ADAPT: Attention Dynamics Alignment with Preference Tuning for Faithful MLLMs
Pith reviewed 2026-07-01 06:48 UTC · model grok-4.3
The pith
Direct intervention on degrading text-to-image attention during generation cuts hallucinations in multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hallucination arises from measurable degradation in text-to-image cross-attention dynamics; aligning those dynamics through a refined visual anchor, attention-supervised inference, and Visual Attention Guidance DPO produces more image-faithful outputs without capability trade-offs.
What carries the argument
The ADAPT framework, which intervenes on text-to-image cross-attention dynamics via a cross-attention visual anchor, attention-supervised inference, and Visual Attention Guidance DPO.
If this is right
- Each of the three components contributes independently to lower hallucination rates on existing benchmarks.
- The full ADAPT system sets new best results across multiple hallucination benchmarks while preserving general multimodal capabilities.
- Attention drift can be detected and corrected online during inference to improve output faithfulness.
- Preference optimization guided by attention patterns favors visually grounded responses over ungrounded ones.
Where Pith is reading between the lines
- Attention patterns could serve as an internal diagnostic for hallucination risk before final output is generated.
- The same attention-alignment idea might extend to other multimodal failure modes such as object misidentification or spatial errors.
- Models trained with this approach could require fewer post-hoc filters when deployed in high-stakes settings.
Load-bearing premise
Progressive degradation of text-to-image cross-attention is the primary cause of hallucination, and correcting it will not create new errors or capability losses.
What would settle it
An experiment in which attention degradation is observed at the same rate yet hallucinations remain low, or in which the three ADAPT components are applied but hallucination rates on held-out benchmarks show no reduction.
Figures

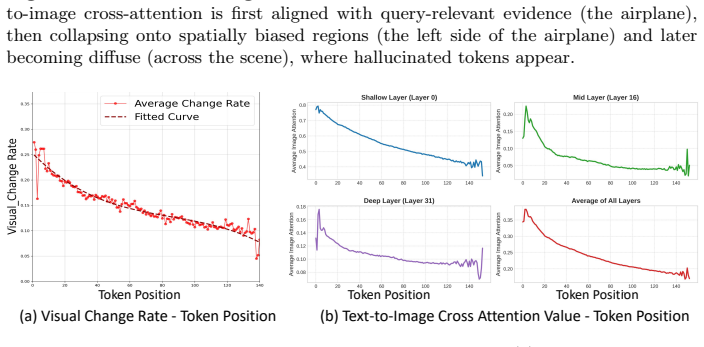




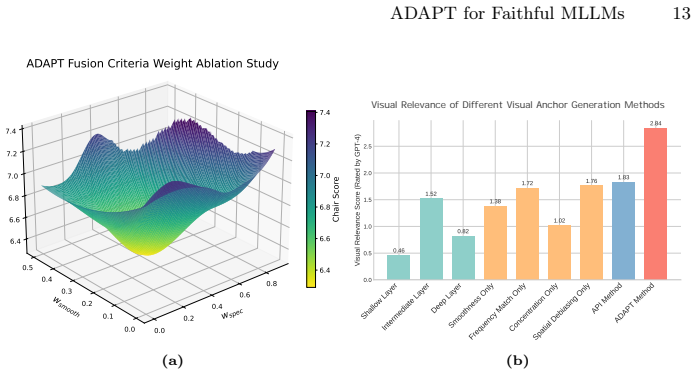
read the original abstract
Multimodal Large Language Models (MLLMs) are critically hampered by hallucination, generating content inconsistent with the provided image. In this paper, we identify an internal signature of hallucination: progressive degradation of text-to-image cross-attention during generation, leading to specific failure patterns like unfocused or biased attention. Existing mitigation strategies are largely outcome-driven and do not explicitly target this failure mode. To address this problem, we propose ADAPT (Attention Dynamics Alignment with Preference Tuning), an attention-based framework that intervenes directly on text-to-image cross-attention dynamics. We propose ADAPT with three key contributions: a cross-attention visual anchor refined from early decoding to provide stable spatial grounding, an attention-supervised inference mechanism that detects and corrects attention drift online, and a Visual Attention Guidance DPO that aligns preferences toward visually grounded responses. Experiments show that each component of ADAPT contributes to hallucination reduction, and the full framework achieves new best results across multiple hallucination benchmarks, reducing hallucination rates by 40%-60% across mainstream backbones while preserving general multimodal capabilities. Our work provides an attention-based perspective on mitigating hallucinations by exploring the model's internal text-to-image cross-attention behaviors. Code is available at https://github.com/yao-ustc/ADAPT
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies progressive degradation of text-to-image cross-attention during generation as an internal signature of hallucination in MLLMs and proposes the ADAPT framework with three components—a refined cross-attention visual anchor from early decoding, an attention-supervised inference mechanism to detect and correct drift online, and Visual Attention Guidance DPO—to align attention dynamics with preference tuning. Experiments are reported to show each component contributes to gains, with the full framework achieving new best results on multiple hallucination benchmarks (40-60% reduction rates across backbones) while preserving general multimodal capabilities; code is released publicly.
