AVTok: 1D Unified Tokenization for Holistic Audio-Video Generation
Pith reviewed 2026-07-01 06:14 UTC · model grok-4.3
The pith
AVTok encodes audio-video pairs into one compact 1D latent sequence via a shared codebook.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
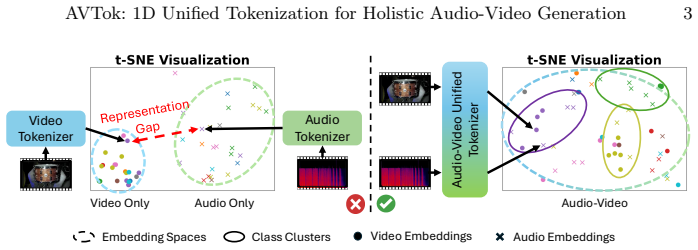
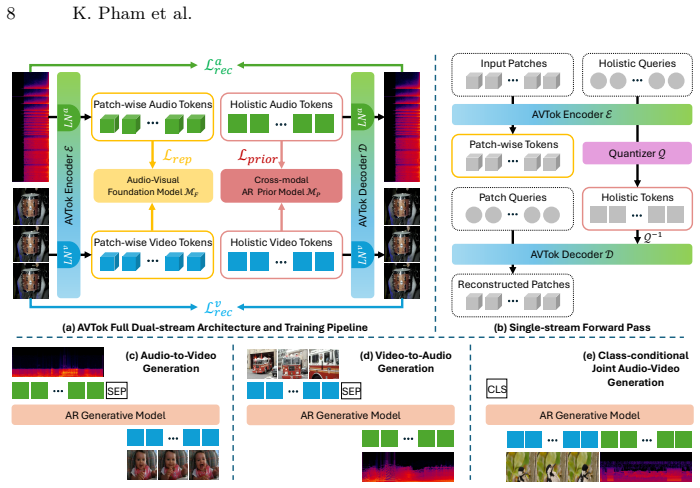
AVTok features a dual-stream transformer-based architecture with shared encoder-decoder and modal-specific learnable queries to efficiently and effectively encode an audio-video pair into a compact one-dimensional latent representation with a unified codebook, using hierarchical training to address information imbalance.
What carries the argument
dual-stream transformer-based architecture with shared encoder-decoder and modal-specific learnable queries that map audio-video input to a unified 1D codebook
If this is right
- AVTok produces stronger audio-video reconstruction than prior separate-modality methods.
- The same tokens integrate directly into audio-to-video generation pipelines.
- The tokens also support video-to-audio generation.
- Class-conditional joint audio-video generation becomes feasible with the single representation.
Where Pith is reading between the lines
- A shared codebook may lower total parameter count and training compute relative to fully separate modality pipelines.
- The 1D format could simplify scaling to larger multimodal sequence models that mix audio and video tokens.
Load-bearing premise
The heterogeneous information imbalance between audio and video can be effectively addressed by a hierarchical training strategy that progressively realizes reconstruction capabilities for each modality.
What would settle it
Controlled experiments in which a dual-branch tokenizer with separate codebooks matches or exceeds AVTok on both reconstruction fidelity metrics and downstream audio-to-video generation quality would undermine the unified approach.
