Deep Optimizer States: Towards Scalable Training of Transformer Models Using Interleaved Offloading
Pith reviewed 2026-05-23 19:38 UTC · model grok-4.3
The pith
Splitting optimizer states into CPU-GPU scheduled subgroups via a performance model yields 2.5 times faster transformer training iterations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Deep Optimizer States splits the LLM into subgroups whose update phase is scheduled on either the CPU or the GPU based on a proposed performance model that addresses the trade-off between data movement cost, acceleration on the GPUs versus the CPUs, and competition for shared resources, thereby exploiting interleaving-induced memory fluctuations to improve hybrid CPU-GPU utilization.
What carries the argument
Deep Optimizer States, a partitioning and scheduling technique that uses a performance model to assign optimizer-state updates to CPU or GPU at each iteration.
If this is right
- Training iterations complete in less wall-clock time for the same model size and hardware.
- Larger models become trainable without adding more GPUs by making fuller use of host memory and CPU compute.
- Existing frameworks such as DeepSpeed can adopt the technique with the reported integration.
- The same interleaving principle could apply to other memory-intensive phases beyond optimizer states.
Where Pith is reading between the lines
- Similar dynamic scheduling might reduce memory pressure during fine-tuning or inference if activation memory also fluctuates predictably.
- The approach could combine with pipeline parallelism to decide offload targets per pipeline stage rather than per subgroup.
- Extending the performance model to multi-node settings would require accounting for network bandwidth in addition to PCIe.
- If the model proves accurate across more hardware generations, it could become a standard component in future distributed training runtimes.
Load-bearing premise
GPU memory utilization fluctuates enough during each training iteration to allow low-overhead dynamic offloading, and the performance model correctly predicts the best CPU-GPU assignment without hidden contention costs.
What would settle it
A controlled run on the same hardware and model where the measured iteration time using the performance-model schedule is no faster than the best static offloading baseline.
Figures


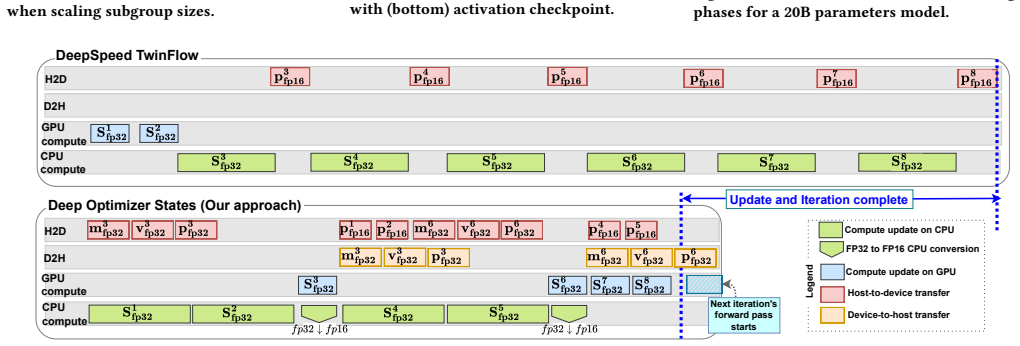

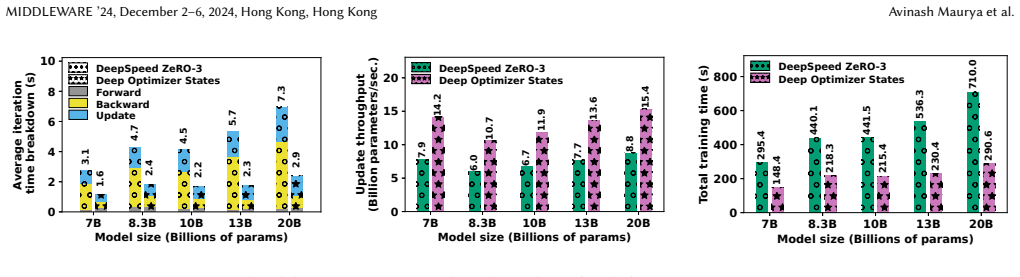



read the original abstract
Transformers and large language models~(LLMs) have seen rapid adoption in all domains. Their sizes have exploded to hundreds of billions of parameters and keep increasing. Under these circumstances, the training of transformers is very expensive and often hits a ``memory wall'', i.e., even when using 3D parallelism (pipeline, tensor, data) and aggregating the memory of many GPUs, it is still not enough to hold the necessary data structures (model parameters, optimizer state, gradients, activations) in GPU memory. To compensate, state-of-the-art approaches offload the optimizer state, at least partially, to the host memory and perform hybrid CPU-GPU computations. However, the management of the combined host-GPU memory is often suboptimal and results in poor overlapping between data movements and computations. This leads to missed opportunities to simultaneously leverage the interconnect bandwidth and computational capabilities of CPUs and GPUs. In this paper, we leverage a key observation that the interleaving of the forward, backward, and update phases generates fluctuations in the GPU memory utilization, which can be exploited to dynamically move a part of the optimizer state between the host and the GPU memory at each iteration. To this end, we design and implement Deep Optimizer States, a novel technique to split the LLM into subgroups, whose update phase is scheduled on either the CPU