Significance. If the results hold, the work supplies a targeted internal-mechanism perspective on hallucination mitigation that is more interpretable than purely outcome-driven baselines. The public code release is a clear strength supporting reproducibility.
major comments (3)
- [Experiments] Experiments section: The reported ablations show contribution from each ADAPT component, but omit a control that applies standard DPO (or preference tuning) while disabling the attention-specific mechanisms (visual anchor and attention-supervised inference). This leaves the central claim—that gains arise specifically from correcting attention drift rather than from added supervision or preference tuning in general—unisolated.
- [Evaluation] Evaluation protocols: The manuscript does not supply sufficient detail on benchmarks, data splits, number of evaluation runs, statistical significance testing, or exact baseline re-implementations to substantiate the claimed 40-60% reductions and new state-of-the-art status.
- [Method and Experiments] Method and Experiments: The assumption that progressive text-to-image cross-attention degradation is the primary driver (and that direct intervention on it is necessary/sufficient) requires stronger causal evidence; correlation in attention maps is noted but targeted interventions that hold other factors fixed are not demonstrated.
minor comments (1)
- [Abstract] The abstract would be strengthened by naming the specific hallucination benchmarks used to support the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The reported ablations show contribution from each ADAPT component, but omit a control that applies standard DPO (or preference tuning) while disabling the attention-specific mechanisms (visual anchor and attention-supervised inference). This leaves the central claim—that gains arise specifically from correcting attention drift rather than from added supervision or preference tuning in general—unisolated.
Authors: We agree that an explicit control using standard DPO without the attention-specific components would better isolate the role of attention dynamics. In the revised manuscript, we will add this ablation by applying standard DPO to the base models and comparing performance against the full ADAPT framework on the hallucination benchmarks. revision: yes
-
Referee: [Evaluation] Evaluation protocols: The manuscript does not supply sufficient detail on benchmarks, data splits, number of evaluation runs, statistical significance testing, or exact baseline re-implementations to substantiate the claimed 40-60% reductions and new state-of-the-art status.
Authors: We acknowledge the need for greater transparency in evaluation reporting. The revised manuscript will expand the Experiments section to detail all benchmarks and data splits, the number of runs with standard deviations, statistical significance tests performed, and exact procedures for baseline re-implementations including hyperparameters. revision: yes
-
Referee: [Method and Experiments] Method and Experiments: The assumption that progressive text-to-image cross-attention degradation is the primary driver (and that direct intervention on it is necessary/sufficient) requires stronger causal evidence; correlation in attention maps is noted but targeted interventions that hold other factors fixed are not demonstrated.
