SABER-Math: Automated Benchmark for Information Retrieval Evaluation in Mathematics
Pith reviewed 2026-06-30 04:37 UTC · model grok-4.3
The pith
SABER-Math creates the first automated benchmark for mathematical information retrieval without expert annotators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SABER-Math is the first fully automated benchmark for mathematical IR evaluation. Starting from 283K high-school problems with solutions, it extracts LLM-generated summaries and topics, discovers relevant documents via topic-based and lexical similarities, and produces fine-grained relevance ratings through Swiss-style LLM preference tournaments, enabling evaluation of lexical, math-specific, and embedding retrievers without human experts.
What carries the argument
The Swiss-style LLM preference tournament that converts pairwise preferences into fine-grained relevance ratings for candidate documents.
If this is right
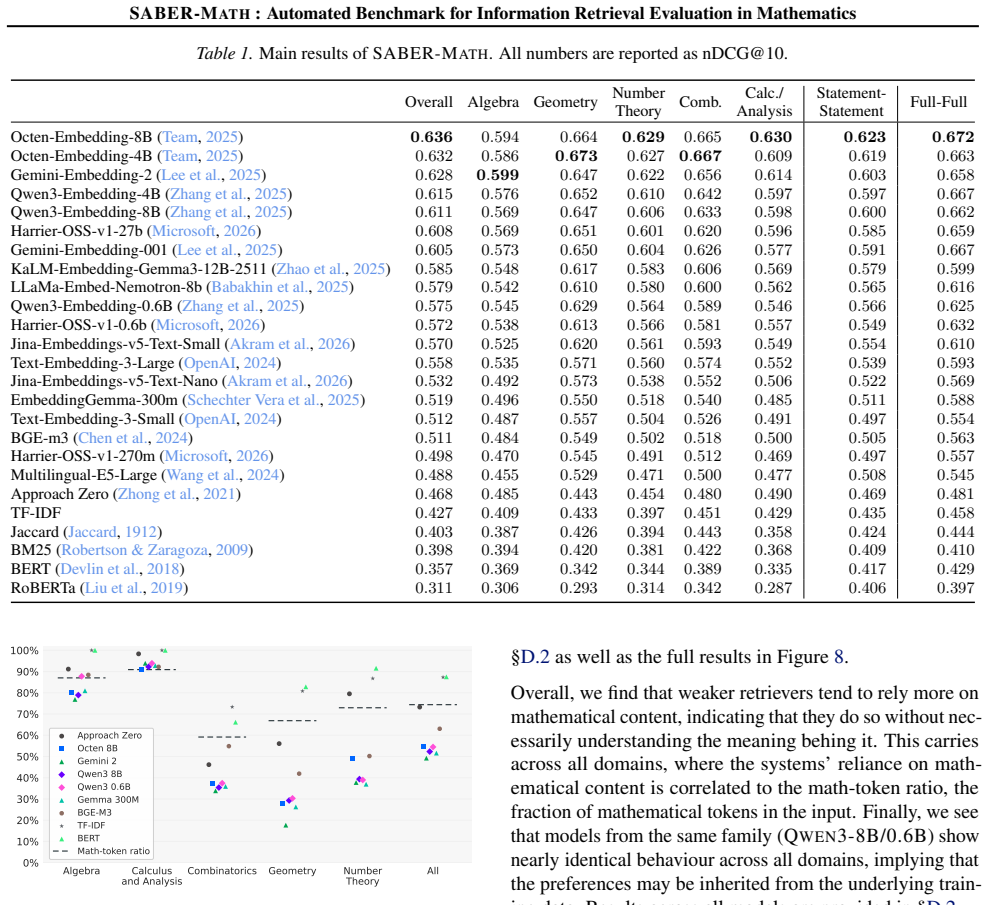
- Modern embedding models substantially outperform classical and math-specific baselines on mathematical retrieval tasks.
- Even the strongest retrievers still underperform in symbol-heavy domains such as Algebra and Calculus.
- General-purpose IR benchmarks such as MTEB do not reliably predict performance on mathematical content.
Where Pith is reading between the lines
- Teams building math-aware agents may need separate retriever testing on domain-specific data rather than relying on general benchmarks.
- The automated construction method could be adapted to create similar benchmarks for retrieval in physics or programming domains.
- Symbol handling in current embeddings may need targeted improvements to close the gap observed in algebra and calculus.
Load-bearing premise
LLM-generated solution summaries, topic tags, and Swiss-style preference tournaments produce accurate fine-grained relevance ratings that reflect true mathematical relevance.
