NIESR: Nuisance Invariant End-to-end Speech Recognition
Pith reviewed 2026-05-25 01:44 UTC · model grok-4.3
The pith
An unsupervised adversarial framework trains end-to-end speech recognizers to ignore nuisances like noise and speaker identity using only transcriptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that an unsupervised adversarial invariance induction framework can be integrated into end-to-end speech recognition training to produce models that remain invariant to nuisance factors while using only transcription labels, yielding relative word error rate reductions of 5.48 percent on WSJ0, 6.16 percent on CHiME3, 6.61 percent on TIMIT, and 14.44 percent on the combined WSJ0+CHiME3 dataset compared with the baseline model.
What carries the argument
The unsupervised adversarial invariance induction framework, which uses adversarial training to enforce separation of essential transcription factors from nuisances without supplementary labels.
If this is right
- The recognizer achieves measurable accuracy gains on multiple standard speech datasets without extra annotations.
- Performance holds on both clean and noisy recordings using the same training procedure.
- The method scales to combined datasets that mix different recording conditions.
- No enumeration or labeling of nuisance types is required during training.
Where Pith is reading between the lines
- The same separation technique might reduce the need for domain-specific data collection in other audio tasks.
- If the invariance generalizes, models could be trained on mixed public datasets without per-nuisance metadata.
- The framework might be tested by checking whether internal representations lose information about speaker or noise while retaining phonetic content.
Load-bearing premise
The adversarial process can reliably isolate only the speech factors required for transcription and exclude all relevant nuisances even though no nuisance labels are provided.
What would settle it
Measure word error rate on a held-out test set containing nuisance combinations deliberately withheld from training; if accuracy gains disappear, the invariance separation has not occurred.
Figures
read the original abstract
Deep neural network models for speech recognition have achieved great success recently, but they can learn incorrect associations between the target and nuisance factors of speech (e.g., speaker identities, background noise, etc.), which can lead to overfitting. While several methods have been proposed to tackle this problem, existing methods incorporate additional information about nuisance factors during training to develop invariant models. However, enumeration of all possible nuisance factors in speech data and the collection of their annotations is difficult and expensive. We present a robust training scheme for end-to-end speech recognition that adopts an unsupervised adversarial invariance induction framework to separate out essential factors for speech-recognition from nuisances without using any supplementary labels besides the transcriptions. Experiments show that the speech recognition model trained with the proposed training scheme achieves relative improvements of 5.48% on WSJ0, 6.16% on CHiME3, and 6.61% on TIMIT dataset over the base model. Additionally, the proposed method achieves a relative improvement of 14.44% on the combined WSJ0+CHiME3 dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NIESR, an end-to-end ASR model that employs an unsupervised adversarial invariance induction framework to disentangle speech-recognition factors from nuisances (speaker identity, noise, etc.) using only transcription supervision. It reports relative WER reductions of 5.48% on WSJ0, 6.16% on CHiME3, 6.61% on TIMIT, and 14.44% on the combined WSJ0+CHiME3 corpus relative to a base model.
Significance. If reproducible, the result is moderately significant because it removes the need for explicit nuisance annotations, a practical bottleneck in robust ASR. The consistent gains across three standard corpora constitute direct, falsifiable evidence for the central mechanism; the work also ships an explicit hyperparameter (adversarial loss weight) whose effect can be inspected.
major comments (2)
- [§4, Table 1] §4 (Experiments), Table 1: absolute WER numbers and standard deviations across runs are not reported, only relative deltas; without these it is impossible to judge whether the 5–14% relative gains exceed typical run-to-run variance on the cited corpora.
- [§3.2, Eq. (3)–(5)] §3.2, Eq. (3)–(5): the adversarial discriminator is trained on the same transcription-only data as the recognizer; the manuscript does not demonstrate (via ablation or visualization) that the learned invariance actually removes the targeted nuisance factors rather than simply regularizing the encoder.
minor comments (2)
- [§1] The abstract and §1 use “nuisance factors” without a precise operational definition; a short paragraph listing the concrete factors the method is intended to be invariant to would improve clarity.
