Fixed-Point Reasoners: Stable and Adaptive Deep Looped Transformers
Pith reviewed 2026-06-27 00:35 UTC · model grok-4.3
The pith
Fixed-point convergence acts as a stable halting mechanism in looped Transformers after pre-norm and residual scaling fix signal issues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When pre-norm layers and residual scaling are added to a looped Transformer, the fixed point of the iteration becomes a reliable, end-to-end halting criterion that allows the model to adapt its effective depth to task difficulty and solve compositional reasoning problems.
What carries the argument
Fixed-point convergence used as the halting signal inside a looped Transformer equipped with pre-norm layers and residual scaling.
If this is right
- The architecture can allocate variable compute per example without an auxiliary halting head.
- Looped depth becomes determined by input content rather than a fixed hyperparameter.
- The same model can handle both easy and hard instances of Sudoku, Maze, state tracking, and ARC-AGI by iterating until convergence.
- Training remains end-to-end because the halting decision is a direct property of the forward pass.
Where Pith is reading between the lines
- The approach may extend naturally to other sequence or grid tasks where solution quality improves with additional reasoning steps.
- If convergence speed correlates with human-perceived difficulty, the iteration count could serve as an interpretable difficulty metric.
- Removing the fixed-point assumption while keeping pre-norm and scaling might reveal whether the stability benefit is independent of the halting method.
Load-bearing premise
Pre-norm layers and residual scaling are sufficient to keep signals stable in deep loops so that convergence can be trusted as the stopping rule.
What would settle it
Run the model on the reported benchmarks and observe whether it remains stable, whether iteration count increases with problem difficulty, and whether accuracy matches or exceeds non-adaptive baselines.
Figures

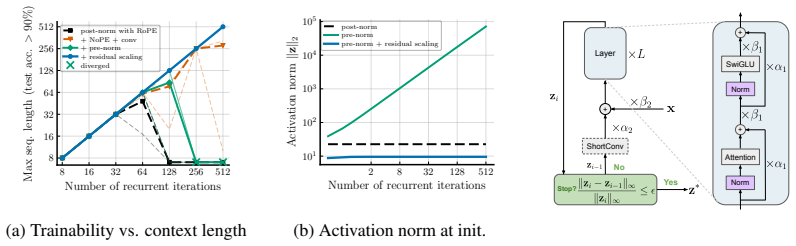






read the original abstract
Looped architectures provide an inductive bias toward learning step-by-step procedures for tasks that require compositional reasoning. The number of effective layers reached by looping determines the quality of the solution these models find. Like deep architectures, looped architectures are prone to a signal propagation problem induced by depth as the halting decision is postponed. In this paper, we address this signal propagation issue using pre-norm layers and residual scaling. Building on these architectural modifications, we propose FPRM, a Transformer-based Fixed-Point Reasoning Model that uses fixed-point convergence as an end-to-end halting mechanism in a looped architecture. We show that fixed-point halting allows FPRM to adapt its compute to task difficulty. FPRM is effective on common reasoning benchmarks, namely Sudoku, Maze, state-tracking, and ARC-AGI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Fixed-Point Reasoning Models (FPRM), a looped Transformer architecture that employs fixed-point convergence as an end-to-end halting mechanism. The authors argue that pre-norm layers and residual scaling address the signal propagation problem in deep looped architectures, enabling the model to adapt its computational effort to task difficulty. They claim effectiveness on reasoning benchmarks including Sudoku, Maze, state-tracking, and ARC-AGI.
Significance. If substantiated with quantitative evidence and analysis, the work could advance adaptive-depth models for compositional reasoning by providing a stability mechanism for looped transformers that uses convergence itself as the halting signal, rather than learned or fixed-depth alternatives.
major comments (2)
- Abstract: the claim of effectiveness on benchmarks is asserted after describing the architectural changes, but supplies no quantitative results, baselines, error bars, or experimental protocol; support for the central claim cannot be evaluated.
- Architecture section (description of FPRM and modifications): no convergence analysis, derivation, ablation studies, or empirical verification is provided showing that pre-norm layers and residual scaling resolve the depth-induced signal propagation problem sufficiently for fixed-point convergence to act as a reliable, stable halting criterion without divergence, vanishing gradients, or non-convergence. This assumption is load-bearing for attributing adaptive compute and benchmark performance to the fixed-point mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and agree that revisions are needed to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: the claim of effectiveness on benchmarks is asserted after describing the architectural changes, but supplies no quantitative results, baselines, error bars, or experimental protocol; support for the central claim cannot be evaluated.
