TurboMPC: Fast, Scalable, and Differentiable Model Predictive Control on the GPU
Pith reviewed 2026-06-26 00:49 UTC · model grok-4.3
The pith
A fully GPU-based differentiable MPC solver achieves up to 15 times faster runtimes than prior CPU and GPU methods while supporting constraints and scaling beyond 8000 planning steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
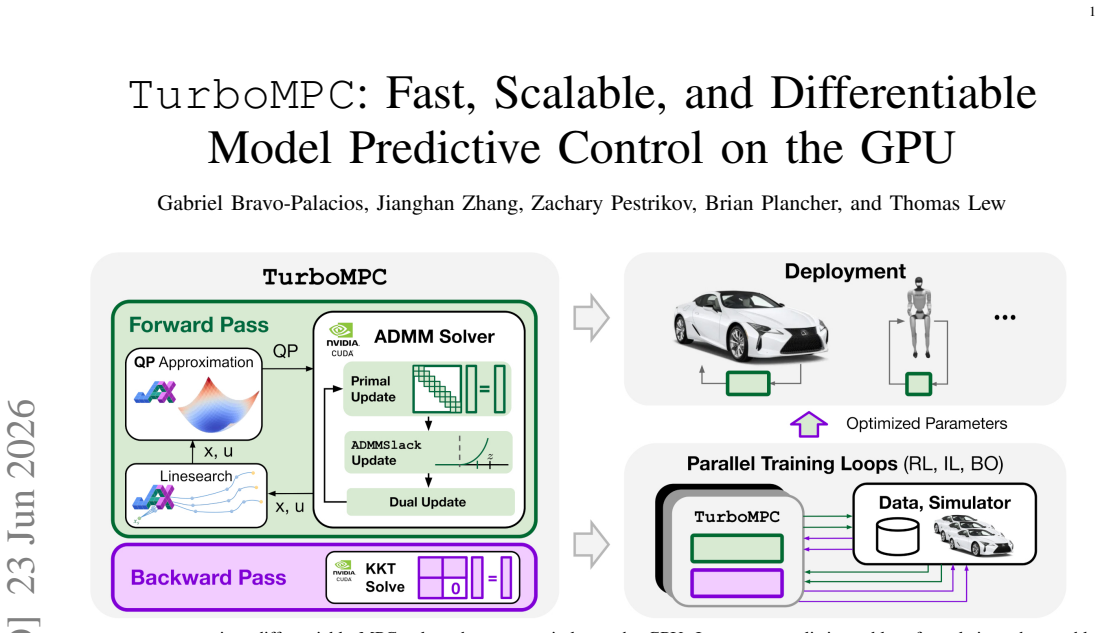
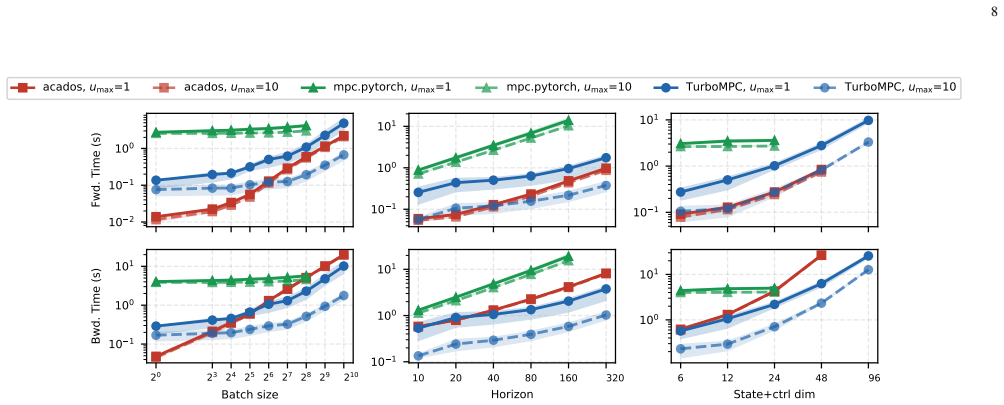
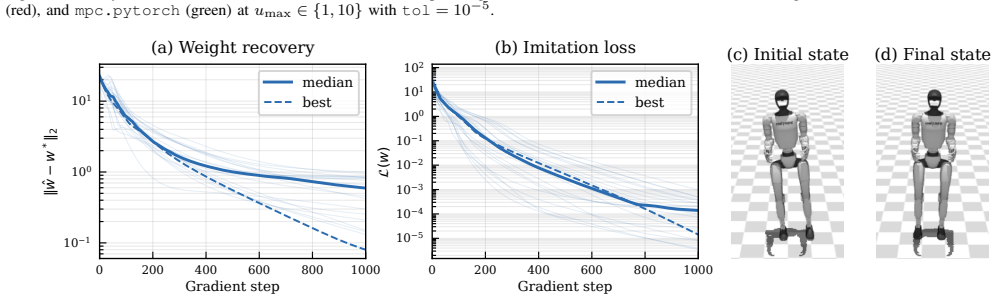
TurboMPC is a differentiable MPC solver that executes entirely on the GPU. It combines sequential quadratic programming, an ADMM inner solver, implicit differentiation, and a co-designed JAX-CUDA implementation. The solver accepts state and control inequality constraints, implicit integrators, cross-time-coupled costs, and slack variables. On simulation benchmarks it records up to 15 times speedup over state-of-the-art CPU solvers and 58 times over prior GPU solvers. When deployed on a full-scale car for minimum-time racing, GPU-accelerated Bayesian optimization of its parameters produces faster driving than a hand-tuned baseline, and the method continues to control the vehicle at planning h
What carries the argument
Sequential quadratic programming outer loop with an ADMM inner solver and implicit differentiation, all executed inside a single JAX-CUDA implementation.
