Integrating Facial Generation into Full-Duplex Spoken Dialogue Systems
Pith reviewed 2026-06-26 12:07 UTC · model grok-4.3
The pith
Moshi-Face extends full-duplex dialogue models to generate synchronized facial motion from face tokens produced by a non-autoregressive transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
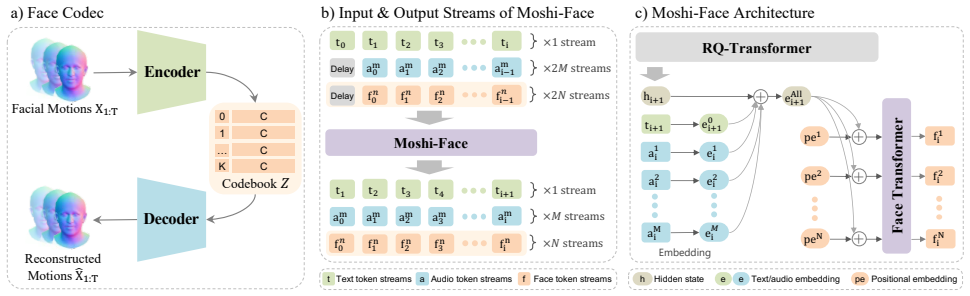
Moshi-Face is the first full-duplex dialogue model that jointly processes the user's audio and facial input while simultaneously generating speech and facial motion. It first constructs a vector-quantized variational autoencoder (VQ-VAE) as a face codec that encodes 3D head meshes extracted from facial videos into compact discrete tokens and reconstructs meshes from those tokens, then extends Moshi with a Face Transformer module that generates face tokens non-autoregressively to produce synchronized audio and face tokens in real time.
What carries the argument
The Face Transformer module that generates face tokens non-autoregressively, allowing synchronized audiovisual output at the same low latency as the original audio-only model.
If this is right
- Moshi-Face achieves audiovisual alignment at low latency.
- Dialogue quality remains comparable to the audio-only Moshi model.
- The system accepts both audio and facial input from the user in real time.
- Face tokens are produced and consumed synchronously with speech tokens.
Where Pith is reading between the lines
- The same non-autoregressive token-generation pattern could be tested on other modalities such as hand gestures or body pose.
- If the VQ-VAE reconstruction quality proves sufficient, the approach might scale to higher-resolution face meshes without autoregressive delays.
- Applications that already use full-duplex voice interfaces could add visual output by swapping in an equivalent face codec and transformer head.
Load-bearing premise
The non-autoregressive Face Transformer can generate face tokens in real time without introducing misalignment or quality loss, relying on the VQ-VAE face codec performing adequately on 3D meshes extracted from videos.
What would settle it
A side-by-side evaluation in which Moshi-Face produces measurable audiovisual desynchronization or lower dialogue quality scores than the original Moshi model on the same test conversations.
Figures

read the original abstract
Full-duplex spoken dialogue models, such as Moshi, enable natural, low-latency voice conversations. However, they remain limited to the audio modality, lacking the facial expressions that are integral to human communication. We present Moshi-Face, the first full-duplex dialogue model that jointly processes the user's audio and facial input while simultaneously generating speech and facial motion. We first construct a vector-quantized variational autoencoder (VQ-VAE) as a face codec that encodes 3D head meshes extracted from facial videos into compact discrete tokens, referred to as face tokens, and conversely reconstructs 3D meshes from these tokens. We then extend Moshi with a Face Transformer module that generates face tokens non-autoregressively, enabling Moshi-Face to produce synchronized audio and face tokens in real time. Experiments show that Moshi-Face achieves audiovisual alignment at low latency while preserving the dialogue quality of the original audio-only model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Moshi-Face, an extension of the Moshi full-duplex spoken dialogue model to jointly handle user audio and facial input while generating synchronized speech and facial motion. It first trains a VQ-VAE face codec on 3D head meshes extracted from video to produce discrete face tokens, then adds a non-autoregressive Face Transformer module that emits face tokens in real time alongside the autoregressive audio decoder, claiming low-latency audiovisual alignment without degrading the original model's dialogue quality.