Authors: We agree that the abstract lacks supporting quantitative evidence. In the revised manuscript, we will incorporate key performance metrics (e.g., accuracy on Sudoku, Maze, state-tracking, and ARC-AGI), baseline comparisons, and error bars to substantiate the effectiveness claims. revision: yes
-
Referee: Architecture section (description of FPRM and modifications): no convergence analysis, derivation, ablation studies, or empirical verification is provided showing that pre-norm layers and residual scaling resolve the depth-induced signal propagation problem sufficiently for fixed-point convergence to act as a reliable, stable halting criterion without divergence, vanishing gradients, or non-convergence. This assumption is load-bearing for attributing adaptive compute and benchmark performance to the fixed-point mechanism.
Authors: We acknowledge the absence of explicit convergence analysis, derivations, or targeted ablations in the current manuscript. The work relies on overall benchmark results to indicate stability. We will add a dedicated subsection with theoretical motivation for the modifications, a derivation of residual scaling, ablation studies isolating their impact on convergence, and empirical checks (e.g., gradient norms and iteration counts) to verify fixed-point behavior. revision: yes
Circularity Check
No circularity: architectural proposal rests on empirical validation, not self-referential derivation.
full rationale
The paper proposes pre-norm layers and residual scaling to stabilize looped transformers, then uses fixed-point convergence as a halting mechanism. No equations, derivations, or fitted parameters are presented that reduce by construction to the inputs. The central claims are supported by benchmark results on Sudoku, Maze, state-tracking, and ARC-AGI rather than any mathematical identity or self-citation chain. This is the common case of an empirical architecture paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
FPRM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
Equilibrium Reasoners: Learning Attractors Enables Scalable Reasoning , author=. 2026 , eprint=
2026
-
[2]
Guan Wang and Jin Li and Yuhao Sun and Xing Chen and Changling Liu and Yue Wu and Meng Lu and Sen Song and Yasin Abbasi. Hierarchical Reasoning Model , journal =. 2025 , url =. doi:10.48550/ARXIV.2506.21734 , eprinttype =. 2506.21734 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.21734 2025
-
[3]
Vardhan Palod and Karthik Valmeekam and Kaya Stechly and Subbarao Kambhampati , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.07339 , eprinttype =. 2509.07339 , timestamp =
-
[4]
William Merrill and Ashish Sabharwal , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.03961 , eprinttype =. 2503.03961 , timestamp =
-
[5]
2026 , eprint=
Parcae: Scaling Laws For Stable Looped Language Models , author=. 2026 , eprint=
2026
-
[6]
2022 , url =
Learning Iterative Reasoning through Energy Minimization , booktitle =. 2022 , url =
2022
-
[7]
Tenenbaum , editor =
Yilun Du and Jiayuan Mao and Joshua B. Tenenbaum , editor =. Learning Iterative Reasoning through Energy Diffusion , booktitle =. 2024 , url =
2024
-
[8]
Nowak and Dimitris Papailiopoulos , title =
Liu Yang and Kangwook Lee and Robert D. Nowak and Dimitris Papailiopoulos , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[9]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao and Sainbayar Sukhbaatar and DiJia Su and Xian Li and Zhiting Hu and Jason Weston and Yuandong Tian , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.06769 , eprinttype =. 2412.06769 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.06769 2024
-
[10]
International Conference on Learning Representations , volume=
Looped transformers for length generalization , author=. International Conference on Learning Representations , volume=
-
[11]
2024 , eprint=
The Expressive Power of Transformers with Chain of Thought , author=. 2024 , eprint=
2024
-
[12]
Reasoning by superposition: A theoretical perspective on chain of continuous thought.arXiv, 2025
Hanlin Zhu and Shibo Hao and Zhiting Hu and Jiantao Jiao and Stuart Russell and Yuandong Tian , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.12514 , eprinttype =. 2505.12514 , timestamp =
-
[13]
Stability and Generalization in Looped Transformers
