Motion-2-To-3: Leveraging 2D Motion Data for 3D Motion Generations
Pith reviewed 2026-05-23 06:34 UTC · model grok-4.3
The pith
Disentangling local joint motion from global movements lets 2D video data train more diverse text-driven 3D human motion generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A single-view 2D local motion generator trained on large text-2D motion pairs can be fine-tuned with 3D data to become a multi-view generator that outputs view-consistent local joint motion together with root dynamics, thereby using 2D data to support a wider range of realistic 3D human motion generation from text.
What carries the argument
Disentanglement of local joint motion from global movements, which isolates transferable local priors that can be learned from 2D video before 3D fine-tuning.
Load-bearing premise
That separating local joint motion from global movements allows local priors learned from 2D data to transfer usefully when the model is later fine-tuned on 3D data.
What would settle it
A side-by-side test on the same text prompts showing that the 2D-pretrained model produces lower motion diversity scores or poorer multi-view consistency than an otherwise identical model trained only on 3D data.
Figures


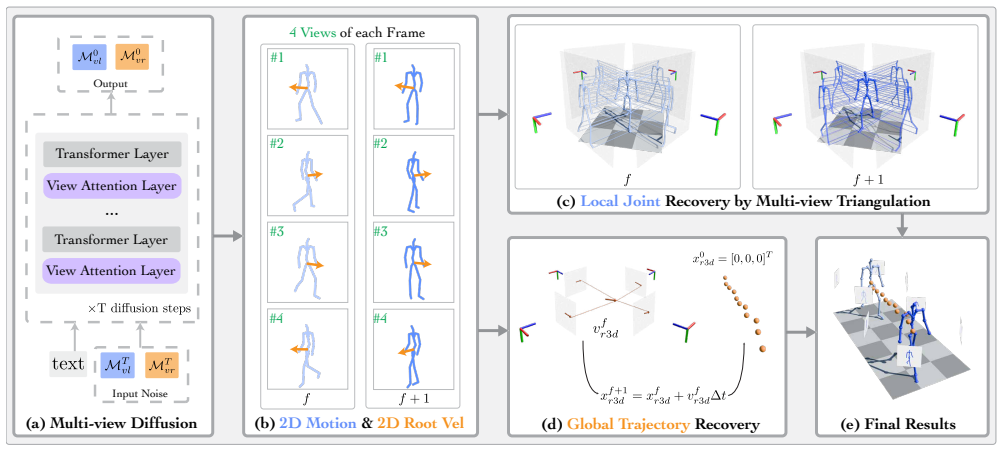
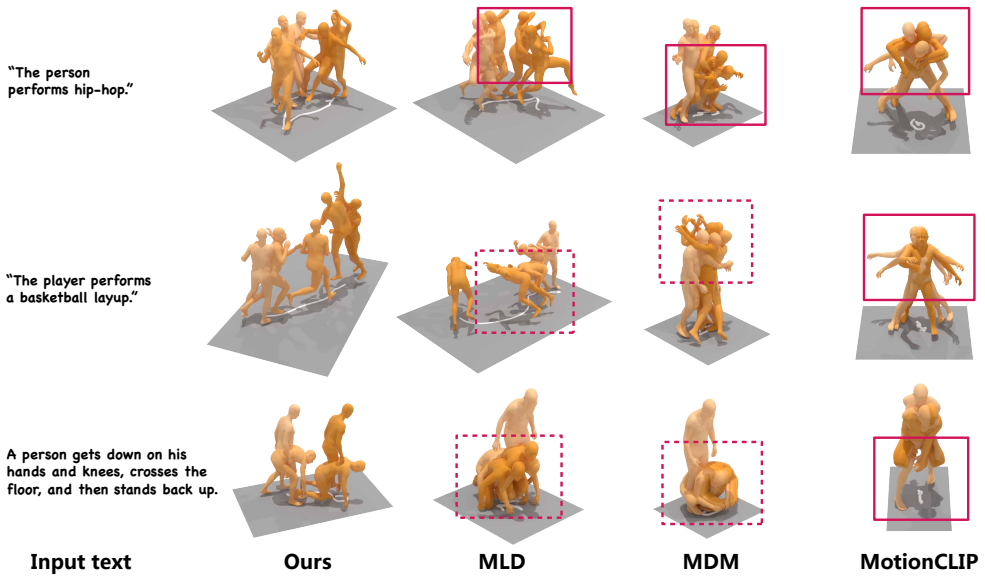
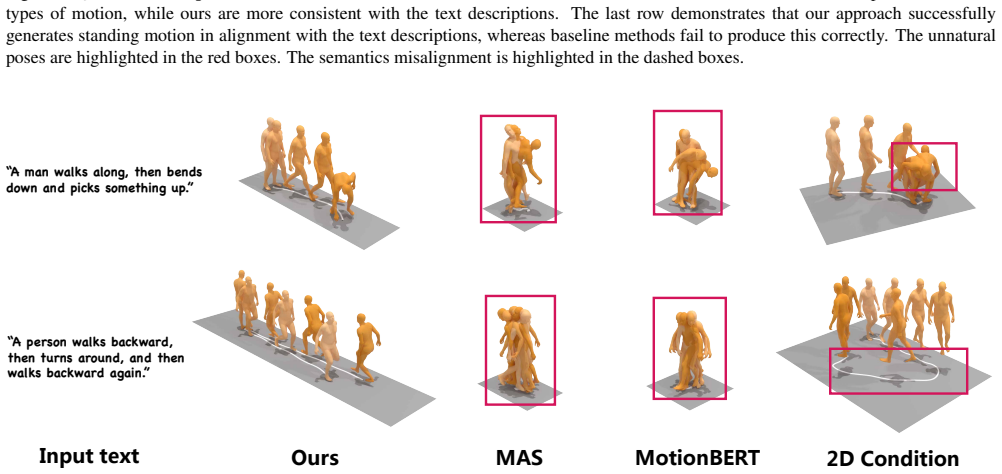
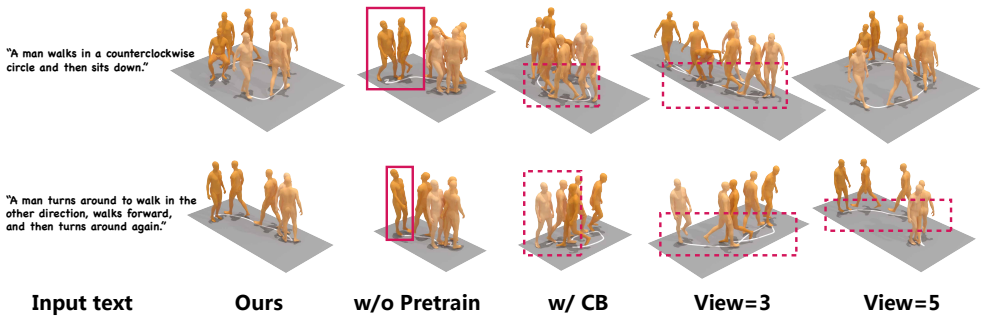
read the original abstract
Text-driven human motion synthesis has showcased its potential for revolutionizing motion design in the movie and game industry. Existing methods often rely on 3D motion capture data, which requires special setups, resulting in high costs for data acquisition, ultimately limiting the diversity and scope of human motion. In contrast, 2D human videos offer a vast and accessible source of motion data, covering a wider range of styles and activities. In this paper, we explore the use of 2D human motion extracted from videos as an alternative data source to improve text-driven 3D motion generation. Our approach introduces a novel framework that disentangles local joint motion from global movements, enabling efficient learning of local motion priors from 2D data. We first train a single-view 2D local motion generator on a large dataset of text-2D motion pairs. Then we fine-tune the generator with 3D data, transforming it into a multi-view generator that predicts view-consistent local joint motion and root dynamics. Evaluations on the well-acknowledged dataset and novel text prompts demonstrate that our method can efficiently utilize 2D data, supporting a wider range of realistic 3D human motion generation. Our code is publicly available at