Significance. If the central claims hold, the work would constitute the first demonstration of a full-duplex multimodal dialogue system that adds expressive facial output to an existing low-latency audio model. The VQ-VAE discretization of 3D meshes combined with non-autoregressive face generation offers a potentially scalable route for extending audio-only systems, provided synchronization and reconstruction fidelity can be verified.
major comments (2)
- [Abstract] The abstract asserts that 'experiments show that Moshi-Face achieves audiovisual alignment at low latency while preserving the dialogue quality,' yet supplies no quantitative metrics (e.g., alignment error, latency measurements, or dialogue-quality scores), no baselines, and no description of evaluation protocols or error analysis. This absence prevents evaluation of the central claim.
- No description is given of the synchronization mechanism between the non-autoregressive Face Transformer and the autoregressive audio decoder: the relative token rates, any buffering or lookahead strategy, the conditioning of face-token generation on audio state, or any alignment loss term used in joint training. These details are load-bearing for the claim that real-time face tokens can be emitted without introducing misalignment during turn-taking or prosody changes.
minor comments (1)
- A system diagram showing data flow between the VQ-VAE, Face Transformer, and Moshi audio components would clarify the architecture.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the two major comments below and will revise the manuscript to provide the requested quantitative details and technical descriptions.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts that 'experiments show that Moshi-Face achieves audiovisual alignment at low latency while preserving the dialogue quality,' yet supplies no quantitative metrics (e.g., alignment error, latency measurements, or dialogue-quality scores), no baselines, and no description of evaluation protocols or error analysis. This absence prevents evaluation of the central claim.
Authors: We agree that the abstract would benefit from including key quantitative results. The Experiments section of the manuscript reports these metrics (including alignment error, latency, and dialogue quality scores with baselines), but the abstract itself is currently high-level. We will revise the abstract to incorporate specific numerical results and a brief reference to the evaluation protocol. revision: yes
-
Referee: No description is given of the synchronization mechanism between the non-autoregressive Face Transformer and the autoregressive audio decoder: the relative token rates, any buffering or lookahead strategy, the conditioning of face-token generation on audio state, or any alignment loss term used in joint training. These details are load-bearing for the claim that real-time face tokens can be emitted without introducing misalignment during turn-taking or prosody changes.
Authors: We acknowledge that the manuscript provides only a high-level overview of the Face Transformer and does not detail the synchronization mechanism. We will add a new subsection in the Methods section describing the relative token rates, buffering/lookahead approach, conditioning of face tokens on audio states, and any alignment considerations during joint training. revision: yes
Circularity Check
No significant circularity; standard VQ-VAE + transformer extension evaluated empirically
full rationale
The paper constructs a VQ-VAE face codec from 3D meshes and adds a non-autoregressive Face Transformer to Moshi, then reports experimental outcomes on latency, alignment, and dialogue quality. No equations, definitions, or claims reduce the audiovisual alignment result to a fitted parameter, self-citation chain, or input by construction. The derivation relies on established techniques (VQ-VAE discretization, non-autoregressive generation) applied to a new modality combination, with performance claims grounded in separate evaluation rather than tautological renaming or internal fitting.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A vector-quantized variational autoencoder can effectively encode and decode 3D head meshes into compact discrete face tokens.
Reference graph
Works this paper leans on
-
[1]
Introduction Human conversation is inherently simultaneous and multi- modal. It unfolds as a real-time, bidirectional exchange marked by overlapping, interruptions, and backchannels, and it is con- veyed through both verbal and nonverbal cues, such as facial expressions, head movements, and gestures [1]. Developing dialogue systems that capture both chara...
-
[2]
!:# t!t" a!# a) FaceCodec b)Input & Output Streams of Moshi-Face f!$ t% a
Moshi-Face Our goal is to extend a full-duplex spoken dialogue model to jointly process and generate 3D facial motion alongside speech. We proposeMoshi-Face, an extension of Moshi [7] that repre- sents facial motions as discrete tokens and handles them jointly with audio in real time. As illustrated in Figure 2, this section describes: a) a VQ-V AE servin...
Pith/arXiv arXiv 2026
-
[3]
Experiments 3.1. 3D Audiovisual Dialogue Dataset Training Moshi-Face requires a large-scale conversational au- diovisual dataset with 3D face vertices. Existing widely used 3D audiovisual datasets, such as VOCASET [18] and BIWI [19], are non-conversational and contain only minutes of utterance recordings, making them insufficient for training audiovisual ...
-
[4]
To train this model, we derived a 180-hour 3D audiovisual dialogue dataset from the Seamless Interaction dataset
Conclusion We presented Moshi-Face, which jointly processes and gen- erates facial motion and speech within a full-duplex dialogue framework. To train this model, we derived a 180-hour 3D audiovisual dialogue dataset from the Seamless Interaction dataset. We trained a face codec that tokenizes facial motion into discrete face tokens and reconstructs facia...