What would settle it
A side-by-side comparison of SABER-Math ratings against ratings assigned by human mathematics experts on the same set of queries and documents.
Figures



read the original abstract
As agentic AI systems tackle more complex mathematical tasks, they increasingly rely on information retrieval (IR) to search problem databases, theorem libraries, and educational resources. However, choosing the right retriever remains difficult, as it is infeasible to directly isolate its effect on downstream performance. On the other hand, existing retrieval-specific benchmarks often fail to capture fine-grained mathematical relevance, penalizing relevant documents. We address this gap by introducing SABER-Math, the first fully automated benchmark for evaluating mathematical IR without expert annotation. Starting from 283K high-school-level math problems with solutions, SABER-Math builds challenging reranking tasks in three steps: (i) first, LLMs extract concise solution summaries and mathematical topics for each problem; (ii) then, per-query relevant documents are discovered using ontology topic-based and lexical solutions-summary-based similarities, and (iii) finally, a Swiss-style LLM preference tournament produces fine-grained relevance ratings for the documents. We evaluate lexical retrievers, specialized mathematical retrieval systems, and recent embedding models. We find that while modern embedding models substantially outperform classical and math-specific baselines, even the strongest systems struggle in symbol-heavy domains like Algebra and Calculus. Importantly, we show that general-purpose IR benchmarks such as MTEB do not reliably predict mathematical performance, especially for recent embedding models, highlighting the need for math-specific retrieval benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SABER-Math as the first fully automated benchmark for mathematical IR evaluation. Starting from 283K high-school math problems, it constructs reranking tasks via three LLM-driven steps: extraction of solution summaries and topic tags, discovery of relevant documents through ontology-based topic and lexical summary similarities, and Swiss-style LLM preference tournaments to generate fine-grained relevance ratings. Evaluations of lexical retrievers, math-specific systems, and embedding models show modern embeddings outperforming baselines yet struggling in Algebra and Calculus, while demonstrating that MTEB scores do not reliably predict mathematical IR performance.
Significance. If the automated pipeline produces ratings that align with expert mathematical relevance, the work would provide a scalable, expert-annotation-free benchmark for a domain where manual labeling is costly. The large corpus size, explicit three-step construction, and direct comparison to MTEB constitute concrete strengths that could enable reproducible progress in math-specific retrieval.
major comments (2)
- [Section 3.3] Section 3.3: The Swiss-style LLM preference tournament is presented as yielding fine-grained relevance ratings that substitute for expert annotation and reflect true mathematical relevance, yet the manuscript reports no human-expert correlation study, inter-rater agreement baseline, or ablation against gold labels on any held-out set. This directly undermines the central claim that the benchmark evaluates retrievers on accurate mathematical relevance without expert input.
- [Section 4] Section 4 and abstract: Claims that embedding models 'substantially outperform' baselines and that MTEB does not predict math performance rest on the unvalidated tournament ratings; without a validation subsection, these comparative results cannot be interpreted as evidence about mathematical relevance.
minor comments (1)
- [Section 3] The similarity thresholds and prompt templates used in steps (i) and (ii) of the pipeline are described at a high level but lack explicit values or sensitivity analysis, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback, particularly the emphasis on validating the automated relevance ratings. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Section 3.3] Section 3.3: The Swiss-style LLM preference tournament is presented as yielding fine-grained relevance ratings that substitute for expert annotation and reflect true mathematical relevance, yet the manuscript reports no human-expert correlation study, inter-rater agreement baseline, or ablation against gold labels on any held-out set. This directly undermines the central claim that the benchmark evaluates retrievers on accurate mathematical relevance without expert input.
Authors: We agree that the absence of a human-expert correlation study is a substantive limitation. In the revised version we will add a dedicated validation subsection to Section 3.3. This subsection will describe a human evaluation on a held-out sample of 100 queries (with their candidate documents), where two mathematics experts independently assign relevance grades. We will report (i) inter-rater agreement (Cohen’s kappa), (ii) correlation between the LLM tournament scores and the expert grades (Spearman’s rho and Kendall’s tau), and (iii) an ablation comparing retrieval metrics obtained with LLM ratings versus expert ratings. The results will be used to qualify the benchmark’s reliability. revision: yes
-
Referee: [Section 4] Section 4 and abstract: Claims that embedding models 'substantially outperform' baselines and that MTEB does not predict math performance rest on the unvalidated tournament ratings; without a validation subsection, these comparative results cannot be interpreted as evidence about mathematical relevance.