Authors: Our evidence rests on observed correlations between attention degradation and hallucination patterns together with component ablations showing diminished gains when attention mechanisms are removed. To strengthen the causal case, the revision will incorporate additional controlled perturbation experiments that induce attention drift while holding other factors fixed and measure resulting hallucination changes. We view this as a partial revision that addresses the core concern while noting the practical limits of full causal isolation in complex models. revision: partial
Circularity Check
No circularity: empirical framework with benchmark results
full rationale
The paper presents an empirical method identifying progressive cross-attention degradation as a hallucination signature and testing three interventions (visual anchor, attention-supervised inference, Visual Attention Guidance DPO) via benchmark experiments. No equations, derivations, or fitted parameters are described that reduce to inputs by construction. Claims rest on reported experimental reductions (40-60%) and component ablations rather than self-referential definitions or self-citation chains. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Progressive degradation of text-to-image cross-attention is an internal signature of hallucination
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-VL technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Hallucination of Multimodal Large Language Models: A Survey
Bai, Z., Wang, P., Xiao, T., He, T., Han, Z., Zhang, Z., Shou, M.Z.: Hallucination of multimodal large language models: A survey. arXiv preprint arXiv:2404.18930 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Cho,Y.,Kim,K.,Hwang,T.,Cho,S.:Doyoukeepaneyeonwhatiask?mitigating multimodal hallucination via attention-guided ensemble decoding. arXiv preprint arXiv:2505.17529 (2025)
-
[4]
Advances in neural information processing systems30(2017)
Christiano, P.F., Leike, J., Brown, T., Martic, M., Legg, S., Amodei, D.: Deep reinforcement learning from human preferences. Advances in neural information processing systems30(2017)
2017
-
[5]
In: Belgrave, D., Zhang, C., Montoya, L.N., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., Chen, N., Ruíz, I.V.M., Loaiza-Bonilla, A
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., Wu, Y., Ji, R., Shan, C., He, R.: MME: A comprehensive evalua- tion benchmark for multimodal large language models. In: Belgrave, D., Zhang, C., Montoya, L.N., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., Chen, N., Ruíz, I.V.M., Loaiza-Bonilla, A. (eds.) Adv...
2025
-
[6]
In: Findings of the Association for Computational Linguistics: ACL 2025
Fu, Y., Xie, R., Sun, X., Kang, Z., Li, X.: Mitigating hallucination in multimodal large language model via hallucination-targeted direct preference optimization. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 16563– 16577 (2025)
2025
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Q., Dong, X., Zhang, P., Wang, B., He, C., Wang, J., Lin, D., Zhang, W., Yu, N.: Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13418–13427 (2024)
2024
-
[8]
arXiv preprint arXiv:2408.02032 (2024)
Huo, F., Xu, W., Zhang, Z., Wang, H., Chen, Z., Zhao, P.: Self-introspective de- coding: Alleviating hallucinations for large vision-language models. arXiv preprint arXiv:2408.02032 (2024)
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jiang, Z., Chen, J., Zhu, B., Luo, T., Shen, Y., Yang, X.: Devils in middle lay- ers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 25004–25014 (2025) 16 Z. Yao et al
2025
-
[10]
arXiv preprint arXiv:2503.03321 (2025)
Kang, S., Kim, J., Kim, J., Hwang, S.J.: See what you are told: Visual attention sink in large multimodal models. arXiv preprint arXiv:2503.03321 (2025)
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., Bing, L.: Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13872–13882 (2024)
2024
-
[12]
Cross-Modal Attention Calibration for LVLM Hallucination Mitigation
Li, J., Zhang, J., Jie, Z., Ma, L., Li, G.: Mitigating hallucination for large vision language model by inter-modality correlation calibration decoding. arXiv preprint arXiv:2501.01926 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