If this is right
- Batched GPU evaluation allows Bayesian optimization to tune MPC parameters orders of magnitude faster than sequential CPU tuning.
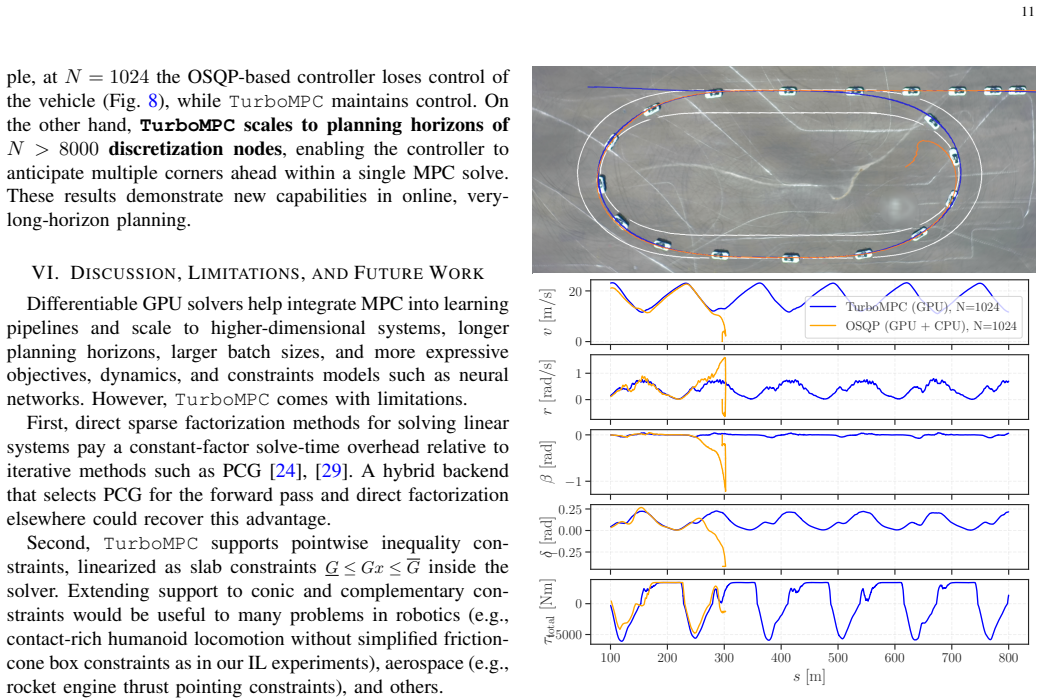
- The same solver instance can maintain stable vehicle control at planning horizons of more than 8000 knot points.
- Neural-network cost functions and implicit integrators can be used inside the MPC loop without leaving GPU memory.
- Real-time minimum-time racing on a full-scale car becomes feasible with automatic rather than manual parameter selection.
Where Pith is reading between the lines
- Placing the entire MPC pipeline on the GPU removes a major barrier to folding differentiable control into larger end-to-end learning systems that already live on the same hardware.
- The scaling behavior suggests that problems previously considered intractable for online MPC, such as high-dimensional humanoid planning over long horizons, may now be worth re-examining.
- Because the solver remains differentiable, gradient-based meta-optimization of cost weights or dynamics parameters can be performed directly on batches of real or simulated trajectories.
Load-bearing premise
The measured speedups and real-vehicle gains rest on the assumption that the chosen simulation tasks, neural-network cost functions, and racing scenario are representative of broader robotics use without undisclosed benchmark-specific optimizations.
What would settle it
A controlled re-run of the same planning and racing benchmarks on the same hardware in which a competing differentiable solver matches or exceeds the reported runtimes and horizon lengths would falsify the speedup and scalability claims.