or the GPU based on our proposed performance model that addresses the trade-off between data movement cost, acceleration on the GPUs vs the CPUs, and competition for shared resources. We integrate our approach with DeepSpeed and demonstrate 2.5$\times$ faster iterations over state-of-the-art approaches using extensive experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by splitting LLMs into subgroups and using a performance model to dynamically schedule optimizer-state updates on CPU or GPU, Deep Optimizer States can exploit GPU memory fluctuations across forward/backward/update phases to reduce iteration time. The approach is integrated with DeepSpeed and is reported to deliver 2.5× faster iterations than prior offloading methods through extensive experiments.
Significance. If the performance model accurately captures data-movement costs, CPU/GPU acceleration differences, and shared-resource contention while keeping offload overhead low, the technique could improve hybrid CPU-GPU utilization for training models that exceed aggregate GPU memory, offering a practical extension to existing 3D-parallelism frameworks.
major comments (2)
- [§4 (Performance Model)] §4 (Performance Model): the model is described as addressing the trade-off among data-movement cost, GPU vs. CPU acceleration, and competition for shared resources, yet the derivation and any accompanying equations do not include an explicit term or validation for PCIe/memory-bandwidth contention that arises when CPU and GPU updates run concurrently; without this, the claimed optimality of the per-subgroup schedule cannot be verified.
- [§5 (Experiments)] §5 (Experiments): the 2.5× iteration speedup is asserted over state-of-the-art baselines, but the section provides no quantitative breakdown of the performance model’s prediction accuracy (e.g., measured vs. predicted iteration times), no statistical significance across repeated runs, and no ablation isolating the contribution of dynamic scheduling versus static subgroup splitting.
minor comments (1)
- [§3] Notation for subgroup partitioning and the exact definition of the performance-model objective function could be clarified with a small illustrative example in §3.
Simulated Author's Rebuttal
Dear Editor, We thank the referee for the constructive feedback on our manuscript. The comments identify opportunities to strengthen the presentation of the performance model and the experimental validation. We respond point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4 (Performance Model)] the model is described as addressing the trade-off among data-movement cost, GPU vs. CPU acceleration, and competition for shared resources, yet the derivation and any accompanying equations do not include an explicit term or validation for PCIe/memory-bandwidth contention that arises when CPU and GPU updates run concurrently; without this, the claimed optimality of the per-subgroup schedule cannot be verified.
Authors: We acknowledge that while §4 describes the model as capturing competition for shared resources, the provided equations do not isolate an explicit PCIe contention term for concurrent CPU-GPU execution. In the revised manuscript we will augment the derivation with a dedicated contention factor derived from measured effective bandwidth under simultaneous transfers, together with micro-benchmark validation. This addition will make the optimality argument for the per-subgroup schedule directly verifiable. revision: yes
-
Referee: [§5 (Experiments)] the 2.5× iteration speedup is asserted over state-of-the-art baselines, but the section provides no quantitative breakdown of the performance model’s prediction accuracy (e.g., measured vs. predicted iteration times), no statistical significance across repeated runs, and no ablation isolating the contribution of dynamic scheduling versus static subgroup splitting.
