Experience Graphs: The Data Foundation for Self-Improving Agents
Pith reviewed 2026-06-30 04:05 UTC · model grok-4.3
The pith
Treating experience graphs as first-class database state turns agents into stateless compute with crash recovery and scaling as byproducts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
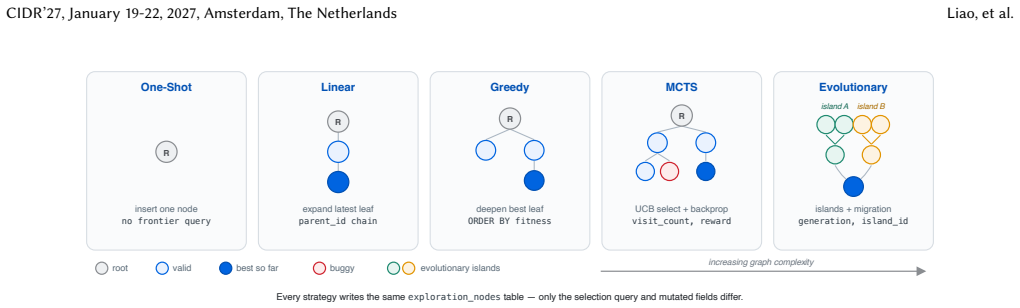
The central claim is that when the database owns the experience graph, agents become stateless compute, and crash recovery, horizontal scaling, and a closed-loop training flywheel emerge as architectural byproducts. Frontier selection is a query, cross-session reuse is vector-seeded graph retrieval, training-data extraction is a materialized view, and reconstructing what an agent knew at any past step is a time-travel query.
What carries the argument
The experience graph (executable artifacts, tool outputs, rewards, sibling comparisons, and causal lineage) managed as first-class queryable database state by Trellis so that search patterns become database access patterns.
If this is right
- Frontier selection reduces to a database query.
- Cross-session reuse reduces to vector-seeded graph retrieval.
- Training-data extraction reduces to a materialized view.
- Reconstructing an agent's past knowledge reduces to a time-travel query.
- In the KernelEvolve case, cross-session reuse reached target speedup roughly 10x faster at 52% lower token cost.
Where Pith is reading between the lines
- Multiple independent agent instances could share and incrementally enrich the same experience graph without custom synchronization code.
- Enterprises could audit or replay agent decision paths through standard database audit logs and time-travel features.
- The model could extend to multi-agent coordination where one agent's outputs become another's starting frontier via shared graph queries.
Load-bearing premise
Search over experience graphs is fundamentally a database access pattern rather than a custom session-based computation.
What would settle it
A controlled comparison showing that expressing agent frontier selection, reuse, and training extraction as database queries incurs more than marginal overhead versus optimized in-memory session logs on the same workload.
Figures



read the original abstract
The database community has repeatedly advanced the state of the art by recognizing that new workloads demand new system architectures. We argue that long-horizon agentic tasks -- code generation, scientific discovery, hardware design -- are such a workload. These agents explore: they generate artifacts, execute tools, observe failures, branch, and repair over hundreds of steps. This search produces a structured object we call an experience graph: executable artifacts, tool outputs, rewards, sibling comparisons, and causal lineage. Yet existing agent frameworks treat this experience as disposable state -- JSON checkpoints and session logs that cannot be recovered after a crash, queried across users, or materialized into training data. We propose Trellis: a data foundation that treats the experience graph as first-class, governed, queryable database state. The core insight is that search over experience graphs is a database access pattern. Frontier selection is a query, cross-session reuse is vector-seeded graph retrieval, training-data extraction is a materialized view, and reconstructing what an agent knew at any past step is a time-travel query. When the database owns the experience graph, agents become stateless compute, and crash recovery, horizontal scaling, and a closed-loop training flywheel emerge as architectural byproducts. We ground the design in KernelEvolve, a production accelerator-kernel optimizer at Meta, where cross-session reuse reaches a target speedup roughly 10x faster at 52% lower token cost. More broadly, Trellis turns inference-time search from disposable computation into a durable institutional asset: logs made databases reliable; experience graphs may make agents cumulative.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that long-horizon agentic tasks (code generation, scientific discovery) generate a structured 'experience graph' of artifacts, tool outputs, rewards, and lineage. Existing frameworks treat this as disposable session state, whereas the proposed Trellis system makes the graph first-class, governed, queryable database state. The core insight is that search operations map to database primitives (frontier selection as query, cross-session reuse as vector-seeded retrieval, training extraction as materialized view, time-travel as historical query). This renders agents stateless compute, from which crash recovery, horizontal scaling, and a closed-loop training flywheel emerge automatically. The design is grounded in the KernelEvolve production deployment at Meta, where cross-session reuse reached target speedup roughly 10x faster at 52% lower token cost.