- [Figure 2] Figure 2 caption does not state the exact value of the adversarial loss weight used for the reported runs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§4, Table 1] §4 (Experiments), Table 1: absolute WER numbers and standard deviations across runs are not reported, only relative deltas; without these it is impossible to judge whether the 5–14% relative gains exceed typical run-to-run variance on the cited corpora.
Authors: We agree that absolute WER values and standard deviations are necessary to evaluate whether the reported gains are statistically meaningful. In the revised manuscript we will report the absolute WER for both the baseline and NIESR on every corpus, together with standard deviations obtained from multiple independent runs with different random seeds. revision: yes
-
Referee: [§3.2, Eq. (3)–(5)] §3.2, Eq. (3)–(5): the adversarial discriminator is trained on the same transcription-only data as the recognizer; the manuscript does not demonstrate (via ablation or visualization) that the learned invariance actually removes the targeted nuisance factors rather than simply regularizing the encoder.
Authors: The consistent relative improvements across three corpora that differ substantially in their nuisance characteristics provide indirect support that the adversarial term contributes beyond generic regularization. Nevertheless, we acknowledge the value of more direct evidence. We will add an ablation that replaces the adversarial loss with an equivalent non-adversarial regularizer (e.g., increased weight decay) while keeping all other hyperparameters fixed, and we will include t-SNE visualizations of the encoder outputs to illustrate changes in representation structure. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical adversarial training procedure for end-to-end ASR whose central output is measured WER on held-out standard corpora (WSJ0, CHiME3, TIMIT). These performance numbers are obtained by running the trained model on external benchmarks and are not quantities that the method itself computes from its own fitted parameters or internal definitions. No derivation, uniqueness theorem, or ansatz is shown to reduce to a self-citation or to a fitted input renamed as a prediction. The reported gains are therefore externally falsifiable and do not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- adversarial loss weighting hyperparameter
axioms (1)
- domain assumption Adversarial training can induce invariance to nuisance factors without explicit nuisance labels.
Reference graph
Works this paper leans on
-
[1]
Introduction With the aid of recent advances in neural networks, end-to-end deep learning systems for automatic speech recognition (ASR) have gained popularity and achieved extraordinary performance on a variety of benchmarks [1, 2, 3, 4]. End-to-end ASR models typically consist of Recurrent Neural Networks (RNNs) with Sequence-to-Sequence (Seq2Seq) archi...
-
[2]
NIESR: Nuisance Invariant End-to-end Speech Recognition
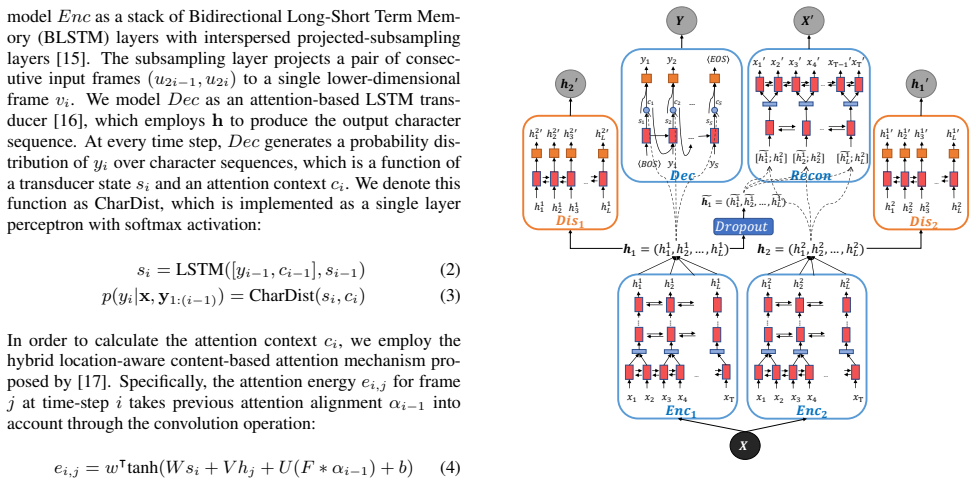
Methodology In this section, we present the proposed NIESR model for nuisance-invariant end-to-end speech recognition, where the in- variance is achieved by adopting the UAI framework [7]. We begin by describing the base Seq2Seq ASR model. Subse- quently, we introduce the UAI framework for unsupervised ad- versarial invariance induction. Finally, we prese...