Authors: We agree that the experimental section would benefit from these elements. The current manuscript reports average iteration times but omits explicit prediction-error metrics, statistical tests, and the requested ablation. We will add (i) a table comparing measured versus predicted iteration times, (ii) standard-deviation error bars across repeated runs, and (iii) an ablation that isolates dynamic scheduling from static subgroup partitioning. These revisions will be included in the next version. revision: yes
Circularity Check
No circularity; performance model addresses trade-offs independently
full rationale
The paper's central technique splits the model into subgroups and uses a proposed performance model to decide per-subgroup CPU vs. GPU scheduling by explicitly trading off data-movement cost, CPU/GPU acceleration, and shared-resource contention. This model is introduced as a new construct to exploit observed memory fluctuations during forward/backward/update phases rather than being fitted to or defined by the reported 2.5× speedup. No self-definitional equations, fitted inputs renamed as predictions, load-bearing self-citations, or imported uniqueness theorems appear in the provided abstract or description. The experimental validation is presented as external evidence, keeping the derivation chain self-contained against the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Moiz Arif, Kevin Assogba, and M. Mustafa Rafique. Canary: Fault-tolerant faas for stateful time-sensitive applications. In SC22: International Conference for High Performance Computing, Networking, Storage and Analysis , pages 1–16, Dallas, TX, USA, 2022. IEEE
work page 2022
-
[2]
Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Lau- rence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, et al. Deep Optimizer States : Towards Scalable Training of Transformer Models Using Interleaved Offloading MIDDLEWARE ’24, December 2–6, 2024, Hong Kong, Hong Kong Gpt-neox-20b: An open-source autoregressive langua...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
modnn: Memory optimal dnn training on gpus
Xiaoming Chen, Danny Z Chen, and Xiaobo Sharon Hu. modnn: Memory optimal dnn training on gpus. In 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), pages 13–18. IEEE, 2018
work page 2018
-
[4]
Jiao Dong, Hao Zhang, Lianmin Zheng, Jun Gong, Jules S. Damji, and Phi Nguyen. Training 175b parameter language models at 1000 gpu scale with alpa and ray. https://www.anyscale.com/blog/training-175b-parameter-language-models- at-1000-gpu-scale-with-alpa-and-ray, 2023
work page 2023
-
[5]
Adaptive subgradient methods for online learning and stochastic optimization
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of machine learning research, 12(7), 2011
work page 2011
-
[6]
Dapple: A pipelined data parallel approach for training large models
Shiqing Fan, Yi Rong, Chen Meng, Zongyan Cao, Siyu Wang, Zhen Zheng, Chuan Wu, Guoping Long, Jun Yang, Lixue Xia, et al. Dapple: A pipelined data parallel approach for training large models. In Proc. of the SIGPLAN Symposium on Principles and Practice of Parallel Programming , pages 431–445, 2021
work page 2021
-
[7]
Switch transformers: scaling to trillion parameter models with simple and efficient sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(1), jan 2022
work page 2022
-
[8]
Generating sequences with recurrent neural networks, 2014
Alex Graves. Generating sequences with recurrent neural networks, 2014
work page 2014
-
[9]
Xpipe: Efficient pipeline model parallelism for multi-gpu dnn training, 2020
Lei Guan, Wotao Yin, Dongsheng Li, and Xicheng Lu. Xpipe: Efficient pipeline model parallelism for multi-gpu dnn training, 2020
work page 2020
-
[10]
Autotm: Automatic tensor movement in heterogeneous memory systems using integer linear programming
Mark Hildebrand, Jawad Khan, Sanjeev Trika, Jason Lowe-Power, and Venkatesh Akella. Autotm: Automatic tensor movement in heterogeneous memory systems using integer linear programming. In Proc. of the International Conference on Architectural Support for Programming Languages and Operating Systems , 2020
work page 2020
-
[11]
Gpipe: Efficient training of giant neural networks using pipeline parallelism
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. Advances in neural information processing systems , 32, 2019
work page 2019
-
[12]
Nanotron: Minimalistic large language model 3d-parallelism train- ing
HuggingFace. Nanotron: Minimalistic large language model 3d-parallelism train- ing. https://github.com/huggingface/nanotron
-
[13]
Whale: Efficient giant model training over heterogeneous {GPUs }
Xianyan Jia, Le Jiang, Ang Wang, Wencong Xiao, Ziji Shi, Jie Zhang, Xinyuan Li, Langshi Chen, Yong Li, Zhen Zheng, et al. Whale: Efficient giant model training over heterogeneous {GPUs }. In 2022 USENIX Annual Technical Conference (USENIX ATC 22), pages 673–688, 2022
work page 2022
-
[14]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[15]
PyTorch Distributed: Experiences on Accelerating Data Parallel Training
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, et al. Pytorch distributed: Experiences on accelerating data parallel training. arXiv preprint arXiv:2006.15704, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[16]