Significance. If the database-mapping premise holds and generalizes, the work could reorient agent architectures from ephemeral sessions to durable institutional assets, analogous to how logs enabled reliable distributed systems. The production anecdote supplies an existence proof for cross-session reuse benefits, but the significance remains prospective pending broader empirical validation across tasks and scales.
major comments (2)
- [Abstract] Abstract: the central claim that 'search over experience graphs is a database access pattern' (with frontier selection as query, etc.) is load-bearing for the stateless-agents and byproduct-emergence argument, yet no concrete query examples, schema, or index design are supplied to demonstrate the mapping.
- [Abstract] Abstract: the KernelEvolve grounding ('roughly 10x faster at 52% lower token cost') is presented without baselines, session counts, variance, controls, or comparison to non-Trellis implementations; this weakens the evidential support for the architectural claims.
minor comments (1)
- [Abstract] The manuscript introduces 'Trellis' and 'experience graph' without relating them to prior database or agent literature on persistent state or graph query workloads.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for identifying the load-bearing elements of the central argument. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'search over experience graphs is a database access pattern' (with frontier selection as query, etc.) is load-bearing for the stateless-agents and byproduct-emergence argument, yet no concrete query examples, schema, or index design are supplied to demonstrate the mapping.
Authors: We agree the mapping is central and that the abstract presents it conceptually. The revised manuscript will add a new subsection with (1) a concrete relational schema for experience-graph nodes and edges, (2) example queries (in SQL extended with vector and graph operators) that realize frontier selection, cross-session retrieval, and time-travel, and (3) a brief discussion of index choices (vector indexes on embeddings, B-tree indexes on lineage timestamps, and graph indexes on causal edges). revision: yes
-
Referee: [Abstract] Abstract: the KernelEvolve grounding ('roughly 10x faster at 52% lower token cost') is presented without baselines, session counts, variance, controls, or comparison to non-Trellis implementations; this weakens the evidential support for the architectural claims.
Authors: The cited figures are observational outcomes from a live production deployment. Because of Meta's confidentiality policies we cannot release the requested session counts, variance statistics, or controlled non-Trellis baselines. In revision we will (a) qualify the claim as an existence proof rather than a controlled experiment and (b) add an explicit limitations paragraph describing what data cannot be shared. revision: partial
- Full disclosure of session counts, variance, controls, and non-Trellis comparisons for the KernelEvolve production deployment, which is precluded by Meta confidentiality requirements.
Circularity Check
Architectural proposal with no derivation chain or fitted quantities
full rationale
The paper advances an architectural proposal that experience graphs should be first-class database state, with the claim that this mapping makes search operations (frontier selection, reuse, training extraction) into database primitives and thereby yields stateless agents plus byproducts such as crash recovery and scaling. No equations, parameters, or closed mathematical derivations are present; the central premise is asserted directly as an insight rather than derived from prior results. No self-citations, ansatzes, or renamings reduce any claim to its own inputs. The KernelEvolve deployment is cited only as grounding evidence, not as a load-bearing self-referential step. The argument is therefore self-contained as a design argument rather than a derivation that collapses by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Search over experience graphs is a database access pattern (frontier selection is a query, cross-session reuse is vector-seeded graph retrieval, training-data extraction is a materialized view).
