AVI-Bench: Toward Human-like Audio-Visual Intelligence of Omni-MLLMs
Pith reviewed 2026-06-28 14:34 UTC · model grok-4.3
The pith
Omni-MLLMs exhibit substantial limitations in audio-visual intelligence when tested on a new three-stage cross-modal benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
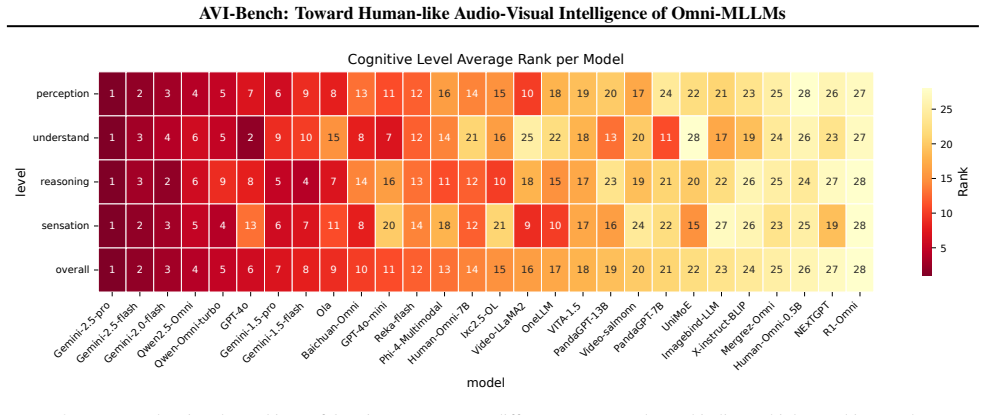
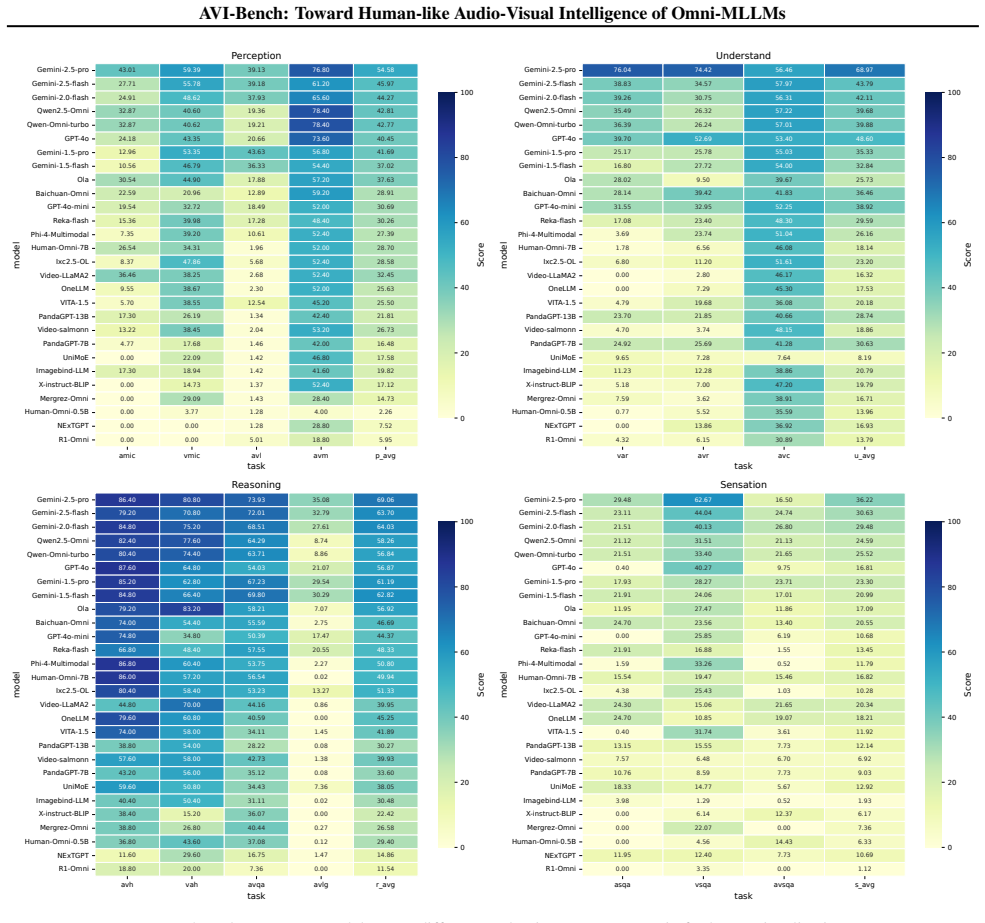
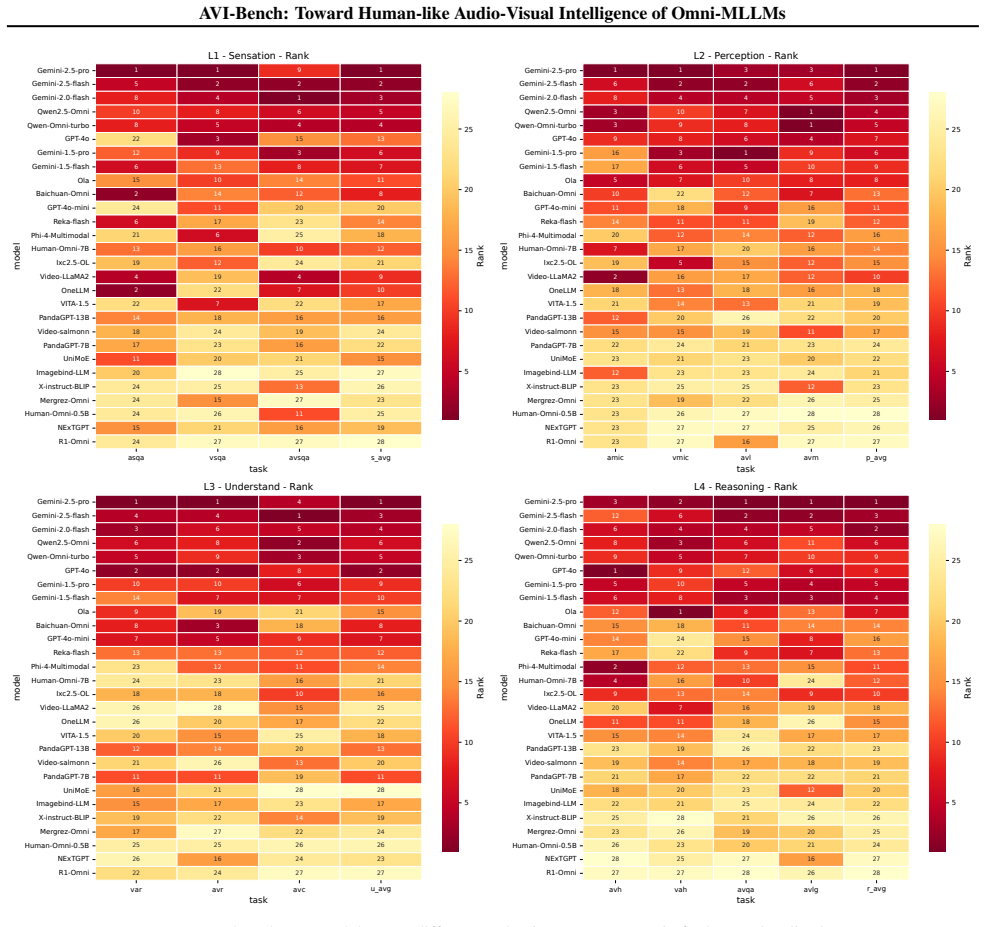
The paper claims that current Omni-MLLMs lack robust audio-visual intelligence, as shown by their performance on AVI-Bench which measures joint audio-visual interpretation through staged cross-modal tasks and on AVI-Bench-PriSe which tests primitive sensation with unfamiliar stimuli, leading directly to the definition of a four-level AVI taxonomy that classifies model capabilities and gaps.