Figures

read the original abstract
Robotics increasingly relies on GPUs for parallel simulation, large-scale learning, and neural-network inference. For model predictive control (MPC) to scale with this paradigm, solvers must run efficiently on this hardware while remaining fast, differentiable, and compatible with expressive MPC formulations used in robotics. We present TurboMPC, a differentiable MPC solver that runs entirely on the GPU and supports state and control inequality constraints, implicit integrators, cross-time-coupled costs, and slack variables. TurboMPC combines sequential quadratic programming (SQP), an alternating direction method of multipliers (ADMM) inner solver, implicit differentiation, and a co-designed JAX-CUDA implementation for efficiency and ease of use. In simulation, we validate TurboMPC on constrained planning, humanoid imitation learning, and reinforcement learning with neural-network cost function tasks, achieving up to $15\times$ and $58\times$ speedups over state-of-the-art CPU and GPU differentiable solvers, respectively. We deploy TurboMPC on a full-scale car for minimum-time racing and find that batched, GPU-accelerated tuning of MPC parameters via Bayesian optimization yields significantly faster driving than a hand-tuned baseline. TurboMPC also scales to planning horizons of over $8000$ knot points while maintaining control of the vehicle. We open-source TurboMPC at: https://github.com/ToyotaResearchInstitute/turbompc
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TurboMPC, a fully GPU-resident differentiable MPC solver built on SQP with an ADMM inner solver and implicit differentiation, implemented in JAX-CUDA. It supports state/control inequalities, implicit integrators, cross-time-coupled costs, and slack variables. Empirical results on constrained planning, humanoid imitation, and RL with neural-network costs report speedups of up to 15× versus CPU solvers and 58× versus prior GPU solvers; the method scales to >8000 knot points and is deployed on a full-scale car for minimum-time racing, where batched Bayesian optimization of MPC parameters outperforms hand-tuning. The implementation and benchmark scripts are open-sourced.
Significance. If the reported speedups and scaling hold under the disclosed experimental conditions, the work provides a practical, reproducible route to integrate high-performance MPC with GPU-accelerated simulation and learning pipelines in robotics. The open-source release, concrete real-vehicle deployment, and support for expressive problem features (implicit dynamics, NN costs, long horizons) are notable strengths that lower barriers for downstream use.
minor comments (3)
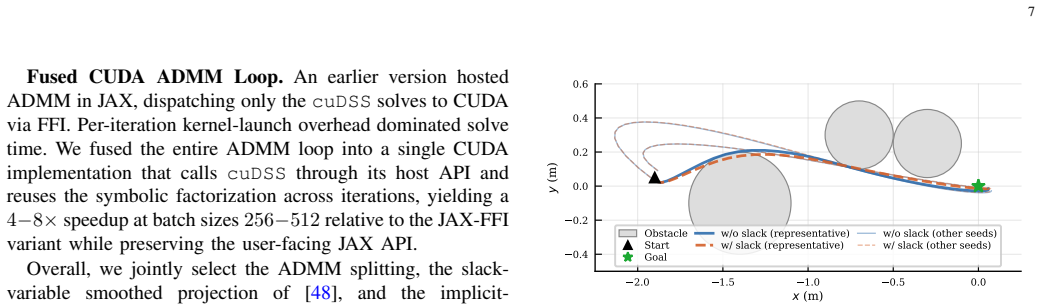
- [§4] §4 (Experiments): the timing tables would benefit from explicit listing of the exact solver versions, JAX/CUDA configurations, and hardware (GPU model, CPU) used for each baseline to facilitate exact reproduction.
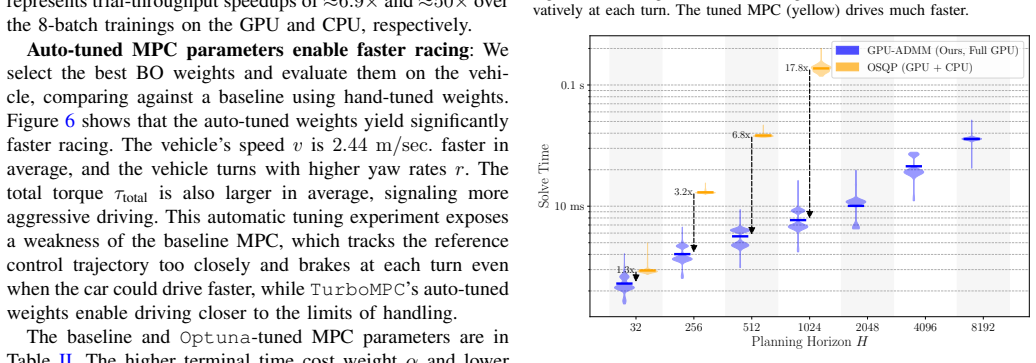
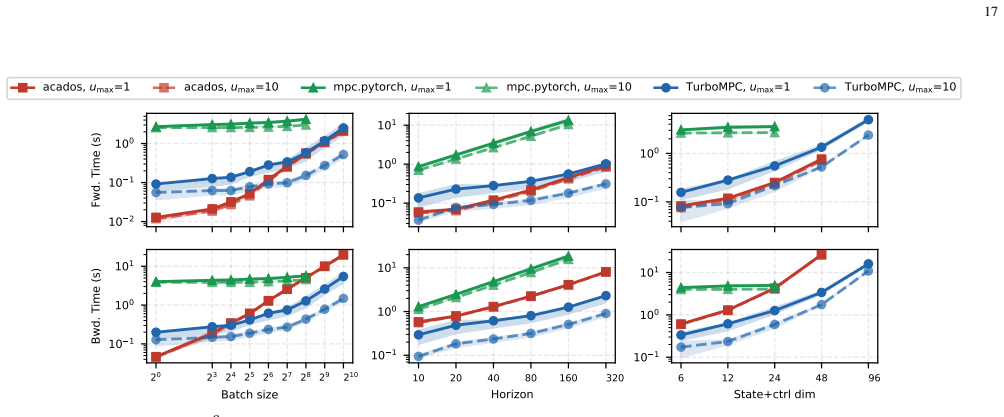
- [Figure 5] Figure 5 (scaling plot): the y-axis label and legend should clarify whether the plotted times are per-iteration or total solve time, and whether batch size is held constant across horizon lengths.