invented entities (2)
-
experience graph
no independent evidence
-
Trellis
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Algorithmic Superintelligence Inc. 2025. OpenEvolve: Open- Source Evolutionary Coding Agent.https://github.com/ algorithmicsuperintelligence/openevolve
2025
-
[2]
Renzo Angles, Marcelo Arenas, Pablo Barceló, Aidan Hogan, Juan Reutter, and Domagoj Vrgoč. 2017. An Introduction to Graph Data Management.Springer(2017)
2017
-
[3]
Anthropic. 2025. Claude Code: An Agentic Coding Tool.https://docs. anthropic.com/en/docs/claude-code
2025
-
[4]
Anthropic. 2025. Project Glasswing: Securing Critical Software for the AI Era.https://www.anthropic.com/glasswing
2025
-
[5]
Browne, Edward Powley, Daniel Whitehouse, Simon M
Cameron B. Browne, Edward Powley, Daniel Whitehouse, Simon M. Lucas, Peter I. Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. 2012. A Survey of Monte Carlo Tree Search Methods.IEEE Transactions on Computational Intelligence and AI in Games4, 1 (2012), 1–43
2012
-
[6]
Nicholas Carlini. 2026. Building a C Compiler with a Team of Par- allel Claudes.https://www.anthropic.com/engineering/building-c- compiler
2026
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating Large Language Models Trained on Code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.arXiv preprint arXiv:2504.19413 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Joel Coburn, Chunqiang Tang, Sameer Abu Asal, Neeraj Agrawal, Raviteja Chinta, Harish Dixit, Brian Dodds, Saritha Dwarakapuram, Amin Firoozshahian, Cao Gao, et al. 2025. Meta’s Second Generation AI Chip: Model-Chip Co-Design and Productionization Experiences. In Proceedings of the 52nd Annual International Symposium on Computer Architecture. 1689–1702
2025
-
[10]
James C Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christo- pher Frost, Jeffrey John Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, et al. 2013. Spanner: Google’s Globally Distributed Database.ACM Transactions on Computer Systems (TOCS)31, 3 (2013), 1–22
2013
-
[11]
Benoit Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Mar- tin Hentschel, Jiansheng Huang, et al . 2016. The snowflake elastic data warehouse. InProceedings of the 2016 International Conference on Management of Data. 215–226
2016
-
[12]
Databricks AI Research Team. 2026. Memory Scaling for AI Agents. https://www.databricks.com/blog/memory-scaling-ai-agents
2026
-
[13]
Marina Favaro and Jack Clark. 2026. When AI Builds Itself.https:// www.anthropic.com/institute/recursive-self-improvement. Anthropic Institute, 2026
2026
-
[14]
Nadime Francis, Alastair Green, Paolo Guagliardo, Leonid Libkin, To- bias Lindaaker, Victor Marsault, Stefan Plantikow, Mats Rydberg, Pe- tra Selmer, and Andrés Taylor. 2018. Cypher: An Evolving Query Language for Property Graphs.Proceedings of the 2018 International Conference on Management of Data (SIGMOD)(2018), 1433–1445
2018
-
[15]
2026.Sakana Fugu Technical Report
Fugu Team, Sakana AI. 2026.Sakana Fugu Technical Report. Technical Report. June 2026
2026
-
[16]
Daya Guo, Dejian Yang, He Zhang, Junxiao Song, Runxin Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Rein- forcement Learning.arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Noy, Christopher Olston, Neoklis Polyzotis, Sudip Roy, and Steven Euijong Whang
Alon Halevy, Flip Korn, Natalya F. Noy, Christopher Olston, Neoklis Polyzotis, Sudip Roy, and Steven Euijong Whang. 2016. Goods: Or- ganizing Google’s Datasets. InProceedings of the 2016 International Conference on Management of Data (SIGMOD). ACM, New York, NY, USA, 795–806
2016
-
[18]
Hellerstein, Jose Faleiro, Joseph E
Joseph M. Hellerstein, Jose Faleiro, Joseph E. Gonzalez, Johann Schleier- Smith, Vikram Sreekanti, Alexey Tumanov, and Chenggang Wu. 2019. Serverless Computing: One Step Forward, Two Steps Back. InConfer- ence on Innovative Data Systems Research (CIDR)
2019
-
[19]
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, et al
-
[20]
Memory in the Age of AI Agents: A Survey—Forms, Functions and Dynamics.arXiv preprint arXiv:2512.13564(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Zhengyao Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Jacenko, and Yuxiang Wu. 2025. AIDE: The Machine Learning Engineer Agent.arXiv preprint arXiv:2502.13138(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-Scale Similarity Search with GPUs.IEEE Transactions on Big Data7, 3, 535–547
2019
-
[23]
Andrej Karpathy. 2026. autoresearch.https://github.com/karpathy/ autoresearch
2026
-
[24]
Levente Kocsis and Csaba Szepesvári. 2006. Bandit Based Monte- Carlo Planning. InEuropean Conference on Machine Learning. Springer, 282–293
2006
-
[25]
Gang Liao and Daniel J. Abadi. 2023. FileScale: Fast and Elastic Meta- data Management for Distributed File Systems. InProceedings of the 2023 ACM Symposium on Cloud Computing (SoCC). 459–474
2023
- [26]
-
[27]
Gang Liao, Hongsen Qin, Ying Wang, Alicia Golden, Michael Kuchnik, Yavuz Yetim, Jia Jiunn Ang, Chunli Fu, Yihan He, Samuel Hsia, Zewei Jiang, Dianshi Li, Liyuan Li, Uladzimir Pashkevich, Varna Puvvada, CIDR’27, January 19-22, 2027, Amsterdam, The Netherlands Liao, et al. Feng Shi, Matt Steiner, Ruichao Xiao, Nathan Yan, Xiayu Yu, Zhou Fang, Roman Levenste...