What carries the argument
AVI-Bench, a cognitively inspired benchmark that structures evaluation into three stages of cross-modal tasks plus an extension for primitive unfamiliar stimuli.
If this is right
- Models must improve joint audio-visual processing at the reasoning stage rather than relying on unimodal strengths.
- Performance drops sharply on unfamiliar stimuli, indicating that current training leaves models vulnerable to distribution shifts.
- The four-level taxonomy supplies a concrete scale for tracking progress toward more integrated audio-visual capabilities.
- Fine-grained stage-wise results allow targeted diagnosis of whether failures occur at perception, understanding, or reasoning.
Where Pith is reading between the lines
- The benchmark could be adapted to measure whether improvements in one stage transfer to others without retraining the entire model.
- Using low-semantic stimuli to test primitive sensation might help separate memorized patterns from genuine cross-modal binding in other multimodal settings.
- If future models close the gaps identified here, applications that depend on simultaneous sound and image understanding, such as scene analysis in video, would become more reliable.
- The taxonomy offers a possible shared vocabulary for comparing audio-visual progress across different model families without relying solely on task accuracy numbers.
Load-bearing premise
The selected cross-modal tasks and unfamiliar stimuli accurately stand in for human-like audio-visual intelligence and generalization outside training data.
What would settle it
If a range of Omni-MLLMs achieve high accuracy across all three stages and the primitive-stimulus extension yet continue to fail on everyday audio-visual tasks that humans handle easily, or if humans score low on the same benchmark items, the claim that the benchmark diagnoses meaningful limitations would be undermined.
Figures


read the original abstract
Recent advances in Omni-Multimodal Large Language Models (Omni-MLLMs) have enabled strong integration of vision, audio, and language. However, their audio-visual intelligence (AVI) remains insufficiently evaluated due to the lack of systematic and comprehensive benchmarks. We introduce AVI-Bench, a cognitively inspired benchmark that evaluates Omni-MLLMs across three stages, perception, understanding, and reasoning, through cross-modal tasks requiring joint audio-visual interpretation. This design enables fine-grained diagnosis of model capabilities and failure modes. To further assess robustness beyond familiar domains, we propose AVI-Bench-PriSe, an extension that probes models' primitive audio-visual sensation using unfamiliar, low-semantic stimuli, testing generalization beyond common training distributions. Extensive experiments on both open-source and closed-source models reveal substantial limitations in current Omni-MLLMs. Based on these findings, we present a four-level AVI taxonomy. Overall, AVI-Bench provides a principled evaluation framework to guide the development of more robust and generalizable AVI. Project website: https://fudancvl.github.io/AVI-Bench/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce AVI-Bench, a cognitively inspired benchmark evaluating Omni-MLLMs on audio-visual intelligence through three stages of perception, understanding, and reasoning using cross-modal tasks. It further proposes AVI-Bench-PriSe to probe primitive sensation with unfamiliar stimuli, reports extensive experiments showing substantial limitations in current models, and derives a four-level AVI taxonomy to guide future development.
Significance. If the benchmark's tasks are confirmed as appropriate proxies for human-like audio-visual intelligence and generalization, the work offers a systematic framework for diagnosing model shortcomings and a taxonomy that could inform the design of more capable Omni-MLLMs. The inclusion of both open- and closed-source models strengthens the empirical scope.
major comments (2)
- [Abstract] Abstract: The assertion that 'extensive experiments ... reveal substantial limitations' is not supported by details on task construction, scoring metrics, model selection criteria, or statistical controls, which are necessary to verify the central claim of limitations in human-like AVI.
- [Benchmark design] Benchmark design: The validity of the three-stage tasks and AVI-Bench-PriSe's unfamiliar low-semantic stimuli as proxies for human-like AVI and out-of-distribution generalization is not substantiated by human baselines, cognitive validation studies, or ablations demonstrating that model failures reflect capability gaps rather than benchmark artifacts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of clarity and validation. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'extensive experiments ... reveal substantial limitations' is not supported by details on task construction, scoring metrics, model selection criteria, or statistical controls, which are necessary to verify the central claim of limitations in human-like AVI.