Authors: We accept that the comparative claims in Section 4 and the abstract cannot be presented as definitive evidence of mathematical relevance until the ratings are validated. After completing the human study described above, we will revise the abstract and Section 4 to (a) state the observed correlations explicitly, (b) condition the performance claims on those correlations, and (c) add a limitations paragraph discussing the degree to which the automated pipeline approximates expert judgment. If correlations prove modest, we will tone down the language accordingly. revision: yes
Circularity Check
No circularity in benchmark construction or claims
full rationale
The paper presents SABER-Math as a constructed benchmark using LLM summaries, topic tags, similarity discovery, and Swiss-style tournaments to generate relevance ratings. No equations, fitted parameters, predictions, or derivations are described that could reduce to inputs by construction. No self-citations are invoked as load-bearing for any uniqueness theorem or ansatz. The process is presented as an independent automated pipeline whose outputs enable downstream evaluations, with no reduction of the central claim to its own fitted values or prior self-referential results.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption LLMs can reliably extract concise solution summaries and mathematical topics from high-school problems
- domain assumption Ontology topic-based and lexical solution-summary similarities discover per-query relevant documents
- domain assumption Swiss-style LLM preference tournament produces accurate fine-grained relevance ratings
Reference graph
Works this paper leans on
-
[1]
Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., Arbus, E., et al
URL https://ceur-ws.org/Vol-385 4/emtcir-2.pdf. Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., Arbus, E., et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025. URL https://arxiv.org/abs/2508.10925. Akram, M. K., Sturua, S., Havriushenko, N., Herreros, Q., Günther, M., Werk, M., and Xiao, H. jina-embeddings-v5- tex...
Pith/arXiv arXiv 2025
-
[2]
MathNet: a Global Multimodal Benchmark for Mathematical Reasoning and Retrieval
doi: 10.48550/ARXIV.2604.18584. URL https: //doi.org/10.48550/arXiv.2604.18584. Babakhin, Y ., Osmulski, R., Ak, R., Moreira, G., Xu, M., Schifferer, B., Liu, B., and Oldridge, E. Llama- embed-nemotron-8b: A universal text embedding model for multilingual and cross-lingual tasks, 2025. URL https://arxiv.org/abs/2511.07025. Bansal, K., Loos, S. M., Rabe, M...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.18584 2025
-
[4]
URL https: //doi.org/10.48550/arXiv.2505.22846
doi: 10.48550/ARXIV.2505.22846. URL https: //doi.org/10.48550/arXiv.2505.22846. Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. Le...
-
[5]
Generative Agents: Interactive Simulacra of Human Behavior
doi: 10.48550/ARXIV.2304.03442. URL https: //doi.org/10.48550/arXiv.2304.03442. Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V ., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V ., VanderPlas, J., Passos, A., Cour- napeau, D., Brucher, M., Perrot, M., and Duchesnay, E. Scikit-learn: Machine learning in python.J. Mach. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.03442 2011
-
[6]
URL https://dl.acm.org/doi/10.5555 /1953048.2078195. Penedo, G., Kydlíˇcek, H., Cappelli, A., Sasko, M., and Wolf, T. Datatrove: large scale data processing, 2024. URL https://github.com/huggingface/datat rove. Petrov, I., Dekoninck, J., Dimitrov, D. I., and Vechev, M. Not all proofs are equal: Evaluating llm proof quality beyond correctness, 2026. URL ht...
-
[7]
URL https: //doi.org/10.1145/3626772.3657707
doi: 10.1145/3626772.3657707. URL https: //doi.org/10.1145/3626772.3657707. Upadhyay, S., Kamalloo, E., and Lin, J. Llms can patch up missing relevance judgments in evaluation.CoRR, abs/2405.04727, 2024. doi: 10.48550/ARXIV.2405.04
-
[8]
URL https://doi.org/10.48550/arXiv .2405.04727. Wang, J. Z., Du, Z., Payattakool, R., Yu, P. S., and Chen, C.-F. A new method to measure the semantic similarity of go terms.Bioinformatics, 23(10):1274–1281, 05 2007. ISSN 1367-4803. doi: 10.1093/bioinformatics/btm087. URL https://doi.org/10.1093/bioinfor matics/btm087. Wang, L., Yang, N., Huang, X., Yang, ...
work page internal anchor Pith review doi:10.48550/arxiv 2007
-
[9]
<tagName>
A comma-separated list of tags # TASK For each of the provided tags assign a real number from the interval [0.0, 1.0]. The most relevant tag to the text must have a relevance score of 1.0 and the most irrelevant must have a score of 0.0. Align the remaining tags with respect to those. # OUTPUT SCHEMA Constrain your output to a pure JSON with no explanatio...
