CAMI: Cost-Aware Agent-Guided Multi-Indexing for Semantic Retrieval
Pith reviewed 2026-06-30 11:05 UTC · model grok-4.3
The pith
CAMI selects high-recall enrichment index portfolios for semantic retrieval by solving a budgeted portfolio problem with atomic evaluation and early pruning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAMI formalizes multi-index construction as a budgeted multi-objective portfolio selection problem and solves it through an agentic discovery phase that proposes representation templates, an atomic-unit search procedure that evaluates enrichment-model pairs and recombines them via fidelity-local closure, and a confidence-aware promotion schedule that prunes unpromising configurations early.
What carries the argument
The atomic-unit search procedure that evaluates individual enrichment-model pairs and recombines them via fidelity-local closure to identify synergistic portfolios.
Load-bearing premise
The atomic-unit evaluations plus local closure reliably surface the best combined portfolios without needing to test every possible combination on the entire corpus.
What would settle it
A controlled experiment on a corpus where the highest-recall combinations only emerge after full-corpus evaluation of all pairs would show whether the early-pruning and closure steps miss superior portfolios.
Figures

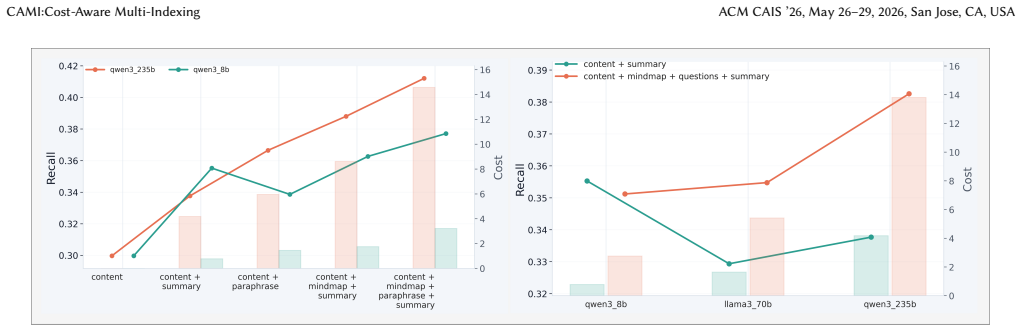
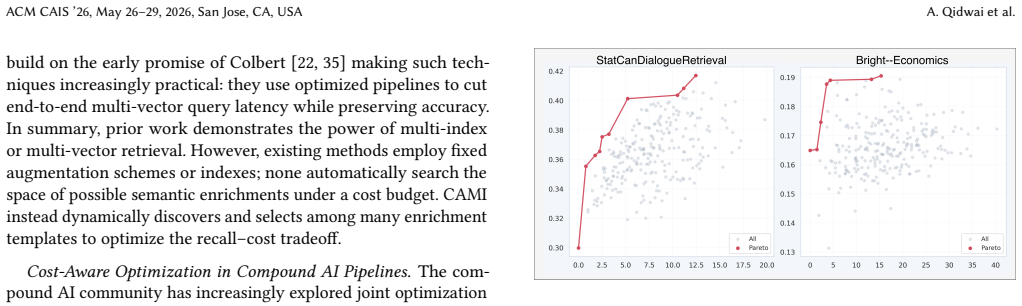
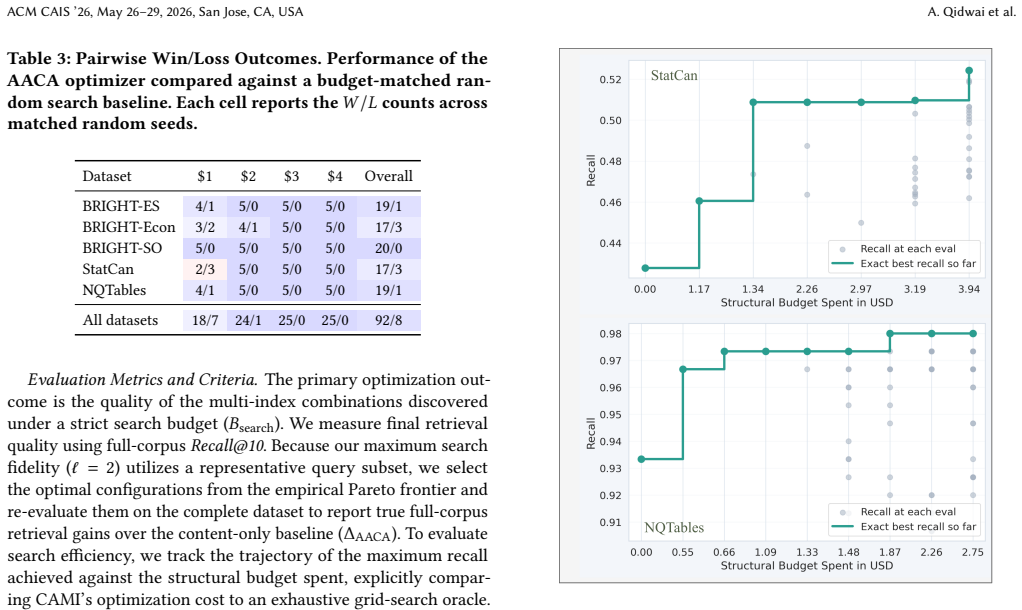
read the original abstract
RAG ingestion pipelines frequently augment search corpus index with semantic enrichment indices (e.g., synthetic queries or summaries generated from corpus chunks) that are subsequently queried alongside the base index to improve retrieval via better alignment between document representations and user intent. While these supplementary representations substantially improve retrieval quality, they introduce a computational bottleneck: the configuration space of enrichment types and generator models is combinatorial, and the cost of exhaustive index-time evaluation scales linearly with corpus size. We introduce CAMI (Cost-Aware Multi-Indexing), a framework that formalizes multi-index construction as a budgeted, multi-objective portfolio selection problem. CAMI targets the upstream decision of which enrichment views to generate and materialize before the retrieval backend is applied. CAMI incorporates three primary mechanisms: (i) an agentic discovery phase that proposes corpus-specific representation templates; (ii) an atomic-unit search procedure that evaluates individual