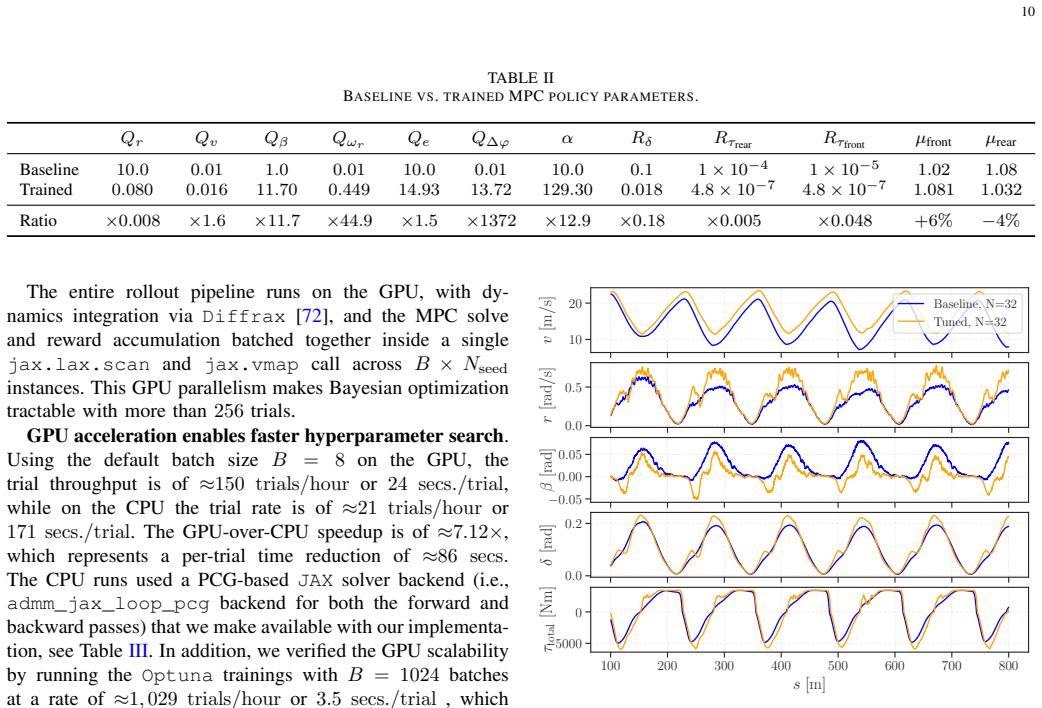
- [§5.2] §5.2 (Car deployment): the description of the Bayesian optimization setup would be clearer with the explicit acquisition function, number of trials, and the precise definition of the 'significantly faster' metric (e.g., mean lap time reduction and standard deviation).
Simulated Author's Rebuttal
We thank the referee for their thorough summary of the manuscript and for recommending acceptance. We are pleased that the contributions—particularly the open-source implementation, support for expressive MPC features, real-vehicle deployment, and reported speedups—were viewed positively.
Circularity Check
No significant circularity
full rationale
The paper is an engineering contribution centered on a co-designed SQP+ADMM solver with implicit differentiation, implemented in JAX-CUDA for GPU execution. Central claims rest on concrete implementation details, timing benchmarks across constrained planning, imitation learning, RL with NN costs, and a real-car minimum-time racing deployment, plus scaling to 8000 knot points. These are externally falsifiable via the open-source repository and stated task descriptions; no load-bearing derivation, fitted-parameter prediction, or self-citation chain reduces the result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RT-2: Vision-language- action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao,et al., “RT-2: Vision-language- action models transfer web knowledge to robotic control,” inConf. on Robot Learning, 2023
2023
-
[2]
Isaac gym: High performance GPU-based physics simulation for robot learning,
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa,et al., “Isaac gym: High performance GPU-based physics simulation for robot learning,” 2021, available at https://arxiv.org/abs/2108.10470
Pith/arXiv arXiv 2021
-
[3]
Open X-embodiment: Robotic learning datasets and RT-X models: Open X-embodiment collaboration,
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar,et al., “Open X-embodiment: Robotic learning datasets and RT-X models: Open X-embodiment collaboration,” inProc. IEEE Conf. on Robotics and Automation, 2024
2024
-
[4]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” inConf. on Robot Learning, 2022
2022
-
[5]
A careful examination of large behavior models for multitask dexterous manipulation,
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau,et al., “A careful examination of large behavior models for multitask dexterous manipulation,”Science Robotics, vol. 11, no. 113, 2026
2026
-
[6]
Optimization-based locomotion planning, estimation, and control design for the Atlas humanoid robot,
S. Kuindersma, R. Deits, M. Fallon, A. Valenzuela, H. Dai, F. Permenter, T. Koolen, P. Marion, and R. Tedrake, “Optimization-based locomotion planning, estimation, and control design for the Atlas humanoid robot,” Autonomous Robots, vol. 40, no. 3, pp. 429–455, 2016
2016
-
[7]
Dynamic locomotion in the MIT cheetah 3 through convex model-predictive control,
J. Di Carlo, P. M. Wensing, B. Katz, G. Bledt, and S. Kim, “Dynamic locomotion in the MIT cheetah 3 through convex model-predictive control,” inIEEE/RSJ Int. Conf. on Intelligent Robots & Systems, 2018
2018
-
[8]
Motion planning for quadrupedal locomotion: Coupled planning, terrain mapping, and whole-body control,
C. Mastalli, I. Havoutis, M. Focchi, D. G. Caldwell, and C. Semini, “Motion planning for quadrupedal locomotion: Coupled planning, terrain mapping, and whole-body control,”IEEE Transactions on Robotics, vol. 36, no. 6, pp. 1635–1648, 2020
2020
-
[9]
Cerberus in the DARPA subterranean challenge,
M. Tranzatto, T. Miki, M. Dharmadhikari, L. Bernreiter, M. Kulkarni, F. Mascarich, O. Andersson, S. Khattak, M. Hutter, R. Siegwart,et al., “Cerberus in the DARPA subterranean challenge,”Science Robotics, vol. 7, no. 66, 2022
2022
-
[10]
Optimization-based control for dynamic legged robots,
P. M. Wensing, M. Posa, Y . Hu, A. Escande, N. Mansard, and A. Del Prete, “Optimization-based control for dynamic legged robots,” IEEE Transactions on Robotics, vol. 40, pp. 43–63, 2023
2023
-
[11]
Per- ceptive locomotion through nonlinear model-predictive control,
R. Grandia, F. Jenelten, S. Yang, F. Farshidian, and M. Hutter, “Per- ceptive locomotion through nonlinear model-predictive control,”IEEE Transactions on Robotics, vol. 39, no. 5, pp. 3402–3421, 2023