https://zju3dv.github.io/Motion-2-to-3/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Motion-2-To-3, a framework for text-driven 3D human motion generation that uses abundant 2D video data as an alternative to scarce 3D mocap. It disentangles local joint motion from global movements, pre-trains a single-view 2D local motion generator on large text-2D pairs, then fine-tunes on 3D data to produce a multi-view generator outputting view-consistent local motions and root dynamics. Evaluations on standard datasets and novel prompts are claimed to show efficient 2D data utilization and a wider range of realistic 3D motions; code is released publicly.
Significance. If the transfer of 2D-derived local priors through fine-tuning holds and produces measurable gains in diversity and realism without sacrificing multi-view consistency, the work would meaningfully expand accessible training data for 3D motion synthesis, reducing reliance on expensive mocap setups. The public code release supports reproducibility and is a clear strength.
major comments (2)
- [Approach] Approach section (disentanglement step): the central claim that disentangling local joint motion from global movements isolates view-invariant local dynamics from 2D videos (despite projection ambiguities, depth loss, and camera motion) is load-bearing for the efficiency argument, yet no concrete mechanism, loss terms, or validation is described to show that the priors survive fine-tuning without being overwritten or introducing inconsistencies.
- [Experiments] Experiments/Evaluation: the abstract states that evaluations 'demonstrate that our method can efficiently utilize 2D data,' but no quantitative ablations, baselines (e.g., 3D-only training), error bars, or metrics isolating the 2D pre-training contribution are visible; without these, the claim that 2D data supports a 'wider range' cannot be assessed and is not yet load-bearing evidence.
minor comments (1)
- [Abstract] The abstract refers to 'the well-acknowledged dataset' without naming it (e.g., HumanML3D or AMASS); this should be explicit in the first paragraph of the evaluation section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that will strengthen the manuscript.
read point-by-point responses
-
Referee: [Approach] Approach section (disentanglement step): the central claim that disentangling local joint motion from global movements isolates view-invariant local dynamics from 2D videos (despite projection ambiguities, depth loss, and camera motion) is load-bearing for the efficiency argument, yet no concrete mechanism, loss terms, or validation is described to show that the priors survive fine-tuning without being overwritten or introducing inconsistencies.