Asher Labovich , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2604.15259 , eprinttype =. 2604.15259 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.15259 2026
-
[14]
2016 , eprint=
Exponential expressivity in deep neural networks through transient chaos , author=. 2016 , eprint=
2016
-
[15]
Zirui Ren and Ziming Liu , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2601.10679 , eprinttype =. 2601.10679 , timestamp =
-
[16]
2026 , eprint=
LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation , author=. 2026 , eprint=
2026
-
[17]
Ferdinand Kapl and Emmanouil Angelis and Kaitlin Maile and Johannes von Oswald and Stefan Bauer , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.16490 , eprinttype =. 2602.16490 , timestamp =
-
[18]
Sajad Movahedi and Felix Sarnthein and Nicola Muca Cirone and Antonio Orvieto , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.10799 , eprinttype =. 2503.10799 , timestamp =
-
[19]
Fran. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.04604 , eprinttype =. 2412.04604 , timestamp =
-
[20]
7th International Conference on Learning Representations,
Mostafa Dehghani and Stephan Gouws and Oriol Vinyals and Jakob Uszkoreit and Lukasz Kaiser , title =. 7th International Conference on Learning Representations,. 2019 , url =
2019
-
[21]
Advances in Neural Information Processing Systems , volume=
Scaling up test-time compute with latent reasoning: A recurrent depth approach , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Less is More: Recursive Reasoning with Tiny Networks
Alexia Jolicoeur. Less is More: Recursive Reasoning with Tiny Networks , journal =. 2025 , url =. doi:10.48550/ARXIV.2510.04871 , eprinttype =. 2510.04871 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.04871 2025
-
[23]
The Illusion of State in State-Space Models , booktitle =
William Merrill and Jackson Petty and Ashish Sabharwal , editor =. The Illusion of State in State-Space Models , booktitle =. 2024 , url =
2024
-
[24]
2022 , eprint=
Saturated Transformers are Constant-Depth Threshold Circuits , author=. 2022 , eprint=
2022
-
[25]
2021 , eprint=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. 2021 , eprint=
2021
-
[26]
2023 , eprint=
Faith and Fate: Limits of Transformers on Compositionality , author=. 2023 , eprint=
2023
-
[27]
Reddi , title =
Nikunj Saunshi and Nishanth Dikkala and Zhiyuan Li and Sanjiv Kumar and Sashank J. Reddi , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[28]
Alex Graves , title =. CoRR , volume =. 2016 , url =. 1603.08983 , timestamp =
Pith/arXiv arXiv 2016
-
[29]
Wen. LoopViT: Scaling Visual. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.02156 , eprinttype =. 2602.02156 , timestamp =
-
[30]
Gomez and Lukasz Kaiser and Illia Polosukhin , editor =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , editor =. Attention is All you Need , booktitle =. 2017 , url =
2017
-
[31]
Neural GPUs Learn Algorithms , booktitle =
Lukasz Kaiser and Ilya Sutskever , editor =. Neural GPUs Learn Algorithms , booktitle =. 2016 , url =
2016
-
[32]
Andrea Banino and Jan Balaguer and Charles Blundell , title =. CoRR , volume =. 2021 , url =. 2107.05407 , timestamp =
arXiv 2021
-
[33]
2022 , eprint=
DeepNet: Scaling Transformers to 1,000 Layers , author=. 2022 , eprint=
2022
-
[34]
The Lipschitz Constant of Self-Attention , booktitle =
Hyunjik Kim and George Papamakarios and Andriy Mnih , editor =. The Lipschitz Constant of Self-Attention , booktitle =. 2021 , url =
2021
-
[35]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert. Language Models are Few-Shot Learners , booktitle =. 2020 , url =
2020
-
[36]
2024 , month = sep, howpublished =
Learning to Reason with. 2024 , month = sep, howpublished =
2024
-
[37]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2408.03314 , eprinttype =. 2408.03314 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.03314 2024
-
[38]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , editor =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , booktitle =. 2022 , url =
2022
-
[39]
Daya Guo and Dejian Yang and Haowei Zhang and others , title =. Nat. , volume =. 2025 , url =. doi:10.1038/S41586-025-09422-Z , timestamp =
-
[40]
Can You Learn an Algorithm? Generalizing from Easy to Hard Problems with Recurrent Networks , booktitle =