Figures







read the original abstract
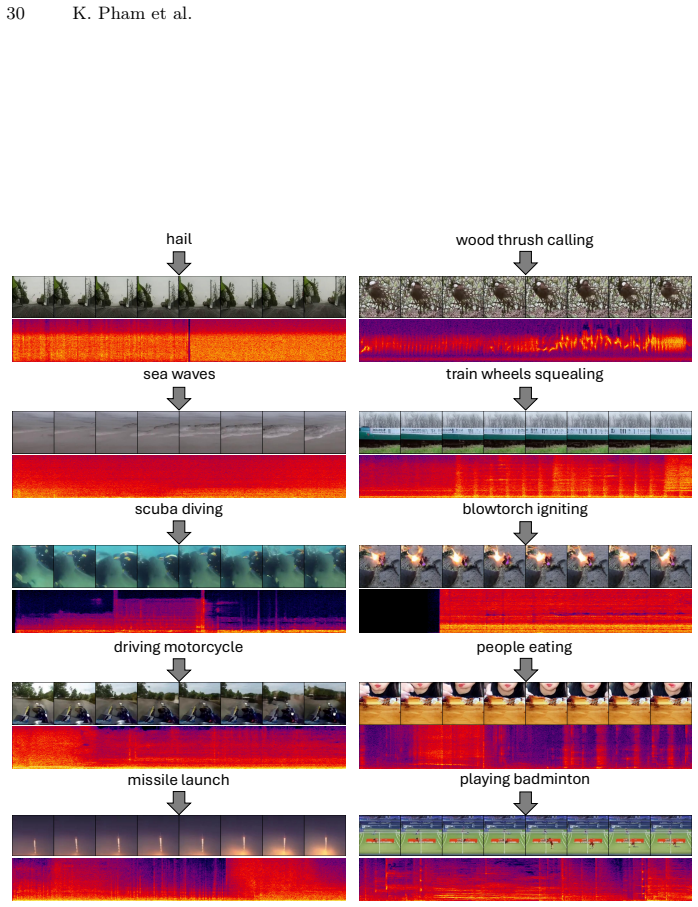
Audio-video generation has recently gained unprecedented research attention, aiming to synthesize high-quality sounding video content with fine-grained synchronization and semantic alignment between the auditory and visual components. The preceding methods predominantly adopt a dual-branch design with separate tokenization and generation modules per modality, neglecting the representation gap while necessitating intensive computational resources for proper training. Inspired by recent advancements in one-dimensional visual tokenization, we present \textbf{AVTok}, a novel unified tokenizer designated for holistic audio-video generation. AVTok features a dual-stream transformer-based architecture with shared encoder-decoder and modal-specific learnable queries to efficiently and effectively encode an audio-video pair into a compact one-dimensional latent representation with a unified codebook. To cope with the heterogeneous information imbalance that hinders AVTok from exploiting aligned audio-visual information, we devise a hierarchical training strategy to progressively realize reconstruction capabilities for each modality. Extensive experiments demonstrate that AVTok excels both in audio-video reconstruction and when integrated into downstream pipelines for audio-to-video, video-to-audio, and class-conditional joint audio-video generation. AVTok paves the way for the challenge of joint audio-video tokenization and provides a potential direction to build unified large multimodal models for audio-video generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AVTok, a unified 1D tokenizer for holistic audio-video generation. It employs a dual-stream transformer architecture with a shared encoder-decoder and modal-specific learnable queries to encode audio-video pairs into a compact 1D latent representation using a single unified codebook. A hierarchical training strategy is proposed to progressively realize reconstruction capabilities and mitigate heterogeneous information imbalance between modalities. The method is claimed to outperform prior dual-branch approaches in audio-video reconstruction and when integrated into downstream pipelines for audio-to-video, video-to-audio, and class-conditional joint generation tasks.
Significance. If the claims hold, AVTok could enable more computationally efficient unified tokenization for audio-video content, reducing the need for separate modality-specific modules and supporting better semantic alignment in generation. The approach builds on 1D visual tokenization advances and targets a key obstacle in multimodal modeling. The manuscript provides extensive experiments on reconstruction and downstream tasks as a strength, though the absence of detailed ablation evidence limits assessment of the training strategy's contribution.
major comments (2)
- [Abstract (paragraph on training strategy) and Experiments] The central claim that the dual-stream shared encoder-decoder plus modal-specific queries plus unified codebook can exploit aligned audio-visual information rests on the hierarchical training strategy mitigating modality imbalance. However, no quantitative comparison is described showing that this progressive schedule yields better reconstruction or downstream metrics than simultaneous joint training or alternatives such as modality-specific loss weighting. This is load-bearing for proving the unified 1D tokenization advantage over dual-branch designs.