-
[5]
We used the computational resources of the supercomputer “Flow” at the Information Technology Center, Nagoya University
Acknowledgments This work was supported by JST Moonshot R&D, Grant num- ber JPMJMS2011. We used the computational resources of the supercomputer “Flow” at the Information Technology Center, Nagoya University
-
[6]
All scientific content, experimental design, implementation, and analysis were con- ducted entirely by the authors
Generative AI Use Disclosure We clarify that generative AI tools were used to assist with edit- ing and polishing the manuscript text. All scientific content, experimental design, implementation, and analysis were con- ducted entirely by the authors
-
[7]
Nonverbal com- munication,
J. A. Hall, T. G. Horgan, and N. A. Murphy, “Nonverbal com- munication,”Annual Review of Psychology, vol. 70, no. 2019, pp. 271–294, 2019
2019
-
[8]
Let’s Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation,
S. Park, C. Kim, H. Rha, M. Kim, J. Hong, J. Yeo, and Y . Ro, “Let’s Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024, pp. 16 334– 16 348
2024
-
[9]
UniTalker: Con- versational Speech-Visual Synthesis,
Y . Hu, R. Liu, Y . Ren, X. Yin, and H. Li, “UniTalker: Con- versational Speech-Visual Synthesis,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 10 248– 10 257
2025
-
[10]
Seeing is Believing: Emotion-Aware Audio-Visual Language Modeling for Expressive Speech Generation,
W. Tan, J. Lian, H. Inaguma, P. Tomasello, P. Koehn, and X. Ma, “Seeing is Believing: Emotion-Aware Audio-Visual Language Modeling for Expressive Speech Generation,” inFindings of the Association for Computational Linguistics: EMNLP 2025, 2025, pp. 2600–2617
2025
-
[11]
On the Landscape of Spoken Language Models: A Comprehensive Sur- vey,
S. Arora, K.-W. Chang, C.-M. Chien, Y . Peng, H. Wu, Y . Adi, E. Dupoux, H.-Y . Lee, K. Livescu, and S. Watanabe, “On the Landscape of Spoken Language Models: A Comprehensive Sur- vey,”arXiv preprint arXiv:2504.08528, 2025
Pith/arXiv arXiv 2025
-
[12]
WavChat: A Survey of Spoken Dialogue Models,
S. Ji, Y . Chen, M. Fang, J. Zuo, J. Lu, H. Wang, Z. Jiang, L. Zhou, S. Liu, X. Chenget al., “WavChat: A Survey of Spoken Dialogue Models,”arXiv preprint arXiv:2411.13577, 2024
arXiv 2024
-
[13]
Moshi: a speech-text foundation model for real-time dialogue,
A. D ´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
Pith/arXiv arXiv 2024
-
[14]
Freeze-Omni: A Smart and Low Latency Speech-to- speech Dialogue Model with Frozen LLM,
X. Wang, Y . Li, C. Fu, Y . Zhang, Y . Shen, L. Xie, K. Li, X. Sun, and L. Ma, “Freeze-Omni: A Smart and Low Latency Speech-to- speech Dialogue Model with Frozen LLM,” inProceedings of the 42nd International Conference on Machine Learning, 2025, pp. 63 345–63 354
2025
-
[15]
Generative Spoken Dialogue Language Modeling,
T. A. Nguyen, E. Kharitonov, J. Copet, Y . Adi, W.-N. Hsu, A. Elkahky, P. Tomasello, R. Algayres, B. Sagot, A. Mohamed et al., “Generative Spoken Dialogue Language Modeling,”Trans- actions of the Association for Computational Linguistics, vol. 11, pp. 250–266, 2023
2023
-
[16]
Towards a Japanese Full-duplex Spoken Dialogue System,
A. Ohashi, S. Iizuka, J. Jiang, and R. Higashinaka, “Towards a Japanese Full-duplex Spoken Dialogue System,” inProceedings of the 26th INTERSPEECH Conference, 2025, pp. 1783–1787
2025
-
[17]
Seamless Interaction: Dyadic Audiovisual Motion Modeling and Large-scale Dataset,
V . Agrawal, A. Akinyemi, K. Alvero, M. Behrooz, J. Buffalini, F. M. Carlucci, J. Chen, J. Chen, Z. Chen, S. Chenget al., “Seamless Interaction: Dyadic Audiovisual Motion Modeling and Large-scale Dataset,”arXiv preprint arXiv:2506.22554, 2025
arXiv 2025
-
[18]
GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians,
