Flow Control: Steering Vision-Language-Action Models with Simple Real-Time Inputs
Pith reviewed 2026-06-27 16:00 UTC · model grok-4.3
The pith
Flow control steers vision-language-action robot models in real time with simple inputs like a keyboard without any retraining or model changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Flow control converts simple user inputs into action samples from the VLA expert action distribution. This produces robot actions that are high quality because they conform to the distribution learned during training and high fidelity because they align with the user's intent. The method works without retraining the VLA and yields accurate responsive steering that is robust to imperfect user inputs, resulting in significantly higher task success rates and faster completion times. Collecting trajectories under flow control and fine-tuning the VLA on them improves the autonomous policy.
What carries the argument
Flow control, the mapping of generic user inputs to samples from the VLA's expert action distribution.
If this is right
- Flow control accurately and responsively steers robot actions with user inputs.
- It remains robust even when user inputs are suboptimal.
- It produces significantly higher success rates and faster task completion.
- Fine-tuning a VLA on trajectories generated under flow control improves the autonomous policy.
Where Pith is reading between the lines
- The same input-to-distribution mapping could be applied to other low-dimensional interfaces such as joysticks or touchscreens.
- Flow control offers a lightweight way to collect high-quality human-corrected data for policy improvement without changing model architecture.
- Real-time steering may reduce the need for full autonomy in safety-critical or novel environments by letting users supply corrections on the fly.
- If the mapping step generalizes across tasks, flow control could serve as a standard interface layer between humans and any pretrained VLA.
Load-bearing premise
Simple user inputs can be transformed into samples from the VLA expert distribution without degrading action quality and while matching user intent.
What would settle it
A controlled experiment in which steering with flow control produces no measurable increase in task success rate or reduction in completion time compared with the unsteered VLA.
Figures

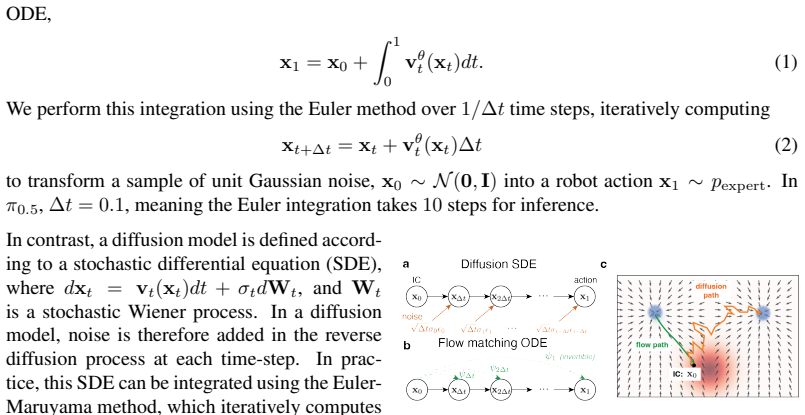
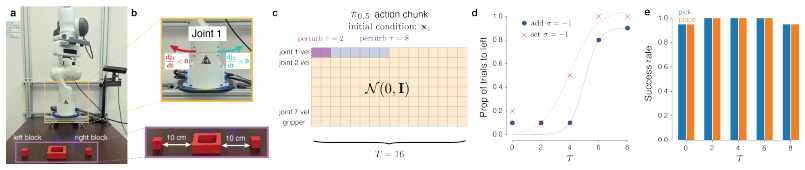



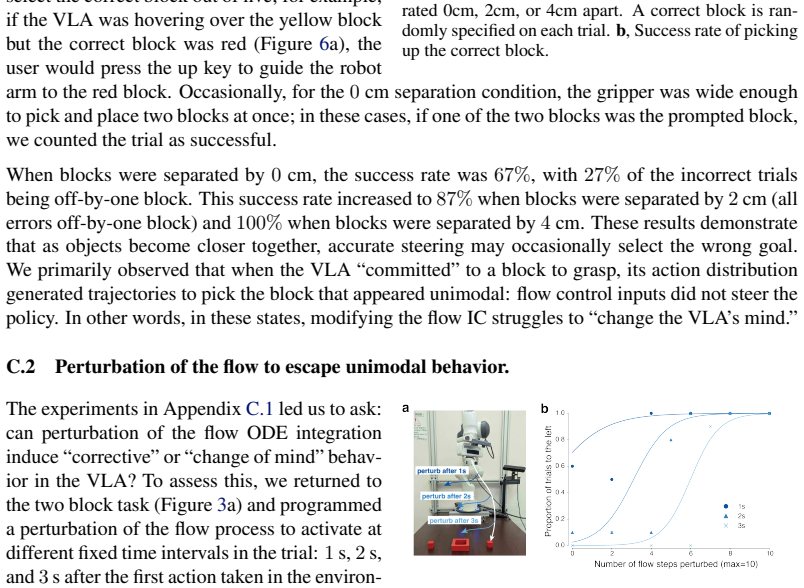
read the original abstract
We introduce flow control of vision-language-action (VLA) models, a simple and effective way to steer VLA actions in real-time through generic inputs, such as a keyboard. This method can be used out-of-the-box and does not require retraining or fine-tuning VLAs. It enables relatively crude user inputs to steer a VLA to align with user intent. The VLA transforms these inputs into action samples drawn from the VLA expert action distribution learned during training, so that the generated actions are high quality (conformity to the action expert distribution) and high fidelity (reflecting the user's intent). We demonstrate that flow control has many desirable properties: (1) flow control accurately and responsively steers robot actions with user inputs, (2) it is robust to suboptimal