Feature-Aligned Speech Watermarking for Robustness to Reconstruction Distortions
Pith reviewed 2026-06-27 08:25 UTC · model grok-4.3
The pith
Aligning watermarks to speech feature distributions permits higher embedding energy while preserving imperceptibility and boosting robustness against reconstruction models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
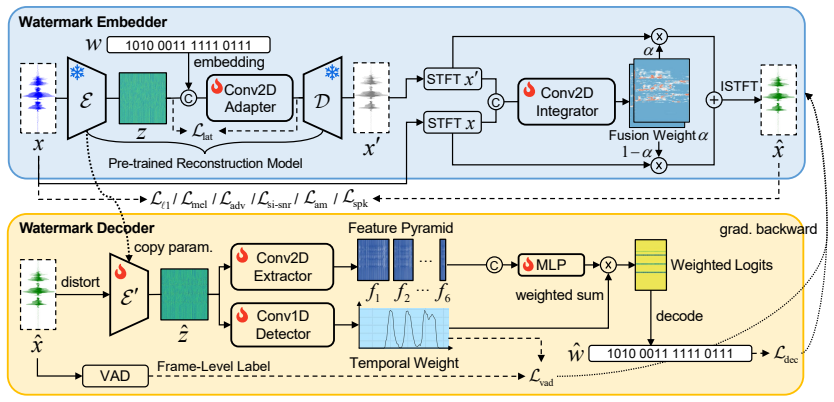
The central claim is that feature-aligned watermarking, achieved by generating a pseudo-speech watermark via a pretrained codec and embedding it into the input spectrogram guided by VAD loss and perceptual losses, aligns the watermark with the original speech feature distribution. This permits higher watermark energy that improves robustness to reconstruction distortions without reducing imperceptibility.
What carries the argument
The feature-aligned watermarking method that generates a pseudo-speech watermark from a pretrained codec and fuses it under VAD and perceptual losses to match the original speech feature distribution.
If this is right
- Imperceptibility stays comparable to existing high-fidelity watermarking approaches.
- Robustness increases substantially against both seen and unseen speech reconstruction models.
- The inherent robustness-fidelity trade-off is resolved through distribution alignment.
- Watermark detection succeeds after reconstruction attacks that remove conventional low-energy marks.
Where Pith is reading between the lines
- The same alignment idea might be tested on music or environmental audio to check whether reconstruction robustness generalizes beyond speech.
- If alignment works by mimicking natural feature statistics, one could measure how closely the generated pseudo-watermark must match the host distribution for the robustness benefit to appear.
Load-bearing premise
The method assumes that a pseudo-speech watermark created by a pretrained codec and guided by VAD and perceptual losses will align closely enough with original speech features to support higher energy without creating new perceptible artifacts.
What would settle it
Passing watermarked audio through an unseen reconstruction model and finding that watermark detection accuracy drops to the level of low-energy baseline methods would show the alignment does not deliver the claimed robustness gain.
Figures


read the original abstract
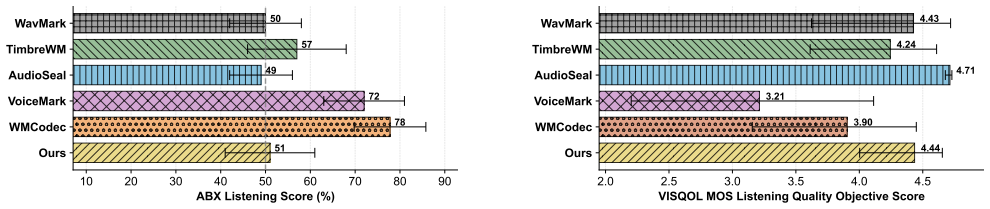
Audio watermarking aims to embed identifiable information into audio while remaining imperceptible. Existing methods adopt high-fidelity, low-energy designs to preserve perceptual quality, but the resulting watermarks lack robustness under suppression by speech reconstruction models. Improving robustness is challenging due to the inherent robustness-fidelity trade-off in existing designs, where increasing watermark energy improves robustness but reduces fidelity. To address this problem, we propose a feature-aligned watermarking method that aligns the watermark with the original speech feature distribution, allowing higher watermark energy to improve robustness while preserving imperceptibility. We use a pretrained speech codec to generate a pseudo-speech watermark and fuse it into the spectrogram of the input audio, with VAD loss and perceptual losses guiding embedding within voiced regions. Experiments show that our method maintains imperceptibility comparable to existing approaches while substantially improving robustness under both seen and unseen speech reconstruction models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a feature-aligned speech watermarking method that generates a pseudo-speech watermark via a pretrained codec and fuses it into the input audio spectrogram, guided by VAD loss and perceptual losses to align the watermark with the original speech feature distribution. This design is claimed to resolve the robustness-fidelity trade-off by permitting higher watermark energy (improving robustness to seen and unseen speech reconstruction models) while preserving imperceptibility comparable to existing low-energy methods, as asserted in the experiments.