Cotrain: Efficient schedul- ing for large-model training upon gpu and cpu in parallel
Zhenxing Li, Qiang Cao, Yajie Chen, and Wenrui Yan. Cotrain: Efficient schedul- ing for large-model training upon gpu and cpu in parallel. In Proceedings of the 52nd International Conference on Parallel Processing , pages 92–101, 2023
work page 2023
-
[17]
M6-10t: A sharing-delinking paradigm for efficient multi-trillion parameter pretraining, 2021
Junyang Lin, An Yang, Jinze Bai, Chang Zhou, Le Jiang, Xianyan Jia, Ang Wang, Jie Zhang, Yong Li, Wei Lin, et al. M6-10t: A sharing-delinking paradigm for efficient multi-trillion parameter pretraining, 2021
work page 2021
-
[18]
Mustafa Rafique, Thierry Tonellot, and Franck Cappello
Avinash Maurya, Bogdan Nicolae, M. Mustafa Rafique, Thierry Tonellot, and Franck Cappello. Towards Efficient I/O Scheduling for Collaborative Multi-Level Checkpointing. In 2021 29th International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS) , 2021
work page 2021
-
[19]
Gpu-enabled asynchronous multi-level checkpoint caching and prefetching
Avinash Maurya, Mustafa Rafique, Thierry Tonellot, Hussain AlSalem, Franck Cappello, and Bogdan Nicolae. Gpu-enabled asynchronous multi-level checkpoint caching and prefetching. In HPDC’23: The 32nd International Symposium on High- Performance Parallel and Distributed Computing , Orlando, USA, 2023
work page 2023
-
[20]
Mustafa Rafique, Franck Cappello, and Bogdan Nicolae
Avinash Maurya, Robert Underwood, M. Mustafa Rafique, Franck Cappello, and Bogdan Nicolae. DataStates-LLM: Lazy Asynchronous Checkpointing for Large Language Models. In Proc. of the International Symposium on High-Performance Parallel and Distributed Computing , HPDC’24, 2024
work page 2024
-
[21]
Mustafa Rafique, Franck Cappello, and Bogdan Nicolae
Avinash Maurya, Jue Ye, M. Mustafa Rafique, Franck Cappello, and Bogdan Nicolae. Breaking the memory wall: A study of i/o patterns and gpu memory utilization for hybrid cpu-gpu offloaded optimizers. In FlexScience’24: Workshop on AI & Scientific Computing at Scale using Flexible Comp. Infrastructures , 2024
work page 2024
-
[22]
Mixed precision training, 2018
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. Mixed precision training, 2018
work page 2018
-
[23]
Pipedream: generalized pipeline parallelism for dnn training
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur, Gregory R Ganger, Phillip B Gibbons, and Matei Zaharia. Pipedream: generalized pipeline parallelism for dnn training. In Proceedings of the 27th ACM symposium on operating systems principles , pages 1–15, 2019
work page 2019
-
[24]
Deepfreeze: Towards scalable asynchronous checkpointing of deep learning models
Bogdan Nicolae, Jiali Li, Justin Wozniak, George Bosilca, Matthieu Dorier, and Franck Cappello. Deepfreeze: Towards scalable asynchronous checkpointing of deep learning models. In CGrid’20: 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing , Melbourne, Australia, 2020
work page 2020
-
[25]
NVIDIA Management Library (NVML)
Nvidia. NVIDIA Management Library (NVML). https://developer.nvidia.com/ management-library-nvml
-
[26]
Capuchin: Tensor-based gpu memory management for deep learning
Xuan Peng, Xuanhua Shi, Hulin Dai, Hai Jin, Weiliang Ma, Qian Xiong, Fan Yang, and Xuehai Qian. Capuchin: Tensor-based gpu memory management for deep learning. In The 25th International Conference on Architectural Support for Programming Languages and Operating Systems , pages 891–905, 2020
work page 2020
-
[27]
Gradients accumulation-pytorch
Pytorch. Gradients accumulation-pytorch. https://gist.github.com/thomwolf/ ac7a7da6b1888c2eeac8ac8b9b05d3d3, 2019
work page 2019
-
[28]
Zero: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE, 2020
work page 2020
-
[29]
Zero-infinity: breaking the gpu memory wall for extreme scale deep learning
Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, and Yuxiong He. Zero-infinity: breaking the gpu memory wall for extreme scale deep learning. In SC’21: The 2021 International Conference for High Performance Computing, Networking, Storage and Analysis, St. Louis, USA, 2021
work page 2021
-
[30]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages 3505–3506, 2020
work page 2020
-
[31]
{Zero-offload}: Democratizing {billion-scale} model training
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. {Zero-offload}: Democratizing {billion-scale} model training. In 2021 USENIX Annual Technical Conference (USENIX ATC 21), pages 551–564, 2021
work page 2021
-
[32]
Horovod: fast and easy distributed deep learning in TensorFlow
Alexander Sergeev and Mike Del Balso. Horovod: fast and easy distributed deep learning in tensorflow. arXiv preprint arXiv:1802.05799, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[34]
Shaden Smith, Mostofa Patwary, Brandon Norick, Patrick LeGresley, Samyam Rajbhandari, Jared Casper, Zhun Liu, Shrimai Prabhumoye, George Zerveas, Vijay Korthikanti, Elton Zhang, Rewon Child, Reza Yazdani Aminabadi, Julie Bernauer, Xia Song, Mohammad Shoeybi, Yuxiong He, Michael Houston, Saurabh Tiwary, and Bryan Catanzaro. Using deepspeed and megatron to ...