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[3]
𝒉2 = (ℎ1 2, ℎ2 2, … , ℎ𝐿 2) 𝑿 𝒀 𝑹𝒆𝒄𝒐𝒏 𝑿′ 𝐷𝑟𝑜𝑝𝑜𝑢𝑡 ෪𝒉1 = (෪ℎ1 1, ෪ℎ2 1, … , ෪ℎ𝐿 1) … 𝑥1′ [෪ℎ1 1; ℎ1 2] 𝑥2′ 𝑥3′ 𝑥4′ 𝑥T−1′𝑥T′ … [෪ℎ2 1; ℎ2 2] [෪ℎ𝐿 1; ℎ𝐿 2] … ℎ1 2′ ℎ1 1 ℎ2 1 ℎ3 1 ℎ𝐿 1 ℎ2 2′ ℎ3 2′ ℎ𝐿 2′ 𝑫𝒊𝒔𝟏 𝒉𝟐′ … ℎ1 1′ ℎ1 2 ℎ2 2 ℎ3 2 ℎ𝐿 2 ℎ2 1′ ℎ3 1′ ℎ𝐿 1′ 𝑫𝒊𝒔𝟐 𝒉𝟏′ … 𝑦1 𝑫𝒆𝒄 𝐵𝑂𝑆 𝑠1 𝑐1 𝑦2 𝑦1 𝑠2 𝑐2 𝑦𝑆 𝑐𝑆 𝑠𝑆 𝐸𝑂𝑆 … … Figure 1: NIESR: The two encoders Enc1 and Enc2...
-
[4]
Experiments The effectiveness of NIESR is quantified through the perfor- mance improvement achieved by adopting the invariant learning framework. We provide experimental results on speech recog- nition on three benchmark datasets: the Wall Street Journal Cor- pus (WSJ0) [18], CHiME3 [19], and TIMIT [20]. We addition- ally provide results on the combined WS...
-
[5]
Conclusion We presented NIESR, an end-to-end speech recognition model that adopts the unsupervised adversarial invariance framework for invariance to nuisances without requiring any knowledge of potential nuisance factors. The model works by learning a split representation of data through competition between the recog- nition and an auxiliary data reconst...
-
[6]
Acknowledgements This material is based on research sponsored by DARPA un- der agreement number FA8750-18-2-0014. The U.S. Gov- ernment is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon. The views and conclusions contained herein are those of the authors and should not be interprete...