Significance. If the central empirical claims hold with proper validation, the work would address a practical limitation in audio watermarking for robustness against reconstruction distortions. The approach of using pretrained codecs for pseudo-speech watermarks and restricting embedding via VAD represents a concrete design choice that could be adopted or extended in speech security applications.
major comments (2)
- [Abstract] Abstract: the central claim of 'substantially improving robustness' while 'maintaining imperceptibility comparable to existing approaches' is asserted without any quantitative metrics, baseline comparisons, dataset details, or statistical tests. This leaves the empirical support for the feature-alignment benefit unverifiable from the provided text.
- [Abstract] Abstract (and implied Experiments section): the assertion that alignment 'allows higher watermark energy to improve robustness while preserving imperceptibility' lacks any direct comparison of embedding energy, SNR, or watermark power ratio against baselines on identical audio. Robustness gains could therefore arise from voiced-region restriction alone rather than the claimed energy increase.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve clarity and verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'substantially improving robustness' while 'maintaining imperceptibility comparable to existing approaches' is asserted without any quantitative metrics, baseline comparisons, dataset details, or statistical tests. This leaves the empirical support for the feature-alignment benefit unverifiable from the provided text.
Authors: The abstract is a concise summary; the Experiments section contains the quantitative metrics, baseline comparisons, dataset details, and statistical tests. To make the central claims more self-contained and verifiable directly from the abstract, we will revise it to include key quantitative highlights (e.g., robustness and imperceptibility scores) from the experiments. revision: yes
-
Referee: [Abstract] Abstract (and implied Experiments section): the assertion that alignment 'allows higher watermark energy to improve robustness while preserving imperceptibility' lacks any direct comparison of embedding energy, SNR, or watermark power ratio against baselines on identical audio. Robustness gains could therefore arise from voiced-region restriction alone rather than the claimed energy increase.
Authors: We agree that explicit side-by-side comparisons of embedding energy, SNR, and watermark power ratio on identical audio would strengthen the argument that feature alignment (rather than VAD restriction alone) enables the higher-energy regime. We will add these direct comparisons, along with any necessary ablation on the contribution of alignment versus VAD, in the revised manuscript. revision: yes
Circularity Check
No circularity: independent design evaluated experimentally
full rationale
The paper describes a proposed method (pretrained codec for pseudo-speech watermark, fusion under VAD and perceptual losses) as a design choice to align features and enable higher embedding energy. No equations, fitting procedures, or self-citations are presented that reduce the claimed robustness gain or alignment property to a quantity defined by the inputs or prior author work. The central claim rests on experimental comparison rather than any self-definitional or fitted-input reduction, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A pretrained speech codec produces a pseudo-speech signal whose feature distribution is sufficiently close to real speech to serve as an imperceptible yet robust watermark carrier.
Reference graph
Works this paper leans on
-
[1]
Deep audio watermarks are shallow: Limitations of post-hoc watermarking techniques for speech,
P. O’Reilly, Z. Jin, J. Su, and B. Pardo, “Deep audio watermarks are shallow: Limitations of post-hoc watermarking techniques for speech,” inICLR Workshop on GenAI Watermarking, 2025
2025
-
[2]
Sok: How robust is audio watermarking in generative ai models?
Y . Wen, A. Innuganti, A. B. Ramos, H. Guo, and Q. Yan, “Sok: How robust is audio watermarking in generative ai models?”arXiv preprint arXiv:2503.19176, 2025
arXiv 2025
-
[3]
A Comprehensive Real-World Assessment of Audio Watermarking Algorithms: Will They Survive Neural Codecs?