2023
-
[12]
TinyMPC: Model-predictive control on resource-constrained microcon- trollers,
K. Nguyen, S. Schoedel, A. Alavilli, B. Plancher, and Z. Manchester, “TinyMPC: Model-predictive control on resource-constrained microcon- trollers,” inProc. IEEE Conf. on Robotics and Automation, 2024. 19
2024
-
[13]
Push anything: Single-and multi-object pushing from first sight with contact-implicit MPC,
H. Bui, Y . Gao, H. Yang, E. Cui, S. Mody, B. Acosta, T. S. Felix, B. Bianchini, and M. Posa, “Push anything: Single-and multi-object pushing from first sight with contact-implicit MPC,” inProc. IEEE Conf. on Robotics and Automation, 2026
2026
-
[14]
Structure-exploiting sequential quadratic programming for model-predictive control,
A. Jordana, S. Kleff, A. Meduri, J. Carpentier, N. Mansard, and L. Righetti, “Structure-exploiting sequential quadratic programming for model-predictive control,”IEEE Transactions on Robotics, vol. 41, pp. 4960–4974, 2025
2025
-
[15]
HPIPM: a high-performance quadratic pro- gramming framework for model predictive control,
G. Frison and M. Diehl, “HPIPM: a high-performance quadratic pro- gramming framework for model predictive control,”IFAC-Papers On- line, vol. 53, no. 2, pp. 6563–6569, 2020
2020
-
[16]
OSQP: an operator splitting solver for quadratic programs,
B. Stellato, G. Banjac, P. Goulart, A. Bemporad, and S. Boyd, “OSQP: an operator splitting solver for quadratic programs,”Mathematical Programming Computation, vol. 12, no. 4, pp. 637–672, 2020
2020
-
[17]
DOC: Differentiable optimal control for retargeting motions onto legged robots,
R. Grandia, F. Farshidian, E. Knoop, C. Schumacher, M. Hutter, and M. B¨acher, “DOC: Differentiable optimal control for retargeting motions onto legged robots,”ACM Transactions on Graphics, vol. 42, no. 4, pp. 1–14, 2023
2023
-
[18]
On the implementation of an interior- point filter line-search algorithm for large-scale nonlinear programming,
A. W ¨achter and L. T. Biegler, “On the implementation of an interior- point filter line-search algorithm for large-scale nonlinear programming,” Mathematical programming, vol. 106, no. 1, pp. 25–57, 2006
2006
-
[19]
SNOPT: An SQP algorithm for large-scale constrained optimization,
P. E. Gill, W. Murray, and M. A. Saunders, “SNOPT: An SQP algorithm for large-scale constrained optimization,”SIAM review, vol. 47, no. 1, pp. 99–131, 2005
2005
-
[20]
acados—a modular open-source framework for fast embedded optimal control,
R. Verschueren, G. Frison, D. Kouzoupis, J. Frey, N. v. Duijkeren, A. Zanelli, B. Novoselnik, T. Albin, R. Quirynen, and M. Diehl, “acados—a modular open-source framework for fast embedded optimal control,”Mathematical Programming Computation, vol. 14, no. 1, pp. 147–183, 2022
2022
-
[22]
Frostig, S
R. Frostig, S. Sindhwani, and S. Tu, “Trajax,” 2021, available at http: //github.com/google/trajax
2021
-
[23]
Differentiable MPC for end-to-end planning and control,
B. Amos, I. D. J. Rodriguez, J. Sacks, B. Boots, and Z. Kolter, “Differentiable MPC for end-to-end planning and control,”Conf. on Neural Information Processing Systems, vol. 31, 2018
2018
-
[24]
Differentiable model predictive control on the GPU,
E. Adabag, M. Greiff, J. Subosits, and T. Lew, “Differentiable model predictive control on the GPU,” inInt. Conf. on Learning Representa- tions, 2026
2026
-
[25]
Primal-dual iLQR for GPU-accelerated learning and control in legged robots,
L. Amatucci, J. Sousa-Pinto, G. Turrisi, D. Orban, V . Barasuol, and C. Semini, “Primal-dual iLQR for GPU-accelerated learning and control in legged robots,”IEEE Robotics and Automation Letters, vol. 11, no. 1, pp. 1010–1017, 2025
2025
-
[26]
Cusadi: A GPU parallelization framework for symbolic expressions and optimal control,
S. H. Jeon, S. Hong, H. J. Lee, C. Khazoom, and S. Kim, “Cusadi: A GPU parallelization framework for symbolic expressions and optimal control,”IEEE Robotics and Automation Letters, 2024
2024
-
[27]
A performance analysis of parallel dif- ferential dynamic programming on a GPU,
B. Plancher and S. Kuindersma, “A performance analysis of parallel dif- ferential dynamic programming on a GPU,” inWorkshop on Algorithmic Foundations of Robotics, 2018