- [Abstract and Experiments section] The abstract asserts that AVTok 'excels both in audio-video reconstruction and when integrated into downstream pipelines,' but without access to specific metrics, baselines, ablation tables, or quantitative results in the provided description, the support for these performance claims cannot be evaluated. This affects the ability to assess whether the unified codebook and architecture deliver the claimed gains.
minor comments (1)
- [Abstract] The abstract uses qualitative language ('excels', 'paves the way') without accompanying quantitative highlights; adding one or two key metric comparisons would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract (paragraph on training strategy) and Experiments] The central claim that the dual-stream shared encoder-decoder plus modal-specific queries plus unified codebook can exploit aligned audio-visual information rests on the hierarchical training strategy mitigating modality imbalance. However, no quantitative comparison is described showing that this progressive schedule yields better reconstruction or downstream metrics than simultaneous joint training or alternatives such as modality-specific loss weighting. This is load-bearing for proving the unified 1D tokenization advantage over dual-branch designs.
Authors: We agree that the absence of a direct ablation comparing the hierarchical training strategy to simultaneous joint training or loss-weighting alternatives limits the strength of the claim. The manuscript motivates and describes the strategy but does not report such a comparison. In the revision we will add this ablation, including reconstruction and downstream metrics for all variants. revision: yes
-
Referee: [Abstract and Experiments section] The abstract asserts that AVTok 'excels both in audio-video reconstruction and when integrated into downstream pipelines,' but without access to specific metrics, baselines, ablation tables, or quantitative results in the provided description, the support for these performance claims cannot be evaluated. This affects the ability to assess whether the unified codebook and architecture deliver the claimed gains.
Authors: The full manuscript reports the requested quantitative evidence in the Experiments section. Tables 1–2 give audio-video reconstruction metrics against dual-branch baselines; Tables 3–5 give downstream results (audio-to-video, video-to-audio, class-conditional joint generation) with FID, FVD, and audio quality scores. We will ensure these tables are clearly referenced from the abstract in the revision if needed, but the supporting numbers and baselines are already present. revision: partial
Circularity Check
No circularity: architecture and training strategy are empirical proposals, not self-referential derivations.
full rationale
The paper presents AVTok as a dual-stream transformer with shared encoder-decoder, modal-specific queries, unified codebook, and a hierarchical training schedule to address modality imbalance. No equations, first-principles derivations, or predictions are described that reduce claimed performance to fitted parameters or self-definitions by construction. Claims rest on experimental reconstruction and downstream metrics rather than tautological reductions. Self-citations, if present, are not load-bearing for any central mathematical result. This is the normal case for an applied ML architecture paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- modal-specific learnable queries
axioms (1)
- domain assumption One-dimensional visual tokenization advances can be directly extended to joint audio-video tokenization.
invented entities (1)
-
unified codebook for audio-video
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Araujo, E., Rouditchenko, A., Gong, Y., Bhati, S., Thomas, S., Kingsbury, B., Kar- linsky, L., Feris, R., Glass, J.R., Kuehne, H.: Cav-mae sync: Improving contrastive audio-visual mask autoencoders via fine-grained alignment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18794–18803 (June 2025)
2025
-
[2]
In: Forty-second International Conference on Machine Learning (2025)
Bachmann, R., Allardice, J., Mizrahi, D., Fini, E., Kar, O.F., Amirloo, E., El- Nouby, A., Zamir, A., Dehghan, A.: Flextok: Resampling images into 1d token sequences of flexible length. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[3]
In: Computer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: Computer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I. p. 213–229. Springer-Verlag, Berlin, Heidelberg (2020).https://doi.org/10. 1007/978-3-030-58452-8_13