Authors: The abstract is a concise summary; the full manuscript details task construction in Section 3, scoring metrics in Section 4.2, model selection criteria in Section 5.1, and statistical controls in Section 5.3 with results across models. These sections directly support the reported limitations. We will revise the abstract to include a brief reference to the evaluation framework for improved standalone readability. revision: partial
-
Referee: [Benchmark design] Benchmark design: The validity of the three-stage tasks and AVI-Bench-PriSe's unfamiliar low-semantic stimuli as proxies for human-like AVI and out-of-distribution generalization is not substantiated by human baselines, cognitive validation studies, or ablations demonstrating that model failures reflect capability gaps rather than benchmark artifacts.
Authors: The three-stage structure and AVI-Bench-PriSe draw directly from cognitive models of audio-visual processing, as described in Sections 2 and 3, with low-semantic stimuli chosen to probe generalization beyond training distributions. Consistent failure patterns across open- and closed-source models indicate capability gaps. We acknowledge the value of human baselines and will add further ablations (e.g., stimulus variation tests) in revision to strengthen artifact exclusion, while noting that full human validation studies fall outside the current model-focused scope. revision: partial
Circularity Check
No significant circularity; external benchmark framework
full rationale
The paper introduces AVI-Bench as an independent evaluation framework with three stages (perception/understanding/reasoning) and the PriSe extension using unfamiliar stimuli; no equations, fitted parameters, self-referential predictions, or derivation chains are present. Claims of model limitations rest on experimental application of this benchmark rather than any reduction to its own inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are quoted or evident. The structure is a standard benchmark paper whose central evaluation is self-contained against external model testing.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[2]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[3]
arXiv preprint arXiv:2403.05530 , year=
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
-
[4]
2023 , eprint=
LLaMA: Open and Efficient Foundation Language Models , author=. 2023 , eprint=
2023
-
[5]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[6]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[7]
2023 , eprint=
Qwen Technical Report , author=. 2023 , eprint=
2023
-
[8]
Qwen2. 5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[9]
arXiv preprint arXiv:2409.12191 , year=
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
-
[10]
arXiv preprint arXiv:2304.10592 , year=
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
-
[11]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[12]
2023 , url =
GPT-4V(ision) System Card , author =. 2023 , url =
2023
-
[13]
Advances in Neural Information Processing Systems , volume=
Pengi: An audio language model for audio tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:2504.18425 , year=
Kimi-Audio Technical Report , author=. arXiv preprint arXiv:2504.18425 , year=
-
[15]
arXiv preprint arXiv:2407.10759 , year=
Qwen2-audio technical report , author=. arXiv preprint arXiv:2407.10759 , year=
-
[16]
arXiv preprint arXiv:2305.11000 , year=
Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities , author=. arXiv preprint arXiv:2305.11000 , year=
-
[17]
arXiv preprint arXiv:2305.16355 , year=
Pandagpt: One model to instruction-follow them all , author=. arXiv preprint arXiv:2305.16355 , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Forty-first International Conference on Machine Learning , year=
Next-gpt: Any-to-any multimodal llm , author=. Forty-first International Conference on Machine Learning , year=
-
[20]
arXiv preprint arXiv:2402.12226 , year=
Anygpt: Unified multimodal llm with discrete sequence modeling , author=. arXiv preprint arXiv:2402.12226 , year=
-
[21]
arXiv preprint arXiv:2306.02858 , year=
Video-llama: An instruction-tuned audio-visual language model for video understanding , author=. arXiv preprint arXiv:2306.02858 , year=
-
[22]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[23]
arXiv preprint arXiv:2410.18325 , year=
AVHBench: A Cross-Modal Hallucination Benchmark for Audio-Visual Large Language Models , author=. arXiv preprint arXiv:2410.18325 , year=
-
[24]
2025 , eprint=