S. Qian, T. Kirschstein, L. Schoneveld, D. Davoli, S. Giebenhain, and M. Nießner, “GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 299–20 309
2024
-
[19]
Neural Discrete Representa- tion Learning,
A. Van Den Oord, O. Vinyalset al., “Neural Discrete Representa- tion Learning,” inProceedings of the Thirty-first Annual Confer- ence on Neural Information Processing Systems, vol. 30, 2017
2017
-
[20]
CodeTalker: Speech-Driven 3D Facial Animation with Discrete Motion Prior,
J. Xing, M. Xia, Y . Zhang, X. Cun, J. Wang, and T.-T. Wong, “CodeTalker: Speech-Driven 3D Facial Animation with Discrete Motion Prior,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 12 780– 12 790
2023
-
[21]
Learning a model of facial shape and expression from 4D scans,
T. Li, T. Bolkart, M. J. Black, H. Li, and J. Romero, “Learning a model of facial shape and expression from 4D scans,”ACM Trans- actions on Graphics, vol. 36, no. 6, pp. 194:1–194:17, 2017
2017
-
[22]
SoundStream: An End-to-End Neural Audio Codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “SoundStream: An End-to-End Neural Audio Codec,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 30, pp. 495–507, 2022
2022
-
[23]
High-Fidelity Audio Compression with Improved RVQGAN,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-Fidelity Audio Compression with Improved RVQGAN,” inProceedings of the Thirty-seventh Annual Conference on Neu- ral Information Processing Systems, vol. 36, 2023, pp. 27 980– 27 993
2023
-
[24]
Capture, Learning, and Synthesis of 3D Speaking Styles,
D. Cudeiro, T. Bolkart, C. Laidlaw, A. Ranjan, and M. J. Black, “Capture, Learning, and Synthesis of 3D Speaking Styles,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 10 101–10 111
2019
-
[25]
A 3-D Audio-Visual Corpus of Affective Communication,
G. Fanelli, J. Gall, H. Romsdorfer, T. Weise, and L. Van Gool, “A 3-D Audio-Visual Corpus of Affective Communication,”IEEE Transactions on Multimedia, vol. 12, no. 6, pp. 591–598, 2010
2010
-
[26]
Decoupled Weight Decay Regular- ization,
I. Loshchilov and F. Hutter, “Decoupled Weight Decay Regular- ization,” inProceedings of the 7th International Conference on Learning Representations, 2019
2019
-
[27]
Wav2Sem: Plug-and-Play Audio Semantic Decoupling for 3D Speech-Driven Facial Animation,
H. Li, J. Dai, X. Zhao, F. Zhou, J. Pan, and L. Li, “Wav2Sem: Plug-and-Play Audio Semantic Decoupling for 3D Speech-Driven Facial Animation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 183–192
2025
-
[28]
Out of time: automated lip sync in the wild,
J. S. Chung and A. Zisserman, “Out of time: automated lip sync in the wild,” inProceedings of the 13th Asian Conference on Com- puter Vision, 2016, pp. 251–263
2016
-
[29]
A Lip Sync Expert is All You Need for Speech to Lip Genera- tion in the Wild,
K. Prajwal, R. Mukhopadhyay, V . P. Namboodiri, and C. Jawahar, “A Lip Sync Expert is All You Need for Speech to Lip Genera- tion in the Wild,” inProceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 484–492
2020
-
[30]
UTMOS: UTokyo-Sarulab System for V oiceMOS Challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-Sarulab System for V oiceMOS Challenge 2022,” inProceedings of the 23rd INTERSPEECH Conference, 2022
2022
-
[31]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,” inProceedings of the Thirty- seventh Annual Conference on Neural Information Processing Systems, vol. 36, 2023, pp. 46 595–46 623
2023
-
[32]
Effects of Dia- logue Corpora Properties on Fine-Tuning a Moshi-Based Spoken Dialogue model,
Y . Abe, M. Saeki, A. Ohashi, S. Takamichi, S. Fujie, T. Kobayashi, T. Ogawa, and R. Higashinaka, “Effects of Dia- logue Corpora Properties on Fine-Tuning a Moshi-Based Spoken Dialogue model,” inProceedings of the 16th International Work- shop on Spoken Dialogue System Technology, 2026, pp. 104–108
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.