-
[28]
Gang Liao, Hongsen Qin, Ying Wang, Alicia Golden, Michael Kuch- nik, Yavuz Yetim, Ruichao Xiao, Jia Jiunn Ang, Chunli Fu, Yihan He, Samuel Hsia, Zewei Jiang, Roman Levenstein, Dianshi Li, Liyuan Li, Ajit Mathews, Varna Puvvada, Feng Shi, Nathan Yan, Xiayu Yu, Uladz- imir Pashkevich, Matt Steiner, Carole-Jean Wu, and Gaoxiang Liu
-
[29]
InProceedings of the 52nd International Symposium on Computer Architecture (ISCA)
KernelEvolve: Scaling Agentic Kernel Coding for Heteroge- neous AI Accelerators at Meta. InProceedings of the 52nd International Symposium on Computer Architecture (ISCA)
-
[30]
Gang Liao, Yavuz Yetim, Ruichao Xiao, Zewei Jiang, Raghav Boinepalli, Sheela Yadawad, Liyuan Li, Nathan Yan, Ajit Mathews, Chunqiang Tang, Carole-Jean Wu, and Gaoxiang Liu. 2026. KernelEvolve: How Meta’s Ranking Engineer Agent Optimizes AI Infrastructure. https://engineering.fb.com/2026/04/02/developer-tools/kernelevolve- how-metas-ranking-engineer-agent-...
2026
-
[31]
Long-Ji Lin. 1992. Self-Improving Reactive Agents Based on Rein- forcement Learning, Planning and Teaching.Machine Learning8, 3–4 (1992), 293–321
1992
-
[32]
Meta Platforms. 2025. Axiom: A Cost-Based Optimizer for Multi-Modal Query Planning.https://github.com/facebookincubator/axiom. Open source
2025
-
[33]
Rusu, Joel Veness, Marc G
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, An- dreas K. Fidjeland, Georg Ostrovski, et al. 2015. Human-Level Control Through Deep Reinforcement Learning.Nature518, 7540 (2015), 529– 533
2015
-
[34]
Nous Research. 2025. Hermes Agent.https://hermes-agent. nousresearch.com/docs
2025
-
[35]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Ko- zlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebas- tian Nowozin, Pushmeet Kohli, and Matej Balog. 2025. AlphaEvolve: A Coding Agent for Scientific...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
OpenAI. 2025. Codex: A Cloud-Based Software Engineering Agent. https://openai.com/index/introducing-codex/
2025
-
[37]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems.arXiv preprint arXiv:2310.08560(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST)
2023
-
[39]
Pedro Pedreira, Orri Erling, Masha Basmanova, Kevin Wilfong, Laith Sakka, Krishna Pai, Wei He, and Biswapesh Chattopadhyay. 2022. Velox: Meta’s Unified Execution Engine.Proceedings of the VLDB Endowment15, 12 (2022), 3372–3384
2022
-
[40]
Alberto Pepe, Chien-Yu Lin, Despoina Magka, Bilge Acun, Yannan Nel- lie Wu, Anton Protopopov, Carole-Jean Wu, and Yoram Bachrach
-
[41]
Agentic Discovery of Neural Architectures: AIRA-Compose and AIRA-Design.arXiv preprint arXiv:2605.15871(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christo- pher D. Manning, and Chelsea Finn. 2023. Direct Preference Optimiza- tion: Your Language Model Is Secretly a Reward Model. InAdvances in Neural Information Processing Systems
2023
-
[43]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Graphiti: Building Real-Time Knowledge Graphs for AI Agents.arXiv preprint arXiv:2501.13956(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Kai Olav Ellefsen, et al . 2024. Mathematical Discoveries from Program Search with Large Language Models. InNature, Vol. 625. 468–475