-
[10]
Capture the untrial step or idea that is the greatest hint for the solution
Identify what makes the solution work conceptually, not how to carry it out. Capture the untrial step or idea that is the greatest hint for the solution
-
[11]
Don't include any annotations that are in the solution but not in the original problem statement
Never include any multi-step reasoning, equations, or numeric computations. Don't include any annotations that are in the solution but not in the original problem statement
-
[12]
Never try to solve the problem on your own, and don't include your reasoning or thoughts
-
[13]
Output a single valid JSON object matching the schema below
-
[14]
Structure the ideas imperatively so they look like you are giving a hint to someone
-
[15]
noCoreIdea
If the problem seems too easy or straightforward, or you can't identify a core idea, store its value as 'null' and set the 'noCoreIdea' to 'true'. # SCHEMA ```json { "noCoreIdea": <true|false>, "coreIdea": "<string - one short sentence (up to 30 words) naming the main insight to the problem>", "supportingIdeas": ["<strings - 0-3 short technique phrases>"]...
-
[16]
symmetry/invariants vs
Technique overlap: - Are the same kinds of tools central (not merely mentioned)? - Are the same transformations used (e.g., factoring vs. symmetry/invariants vs. counting)?
-
[17]
Problem structure alignment: - Are the same intermediate objects introduced (auxiliary point, substitution, generating function, invariant quantity, etc.)? - Do both require the same "shape" of argument (e.g., construction + chase, or setup of recurrence + induction, or extremal argument + contradiction)? This criterion should be weighted lower than the t...
-
[18]
hard/easy
Difficulty is NOT the criterion: - Prefer shared method and structure over "hard/easy"
-
[19]
Further, algebraic computations do not imply similarity if the core method is different, or if the algebra is just a technical detail rather than the main driver
Penalize superficial similarity: - Do NOT reward matching variable names, story context, or domain language if the underlying method differs. Further, algebraic computations do not imply similarity if the core method is different, or if the algebra is just a technical detail rather than the main driver. Produce two subsections: - Sample 1 vs Target -- Sim...
-
[20]
The sample whose *main* technique is the same as the target's main technique
-
[21]
The sample whose *sequence of moves* (setup -> transformation -> key lemma -> finish) matches more closely
-
[22]
modular arithmetic
The sample that relies on the same representation (e.g., algebraic manipulation vs. geometric configuration vs. combinatorial counting vs. graph reasoning). -------- OUTPUT FORMAT (must follow) - You may include your extracted profiles and comparisons above. - Output your final decision on the last line, formatted as either: $\\boxed{{1}}$ -> correspondin...
-
[23]
Technique overlap - Which techniques are shared? - Which shared techniques are central rather than incidental? - Are the same theorems, transformations, or proof strategies doing the main work?
-
[24]
Technique differences - Which important techniques appear in one but not the other? - Do the problems rely on different core ideas even if they are in the same broad subject?
-
[25]
Important rules: - Focus on the methods actually used in the solutions
Structural alignment - Do the two solutions have a similar shape, such as: - setup -> substitution -> simplification -> conclusion - construction -> theorem application -> chase -> finish - recurrence -> induction - extremal argument -> contradiction - counting representation -> double count -> algebraic cleanup - This matters, but it should be weighted l...
-
[26]
\) and \\(
DELIMITER CONVERSION: Replace all instances of \( ... \) and \\( ... \\) with standard dollar signs. - Use $...$ for inline text. - Use $$...$$ for display equations
-
[27]
UNIVERSAL MATH TAGGING: Apply math mode ($...$) to every single mathematical element without exception
-
[28]
CONTENT INTEGRITY: Do not solve the problem or edit the prose
-
[29]
FINAL WRAPPING: The entire output must be contained within \boxed{{ <your_formatted_text_here> }}
-
[30]
Finished Tasks
NO VERBOSITY: Provide ONLY the \boxed{{...}} block. Example Transformation: Input: If the radius r is 5, find the area. Use \( \pi \). Output: \boxed{{If the radius $r$ is $5$, find the area. Use $\pi$.}} F.6. Human Annotator Instructions Human Annotator Instructions Goal: Compare Candidate 1 and Candidate 2 against the Target problem. Candidate 1: Choose...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.