Optimized Sharing of Coefficients in Parallel Filter Banks
Pith reviewed 2026-05-24 22:54 UTC · model grok-4.3
The pith
A two-stage coefficient grouping algorithm reduces registers, LUTs and DSP48s by up to 50 percent in parallel filter banks without raising the sampling rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
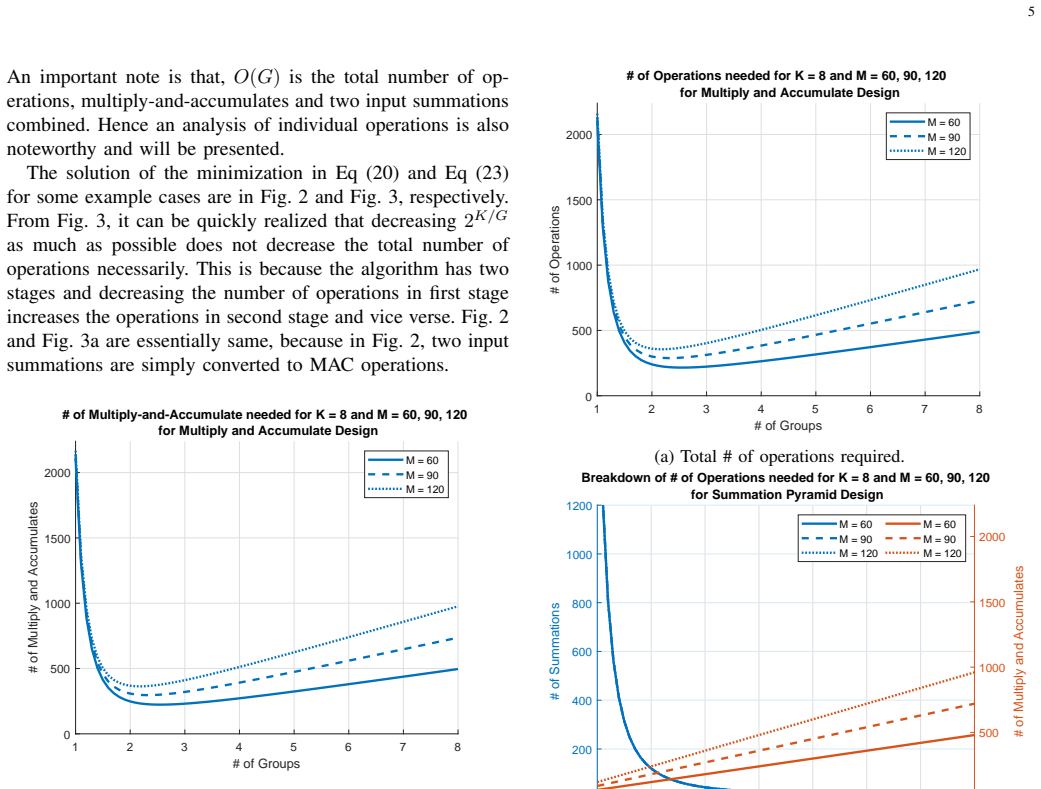
The authors state that a novel two-stage grouping process applied to the coefficients of a set of parallel filters produces greater coefficient sharing than a conventional implementation, thereby decreasing the number of registers, look-up tables and DSP48s by up to 50 percent of a regular parallel filter bank while leaving the sampling rate unchanged.
What carries the argument
The two-stage grouping process that rearranges filter coefficients to maximize reuse across the bank.
If this is right
- Hardware implementations of parallel filter banks require fewer registers, look-up tables and DSP48s.
- The sampling rate of the system does not need to increase to obtain the reported resource savings.
- The same coefficient set can be reused across multiple filters inside the bank.
- The method applies to any collection of parallel filters used as a filter bank.
Where Pith is reading between the lines
- Designers of resource-constrained embedded signal processors could adopt the grouping step as a pre-processing pass before synthesis.
- The approach may extend to other linear structures such as polyphase filter banks if the grouping logic is generalized.
- Verification on a wider range of filter lengths and coefficient precisions would clarify how often the 50 percent ceiling is reached.
Load-bearing premise
The two-stage grouping preserves the original filter frequency responses without introducing unacceptable approximation error and without forcing any change in sampling rate.
What would settle it
Synthesize both the original and the grouped-coefficient filter banks on the same FPGA fabric, measure actual register/LUT/DSP48 counts, and compare the measured magnitude responses at the same sampling rate.