2020
-
[4]
In: International Conference on Acoustics, Speech, and Signal Processing (ICASSP) (2020)
Chen, H., Xie, W., Vedaldi, A., Zisserman, A.: Vggsound: A large-scale audio-visual dataset. In: International Conference on Acoustics, Speech, and Signal Processing (ICASSP) (2020)
2020
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Cheng, H.K., Ishii, M., Hayakawa, A., Shibuya, T., Schwing, A., Mitsufuji, Y.: Mmaudio: Taming multimodal joint training for high-quality video-to-audio syn- thesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 28901–28911 (June 2025)
2025
-
[6]
In: Thirty-seventh Conference on Neural Information Processing Systems (2023) 16 K
Copet, J., Kreuk, F., Gat, I., Remez, T., Kant, D., Synnaeve, G., Adi, Y., Défossez, A.: Simple and controllable music generation. In: Thirty-seventh Conference on Neural Information Processing Systems (2023) 16 K. Pham et al
2023
-
[7]
Transactions on Machine Learning Research (2023), featured Certification, Reproducibility Certification
Défossez, A., Copet, J., Synnaeve, G., Adi, Y.: High fidelity neural audio compres- sion. Transactions on Machine Learning Research (2023), featured Certification, Reproducibility Certification
2023
-
[8]
In: International Conference on Learning Representations (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations (2021)
2021
-
[9]
Ergasti, A., Tarollo, G.G., Botti, F., Fontanini, T., Ferrari, C., Bertozzi, M., Prati, A.: rflav: Rolling flow matching for infinite audio video generation (2025)
2025
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 12873–12883 (June 2021)
2021
-
[11]
Evans, Z., Parker, J.D., Carr, C., Zukowski, Z., Taylor, J., Pons, J.: Stable audio open (2024)
2024
-
[12]
In: CVPR (2023)
Girdhar, R., El-Nouby, A., Liu, Z., Singh, M., Alwala, K.V., Joulin, A., Misra, I.: Imagebind: One embedding space to bind them all. In: CVPR (2023)
2023
-
[13]
Gong, Y., Chung, Y.A., Glass, J.: AST: Audio Spectrogram Transformer. In: Proc. Interspeech 2021. pp. 571–575 (2021).https://doi.org/10.21437/Interspeech. 2021-698
-
[14]
In: The Eleventh Inter- national Conference on Learning Representations (2023)
Gong, Y., Rouditchenko, A., Liu, A.H., Harwath, D., Karlinsky, L., Kuehne, H., Glass, J.R.: Contrastive audio-visual masked autoencoder. In: The Eleventh Inter- national Conference on Learning Representations (2023)
2023
-
[15]
In: Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. In: Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume
-
[16]
2672–2680
p. 2672–2680. NIPS’14, MIT Press, Cambridge, MA, USA (2014)
2014
-
[17]
Gu, Y., Zhang, X., Xue, L., Wu, Z.: Multi-scale sub-band constant-q transform discriminator for high-fidelity vocoder (2023)
2023
-
[18]
Guo, P., Wang, J., Xing, Z., Liu, C., Dong, D., Qian, X., Wu, Z.: Dera: Decoupled representation alignment for video tokenization (2025)
2025
-
[19]
LTX-Video: Realtime Video Latent Diffusion
HaCohen, Y., Chiprut, N., Brazowski, B., Shalem, D., Moshe, D., Richardson, E., Levin, E., Shiran, G., Zabari, N., Gordon, O., Panet, P., Weissbuch, S., Kulikov, V., Bitterman, Y., Melumian, Z., Bibi, O.: Ltx-video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Ho, J., Salimans, T.: Classifier-free diffusion guidance (2022)
2022
-
[21]
Iashin,V.,Rahtu,E.:Tamingvisuallyguidedsoundgeneration.In:BritishMachine Vision Conference (BMVC) (2021)
2021
-
[22]
Efficient Learning on Successive Test Time Augmentation,
Iashin, V., Xie, W., Rahtu, E., Zisserman, A.: Synchformer: Efficient synchro- nization from sparse cues. In: ICASSP 2024 - 2024 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP). pp. 5325–5329 (2024). https://doi.org/10.1109/ICASSP48485.2024.10448489
-
[23]
Wavtokenizer: An efficient acoustic discrete codec tokenizer for audio language modeling
Ji, S., Jiang, Z., Wang, W., Chen, Y., Fang, M., Zuo, J., Yang, Q., Cheng, X., Wang, Z., Li, R., et al.: Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling. arXiv preprint arXiv:2408.16532 (2024)
-
[24]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Jiang, Y., Chen, Q., Ji, S., Xi, Y., Wang, W., Zhang, C., Yue, X., Zhang, S., Li, H.: UniCodec: Unified audio codec with single domain-adaptive codebook. In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (eds.) Proceedings of the 63rd Annual MeetingoftheAssociationforComputationalLinguistics(Volume1:LongPapers). pp. 19112–19124. Association for Comput...