user inputs, (3) it enables users to steer VLAs to achieve significantly higher success rates and faster task completion, and (4) fine-tuning a VLA on flow control trajectories improves the autonomous policy. Together, these results provide a simple and intuitive way for users to help steer VLA actions, increasing task performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces flow control, an inference-time procedure for steering pretrained vision-language-action (VLA) models using generic real-time inputs such as keyboard commands. The approach injects the user signal directly into the flow-matching or diffusion sampling process to produce actions drawn from the VLA's expert distribution while remaining faithful to user intent. Experiments across multiple robot tasks report improved success rates, faster completion times, robustness to noisy or suboptimal inputs, and additional gains when the VLA is subsequently fine-tuned on trajectories generated under flow control.
Significance. If the empirical claims hold, the work supplies a practical, model-agnostic mechanism for incorporating human guidance into deployed VLAs without architectural modification or retraining. The reported performance improvements and the downstream fine-tuning benefit constitute concrete, falsifiable contributions. The emphasis on preserving conformity to the expert distribution while accommodating crude inputs addresses a recurring deployment challenge in robotics.
minor comments (3)
- [§3] The abstract and §3 would benefit from an explicit statement of the precise mathematical form in which the user input is injected into the flow or diffusion step (e.g., the modified velocity field or noise schedule).
- [Figure 4] Figure 4 caption should clarify whether the plotted trajectories are single-rollout examples or aggregated statistics; the current wording leaves the reader uncertain about variance across seeds.
- [§5.3] The fine-tuning experiment in §5.3 reports success-rate gains but does not state the number of flow-control trajectories used or the number of gradient steps; these details are needed to assess data efficiency.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. No specific major comments were provided in the report, so we have no points to address point-by-point at this time. We remain available to incorporate any minor suggestions during revision.
Circularity Check
No significant circularity
full rationale
The manuscript introduces an inference-time steering procedure for VLAs using generic real-time inputs (e.g., keyboard) mapped into the model's expert action distribution. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described method. Claims rest on experimental results across robot tasks (success rates, task completion time, robustness to noisy inputs, and downstream fine-tuning gains). The approach is presented as model-agnostic at inference time with ablations addressing robustness, rendering the central claims self-contained against external benchmarks rather than reducing to definitional or fitted inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control.arXiv [cs.LG], Oct. 2024
2024
-
[2]
Intelligence, K
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
2025
-
[3]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Mordatch, K. Pe...