Figures




read the original abstract
Filters are the basic and most important blocks of most signal processing applications. In many applications, a group of parallel filters are used as filter banks. Parallel filter banks naturally require much more computations. Especially on chip applications, the resources are limited and shared among many algorithms. For this purpose, many filter optimization schemes are proposed to reduce the number of resources that filtering operations require. In this work, a novel optimization algorithm is proposed to decrease the number of operations in a group of parallel filters. The filter coefficients are grouped in a two stage process which enables increased coefficient sharing between different filters. The algorithm is capable of decreasing the number of registers, look-up tables and DSP48s by up to 50\% of a regular parallel filter bank, without requiring increased sampling rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a novel two-stage coefficient grouping algorithm for parallel filter banks. The algorithm increases coefficient sharing across filters to reduce hardware resources (registers, LUTs, and DSP48s) by up to 50% relative to a standard parallel implementation, while exactly preserving each filter's frequency response and operating at the original sampling rate without approximation.
Significance. If the two-stage grouping process can be shown to preserve responses exactly (with no hidden approximation or sampling-rate increase) and the 50% resource reduction is demonstrated on concrete filter sets with hardware metrics, the result would be significant for resource-constrained FPGA/ASIC designs that employ parallel filter banks. The approach addresses a practical bottleneck in on-chip signal processing where DSP and logic resources are shared across multiple algorithms.
major comments (2)
- [Abstract] Abstract: The central claim of 'up to 50% reduction' in registers, LUTs, and DSP48s is stated without any supporting numerical results, example filter coefficients, error metrics (e.g., maximum deviation from original responses), or verification method. This absence prevents assessment of whether the two-stage grouping truly preserves responses exactly or introduces unacceptable approximation error.
- [Abstract] Abstract: No comparison is provided against existing coefficient-sharing or multiplierless filter optimization techniques, so it is impossible to determine whether the reported savings exceed those achievable by prior methods or whether the two-stage process introduces any new overhead that offsets the claimed gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each point below and will revise the abstract and add comparisons as needed to strengthen the presentation while preserving the manuscript's core claims of exact response preservation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'up to 50% reduction' in registers, LUTs, and DSP48s is stated without any supporting numerical results, example filter coefficients, error metrics (e.g., maximum deviation from original responses), or verification method. This absence prevents assessment of whether the two-stage grouping truly preserves responses exactly or introduces unacceptable approximation error.
Authors: The abstract summarizes the key result; the full manuscript supplies the requested details, including example coefficient sets, measured resource reductions reaching 50%, error metrics confirming maximum deviation of zero (exact preservation with no approximation), and verification via both floating-point simulation and post-synthesis FPGA metrics in Sections 3 and 4. To improve self-containment we will expand the abstract with a concise reference to these elements. revision: yes
-
Referee: [Abstract] Abstract: No comparison is provided against existing coefficient-sharing or multiplierless filter optimization techniques, so it is impossible to determine whether the reported savings exceed those achievable by prior methods or whether the two-stage process introduces any new overhead that offsets the claimed gains.
Authors: The manuscript's primary baseline is the unoptimized parallel filter bank; related coefficient-sharing and multiplierless methods are reviewed in the introduction. We agree a direct quantitative comparison would be valuable and will add a table contrasting resource savings against representative prior techniques in the revised version. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes a two-stage coefficient grouping algorithm for sharing in parallel filter banks. The abstract and provided text contain no equations, fitted parameters, self-citations, or derivations that reduce a claimed prediction or result to its own inputs by construction. The resource-reduction claim is presented as an outcome of the grouping process itself, with no detectable self-definitional or fitted-input structure. This is the normal case of a self-contained algorithmic proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. A. Richards, Fundamentals of radar signal processing . Tata McGraw-Hill Education, 2005
work page 2005
-
[2]
I. G. Cumming and F. H. Wong, “Digital processing of synthetic aperture radar data: Algorithms and implementation [with cdrom](artech house remote sensing library),” Boston, MA, USA: Artech House , 2005