2018
-
[28]
Curobo: Parallelized collision-free robot motion generation,
B. Sundaralingam, S. K. S. Hari, A. Fishman, C. Garrett, K. Van Wyk, V . Blukis, A. Millane, H. Oleynikova, A. Handa, F. Ramos,et al., “Curobo: Parallelized collision-free robot motion generation,” inProc. IEEE Conf. on Robotics and Automation, 2023
2023
-
[29]
MPCGPU: Real-time nonlinear model predictive control through preconditioned conjugate gradient on the GPU,
E. Adabag, M. Atal, W. Gerard, and B. Plancher, “MPCGPU: Real-time nonlinear model predictive control through preconditioned conjugate gradient on the GPU,” inProc. IEEE Conf. on Robotics and Automation, 2024
2024
-
[30]
Relu-QP: A GPU-accelerated quadratic programming solver for model- predictive control,
A. L. Bishop, J. Z. Zhang, S. Gurumurthy, K. Tracy, and Z. Manchester, “Relu-QP: A GPU-accelerated quadratic programming solver for model- predictive control,” inProc. IEEE Conf. on Robotics and Automation, 2024
2024
-
[31]
Fast monte carlo analysis for 6-dof powered-descent guidance via GPU-accelerated sequential convex programming,
G. M. Chari, A. G. Kamath, P. Elango, and B. Acikmese, “Fast monte carlo analysis for 6-dof powered-descent guidance via GPU-accelerated sequential convex programming,” inAIAA SciTech 2024 Forum, 2024, p. 1762
2024
-
[32]
GATO: GPU-accelerated and batched trajectory optimization for scalable edge model predictive control,
A. Du, E. Adabag, G. Bravo, and B. Plancher, “GATO: GPU-accelerated and batched trajectory optimization for scalable edge model predictive control,” inProc. IEEE Conf. on Robotics and Automation, 2026
2026
-
[33]
CACTO-BIC: Scalable actor-critic learning via biased sampling and GPU-accelerated trajectory optimization,
E. Alboni, P. N. Crestaz, E. Fontanari, and A. Del Prete, “CACTO-BIC: Scalable actor-critic learning via biased sampling and GPU-accelerated trajectory optimization,” 2026, available at https://arxiv.org/abs/2006. 10277
2026
-
[34]
J. Fang and G. Chou, “Safe large-scale robust nonlinear MPC in milliseconds via reachability-constrained system level synthesis on the GPU,” 2026, available at https://arxiv.org/abs/2604.07644
Pith/arXiv arXiv 2026
-
[35]
Model predictive path integral control: From theory to parallel computation,
G. Williams, A. Aldrich, and E. A. Theodorou, “Model predictive path integral control: From theory to parallel computation,”Journal of Guidance, Control, and Dynamics, vol. 40, no. 2, pp. 344–357, 2017
2017
-
[36]
Real-time whole-body control of legged robots with model- predictive path integral control,
J. Alvarez-Padilla, J. Z. Zhang, S. Kwok, J. M. Dolan, and Z. Manch- ester, “Real-time whole-body control of legged robots with model- predictive path integral control,” inProc. IEEE Conf. on Robotics and Automation, 2025
2025
-
[37]
From zero to high-speed racing: An autonomous racing stack,
H. Jardali, D. Pushp, Y . Yu, M. Ali, I. S. Mohamed, A. Murillo- Gonzalez, P. D. Coen, M. A.-M. Khan, R. C. Pulivendula, S. Park, et al., “From zero to high-speed racing: An autonomous racing stack,” 2025, available at https://arxiv.org/abs/2512.06892
arXiv 2025
-
[38]
JAX: composable transformations of Python+NumPy pro- grams,
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclau- rin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne, and Q. Zhang, “JAX: composable transformations of Python+NumPy pro- grams,” 2018
2018
-
[39]
NVIDIA, “cuDSS,” 2026, available at https://developer.nvidia.com/ cudss
2026
-
[40]
AMZ driverless: The full autonomous racing system,
J. Kabzan, M. I. Valls, V . J. Reijgwart, H. F. Hendrikx, C. Ehmke, M. Prajapat, A. B ¨uhler, N. Gosala, M. Gupta, R. Sivanesan,et al., “AMZ driverless: The full autonomous racing system,”Journal of Field Robotics, vol. 37, no. 7, pp. 1267–1294, 2020
2020
-
[41]
Risk-averse model predictive control for racing in adverse conditions,
T. Lew, M. Greiff, F. Djeumou, M. Suminaka, M. Thompson, and J. Subosits, “Risk-averse model predictive control for racing in adverse conditions,” inProc. IEEE Conf. on Robotics and Automation, 2025
2025
-
[42]
Contextual tuning of model predictive control for autonomous racing,
L. P. Fr ¨ohlich, C. K ¨uttel, E. Arcari, L. Hewing, M. N. Zeilinger, and A. Carron, “Contextual tuning of model predictive control for autonomous racing,” inIEEE/RSJ Int. Conf. on Intelligent Robots & Systems, 2022