In: Proceedings of the 2023 conference on empirical methods in natural language processing
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.R.: Evaluating object hal- lucination in large vision-language models. In: Proceedings of the 2023 conference on empirical methods in natural language processing. pp. 292–305 (2023)
2023
-
[14]
A Survey on Hallucination in Large Vision-Language Models
Liu, H., Xue, W., Chen, Y., Chen, D., Zhao, X., Wang, K., Hou, L., Li, R., Peng, W.: A survey on hallucination in large vision-language models. arXiv preprint arXiv:2402.00253 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tun- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024)
2024
-
[16]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[17]
Lecture Notes in Computer Science, vol
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., Chen, K., Lin, D.: Mmbench: Is your multi-modal model an all-around player? In: ECCV (6). Lecture Notes in Computer Science, vol. 15064, pp. 216–233. Springer (2024)
2024
-
[18]
Advances in Neural Information Processing Systems37, 122811–122832 (2024)
Lyu, X., Chen, B., Gao, L., Shen, H., Song, J.: Alleviating hallucinations in large vision-language models through hallucination-induced optimization. Advances in Neural Information Processing Systems37, 122811–122832 (2024)
2024
-
[19]
In: European Conference on Computer Vision
Ouali, Y., Bulat, A., Martinez, B., Tzimiropoulos, G.: Clip-dpo: Vision-language models as a source of preference for fixing hallucinations in lvlms. In: European Conference on Computer Vision. pp. 395–413. Springer (2024)
2024
-
[20]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[21]
Advances in neural information processing systems36, 53728–53741 (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems36, 53728–53741 (2023)
2023
-
[22]
In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
Rohrbach, A., Hendricks, L.A., Burns, K., Darrell, T., Saenko, K.: Object halluci- nation in image captioning. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. pp. 4035–4045 (2018)
2018
-
[23]
In: The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 (2025)
Sarkar, P., Ebrahimi, S., Etemad, A., Beirami, A., Arik, S.Ö., Pfister, T.: Miti- gating object hallucination in mllms via data-augmented phrase-level alignment. In: The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 (2025)
2025
-
[24]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Sarkar, S., Che, Y., Gavin, A., Beerel, P.A., Kundu, S.: Mitigating hallucinations in vision-language models through image-guided head suppression. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 12481–12500 (2025)
2025
-
[25]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: OpenAI GPT-5 system card. arXiv preprint arXiv:2601.03267 (2025) ADAPT for Faithful MLLMs 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
In: Pro- ceedings of the 60th Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers)
Subramanian, S., Merrill, W., Darrell, T., Gardner, M., Singh, S., Rohrbach, A.: Reclip: A strong zero-shot baseline for referring expression comprehension. In: Pro- ceedings of the 60th Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers). pp. 5198–5215 (2022)
2022
-
[27]
In: Findings of the Association for Computational Linguistics: ACL 2024
Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y., Gan, C., Gui, L., Wang, Y.X., Yang, Y., et al.: Aligning large multimodal models with factually augmented rlhf. In: Findings of the Association for Computational Linguistics: ACL 2024. pp. 13088–13110 (2024)
2024
-
[28]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tang, F., Liu, C., Xu, Z., Hu, M., Huang, Z., Xue, H., Chen, Z., Peng, Z., Yang, Z., Zhou, S., et al.: Seeing far and clearly: Mitigating hallucinations in mllms with attention causal decoding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 26147–26159 (2025)
2025
-
[29]
arXiv preprint arXiv:2509.25177 (2025)
Tong, B., Xia, J., Zhou, K.: Mitigating hallucination in multimodal llms with layer contrastive decoding. arXiv preprint arXiv:2509.25177 (2025)
-
[30]
In: The Thir- teenth International Conference on Learning Representations, ICLR 2025, Singa- pore, April 24-28, 2025