work page 2005
-
[3]
M. A. Richards, J. Scheer, W. A. Holm, and W. L. Melvin, Principles of modern radar . Citeseer, 2010
work page 2010
-
[4]
H. Meyr, M. Moeneclaey, and S. Fechtel, Digital communication re- ceivers: synchronization, channel estimation, and signal processing . John Wiley & Sons, Inc., 1997
work page 1997
-
[5]
Theory of spread-spectrum communications–a tutorial,
R. Pickholtz, D. Schilling, and L. Milstein, “Theory of spread-spectrum communications–a tutorial,” IEEE transactions on Communications , vol. 30, no. 5, pp. 855–884, 1982
work page 1982
-
[6]
Low-cost digital correlator for frequency hopping radio,
S. ˇSaji´c, N. Maleti´c, M. ˇSunjevari´c, and B. Todorovi´c, “Low-cost digital correlator for frequency hopping radio,” in Systems, Signals and Image Processing (IWSSIP), 2011 18th International Conference on . IEEE, 2011, pp. 1–4
work page 2011
-
[7]
Low-complexity implementation of pn correlator for wireless transmission systems,
W. Li, K. Peng, and J. Song, “Low-complexity implementation of pn correlator for wireless transmission systems,” in Wireless Communica- tions and Networking Conference, 2009. WCNC 2009. IEEE . IEEE, 2009, pp. 1–5
work page 2009
-
[8]
J. Farrell and M. Barth, The global positioning system and inertial navigation. Mcgraw-hill New York, 1999, vol. 61
work page 1999
-
[9]
B. Hofmann-Wellenhof, H. Lichtenegger, and J. Collins, Global posi- tioning system: theory and practice . Springer Science & Business Media, 2012
work page 2012
-
[10]
Convolutional networks and applications in vision,
Y . LeCun, K. Kavukcuoglu, and C. Farabet, “Convolutional networks and applications in vision,” in Proceedings of 2010 IEEE International Symposium on Circuits and Systems . IEEE, 2010, pp. 253–256
work page 2010
-
[11]
Improving neural networks by preventing co-adaptation of feature detectors
G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov, “Improving neural networks by preventing co-adaptation of feature detectors,” arXiv preprint arXiv:1207.0580 , 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[12]
Gpu implementation of neural networks,
K.-S. Oh and K. Jung, “Gpu implementation of neural networks,” Pattern Recognition, vol. 37, no. 6, pp. 1311–1314, 2004
work page 2004
-
[13]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural infor- mation processing systems , 2012, pp. 1097–1105
work page 2012
-
[14]
Multirate digital filters, filter banks, polyphase networks, and applications: a tutorial,
P. P. Vaidyanathan, “Multirate digital filters, filter banks, polyphase networks, and applications: a tutorial,” Proceedings of the IEEE, vol. 78, no. 1, pp. 56–93, 1990
work page 1990
-
[15]
Digital receivers and transmit- ters using polyphase filter banks for wireless communications,
F. J. Harris, C. Dick, and M. Rice, “Digital receivers and transmit- ters using polyphase filter banks for wireless communications,” IEEE transactions on microwave theory and techniques , vol. 51, no. 4, pp. 1395–1412, 2003
work page 2003
-
[16]
Digital filtering by polyphase network: Application to sample-rate alteration and filter banks,
M. Bellanger, G. Bonnerot, and M. Coudreuse, “Digital filtering by polyphase network: Application to sample-rate alteration and filter banks,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 24, no. 2, pp. 109–114, 1976
work page 1976
-
[17]
N. J. Fliege, Multirate digital signal processing. John Wiley New York, 1994, vol. 994
work page 1994
-
[18]
Correlation algorithms, circuits and measurement applica- tions,
J. Jordan, “Correlation algorithms, circuits and measurement applica- tions,” in IEE Proceedings G-Electronic Circuits and Systems , vol. 133, no. 1. IET, 1986, pp. 58–74
work page 1986
-
[19]
Implementation of digit-serial filters,
M. Karlsson, “Implementation of digit-serial filters,” Ph.D. dissertation, Institutionen f ¨or konstruktions-och produktionsteknik, 2005
work page 2005
-
[20]
Low-area/power parallel fir digital filter implementations,
D. A. Parker and K. K. Parhi, “Low-area/power parallel fir digital filter implementations,” Journal of VLSI signal processing systems for signal, image and video technology , vol. 17, no. 1, pp. 75–92, 1997
work page 1997
-
[21]
Low-power correlator architectures for wideband cdma code acquisition,
S. Sriram, K. Brown, and A. Dabak, “Low-power correlator architectures for wideband cdma code acquisition,” in Signals, Systems, and Comput- ers, 1999. Conference Record of the Thirty-Third Asilomar Conference on, vol. 1. IEEE, 1999, pp. 125–129
work page 1999
-
[22]
Efficient implementation of cross-correlation in hard- ware,
D. E. Taylor, “Efficient implementation of cross-correlation in hard- ware,” Master’s thesis, Institutt for elektronikk og telekommunikasjon, 2014
work page 2014
-
[23]
Dsp: Designing for optimal results. high-performance dsp using virtex-4 fpgas,
G. Hawkes, “Dsp: Designing for optimal results. high-performance dsp using virtex-4 fpgas,” Advanced Design Guide. Xilinx Inc , vol. 1, 2005
work page 2005
-
[24]
Coefficient sharing algorithm for fil- ter banks,
M. T. Arslan, “Coefficient sharing algorithm for fil- ter banks,” MATLAB Central File Exchange, 2019. [Online]. Available: https://www.mathworks.com/matlabcentral/ fileexchange/72063-coefficient-sharing-algorithm-for-filter-banks
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.