
[43]
ArXiv e-prints, abs/2305.13673, May , year=
Physics of language models: Part 1, learning hierarchical language structures , author=. ArXiv e-prints, abs/2305.13673, May , year=
-
[44]
2021 , eprint=
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges , author=. 2021 , eprint=
2021
-
[45]
2025 , eprint=
Steering Out-of-Distribution Generalization with Concept Ablation Fine-Tuning , author=. 2025 , eprint=
2025
-
[46]
2025 , eprint=
On the generalization of language models from in-context learning and finetuning: a controlled study , author=. 2025 , eprint=
2025
-
[47]
2025 , eprint=
Task Diversity Shortens the ICL Plateau , author=. 2025 , eprint=
2025
-
[48]
Kirkpatrick, James and Pascanu, Razvan and Rabinowitz, Neil and Veness, Joel and Desjardins, Guillaume and Rusu, Andrei A. and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , year=. Overcoming catastrophic forgetting in neural networks , vol...
-
[49]
2023 , eprint=
Progress measures for grokking via mechanistic interpretability , author=. 2023 , eprint=
2023
-
[50]
2025 , eprint=
Questioning Representational Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis , author=. 2025 , eprint=
2025
-
[51]
2022 , eprint=
Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution , author=. 2022 , eprint=
2022
-
[52]
2025 , eprint=
The Geometry of Self-Verification in a Task-Specific Reasoning Model , author=. 2025 , eprint=
2025
-
[53]
2016 , eprint=
Convergent Learning: Do different neural networks learn the same representations? , author=. 2016 , eprint=
2016
-
[54]
Distill , year =
Olah, Chris and Satyanarayan, Arvind and Johnson, Ian and Carter, Shan and Schubert, Ludwig and Ye, Katherine and Mordvintsev, Alexander , title =. Distill , year =
-
[55]
Goodfire Research , year =
Pearce, Michael and Simon, Elana and Byun, Michael and Balsam, Daniel , title =. Goodfire Research , year =
-
[56]
2024 , journal=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , journal=
2024
-
[57]
2023 , eprint=
Faith and Fate: Limits of Transformers on Compositionality , author=. 2023 , eprint=
2023
-
[58]
2025 , eprint=
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity , author=. 2025 , eprint=
2025
-
[59]
2018 , eprint=
Understanding intermediate layers using linear classifier probes , author=. 2018 , eprint=
2018
-
[60]
GeoNames – All Cities with a Population > 1000 , author =
-
[61]
2024 , eprint=
Eureka-Moments in Transformers: Multi-Step Tasks Reveal Softmax Induced Optimization Problems , author=. 2024 , eprint=
2024
-
[62]
2025 , eprint=
What Happens During the Loss Plateau? Understanding Abrupt Learning in Transformers , author=. 2025 , eprint=
2025
-
[63]
2020 , eprint=
The Pitfalls of Simplicity Bias in Neural Networks , author=. 2020 , eprint=
2020
-
[64]
2025 , eprint=
The pitfalls of next-token prediction , author=. 2025 , eprint=
2025
-
[65]
2022 , eprint=
Data Distributional Properties Drive Emergent In-Context Learning in Transformers , author=. 2022 , eprint=
2022
-
[66]
2025 , eprint=
Analyzing (In)Abilities of SAEs via Formal Languages , author=. 2025 , eprint=
2025
-
[67]
2025 , eprint=
Projecting Assumptions: The Duality Between Sparse Autoencoders and Concept Geometry , author=. 2025 , eprint=
2025
-
[68]
2025 , eprint=
In-Context Learning Strategies Emerge Rationally , author=. 2025 , eprint=
2025
-
[69]
arXiv preprint arXiv:2309.14316 , year=
Physics of language models: Part 3.1, knowledge storage and extraction , author=. arXiv preprint arXiv:2309.14316 , year=
-
[70]
Advances in Neural Information Processing Systems , volume=
Transformers are uninterpretable with myopic methods: a case study with bounded Dyck grammars , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
arXiv preprint arXiv:2210.10749 , year=
Transformers learn shortcuts to automata , author=. arXiv preprint arXiv:2210.10749 , year=
-
[72]
arXiv preprint arXiv:2412.04619 , year=
Sometimes I am a Tree: Data Drives Unstable Hierarchical Generalization , author=. arXiv preprint arXiv:2412.04619 , year=
-
[73]
, author=
Compression in visual working memory: using statistical regularities to form more efficient memory representations. , author=. Journal of Experimental Psychology: General , volume=. 2009 , publisher=
2009
-
[74]
, author=
Conceptual role semantics. , author=. Notre Dame Journal of Formal Logic , volume=. 1982 , publisher=
1982
-
[75]
Routledge encyclopedia of philosophy , volume=
Semantics, conceptual role , author=. Routledge encyclopedia of philosophy , volume=. 1998 , publisher=
1998
-
[76]
arXiv preprint arXiv:2410.17194 , year=
Representation Shattering in Transformers: A Synthetic Study with Knowledge Editing , author=. arXiv preprint arXiv:2410.17194 , year=
-
[77]
arXiv preprint arXiv:2402.07757 , year=
Towards an Understanding of Stepwise Inference in Transformers: A Synthetic Graph Navigation Model , author=. arXiv preprint arXiv:2402.07757 , year=
-
[78]
arXiv preprint arXiv:2412.01003 , year=
Competition Dynamics Shape Algorithmic Phases of In-Context Learning , author=. arXiv preprint arXiv:2412.01003 , year=
-
[79]
arXiv preprint arXiv:2309.05858 , year=
Uncovering mesa-optimization algorithms in transformers , author=. arXiv preprint arXiv:2309.05858 , year=
-
[80]
International Conference on Machine Learning , pages=
Transformers learn in-context by gradient descent , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.