2023
-
[4]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. PaLM-E: An embodied multimodal language model.arXiv [cs.LG], Mar. 2023
2023
-
[5]
A. Szot, B. Mazoure, O. Attia, A. Timofeev, H. Agrawal, D. Hjelm, Z. Gan, Z. Kira, and A. Toshev. From multimodal LLMs to generalist embodied agents: Methods and lessons. arXiv [cs.LG], Dec. 2024
2024
-
[6]
Abeyruwan, J
Gemini Robotics Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Arm- strong, A. Balakrishna, R. Baruch, M. Bauza, M. Blokzijl, S. Bohez, K. Bousmalis, A. Bro- han, T. Buschmann, A. Byravan, S. Cabi, K. Caluwaerts, F. Casarini, O. Chang, J. E. Chen, X. Chen, H.-T. L. Chiang, K. Choromanski, D. D’Ambrosio, S. Dasari, T. Davchev, C. Devin, N....
2025
-
[7]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model.arXiv [cs.RO], June 2024
2024
-
[8]
Intelligence, B
P. Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokin- sky, S. Cao, T. Charbonnier, V . Choudhary, F. Collins, K. Conley, G. Connors, J. Darpinian, 10 K. Dhabalia, M. Dhaka, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glos- sop, T. Godden, I. Goryachev, L. Groom, H. Habeeb, H. Hancock, K. Hausman, G...
2026
-
[9]
Z. Chen, A. Tian, L. Wang, B. Joffe, Y . C. Lin, Y . Chen, S. Karamcheti, and D. Xu. ReSteer: Quantifying and refining the steerability of multitask robot policies.arXiv [cs.RO], Mar. 2026
2026
-
[10]
J. Gao, S. Belkhale, S. Dasari, A. Balakrishna, D. Shah, and D. Sadigh. A taxonomy for evaluating generalist robot manipulation policies.arXiv [cs.RO], Mar. 2025
2025
-
[11]
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, W. Han, W. Pumacay, A. Wu, R. Hendrix, K. Farley, E. VanderBilt, A. Farhadi, D. Fox, and R. Krishna. MolmoAct: Action reasoning models that can reason in space.arXiv [cs.RO], Aug. 2025
2025
-
[12]
S. Ross, G. J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning.arXiv [cs.LG], Nov. 2010
2010
-
[13]
L. X. Shi, B. Ichter, M. Equi, L. Ke, K. Pertsch, Q. Vuong, J. Tanner, A. Walling, H. Wang, N. Fusai, A. Li-Bell, D. Driess, L. Groom, S. Levine, and C. Finn. Hi robot: Open-ended instruction following with hierarchical vision-language-action models.arXiv [cs.RO], Feb. 2025
2025
-
[14]
Belkhale, T
S. Belkhale, T. Ding, T. Xiao, P. Sermanet, Q. Vuong, J. Tompson, Y . Chebotar, D. Dwibedi, and D. Sadigh. RT-H: Action hierarchies using language. InRobotics: Science and Systems XX. Robotics: Science and Systems Foundation, July 2024
2024
-
[15]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, A. Handa, M.-Y . Liu, D. Xiang, G. Wetzstein, and T.-Y . Lin. CoT-VLA: Visual chain-of-thought reason- ing for vision-language-action models.arXiv [cs.CV], Mar. 2025
2025
-
[16]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
2023
-
[17]
B. Chen, D. M. Monso, Y . Du, M. Simchowitz, R. Tedrake, and V . Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.arXiv [cs.LG], July 2024
2024
-
[18]
L. X. Shi, Z. Hu, T. Z. Zhao, A. Sharma, K. Pertsch, J. Luo, S. Levine, and C. Finn. Yell at your robot: Improving on-the-fly from language corrections.arXiv [cs.RO], Mar. 2024
2024
-
[19]
Y . Cui, S. Karamcheti, R. Palleti, N. Shivakumar, P. Liang, and D. Sadigh. No, to the right: Online language corrections for robotic manipulation via shared autonomy. InProceedings of the 2023 ACM/IEEE International Conference on Human-Robot Interaction, pages 93–101, 2023
2023
-
[20]
Lynch, A
C. Lynch, A. Wahid, J. Tompson, T. Ding, J. Betker, R. Baruch, T. Armstrong, and P. Florence. Interactive language: Talking to robots in real time.IEEE Robot. Autom. Lett., pages 1–8, 2024