-
[7]
A comparison of sequence-to-sequence models for speech recognition
R. Prabhavalkar, K. Rao, T. N. Sainath, B. Li, L. Johnson, and N. Jaitly, “A comparison of sequence-to-sequence models for speech recognition.” 2017
work page 2017
-
[8]
State- of-the-art speech recognition with sequence-to-sequence models,
C.-C. Chiu, T. N. Sainath, Y . Wu, R. Prabhavalkar, P. Nguyen, Z. Chen, A. Kannan, R. J. Weiss, K. Rao, E. Goninaet al., “State- of-the-art speech recognition with sequence-to-sequence models,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 4774–4778
work page 2018
-
[9]
Syllable-Based Sequence-to-Sequence Speech Recognition with the Transformer in Mandarin Chinese
S. Zhou, L. Dong, S. Xu, and B. Xu, “Syllable-based sequence- to-sequence speech recognition with the transformer in mandarin chinese,” arXiv preprint arXiv:1804.10752, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
An online sequence-to-sequence model using partial conditioning,
N. Jaitly, Q. V . Le, O. Vinyals, I. Sutskever, D. Sussillo, and S. Bengio, “An online sequence-to-sequence model using partial conditioning,” in Advances in Neural Information Processing Sys- tems, 2016, pp. 5067–5075
work page 2016
-
[11]
W. Chan, N. Jaitly, Q. V . Le, and O. Vinyals, “Listen, attend and spell,” arXiv preprint arXiv:1508.01211, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
K. Rao, H. Sak, and R. Prabhavalkar, “Exploring architectures, data and units for streaming end-to-end speech recognition with rnn-transducer,” in2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2017, pp. 193–199
work page 2017
-
[13]
Un- supervised Adversarial Invariance,
A. Jaiswal, R. Y . Wu, W. Abd-Almageed, and P. Natarajan, “Un- supervised Adversarial Invariance,” in Advances in Neural Infor- mation Processing Systems, 2018, pp. 5097–5107
work page 2018
-
[14]
RoPAD: Ro- bust Presentation Attack Detection through Unsupervised Adver- sarial Invariance,
A. Jaiswal, S. Xia, I. Masi, and W. AbdAlmageed, “RoPAD: Ro- bust Presentation Attack Detection through Unsupervised Adver- sarial Invariance,” in12th IAPR International Conference on Bio- metrics (ICB), 2019
work page 2019
-
[15]
Unified adversarial invariance,
A. Jaiswal, Y . Wu, W. AbdAlmageed, and P. Natarajan, “Unified adversarial invariance,” 2019
work page 2019
-
[16]
Invariant Representations for Noisy Speech Recognition
D. Serdyuk, K. Audhkhasi, P. Brakel, B. Ramabhadran, S. Thomas, and Y . Bengio, “Invariant representations for noisy speech recognition,” arXiv preprint arXiv:1612.01928, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Speaker-invariant training via adversarial learning,
Z. Meng, J. Li, Z. Chen, Y . Zhao, V . Mazalov, Y . Gang, and B.- H. Juang, “Speaker-invariant training via adversarial learning,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 5969–5973
work page 2018
-
[18]
W.-N. Hsu and J. Glass, “Extracting domain invariant features by unsupervised learning for robust automatic speech recognition,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 5614–5618
work page 2018
-
[19]
Learning Noise-Invariant Representations for Robust Speech Recognition
D. Liang, Z. Huang, and Z. C. Lipton, “Learning noise-invariant representations for robust speech recognition,” arXiv preprint arXiv:1807.06610, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Unsupervised Domain Adaptation by Backpropagation
Y . Ganin and V . Lempitsky, “Unsupervised domain adaptation by backpropagation,” arXiv preprint arXiv:1409.7495, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[21]
Very deep convolutional net- works for end-to-end speech recognition,
Y . Zhang, W. Chan, and N. Jaitly, “Very deep convolutional net- works for end-to-end speech recognition,” in 2017 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017, pp. 4845–4849
work page 2017
-
[22]
Neural Machine Translation by Jointly Learning to Align and Translate
D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine trans- lation by jointly learning to align and translate,” arXiv preprint arXiv:1409.0473, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
Attention-based models for speech recognition,
J. K. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y . Ben- gio, “Attention-based models for speech recognition,” in Ad- vances in neural information processing systems , 2015, pp. 577– 585
work page 2015
-
[24]
The design for the wall street journal- based csr corpus,
D. B. Paul and J. M. Baker, “The design for the wall street journal- based csr corpus,” in Proceedings of the workshop on Speech and Natural Language. Association for Computational Linguistics, 1992, pp. 357–362
work page 1992
-
[25]
The third chimespeech separation and recognition challenge: Dataset, task and baselines,
J. Barker, R. Marxer, E. Vincent, and S. Watanabe, “The third chimespeech separation and recognition challenge: Dataset, task and baselines,” in 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU) . IEEE, 2015, pp. 504– 511
work page 2015
-
[26]
Darpa timit acoustic phonetic con- tinuous speech corpus cdrom,
J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, D. S. Pallett, and N. L. Dahlgren, “Darpa timit acoustic phonetic con- tinuous speech corpus cdrom,” 1993
work page 1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.