AVTrustBench: Assessing and Enhancing Reliability and Robustness in Audio-Visual LLMs , author=. 2025 , eprint=
2025
-
[25]
2023 , eprint=
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension , author=. 2023 , eprint=
2023
-
[26]
2024 , eprint=
AV-Odyssey Bench: Can Your Multimodal LLMs Really Understand Audio-Visual Information? , author=. 2024 , eprint=
2024
-
[27]
arXiv preprint arXiv:2501.15111 , year=
HumanOmni: A Large Vision-Speech Language Model for Human-Centric Video Understanding , author=. arXiv preprint arXiv:2501.15111 , year=
-
[28]
arXiv preprint arXiv:2410.08565 , year=
baichuan-omni: To Understand the World with Omni-modality , author=. arXiv preprint arXiv:2410.08565 , year=
-
[29]
5-omni technical report , author=
Qwen2. 5-omni technical report , author=. arXiv preprint arXiv:2503.20215 , year=
-
[30]
2024 , eprint=
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models , author=. 2024 , eprint=
2024
-
[31]
2025 , eprint=
OmniBench: Towards The Future of Universal Omni-Language Models , author=. 2025 , eprint=
2025
-
[32]
arXiv preprint arXiv:2410.12219 , year=
Omnixr: Evaluating omni-modality language models on reasoning across modalities , author=. arXiv preprint arXiv:2410.12219 , year=
-
[33]
Yang, Pinci and Wang, Xin and Duan, Xuguang and Chen, Hong and Hou, Runze and Jin, Cong and Zhu, Wenwu , title =. 2022 , isbn =. doi:10.1145/3503161.3548291 , booktitle =
-
[34]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Learning to Answer Questions in Dynamic Audio-Visual Scenarios , author =. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[35]
arXiv preprint arXiv:2405.03272 , year=
Worldqa: Multimodal world knowledge in videos through long-chain reasoning , author=. arXiv preprint arXiv:2405.03272 , year=
-
[36]
arXiv preprint arXiv:2503.12605 , year=
Multimodal chain-of-thought reasoning: A comprehensive survey , author=. arXiv preprint arXiv:2503.12605 , year=
-
[37]
Journal of Artificial General Intelligence , volume=
Artificial general intelligence: concept, state of the art, and future prospects , author=. Journal of Artificial General Intelligence , volume=. 2014 , publisher=
2014
-
[38]
Nature Communications , volume=
Towards artificial general intelligence via a multimodal foundation model , author=. Nature Communications , volume=. 2022 , publisher=
2022
-
[39]
2023 , publisher=
Sparks of artificial general intelligence: Early experiments with gpt-4 , author=. 2023 , publisher=
2023
-
[40]
2007 , publisher=
Artificial general intelligence , author=. 2007 , publisher=
2007
-
[41]
Advances in neural information processing systems , volume=
Superglue: A stickier benchmark for general-purpose language understanding systems , author=. Advances in neural information processing systems , volume=
-
[42]
Forty-first International Conference on Machine Learning , year=
Chatbot arena: An open platform for evaluating llms by human preference , author=. Forty-first International Conference on Machine Learning , year=
-
[43]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[44]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[45]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[46]
Proceedings of the European conference on computer vision (ECCV) , pages=
Audio-visual event localization in unconstrained videos , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[47]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Localizing visual sounds the hard way , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[48]
European Conference on Computer Vision , pages=
Audio--visual segmentation , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[49]
European Conference on Computer Vision , pages=
Ref-avs: Refer and segment objects in audio-visual scenes , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[50]
Nature reviews neuroscience , volume=
Multisensory integration: current issues from the perspective of the single neuron , author=. Nature reviews neuroscience , volume=. 2008 , publisher=
2008
-
[51]
The Auditory Cortex - Neuroscience - NCBI Bookshelf , author=
-
[52]
The Visual Cortex - Neuroscience - NCBI Bookshelf , author=
-
[53]
Annual review of vision science , volume=
The organization and operation of inferior temporal cortex , author=. Annual review of vision science , volume=. 2018 , publisher=
2018
-
[54]
Current Biology , volume=
Multimodal spatial representations engaged in human parietal cortex during both saccadic and manual spatial orienting , author=. Current Biology , volume=. 2003 , publisher=
2003
-
[55]
Neuropsychopharmacology , volume=