2024
-
[21]
E. Chisari, T. Welschehold, J. Boedecker, W. Burgard, and A. Valada. Correct me if i am wrong: Interactive learning for robotic manipulation.IEEE Robotics and Automation Letters, 7:3695–3702, Apr. 2022. doi:10.1109/LRA.2022.3145516. 11
-
[22]
Sundaresan, Q
P. Sundaresan, Q. Vuong, J. Gu, P. Xu, T. Xiao, S. Kirmani, T. Yu, M. Stark, A. Jain, K. Haus- man, D. Sadigh, J. Bohg, and S. Schaal. RT-sketch: Goal-conditioned imitation learning from hand-drawn sketches.arXiv [cs.RO], Mar. 2024
2024
-
[23]
J. Gu, S. Kirmani, P. Wohlhart, Y . Lu, M. G. Arenas, K. Rao, W. Yu, C. Fu, K. Gopalakrishnan, Z. Xu, P. Sundaresan, P. Xu, H. Su, K. Hausman, C. Finn, Q. Vuong, and T. Xiao. RT- trajectory: Robotic task generalization via hindsight trajectory sketches.arXiv [cs.RO], Nov. 2023
2023
-
[24]
Black, M
K. Black, M. Nakamoto, P. Atreya, H. Walke, C. Finn, A. Kumar, and S. Levine. Zero-shot robotic manipulation with pretrained image-editing diffusion models.arXiv [cs.RO], Oct. 2023
2023
-
[25]
Y . Wang, L. Wang, Y . Du, B. Sundaralingam, X. Yang, Y .-W. Chao, C. Perez-D’Arpino, D. Fox, and J. Shah. Inference-time policy steering through human interactions, 2025. URL https://arxiv.org/abs/2411.16627
arXiv 2025
-
[26]
Du and S
M. Du and S. Song. Dynaguide: Steering diffusion polices with active dynamic guidance,
-
[27]
URLhttps://arxiv.org/abs/2506.13922
-
[28]
S. Park, H. Bharadhwaj, and S. Tulsiani. Demodiffusion: One-shot human imitation using pre-trained diffusion policy, 2025. URLhttps://arxiv.org/abs/2506.20668
arXiv 2025
-
[29]
Wagenmaker, M
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning.arXiv [cs.RO], June 2025
2025
- [30]
-
[31]
A. Wang, X. Yan, B. McMahan, M. Zhou, Y . Yuan, J. Y . Lee, A. Shreif, M. Li, Z. Peng, B. Zhou, Y . Cui, and J. C. Kao. DiSCo: Diffusion sequence copilots for shared autonomy. InProceedings of the 21st ACM/IEEE International Conference on Human-Robot Interaction, pages 982–990, New York, NY , USA, Mar. 2026. ACM
2026
-
[32]
Beyer, A
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Al- abdulmohsin, M. Tschannen, E. Bugliarello, T. Unterthiner, D. Keysers, S. Koppula, F. Liu, A. Grycner, A. Gritsenko, N. Houlsby, M. Kumar, K. Rong, J. Eisenschlos, R. Kabra, M. Bauer, M. Bosnjak, X. Chen, M. Minderer, P. V oigtlaender, I. Bica, I. Balazevic, J. Puigcerv...
2024
-
[33]
Mesnard, C
Gemma Team, T. Mesnard, C. Hardin, R. Dadashi, S. Bhupatiraju, S. Pathak, L. Sifre, M. Rivi`ere, M. S. Kale, J. Love, P. Tafti, L. Hussenot, P. G. Sessa, A. Chowdhery, A. Roberts, A. Barua, A. Botev, A. Castro-Ros, A. Slone, A. H ´eliou, A. Tacchetti, A. Bulanova, A. Pater- son, B. Tsai, B. Shahriari, C. L. Lan, C. A. Choquette-Choo, C. Crepy, D. Cer, D. ...
2024
-
[34]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
2024
-
[35]
Cover and J
Thomas M. Cover and J. A. Thomas.Elements of Information Theory. John Wiley & Sons, Nashville, TN, 2 edition, Nov. 2012
2012
-
[36]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv [cs.LG], Oct. 2022
2022
-
[37]
basins-of-attraction
P. Holderrieth and E. Erives. An introduction to flow matching and diffusion models.arXiv [cs.LG], July 2025. 13 A Geometry of initial condition steering This appendix expands on intuition for why modifying the initial condition can steer the flow (Sec- tion 3.3). We emphasize that while this section provides more intuition for the steering properties, th...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.