enrichment-model pairs and recombines them via fidelity-local closure to identify synergistic portfolios; and (iii) a confidence-aware promotion schedule that prunes unpromising configurations early, decoupling optimization spend from total corpus size. We evaluate CAMI across diverse retrieval corpora. Our findings reveal that the framework systematically isolates high-recall portfolios under strict budget constraints, outperforming standard content-only baselines in challenging settings by up to 9.4% recall@10. Further, CAMI is able to systematically identify these high-recall portfolios using up to 5x less budget compared to random search baselines, making our approach practical in real production scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CAMI, a framework that formalizes multi-index construction for RAG ingestion as a budgeted multi-objective portfolio selection problem. It uses an agentic discovery phase, an atomic-unit search procedure that evaluates enrichment-model pairs and recombines them via fidelity-local closure, and a confidence-aware promotion schedule to prune configurations early, claiming to identify high-recall portfolios under budget constraints with up to 9.4% recall@10 gains over content-only baselines and 5x less budget than random search.
Significance. If the central claims hold with rigorous validation, the work would be significant for production RAG systems by decoupling optimization cost from corpus size while improving retrieval quality through systematic portfolio selection.
major comments (2)
- Abstract: performance numbers (9.4% recall@10 lift, 5x budget reduction) are stated without any accompanying dataset descriptions, baseline details, error bars, ablation results, or statistical tests, so the central empirical claims cannot be assessed for soundness.
- Abstract (atomic-unit search procedure and fidelity-local closure): the headline efficiency and quality claims rest on the assumption that local fidelity evaluations and the closure operator capture synergistic interactions that only manifest at full-corpus scale; no evidence or argument is supplied that non-local synergies are not systematically missed by early pruning, which directly undermines the budgeted-search superiority claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: performance numbers (9.4% recall@10 lift, 5x budget reduction) are stated without any accompanying dataset descriptions, baseline details, error bars, ablation results, or statistical tests, so the central empirical claims cannot be assessed for soundness.