Y . ¨Ozer, W. Choi, J. Serr `a, M. K. Singh, W.-H. Liao, and Y . Mitsufuji, “A Comprehensive Real-World Assessment of Audio Watermarking Algorithms: Will They Survive Neural Codecs?” inInterspeech 2025, 2025, pp. 5113–5117
2025
-
[4]
Wavmark: Watermarking for audio generation,
G. Chen, Y . Wu, S. Liu, T. Liu, X. Du, and F. Wei, “Wavmark: Watermarking for audio generation,”arXiv preprint arXiv:2308.12770, 2023
arXiv 2023
-
[5]
Proactive detection of voice cloning with localized watermark- ing,
R. San Roman, P. Fernandez, H. Elsahar, A. D ´efossez, T. Furon, and T. Tran, “Proactive detection of voice cloning with localized watermark- ing,” inInternational Conference on Machine Learning, vol. 235, 2024
2024
-
[6]
Detecting voice cloning attacks via timbre watermarking,
C. Liu, J. Zhang, T. Zhang, X. Yang, W. Zhang, and N. Yu, “Detecting voice cloning attacks via timbre watermarking,” inNetwork and Dis- tributed System Security Symposium, 2024
2024
-
[7]
V oiceMark: Zero-Shot V oice Cloning-Resistant Watermarking Approach Leveraging Speaker- Specific Latents,
H. Li, Z. Wu, X. Xie, J. Xie, Y . Xu, and H. Peng, “V oiceMark: Zero-Shot V oice Cloning-Resistant Watermarking Approach Leveraging Speaker- Specific Latents,” inInterspeech 2025, 2025, pp. 5108–5112
2025
-
[8]
Wmcodec: End-to-end neural speech codec with deep watermarking for authenticity verification,
J. Zhou, J. Yi, Y . Ren, J. Tao, T. Wang, and C. Y . Zhang, “Wmcodec: End-to-end neural speech codec with deep watermarking for authenticity verification,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[9]
Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,”Advances in neural information processing systems, vol. 33, pp. 17 022–17 033, 2020
2020
-
[10]
Naturalspeech 3: zero-shot speech synthesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shenet al., “Naturalspeech 3: zero-shot speech synthesis with factorized codec and diffusion models,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[11]
Speechtokenizer: Unified speech tokenizer for speech language models,
X. Zhang, D. Zhang, S. Li, Y . Zhou, and X. Qiu, “Speechtokenizer: Unified speech tokenizer for speech language models,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=AF9Q8Vip84
2024
-
[12]
Clearervoice-studio: Bridging advanced speech processing research and practical deployment,
S. Zhao, Z. Pan, and B. Ma, “Clearervoice-studio: Bridging advanced speech processing research and practical deployment,”arXiv preprint arXiv:2506.19398, 2025
arXiv 2025
-
[13]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”arXiv preprint arXiv:2210.13438, 2022
Pith/arXiv arXiv 2022
-
[14]
V ocos: Closing the gap between time-domain and fourier- based neural vocoders for high-quality audio synthesis,
H. Siuzdak, “V ocos: Closing the gap between time-domain and fourier- based neural vocoders for high-quality audio synthesis,” inInternational Conference on Representation Learning, B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, Eds., vol. 2024, 2024, pp. 25 719– 25 733
2024
-
[15]
Standardizing auditory tests,
W. Munson and M. B. Gardner, “Standardizing auditory tests,”The Journal of the Acoustical Society of America, vol. 22, no. 5 Supplement, pp. 675–675, 1950
1950
-
[16]
Visqol: The virtual speech quality objective listener,
A. Hines, J. Skoglund, A. Kokaram, and N. Harte, “Visqol: The virtual speech quality objective listener,” inIWAENC 2012; international workshop on acoustic signal enhancement. VDE, 2012, pp. 1–4
2012
-
[17]
English multi-speaker corpus for cstr voice cloning toolkit,
J. Yamagishi, “English multi-speaker corpus for cstr voice cloning toolkit,” 2012. [Online]. Available: https://datashare.ed.ac.uk/handle/ 10283/3443
2012
-
[18]
Librispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: an asr corpus based on public domain audio books,” in2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210
2015
-
[19]
The lj speech dataset,
K. Ito and L. Johnson, “The lj speech dataset,” https://keithito.com/ LJ-Speech-Dataset/, 2017
2017
-
[20]
G. Mittag, B. Naderi, A. Chehadi, and S. M ¨oller, “Nisqa: A deep cnn- self-attention model for multidimensional speech quality prediction with crowdsourced datasets,”arXiv preprint arXiv:2104.09494, 2021
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.