2024
-
[45]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. 2017. Mastering the Game of Go Without Human Knowledge.Nature550, 7676 (2017), 354–359
2017
-
[47]
Abadi, Adam Batkin, Xuedong Chen, Mitch Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O’Neil, Pat O’Neil, Alex Rasin, Nga Tran, and Stan Zdonik
Michael Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O’Neil, Pat O’Neil, Alex Rasin, Nga Tran, and Stan Zdonik. 2005. C-Store: A Column-Oriented DBMS. InProceedings of the 31st International Conference on Very Large Data Bases (VLDB). 553–564
2005
-
[48]
One Size Fits All
Michael Stonebraker and Ugur Çetintemel. 2005. “One Size Fits All”: An Idea Whose Time Has Come and Gone.Proceedings of the 21st International Conference on Data Engineering (ICDE)(2005), 2–11
2005
-
[49]
John Sviokla. 2026. The Most Important Idea in AI: Recursive Self- Improvement (RSI).https://www.forbes.com/sites/johnsviokla/2026/ 03/16/the-most-important-idea-in-ai-recursive-self-improvement- rsi/. Forbes, March 2026
2026
-
[50]
Miller, Abhishek Charnalia, Derek Dunfield, Carole-Jean Wu, Pontus Stene- torp, Nicola Cancedda, Jakob Nicolaus Foerster, and Yoram Bachrach
Edan Toledo, Karen Hambardzumyan, Martin Josifoski, Rishi Hazra, Nicolas Baldwin, Alexis Audran-Reiss, Michael Kuchnik, Despoina Magka, Minqi Jiang, Alisia Maria Lupidi, Andrei Lupu, Roberta Raileanu, Kelvin Niu, Tatiana Shavrina, Jean-Christophe Gagnon- Audet, Michael Shvartsman, Shagun Sodhani, Alexander H. Miller, Abhishek Charnalia, Derek Dunfield, Ca...
- [51]
-
[52]
Manasi Vartak, Harihar Subramanyam, Wei-En Lee, Srinidhi Viswanathan, Saadiyah Husnoo, Samuel Madden, and Matei Zaharia
-
[53]
InWorkshop on Human-In-the-Loop Data Analytics (HILDA)
ModelDB: A System for Machine Learning Model Management. InWorkshop on Human-In-the-Loop Data Analytics (HILDA). ACM, New York, NY, USA
-
[54]
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. 2025. The AI Scientist- v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search.arXiv preprint arXiv:2504.08066(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Justin Young. 2025. Effective Harnesses for Long-Running Agents.https://www.anthropic.com/engineering/effective-harnesses- for-long-running-agents. Anthropic Engineering, November 2025
2025
-
[56]
Matei Zaharia, Andrew Chen, Aaron Davidson, Ali Ghodsi, Sue Ann Hong, Andy Konwinski, Siddharth Murching, Tomas Nykodym, Paul Ogilvie, Mani Parkhe, Fen Xie, and Corey Zumar. 2018. Accelerating the Machine Learning Lifecycle with MLflow.IEEE Data Engineering Bulletin41, 4 (2018), 39–45
2018
-
[57]
Matei Zaharia, Kasey Uhlenhuth, and Corey Zumar. 2026. Intro- ducing Omnigent: A Meta-Harness to Combine, Control and Share Your Agents.https://www.databricks.com/blog/introducing-omnigent. Databricks, June 2026
2026
-
[58]
Zhipu AI. 2026. GLM-5.2: Built for Long-Horizon Tasks.https://z.ai/ blog/glm-5.2. June 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.