Authors: We agree that the abstract presents the headline results at a high level without sufficient context for immediate assessment. While abstracts have strict length limits, we will revise the abstract to briefly reference the diverse retrieval corpora used and explicitly direct readers to Sections 4 and 5 for full details on datasets, baselines, ablations, error bars, and statistical tests. This change will make the claims more transparent without expanding the abstract beyond reasonable bounds. revision: yes
-
Referee: Abstract (atomic-unit search procedure and fidelity-local closure): the headline efficiency and quality claims rest on the assumption that local fidelity evaluations and the closure operator capture synergistic interactions that only manifest at full-corpus scale; no evidence or argument is supplied that non-local synergies are not systematically missed by early pruning, which directly undermines the budgeted-search superiority claim.
Authors: The atomic-unit search with fidelity-local closure is formulated to identify synergistic portfolios by recombining locally evaluated enrichment-model pairs, with the portfolio selection objective providing the basis for why local fidelity is a reasonable proxy. We acknowledge that the current manuscript does not explicitly argue against systematic omission of non-local synergies. We will add a new subsection in the methodology explaining this rationale grounded in the budgeted multi-objective formulation, and include supporting experiments on smaller corpora where full-scale evaluation is tractable to empirically validate that the approach does not systematically miss high-value configurations. revision: yes
Circularity Check
No derivation chain or equations present; circularity not applicable
full rationale
The manuscript abstract and description introduce CAMI as a framework with three mechanisms (agentic discovery, atomic-unit search with fidelity-local closure, confidence-aware schedule) and report empirical results, but contain no equations, formal derivations, or load-bearing mathematical steps. No self-citations, ansatzes, or fitted inputs are quoted that reduce a claimed prediction to its inputs by construction. Performance claims rest on experimental evaluation rather than a first-principles derivation. Per the rules, absence of any quotable reduction means score 0 with empty steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. 2026. GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning. arXiv:2507.1945...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Elron Bandel, Yotam Perlitz, Elad Venezian, Roni Friedman, Ofir Arviv, Matan Orbach, Shachar Don-Yehiya, Dafna Sheinwald, Ariel Gera, Leshem Choshen, et al
-
[3]
InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: System Demonstrations)
Unitxt: Flexible, shareable and reusable data preparation and evaluation for generative ai. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: System Demonstrations). 207–215
2024
- [4]
- [5]
-
[6]
Lingjiao Chen, Matei Zaharia, and James Zou. 2023. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance. arXiv:2305.05176 [cs.LG] https://arxiv.org/abs/2305.05176
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Peter Baile Chen, Tomer Wolfson, Michael Cafarella, and Dan Roth
-
[8]
arXiv:2504.03598 [cs.CL] https://arxiv.org/abs/2504.03598
EnrichIndex: Using LLMs to Enrich Retrieval Indices Offline. arXiv:2504.03598 [cs.CL] https://arxiv.org/abs/2504.03598
-
[9]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. 2024. Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference. arXiv:2403.04132 [cs.AI] https://arxiv.org/abs/2403. 04132
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [10]
-
[11]
Cormack, Charles L A Clarke, and Stefan Buettcher
Gordon V. Cormack, Charles L A Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval(Boston, MA, USA)(SIGIR ’09). Association for Computing Machinery, New York, NY, USA, 758–759...