-
[25]
Kilgour, K., Zuluaga, M., Roblek, D., Sharifi, M.: Fréchet audio distance: A metric for evaluating music enhancement algorithms (2019)
2019
-
[26]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kim, D., He, J., Yu, Q., Yang, C., Shen, X., Kwak, S., Chen, L.C.: Democratizing text-to-image masked generative models with compact text-aware one-dimensional tokens. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 18442–18452 (October 2025)
2025
-
[27]
In: Interna- tional Conference on Learning Representations (ICLR) (2015)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: Interna- tional Conference on Learning Representations (ICLR) (2015)
2015
-
[28]
In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H
Kong, J., Kim, J., Bae, J.: Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) Advances in Neural Information Processing Systems. vol. 33, pp. 17022–17033. Curran Associates, Inc. (2020)
2020
-
[29]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
In: The Eleventh International Conference on Learning Representations (2023)
Kreuk, F., Synnaeve, G., Polyak, A., Singer, U., Défossez, A., Copet, J., Parikh, D., Taigman, Y., Adi, Y.: Audiogen: Textually guided audio generation. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[31]
In: Thirty-seventh Conference on Neural Information Processing Systems (2023)
Kumar, R., Seetharaman, P., Luebs, A., Kumar, I., Kumar, K.: High-fidelity audio compression with improved RVQGAN. In: Thirty-seventh Conference on Neural Information Processing Systems (2023)
2023
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Kushwaha, S.S., Tian, Y.: Vintage: Joint video and text conditioning for holis- tic audio generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13529–13539 (June 2025)
2025
-
[33]
Langman, R., Jukić, A., Dhawan, K., Koluguri, N.R., Li, J.: Spectral codecs: Im- proving non-autoregressive speech synthesis with spectrogram-based audio codecs (2025)
2025
-
[34]
In: The Eleventh International Conference on Learning Representations (2023)
gil Lee, S., Ping, W., Ginsburg, B., Catanzaro, B., Yoon, S.: BigVGAN: A universal neural vocoder with large-scale training. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[35]
Li, J., Zhao, Z., Zhang, Z., Liu, Y., Lin, L., Zhu, Y., Wu, J., Kong, Q., Li, Y.: Meltok: 2d tokenization for single-codebook audio compression (2025)
2025
-
[36]
In: Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J
Li, J., Li, D., Savarese, S., Hoi, S.: BLIP-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J. (eds.) Proceedings of the 40th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 202, pp....