Avi Schwarzschild and Eitan Borgnia and Arjun Gupta and Furong Huang and Uzi Vishkin and Micah Goldblum and Tom Goldstein , editor =. Can You Learn an Algorithm? Generalizing from Easy to Hard Problems with Recurrent Networks , booktitle =. 2021 , url =
2021
-
[41]
Attention is not all you need: pure attention loses rank doubly exponentially with depth , booktitle =
Yihe Dong and Jean. Attention is not all you need: pure attention loses rank doubly exponentially with depth , booktitle =. 2021 , url =
2021
-
[42]
Yoshua Bengio and Patrice Y. Simard and Paolo Frasconi , title =. 1994 , url =. doi:10.1109/72.279181 , timestamp =
-
[43]
On the difficulty of training recurrent neural networks , booktitle =
Razvan Pascanu and Tom. On the difficulty of training recurrent neural networks , booktitle =. 2013 , url =
2013
-
[44]
On Layer Normalization in the Transformer Architecture , booktitle =
Ruibin Xiong and Yunchang Yang and Di He and Kai Zheng and Shuxin Zheng and Chen Xing and Huishuai Zhang and Yanyan Lan and Liwei Wang and Tie. On Layer Normalization in the Transformer Architecture , booktitle =. 2020 , url =
2020
-
[45]
Alex Graves and Greg Wayne and Ivo Danihelka , title =. CoRR , volume =. 2014 , url =. 1410.5401 , timestamp =
Pith/arXiv arXiv 2014
-
[46]
End-to-end Algorithm Synthesis with Recurrent Networks: Extrapolation without Overthinking , booktitle =
Arpit Bansal and Avi Schwarzschild and Eitan Borgnia and Zeyad Emam and Furong Huang and Micah Goldblum and Tom Goldstein , editor =. End-to-end Algorithm Synthesis with Recurrent Networks: Extrapolation without Overthinking , booktitle =. 2022 , url =
2022
-
[47]
Signal Propagation in Transformers: Theoretical Perspectives and the Role of Rank Collapse , booktitle =
Lorenzo Noci and Sotiris Anagnostidis and Luca Biggio and Antonio Orvieto and Sidak Pal Singh and Aur. Signal Propagation in Transformers: Theoretical Perspectives and the Role of Rank Collapse , booktitle =. 2022 , url =
2022
-
[48]
Wenfang Sun and Xinyuan Song and Pengxiang Li and Lu Yin and Yefeng Zheng and Shiwei Liu , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.05795 , eprinttype =. 2502.05795 , timestamp =
-
[49]
Zico Kolter and Vladlen Koltun , editor =
Shaojie Bai and J. Zico Kolter and Vladlen Koltun , editor =. Deep Equilibrium Models , booktitle =. 2019 , url =
2019
-
[50]
Mathematics of Computation , year=
A Class of Methods for Solving Nonlinear Simultaneous Equations , author=. Mathematics of Computation , year=
-
[51]
2026 , eprint=
PonderLM: Pretraining Language Models to Ponder in Continuous Space , author=. 2026 , eprint=
2026
-
[52]
Advances in neural information processing systems , volume=
Implicit generation and modeling with energy based models , author=. Advances in neural information processing systems , volume=
-
[53]
International conference on machine learning , pages=
Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[54]
2026 , url=
Tao Zhang and Jia-Shu Pan and Ruiqi Feng and Tailin Wu , booktitle=. 2026 , url=
2026
-
[55]
Alexi Gladstone and Ganesh Nanduru and Md Mofijul Islam and Peixuan Han and Hyeonjeong Ha and Aman Chadha and Yilun Du and Heng Ji and Jundong Li and Tariq Iqbal , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.02092 , eprinttype =. 2507.02092 , timestamp =
-
[56]
2021 , note=
Should EBMs Model the Energy or the Score? , author=. 2021 , note=
2021
-
[57]
Structured Prediction Energy Networks , booktitle =
David Belanger and Andrew McCallum , editor =. Structured Prediction Energy Networks , booktitle =. 2016 , url =
2016
-
[58]
End-to-End Learning for Structured Prediction Energy Networks , booktitle =
David Belanger and Bishan Yang and Andrew McCallum , editor =. End-to-End Learning for Structured Prediction Energy Networks , booktitle =. 2017 , url =
2017
-
[59]
Predicting structured data , volume=
A tutorial on energy-based learning , author=. Predicting structured data , volume=
-
[60]
Score-Based Generative Modeling through Stochastic Differential Equations , booktitle =
Yang Song and Jascha Sohl. Score-Based Generative Modeling through Stochastic Differential Equations , booktitle =. 2021 , url =
2021
-
[61]
Denoising Diffusion Probabilistic Models , booktitle =
Jonathan Ho and Ajay Jain and Pieter Abbeel , editor =. Denoising Diffusion Probabilistic Models , booktitle =. 2020 , url =