-
[12]
Jonathan Larson Darren Edge, Ha Trinh. 2024. LazyGraphRAG: Setting a new standard for quality and cost. https://www.microsoft.com/en-us/research/blog/ lazygraphrag-setting-a-new-standard-for-quality-and-cost/
2024
-
[13]
Laxman Dhulipala, Majid Hadian, Rajesh Jayaram, Jason Lee, and Vahab Mir- rokni. 2024. MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings. arXiv:2405.19504 [cs.DS] https://arxiv.org/abs/2405.19504
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
-
[15]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2025. From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv:2404.16130 [cs.CL] https://arxiv.org/abs/2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Abdellah Ghassel, Ian Robinson, Gabriel Tanase, Hal Cooper, Bryan Thompson, Zhen Han, Vassilis Ioannidis, Soji Adeshina, and Huzefa Rangwala. 2025. Hierar- chical Lexical Graph for Enhanced Multi-Hop Retrieval. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 (KDD ’25). ACM, 4457–4466. doi:10.1145/3711896.3737233
-
[17]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. 2025. A Survey on LLM-as- a-Judge. arXiv:2411.15594 [cs.CL] https://arxiv.org/abs/2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su
-
[20]
Hipporag: Neurobiologically inspired long-term memory for large language models, 2025
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. arXiv:2405.14831 [cs.CL] https://arxiv.org/abs/2405.14831
-
[21]
Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. 2025. From RAG to Memory: Non-Parametric Continual Learning for Large Language Models. arXiv:2502.14802 [cs.CL] https://arxiv.org/abs/2502.14802
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [22]
-
[23]
Qihao Huang. 2026. LLM-Guided Beam Search for Decision Graph Optimization with Dynamic Prompting(WSDM ’26). Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/3773966.3778003
- [24]
- [25]
-
[26]
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and Minjoon Seo
-
[27]
arXiv:2310.08491 [cs.CL] https://arxiv.org/abs/2310.08491
Prometheus: Inducing Fine-grained Evaluation Capability in Language Models. arXiv:2310.08491 [cs.CL] https://arxiv.org/abs/2310.08491
- [28]
-
[29]
Nikolaos Livathinos, Christoph Auer, Maksym Lysak, Ahmed Nassar, Michele Dolfi, Panos Vagenas, Cesar Berrospi Ramis, Matteo Omenetti, Kasper Dinkla, Yusik Kim, et al. 2025. Docling: An efficient open-source toolkit for ai-driven document conversion.arXiv preprint arXiv:2501.17887(2025)
-
[30]
Xing Han Lu, Siva Reddy, and Harm de Vries. 2023. The StatCan Dialogue Dataset: Retrieving Data Tables through Conversations with Genuine Intents. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2799–2829. doi:10.18653/v1/2023.eacl-main.206
-
[31]
Sadegh Mahdavi, Branislav Kisacanin, Shubham Toshniwal, Wei Du, Ivan Moshkov, George Armstrong, Renjie Liao, Christos Thrampoulidis, and Igor Gitman. 2025. Scaling Generative Verifiers For Natural Language Mathematical Proof Verification And Selection. arXiv:2511.13027 [cs.AI] https://arxiv.org/abs/ 2511.13027
-
[32]
Factor, Shila Ofek-Koifman, Paula Ta-Shma, and Assaf Toledo
Matan Orbach, Ohad Eytan, Benjamin Sznajder, Ariel Gera, Odellia Boni, Yoav Kantor, Gal Bloch, Omri Levy, Hadas Abraham, Nitzan Barzilay, Eyal Shnarch, Michael E. Factor, Shila Ofek-Koifman, Paula Ta-Shma, and Assaf Toledo. 2025. An Analysis of Hyper-Parameter Optimization Methods for Retrieval Augmented Generation. arXiv:2505.03452 [cs.CL] https://arxiv....