work page 2022
-
[35]
Shuaiwen Leon Song, Bonnie Kruft, Minjia Zhang, Conglong Li, Shiyang Chen, et al. DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies, 2023
work page 2023
-
[36]
Llama 2: Open Foundation and Fine-Tuned Chat Models, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, et al. Llama 2: Open Foundation and Fine-Tuned Chat Models, 2023
work page 2023
-
[37]
Deepspeed zero-offload++: 6x higher training throughput via collaborative cpu/gpu twin-flow, 2023
Guanhua Wang, Masahiro Tanaka, Xiaoxia Wu, Lok Chand Koppaka, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed zero-offload++: 6x higher training throughput via collaborative cpu/gpu twin-flow, 2023
work page 2023
-
[38]
Superneurons: Dynamic gpu memory management for training deep neural networks
Linnan Wang, Jinmian Ye, Yiyang Zhao, Wei Wu, Ang Li, Shuaiwen Leon Song, Zenglin Xu, and Tim Kraska. Superneurons: Dynamic gpu memory management for training deep neural networks. In Proc. of the ACM SIGPLAN symposium on principles and practice of parallel programming , 2018
work page 2018
-
[39]
Training of 1-trillion parameter ai begins
HPC Wire. Training of 1-trillion parameter ai begins. https://www.hpcwire.com/ 2023/11/13/training-of-1-trillion-parameter-scientific-ai-begins/, 2023
work page 2023
-
[40]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model, 2023
BigScience Workshop. BLOOM: A 176B-Parameter Open-Access Multilingual Language Model, 2023
work page 2023
-
[41]
Understanding the performance and estimating the cost of llm fine-tuning
Yuchen Xia, Jiho Kim, Yuhan Chen, Haojie Ye, Souvik Kundu, Nishil Talati, et al. Understanding the performance and estimating the cost of llm fine-tuning. arXiv preprint arXiv:2408.04693, 2024
-
[42]
P. Xu, X. Zhu, and D. A. Clifton. Multimodal learning with transformers: A survey. IEEE Transactions on Pattern Analysis & Machine Intelligence , 45(10), 2023
work page 2023
-
[43]
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes
Yang You, Jing Li, Sashank Reddi, Jonathan Hseu, Sanjiv Kumar, Srinadh Bho- janapalli, Xiaodan Song, James Demmel, Kurt Keutzer, and Cho-Jui Hsieh. Large batch optimization for deep learning: Training bert in 76 minutes. arXiv preprint arXiv:1904.00962, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[44]
GLM-130B: An Open Bilingual Pre-trained Model
Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, et al. Glm-130b: An open bilingual pre-trained model. arXiv preprint arXiv:2210.02414, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Distributed training of large language models
Fanlong Zeng, Wensheng Gan, Yongheng Wang, and S Yu Philip. Distributed training of large language models. In 2023 IEEE 29th International Conference on Parallel and Distributed Systems (ICPADS) , pages 840–847. IEEE, 2023
work page 2023
-
[46]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[47]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Scalefold: Reducing alphafold initial training time to 10 hours, 2024
Feiwen Zhu, Arkadiusz Nowaczynski, Rundong Li, Jie Xin, Yifei Song, Michal Marcinkiewicz, Sukru Burc Eryilmaz, Jun Yang, and Michael Andersch. Scalefold: Reducing alphafold initial training time to 10 hours, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.