The role of prefrontal cortex in cognitive control and executive function , author=. Neuropsychopharmacology , volume=. 2022 , publisher=
2022
-
[56]
IEEE Open Journal of Signal Processing , year=
AVCaps: An Audio-visual Dataset with Modality-specific Captions , author=. IEEE Open Journal of Signal Processing , year=
-
[57]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Valor: Vision-audio-language omni-perception pretraining model and dataset , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[58]
arXiv preprint arXiv:2502.04328 , year=
Ola: Pushing the Frontiers of Omni-Modal Language Model with Progressive Modality Alignment , author=. arXiv preprint arXiv:2502.04328 , year=
-
[59]
arXiv preprint arXiv:2501.15368 , year=
Baichuan-Omni-1.5 Technical Report , author=. arXiv preprint arXiv:2501.15368 , year=
-
[60]
arXiv preprint arXiv:2503.05379 , year=
R1-omni: Explainable omni-multimodal emotion recognition with reinforcement learning , author=. arXiv preprint arXiv:2503.05379 , year=
-
[61]
arXiv preprint arXiv:2503.01743 , year=
Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras , author=. arXiv preprint arXiv:2503.01743 , year=
-
[62]
arXiv preprint arXiv:2505.04921 , year=
Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models , author=. arXiv preprint arXiv:2505.04921 , year=
-
[63]
arXiv preprint arXiv:2505.04620 , year=
On Path to Multimodal Generalist: General-Level and General-Bench , author=. arXiv preprint arXiv:2505.04620 , year=
-
[64]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[65]
arXiv preprint arXiv:2307.16125 , year=
Seed-bench: Benchmarking multimodal llms with generative comprehension , author=. arXiv preprint arXiv:2307.16125 , year=
-
[66]
arXiv preprint arXiv:2410.19168 , year=
Mmau: A massive multi-task audio understanding and reasoning benchmark , author=. arXiv preprint arXiv:2410.19168 , year=
-
[67]
European Conference on Computer Vision , pages=
Audio-visual mismatch-aware video retrieval via association and adjustment , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[68]
European Conference on Computer Vision , pages=
Localizing visual sounds the easy way , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[69]
IEEE Access , volume=
A survey of audio classification using deep learning , author=. IEEE Access , volume=. 2023 , publisher=
2023
-
[70]
Advances in neural information processing systems , volume=
Unsupervised feature learning for audio classification using convolutional deep belief networks , author=. Advances in neural information processing systems , volume=
-
[71]
International journal of Remote sensing , volume=
A survey of image classification methods and techniques for improving classification performance , author=. International journal of Remote sensing , volume=. 2007 , publisher=
2007
-
[72]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
I2mvformer: Large language model generated multi-view document supervision for zero-shot image classification , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[73]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
What does a platypus look like? generating customized prompts for zero-shot image classification , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[74]
ACM Transactions on Multimedia Computing, Communications and Applications , volume=
Variational autoencoder with cca for audio--visual cross-modal retrieval , author=. ACM Transactions on Multimedia Computing, Communications and Applications , volume=. 2023 , publisher=
2023
-
[75]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Pano-avqa: Grounded audio-visual question answering on 360deg videos , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[76]
Wang, Yaoting and Liu, Weisong and Li, Guangyao and Ding, Jian and Hu, Di and Li, Xi , title =. 2024 , isbn =. doi:10.1609/aaai.v38i6.28378 , booktitle =
-
[77]
European Conference on Computer Vision , pages=
Can Textual Semantics Mitigate Sounding Object Segmentation Preference? , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[78]
arXiv preprint arXiv:2406.12793 , year=
Chatglm: A family of large language models from glm-130b to glm-4 all tools , author=. arXiv preprint arXiv:2406.12793 , year=
-
[79]
arXiv preprint arXiv:2502.00358 , year=
Do Audio-Visual Segmentation Models Truly Segment Sounding Objects? , author=. arXiv preprint arXiv:2502.00358 , year=
-
[80]
arXiv preprint arXiv:2407.00634 , year=
Tarsier: Recipes for training and evaluating large video description models , author=. arXiv preprint arXiv:2407.00634 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.