- [33]
- [34]
-
[35]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 3982–3992
2019
-
[36]
2009.The probabilistic relevance frame- work: BM25 and beyond
Stephen Robertson and Hugo Zaragoza. 2009.The probabilistic relevance frame- work: BM25 and beyond. Vol. 4. Now Publishers Inc
2009
-
[37]
Matthew Russo, Sivaprasad Sudhir, Gerardo Vitagliano, Chunwei Liu, Tim Kraska, Samuel Madden, and Michael J. Cafarella. 2025. Abacus: A Cost-Based Optimizer for Semantic Operator Systems.CoRRabs/2505.14661 (2025). arXiv:2505.14661 doi:10.48550/ARXIV.2505.14661
- [38]
- [39]
-
[40]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. arXiv:2401.18059 [cs.CL] https://arxiv.org/abs/2401. 18059
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Jan Luca Scheerer, Matei Zaharia, Christopher Potts, Gustavo Alonso, and Omar Khattab. 2025. WARP: An Efficient Engine for Multi-Vector Retrieval. InProceed- ings of the 48th International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval (SIGIR ’25). ACM, 2504–2512. doi:10.1145/3726302. 3729904
- [42]
-
[43]
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing. arXiv:2410.12189 [cs.DB] https://arxiv.org/abs/2410.12189
- [44]
-
[45]
Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. 2025. Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG. arXiv:2501.09136 [cs.AI] https://arxiv.org/abs/2501.09136
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Dimitris Stripelis, Zijian Hu, Jipeng Zhang, Zhaozhuo Xu, Alay Dilipbhai Shah, Han Jin, Yuhang Yao, Salman Avestimehr, and Chaoyang He. 2024. CAMI:Cost-Aware Multi-Indexing ACM CAIS ’26, May 26–29, 2026, San Jose, CA, USA TensorOpera Router: A Multi-Model Router for Efficient LLM Inference. arXiv:2408.12320 [cs.AI] https://arxiv.org/abs/2408.12320
-
[47]
Siegel, Michael Tang, Ruoxi Sun, Jinsung Yoon, Sercan O
Hongjin Su, Howard Yen, Mengzhou Xia, Weijia Shi, Niklas Muennighoff, Han yu Wang, Haisu Liu, Quan Shi, Zachary S. Siegel, Michael Tang, Ruoxi Sun, Jinsung Yoon, Sercan O. Arik, Danqi Chen, and Tao Yu. 2025. BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval. arXiv:2407.12883 [cs.CL] https://arxiv.org/abs/2407.12883
-
[48]
Lindsey Linxi Wei, Shreya Shankar, Sepanta Zeighami, Yeounoh Chung, Fatma Ozcan, and Aditya G. Parameswaran. 2026. Multi-Objective Agentic Rewrites for Unstructured Data Processing. arXiv:2512.02289 [cs.DB] https://arxiv.org/abs/ 2512.02289
-
[49]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Peiru Yang, Xintian Li, Zhiyang Hu, Jiapeng Wang, Jinhua Yin, Huili Wang, Lizhi He, Shuai Yang, Shangguang Wang, Yongfeng Huang, and Tao Qi. 2025. HeteRAG: A Heterogeneous Retrieval-augmented Generation Framework with Decoupled Knowledge Representations. arXiv:2504.10529 [cs.IR] https://arxiv.org/abs/2504. 10529
- [51]
- [52]
- [53]
-
[54]
Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, and Danqi Chen
-
[55]
arXiv:2310.07641 [cs.CL] https://arxiv.org/abs/2310.07641
Evaluating Large Language Models at Evaluating Instruction Following. arXiv:2310.07641 [cs.CL] https://arxiv.org/abs/2310.07641
-
[56]
Nan Zhang, Prafulla Kumar Choubey, Alexander Fabbri, Gabriel Bernadett- Shapiro, Rui Zhang, Prasenjit Mitra, Caiming Xiong, and Chien-Sheng Wu. 2025. SiReRAG: Indexing Similar and Related Information for Multihop Reasoning. arXiv:2412.06206 [cs.CL] https://arxiv.org/abs/2412.06206
-
[57]
Zihao Zhang, Hui Wei, Kenan Jiang, Shijia Pan, Shu Kai, and Fei Liu
-
[58]
arXiv:2505.14656 [cs.AI] https://arxiv.org/abs/2505.14656
Cost-Awareness in Tree-Search LLM Planning: A Systematic Study. arXiv:2505.14656 [cs.AI] https://arxiv.org/abs/2505.14656
-
[59]
Eckart Zitzler and Lothar Thiele. 2002. Multiobjective evolutionary algorithms: a comparative case study and the strength Pareto approach.IEEE transactions on Evolutionary Computation3, 4 (2002), 257–271. A Appendix: Cost Accounting and Token Pricing Model To calculate the real-world dollar cost for any LLM invoca- tion—whether for generating an EDR text ...
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.