2023
-
[37]
Li, Y., Tian, C., Xia, R., Liao, N., Guo, W., Yan, J., Li, H., Dai, J., Li, H., Yang, X.: Learning adaptive and temporally causal video tokenization in a 1d latent space (2025)
2025
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, Z., Lin, B., Ye, Y., Chen, L., Cheng, X., Yuan, S., Yuan, L.: Wf-vae: En- hancing video vae by wavelet-driven energy flow for latent video diffusion model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 17778–17788 (June 2025)
2025
-
[39]
Open-Sora Plan: Open-Source Large Video Generation Model
Lin, B., Ge, Y., Cheng, X., Li, Z., Zhu, B., Wang, S., He, X., Ye, Y., Yuan, S., Chen, L., et al.: Open-sora plan: Open-source large video generation model. arXiv preprint arXiv:2412.00131 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
In: The Fourteenth International Conference on Learning Representations (2026) 18 K
Liu, K., Li, W., Chen, L., Wu, S., Zheng, Y., Ji, J., Zhou, F., Luo, J., Liu, Z., Fei, H., Chua, T.S.: Javisdit: Joint audio-video diffusion transformer with hier- archical spatio-temporal prior synchronization. In: The Fourteenth International Conference on Learning Representations (2026) 18 K. Pham et al
2026
-
[41]
In: International Conference on Learning Representations (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019)
2019
-
[42]
Low, C., Wang, W., Katyal, C.: Ovi: Twin backbone cross-modal fusion for audio- video generation (2025)
2025
-
[43]
Mao, Y., Shen, X., Zhang, J., Qin, Z., Zhou, J., Xiang, M., Zhong, Y., Dai, Y.: TAVGBench:Benchmarkingtexttoaudible-videogeneration.In:ACMMultimedia 2024 (2024)
2024
-
[44]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Pham, K.T., He, Y., Xing, Y., Chen, Q., Chen, L.: Spa2v: Harnessing spatial auditory cues for audio-driven spatially-aware video generation. In: Proceedings of the 33rd ACM International Conference on Multimedia. p. 10476–10485. MM ’25, Association for Computing Machinery, New York, NY, USA (2025).https: //doi.org/10.1145/3746027.3755705
-
[45]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language models are unsupervised multitask learners (2019)
2019
-
[46]
Roux, J.L., Wisdom, S., Erdogan, H., Hershey, J.R.: Sdr - half-baked or well done? (2018)
2018
-
[47]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ruan, L., Ma, Y., Yang, H., He, H., Liu, B., Fu, J., Yuan, N.J., Jin, Q., Guo, B.: Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10219–10228 (June 2023)
2023
-
[48]
Seedance, T.: Seedance 1.5 pro: A native audio-visual joint generation foundation model (2025)
2025
-
[49]
In: The Fourteenth International Confer- ence on Learning Representations (2026)
Song, J., Kwon, M., Jeong, J., Uh, Y.: Syncphony: Synchronized audio-to-video generation with diffusion transformers. In: The Fourteenth International Confer- ence on Learning Representations (2026)
2026
-
[50]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y., Chen, S., Zhang, S., Peng, B., Luo, P., Yuan, Z.: Autoregres- sive model beats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
arXiv preprint arXiv:2412.13061 (2024)
Tang, A., He, T., Guo, J., Cheng, X., Song, L., Bian, J.: Vidtok: A versatile and open-source video tokenizer. arXiv preprint arXiv:2412.13061 (2024)
-
[52]
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., Lample, G.: Llama: Open and efficient foundation language models (2023)
2023
-
[53]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR)
Tseng, H.Y., Jiang, L., Liu, C., Yang, M.H., Yang, W.: Regularizing generative ad- versarial networks under limited data. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 7921–7931 (June 2021)
2021
-
[54]
Unterthiner, T., van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges (2019)
2019
-
[55]
(eds.) Advances in Neural Information Processing Systems
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L.u.,Polosukhin,I.:Attentionisallyouneed.In:Guyon,I.,Luxburg,U.V.,Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 30. Curran Associates, Inc. (2017)
2017
-
[56]
In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Viertola, I., Iashin, V., Rahtu, E.: Temporally aligned audio for video with au- toregression. In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE (2025)
2025
-
[57]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Wang, B., Yue, Z., Zhang, F., Chen, S., Bi, L., Zhang, J., Song, X., Chan, K.Y., Pan, J., Wu, W., Zhou, M., Lin, W., Pan, K., Zhang, S., Jia, L., Hu, W., Zhao, AVTok: 1D Unified Tokenization for Holistic Audio-Video Generation 19 W., Zhang, H.: Selftok: Discrete visual tokens of autoregression, by diffusion, and for reasoning (2025)