2022
-
[43]
ZipMPC: Compressed context-dependent MPC cost via imitation learning,
R. Rickenbach, A. A. Lahoud, E. Schaffernicht, M. N. Zeilinger, and J. A. Stork, “ZipMPC: Compressed context-dependent MPC cost via imitation learning,” 2025, available at 2507.13088
arXiv 2025
-
[44]
Actor-critic model predictive control,
A. Romero, Y . Song, and D. Scaramuzza, “Actor-critic model predictive control,” inProc. IEEE Conf. on Robotics and Automation, 2024
2024
-
[45]
Differentiable weights-varying nonlinear MPC via gradient- based policy learning: An autonomous vehicle guidance example,
F. Jahncke, B. Zarrouki, M. Piccinini, J. D’sa, D. Isele, S. Bae, and J. Betz, “Differentiable weights-varying nonlinear MPC via gradient- based policy learning: An autonomous vehicle guidance example,”IEEE Robotics and Automation Letters, pp. 1–8, 2026
2026
-
[46]
Aggressive driving with model predictive path integral control,
G. Williams, P. Drews, B. Goldfain, J. M. Rehg, and E. A. Theodorou, “Aggressive driving with model predictive path integral control,” inProc. IEEE Conf. on Robotics and Automation, 2016
2016
-
[47]
Nocedal and S
J. Nocedal and S. J. Wright,Numerical Optimization, 2nd ed. Springer New York, 2006
2006
-
[48]
Solving quadratic pro- grams with slack variables via ADMM without increasing the problem size,
T. Lew, M. Greiff, J. Subosits, and B. Plancher, “Solving quadratic pro- grams with slack variables via ADMM without increasing the problem size,” inEuropean Control Conference, 2026
2026
-
[49]
Robust optimization for MPC,
B. Houska and M. E. Villanueva, “Robust optimization for MPC,” inHandbook of Model Predictive Control. Springer International Publishing, 2018, pp. 413–443
2018
-
[50]
Truncated back- propagation for bilevel optimization,
A. Shaban, C.-A. Cheng, N. Hatch, and B. Boots, “Truncated back- propagation for bilevel optimization,” inAI & Statistics, 2019
2019
-
[51]
The curse of unrolling: Rate of differentiating through optimization,
D. Scieur, G. Gidel, Q. Bertrand, and F. Pedregosa, “The curse of unrolling: Rate of differentiating through optimization,” inConf. on Neural Information Processing Systems, 2022
2022
-
[52]
S. Gould, B. Fernando, A. Cherian, P. Anderson, R. S. Cruz, and E. Guo, “On differentiating parameterized argmin and argmax problems with application to bi-level optimization,” 2016, available at https://arxiv.org/ abs/1607.05447
Pith/arXiv arXiv 2016
-
[53]
Optnet: Differentiable optimization as a layer in neural networks,
B. Amos and Z. Kolter, “Optnet: Differentiable optimization as a layer in neural networks,” inInt. Conf. on Machine Learning, 2017
2017
-
[54]
The elements of differentiable program- ming,
M. Blondel and V . Roulet, “The elements of differentiable program- ming,” 2024, available at https://arxiv.org/abs/2505.01353
arXiv 2024
-
[55]
Learning convex optimization control policies,
A. Agrawal, S. Barratt, S. Boyd, and B. Stellato, “Learning convex optimization control policies,” inLearning for Dynamics & Control Conference, 2020
2020
-
[56]
Parallel KKT solver in PIQP for multistage optimization,
F. Song, R. Schwan, Y . Chen, and C. N. Jones, “Parallel KKT solver in PIQP for multistage optimization,” 2025, available at https://arxiv.org/ abs/2511.00946
arXiv 2025
-
[57]
PIQP: A proximal interior-point quadratic programming solver,
R. Schwan, Y . Jiang, D. Kuhn, and C. N. Jones, “PIQP: A proximal interior-point quadratic programming solver,” inProc. IEEE Conf. on Decision and Control, 2023
2023
-
[58]
Distributed optimization and statistical learning via the alternating direction method of multipliers,
S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, “Distributed optimization and statistical learning via the alternating direction method of multipliers,”Foundations and Trends in Machine Learning, vol. 3, no. 1, pp. 1–122, 2011
2011
-
[59]
Large-scale admm-based co- design of legged robots,
G. Bravo-Palacios and P. M. Wensing, “Large-scale admm-based co- design of legged robots,” inIEEE/RSJ Int. Conf. on Intelligent Robots & Systems, 2022. 20
2022
-
[60]
Augmented Lagrangian methods for handling terminal constraints in spacecraft trajectory optimization,