Wang, C., Chen, X., Zhang, N., Tian, B., Xu, H., Deng, S., Chen, H.: MLLM can see? dynamic correction decoding for hallucination mitigation. In: The Thir- teenth International Conference on Learning Representations, ICLR 2025, Singa- pore, April 24-28, 2025. OpenReview.net (2025)
2025
-
[31]
Wang, F., Zhou, W., Huang, J.Y., Xu, N., Zhang, S., Poon, H., Chen, M.: mdpo: Conditionalpreferenceoptimizationformultimodallargelanguagemodels.In:Pro- ceedings of the 2024 Conference on Empirical Methods in Natural Language Pro- cessing. pp. 8078–8088 (2024)
2024
-
[32]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Wang, J., Wang, Y., Xu, G., Zhang, J., Gu, Y., Jia, H., Wang, J., Xu, H., Yan, M., Zhang, J., et al.: AMBER: an llm-free multi-dimensional benchmark for mllms hallucination evaluation. arXiv preprint arXiv:2311.07397 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
In: Findings of the Association for Computational Linguistics: NAACL 2025
Wang, X., Chen, J., Wang, Z., Zhou, Y., Zhou, Y., Yao, H., Zhou, T., Goldstein, T., Bhatia, P., Kass-Hout, T., et al.: Enhancing visual-language modality alignment in large vision language models via self-improvement. In: Findings of the Association for Computational Linguistics: NAACL 2025. pp. 268–282 (2025)
2025
-
[34]
In: Findings of the Association for Computational Linguistics: ACL 2025
Woo, S., Kim, D., Jang, J., Choi, Y., Kim, C.: Don’t miss the forest for the trees: Attentional vision calibration for large vision language models. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 1927–1951 (2025)
2025
-
[35]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Xie, Y., Li, G., Xu, X., Kan, M.Y.: V-dpo: Mitigating hallucination in large vision language models via vision-guided direct preference optimization. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 13258–13273 (2024)
2024
-
[36]
Advances in neural information processing systems37, 92012– 92035 (2024)
Xing, Y., Li, Y., Laptev, I., Lu, S.: Mitigating object hallucination via concentric causal attention. Advances in neural information processing systems37, 92012– 92035 (2024)
2024
-
[37]
In: European Conference on Computer Vision
Yu, R., Yu, W., Wang, X.: Attention prompting on image for large vision-language models. In: European Conference on Computer Vision. pp. 251–268. Springer (2024)
2024
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, T., Yao, Y., Zhang, H., He, T., Han, Y., Cui, G., Hu, J., Liu, Z., Zheng, H.T., Sun, M., et al.: Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13807–13816 (2024)
2024
-
[39]
Yu, T., Zhang, H., Yao, Y., Dang, Y., Chen, D., Lu, X., Cui, G., He, T., Liu, Z., Chua, T.S., et al.: Rlaif-v: Aligning mllms through open-source ai feedback for super gpt-4v trustworthiness. arXiv preprint arXiv:2405.17220 (2024) 18 Z. Yao et al
-
[40]
arXiv preprint arXiv:2502.06130 (2025)
Zhang, C., Wan, Z., Kan, Z., Ma, M.Q., Stepputtis, S., Ramanan, D., Salakhutdi- nov, R., Morency, L.P., Sycara, K., Xie, Y.: Self-correcting decoding with genera- tive feedback for mitigating hallucinations in large vision-language models. arXiv preprint arXiv:2502.06130 (2025)
-
[41]
Tell Model Where to Look: Mitigating Hallucinations in MLLMs by Vision-Guided Attention
Zhao, J., Zhang, F., Sun, X., Feng, C., Tan, Z.: Tell model where to look: Mitigating hallucinations in mllms by vision-guided attention. arXiv preprint arXiv:2511.20032 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Beyond Hallucinations: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization
Zhao, Z., Wang, B., Ouyang, L., Dong, X., Wang, J., He, C.: Beyond hallucinations: Enhancing lvlms through hallucination-aware direct preference optimization. arXiv preprint arXiv:2311.16839 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhu, L., Ji, D., Chen, T., Xu, P., Ye, J., Liu, J.: Ibd: Alleviating hallucinations in large vision-language models via image-biased decoding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1624–1633 (2025)
2025
-
[44]
arXiv preprint arXiv:2410.03577 (2024)
Zou, X., Wang, Y., Yan, Y., Lyu, Y., Zheng, K., Huang, S., Chen, J., Jiang, P., Liu, J., Tang, C., et al.: Look twice before you answer: Memory-space visual retracing for hallucination mitigation in multimodal large language models. arXiv preprint arXiv:2410.03577 (2024)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.