2025
-
[59]
In: The Thirteenth International Conference on Learning Representations (2025)
Wang, H., Suri, S., Ren, Y., Chen, H., Shrivastava, A.: LARP: Tokenizing videos with a learned autoregressive generative prior. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[60]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024)
Wang, J., Jiang, Y., Yuan, Z., PENG, B., Wu, Z., Jiang, Y.G.: Omnitokenizer: A joint image-video tokenizer for visual generation. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024)
2024
-
[61]
In: Proceed- ings of the 33rd ACM International Conference on Multimedia
Wang, K., Deng, S., Shi, J., Hatzinakos, D., Tian, Y.: Av-dit: Taming image dif- fusion transformers for efficient joint audio and video generation. In: Proceed- ings of the 33rd ACM International Conference on Multimedia. p. 10486–10495. MM ’25, Association for Computing Machinery, New York, NY, USA (2025). https://doi.org/10.1145/3746027.3755713
-
[62]
Wang, Z., Bovik, A., Sheikh, H., Simoncelli, E.: Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing 13(4), 600–612 (2004).https://doi.org/10.1109/TIP.2003.819861
-
[63]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Wen, X., Zhao, B., Elezi, I., Deng, J., Qi, X.: ”principal components” enable a new language of images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 16641–16651 (October 2025)
2025
-
[64]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2026)
Weng, S., Zheng, H., Chang, Z., Li, S., Shi, B., Wang, X.: Audio-sync video genera- tion with multi-stream temporal control. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2026)
2026
-
[65]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Xing, Y., Fei, Y., He, Y., Chen, J., Xie, J., Chi, X., Chen, Q.: Videovae+: Large motion video autoencoding with cross-modal video vae. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 17951– 17960 (October 2025)
2025
-
[66]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xing, Y., He, Y., Tian, Z., Wang, X., Chen, Q.: Seeing and hearing: Open- domain visual-audio generation with diffusion latent aligners. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7151–7161 (June 2024)
2024
-
[67]
Yamamoto, R., Song, E., Kim, J.M.: Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram (2020)
2020
-
[68]
In: The Thirteenth International Conference on Learning Represen- tations (2025)
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., Yin, D., Yuxuan.Zhang, Wang, W., Cheng, Y., Xu, B., Gu, X., Dong, Y., Tang, J.: Cogvideox: Text-to-video diffusion models with an expert transformer. In: The Thirteenth International Conference on Learning Represen- tations (2025)
2025
-
[69]
Yariv, G., Gat, I., Benaim, S., Wolf, L., Schwartz, I., Adi, Y.: Diverse and aligned audio-to-video generation via text-to-video model adaptation. Proceedings of the AAAI Conference on Artificial Intelligence38(7), 6639–6647 (Mar 2024).https: //doi.org/10.1609/aaai.v38i7.28486
-
[70]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024)
Yu, Q., Weber, M., Deng, X., Shen, X., Cremers, D., Chen, L.C.: An image is worth 32 tokens for reconstruction and generation. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024)
2024
-
[71]
In: International Conference on Learning Representations (2025)
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. In: International Conference on Learning Representations (2025)
2025
-
[72]
Pham et al
Zhang, G., Zhou, Z., Hu, T., Peng, Z., Zhang, Y., Chen, Y., Zhou, Y., Lu, Q., Wang, L.: Uniavgen: Unified audio and video generation with asymmetric cross- modal interactions (2025) 20 K. Pham et al
2025
-
[73]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2018)
2018
-
[74]
Zhang, Y., Gu, Y., Zeng, Y., Xing, Z., Wang, Y., Wu, Z., Liu, B., Chen, K.: Foleycrafter: Bring silent videos to life with lifelike and synchronized sounds. Int. J. Comput. Vision134(1) (Jan 2026).https://doi.org/10.1007/s11263-025- 02649-3
-
[75]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2026)
Zheng, J., Pan, S., Yao, Y., Wang, Z., Wang, D., Liu, T.: Aligning what matters: Masked latent adaptation for text-to-audio-video generation. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2026)
2026
-
[76]
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404 (2024) AVTok: 1D Unified Tokenization for Holistic Audio-Video Generation 21 A Additional Experiment Details A.1 Datasets Statistics.WeconductourexperimentsonVGGSound[4]andTAVGBen...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.