B. N. Fanger and R. P. Russell, “Augmented Lagrangian methods for handling terminal constraints in spacecraft trajectory optimization,” Astrodynamics, vol. 10, no. 1, pp. 179–197, 2026
2026
-
[61]
S. G. Krantz and H. R. Parks,The implicit function theorem: history, theory, and applications, 2002, vol. 202, no. 11
2002
-
[62]
Engineering compliance in legged robots via robust co-design,
G. Bravo-Palacios, H. Li, and P. M. Wensing, “Engineering compliance in legged robots via robust co-design,”IEEE/ASME Transactions on Mechatronics, vol. 29, no. 6, pp. 4711–4722, 2024
2024
-
[63]
Learning-based design and control for quadrupedal robots with parallel- elastic actuators,
F. Bjelonic, J. Lee, P. Arm, D. Sako, D. Tateo, J. Peters, and M. Hutter, “Learning-based design and control for quadrupedal robots with parallel- elastic actuators,”IEEE Robotics and Automation Letters, vol. 8, no. 3, pp. 1611–1618, 2023
2023
-
[64]
Control-aware design opti- mization for bio-inspired quadruped robots,
F. De Vincenti, D. Kang, and S. Coros, “Control-aware design opti- mization for bio-inspired quadruped robots,” inIEEE/RSJ Int. Conf. on Intelligent Robots & Systems, 2021
2021
-
[65]
Mujoco: A physics engine for model- based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model- based control,” inIEEE/RSJ Int. Conf. on Intelligent Robots & Systems, 2012
2012
-
[66]
Toward automated vehicle control beyond the stability limits: Drifting along a general path,
J. Y . Goh, T. Goel, and C. J. Gerdes, “Toward automated vehicle control beyond the stability limits: Drifting along a general path,”ASME Journal of Dynamic Systems, Measurement, and Control, vol. 142, no. 2, 2019
2019
-
[67]
A hierarchical adaptive nonlinear model predictive control approach for maximizing tire force usage in autonomous vehicles,
J. Dallas, M. Thompson, J. Goh, and A. Balachandran, “A hierarchical adaptive nonlinear model predictive control approach for maximizing tire force usage in autonomous vehicles,”Journal of Field Robotics, vol. 3, no. 1, pp. 222–242, 2023
2023
-
[68]
Trajectory planning using tire thermodynamics for automated drifting,
T. Kobayashi, T. P. Weber, and J. C. Gerdes, “Trajectory planning using tire thermodynamics for automated drifting,” inIEEE Intelligent Vehicles Symposium, 2024
2024
-
[69]
Seitenkraften am rollenden luftreifen,
E. Fiala, “Seitenkraften am rollenden luftreifen,”VdI Zeitschrift, vol. 96, pp. 973–979, 1954
1954
-
[70]
Optuna: A next-generation hyperparameter optimization framework,
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A next-generation hyperparameter optimization framework,” inACM Int. Conf. on Knowledge Discovery and Data Mining, 2019
2019
-
[71]
Algorithms for hyper- parameter optimization,
J. Bergstra, R. Bardenet, Y . Bengio, and B. K ´egl, “Algorithms for hyper- parameter optimization,” inConf. on Neural Information Processing Systems, 2011
2011
-
[72]
On Neural Differential Equations,
P. Kidger, “On Neural Differential Equations,” Ph.D. dissertation, Uni- versity of Oxford, 2021
2021
-
[73]
GPU acceleration of ADMM for large-scale quadratic programming,
M. Schubiger, G. Banjac, and J. Lygeros, “GPU acceleration of ADMM for large-scale quadratic programming,”Journal of Parallel and Dis- tributed Computing, vol. 144, pp. 55–67, 2020
2020
-
[74]
Diffstack: A differentiable and modular control stack for autonomous vehicles,
P. Karkus, B. Ivanovic, S. Mannor, and M. Pavone, “Diffstack: A differentiable and modular control stack for autonomous vehicles,” in Conf. on Robot Learning, 2023
2023
-
[75]
A differentiable interior- point method in single precision,
J. Arrizabalaga, K. Tracy, and Z. Manchester, “A differentiable interior- point method in single precision,” 2026, available at https://arxiv.org/ abs/2605.17913
Pith/arXiv arXiv 2026
-
[76]
RoboPrec: Enabling reliable embedded computing for robotics by providing accuracy guarantees across mixed-precision datatypes,
A. E. Yilmaz, T. Bourgeat, L. Pentecost, B. Plancher, and S. M. Neuman, “RoboPrec: Enabling reliable embedded computing for robotics by providing accuracy guarantees across mixed-precision datatypes,”IEEE Robotics and Automation Letters, vol. 11, no. 2, pp. 2234–2241, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.