2020
-
[62]
Renee Ge and Qianli Liao and Tomaso A. Poggio , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.00355 , eprinttype =. 2510.00355 , timestamp =
-
[63]
Shixiang Song and He Li and Zitong Wang and Boyi Zeng and Feichen Song and Yixuan Wang and Zhiqin John Xu and Ziwei He and Zhouhan Lin , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.01914 , eprinttype =. 2603.01914 , timestamp =
-
[64]
Sangmin Bae and Yujin Kim and Reza Bayat and Sungnyun Kim and Jiyoun Ha and Tal Schuster and Adam Fisch and Hrayr Harutyunyan and Ziwei Ji and Aaron C. Courville and Se. Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation , journal =. 2025 , url =. doi:10.48550/ARXIV.2507.10524 , eprinttype =. 2507.10524 , timestamp =
-
[65]
Solve the Loop: Attractor Models for Language and Reasoning
Jacob Fein. Solve the Loop: Attractor Models for Language and Reasoning , journal =. 2026 , url =. doi:10.48550/ARXIV.2605.12466 , eprinttype =. 2605.12466 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.12466 2026
-
[66]
Zhengyang Geng and J. Zico Kolter , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.18605 , eprinttype =. 2310.18605 , timestamp =
-
[67]
Donald G. M. Anderson , title =. J. 1965 , url =. doi:10.1145/321296.321305 , timestamp =
-
[68]
Marcelo O. R. Prates and Lu. Problem Solving at the Edge of Chaos: Entropy, Puzzles and the Sudoku Freezing Transition , booktitle =. 2018 , url =. doi:10.1109/ICTAI.2018.00109 , timestamp =
-
[69]
Zico Kolter and Roger B
Cem Anil and Ashwini Pokle and Kaiqu Liang and Johannes Treutlein and Yuhuai Wu and Shaojie Bai and J. Zico Kolter and Roger B. Grosse , editor =. Path Independent Equilibrium Models Can Better Exploit Test-Time Computation , booktitle =. 2022 , url =
2022
-
[70]
On Training Implicit Models , booktitle =
Zhengyang Geng and Xin. On Training Implicit Models , booktitle =. 2021 , url =
2021
-
[71]
Workshop on Latent
Recursive Reasoning as Attractor Landscape Search: Mechanistic Dynamics of the Tiny Recursive Model , author=. Workshop on Latent. 2026 , url=
2026
-
[72]
Zico Kolter , editor =
Shaojie Bai and Vladlen Koltun and J. Zico Kolter , editor =. Stabilizing Equilibrium Models by Jacobian Regularization , booktitle =. 2021 , url =
2021
-
[73]
Looped Transformers as Programmable Computers , booktitle =
Angeliki Giannou and Shashank Rajput and Jy. Looped Transformers as Programmable Computers , booktitle =. 2023 , url =
2023
-
[74]
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers
Harsh Kohli and Srinivasan Parthasarathy and Huan Sun and Yuekun Yao , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2604.07822 , eprinttype =. 2604.07822 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.07822 2026
-
[75]
Hugh Blayney and Alvaro Arroyo and Johan S. Obando. A Mechanistic Analysis of Looped Reasoning Language Models , journal =. 2026 , url =. doi:10.48550/ARXIV.2604.11791 , eprinttype =. 2604.11791 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.11791 2026
-
[76]
Samy Wu Fung and Howard Heaton and Qiuwei Li and Daniel McKenzie and Stanley J. Osher and Wotao Yin , title =. Thirty-Sixth. 2022 , url =. doi:10.1609/AAAI.V36I6.20619 , timestamp =
-
[77]
Peri-LN: Revisiting Normalization Layer in the Transformer Architecture , booktitle =
Jeonghoon Kim and Byeongchan Lee and Cheonbok Park and Yeontaek Oh and Beomjun Kim and Taehwan Yoo and Seongjin Shin and Dongyoon Han and Jinwoo Shin and Kang Min Yoo , editor =. Peri-LN: Revisiting Normalization Layer in the Transformer Architecture , booktitle =. 2025 , url =
2025
-
[78]
Smith and Albert Gu and Anushan Fernando and
Antonio Orvieto and Samuel L. Smith and Albert Gu and Anushan Fernando and. Resurrecting Recurrent Neural Networks for Long Sequences , booktitle =. 2023 , url =
2023
-
[79]
Divya Jyoti Bajpai and Manjesh Kumar Hanawal
Ahmadreza Jeddi and Marco Ciccone and Babak Taati , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.11451 , eprinttype =. 2602.11451 , timestamp =
-
[80]
Scaling Latent Reasoning via Looped Language Models
Rui. Scaling Latent Reasoning via Looped Language Models , journal =. 2025 , url =. doi:10.48550/ARXIV.2510.25741 , eprinttype =. 2510.25741 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.25741 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.