Authors: We acknowledge that the current description of the disentanglement step is high-level and would benefit from greater specificity. In the revised manuscript we will expand the Approach section to explicitly describe the mechanism: local joint motion is obtained by removing global root translation and orientation from the pose sequence, yielding a representation that is independent of camera viewpoint. We will also detail the loss terms used in the 2D pre-training stage (reconstruction, adversarial, and text-alignment losses) and the fine-tuning stage, together with new validation experiments (e.g., consistency checks across held-out views and ablation of the disentanglement) that demonstrate the local priors are preserved rather than overwritten. These additions will make the load-bearing claim fully transparent. revision: yes
-
Referee: [Experiments] Experiments/Evaluation: the abstract states that evaluations 'demonstrate that our method can efficiently utilize 2D data,' but no quantitative ablations, baselines (e.g., 3D-only training), error bars, or metrics isolating the 2D pre-training contribution are visible; without these, the claim that 2D data supports a 'wider range' cannot be assessed and is not yet load-bearing evidence.
Authors: We agree that the experimental evidence for the contribution of 2D pre-training must be strengthened with quantitative ablations. In the revision we will add: (i) a direct 3D-only training baseline, (ii) an ablation that removes the 2D pre-training stage, (iii) standard metrics (FID, diversity, multi-view consistency) reported with error bars from multiple runs, and (iv) results on the novel-prompt set that quantify the increase in motion variety. These new results will isolate the benefit of 2D data and provide load-bearing support for the efficiency claim. revision: yes
Circularity Check
No circularity: standard pretrain-then-finetune pipeline with no equations or self-referential reductions.
full rationale
The paper presents a two-stage training procedure (pretrain single-view 2D local motion generator on text-2D pairs, then fine-tune on 3D data to obtain multi-view consistency) after a disentanglement step. No equations, fitted parameters, or predictions are described that reduce by construction to the inputs. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text. The central claim rests on empirical evaluation of the resulting generator rather than any definitional or citation-based loop, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Disentangling local joint motion from global movements enables efficient learning of local motion priors from 2D data that transfer to 3D.
Forward citations
Cited by 1 Pith paper
-
CoMoVi: Co-Generation of 3D Human Motions and Realistic Videos
CoMoVi co-generates 3D human motions and 2D videos synchronously in a single diffusion denoising loop using 3D-to-2D projection and dual-branch diffusion with 3D-2D cross attentions.
Reference graph
Works this paper leans on
-
[1]
Easymocap - make human motion capture easier. Github,
-
[2]
Lan- guage2pose: Natural language grounded pose forecasting
Chaitanya Ahuja and Louis-Philippe Morency. Lan- guage2pose: Natural language grounded pose forecasting. In 3DV, 2019. 2
work page 2019
-
[3]
Nikos Athanasiou, Mathis Petrovich, Michael J. Black, and G¨ul Varol. SINC: Spatial composition of 3D human motions for simultaneous action generation. ICCV, 2023. 3
work page 2023
-
[4]
Make-an-animation: Large-scale text- conditional 3d human motion generation
Samaneh Azadi, Akbar Shah, Thomas Hayes, Devi Parikh, and Sonal Gupta. Make-an-animation: Large-scale text- conditional 3d human motion generation. In Proceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 15039–15048, 2023. 2, 3, 6
work page 2023
-
[5]
Belfusion: Latent diffusion for behavior-driven human mo- tion prediction
German Barquero, Sergio Escalera, and Cristina Palmero. Belfusion: Latent diffusion for behavior-driven human mo- tion prediction. In ICCV, 2023. 3
work page 2023
-
[6]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023. 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with la- tent diffusion models. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 22563–22575, 2023. 3
work page 2023
-
[8]
Keep it smpl: Automatic estimation of 3d human pose and shape from a single image
Federica Bogo, Angjoo Kanazawa, Christoph Lassner, Peter Gehler, Javier Romero, and Michael J Black. Keep it smpl: Automatic estimation of 3d human pose and shape from a single image. In Computer Vision–ECCV 2016: 14th Euro- pean Conference, Amsterdam, The Netherlands, October 11- 14, 2016, Proceedings, Part V 14, pages 561–578. Springer,
work page 2016
-
[9]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, Sand- hini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, S...
work page 2020
-
[10]
Gener- ating human motion in 3d scenes from text descriptions
Zhi Cen, Huaijin Pi, Sida Peng, Zehong Shen, Minghui Yang, Shuai Zhu, Hujun Bao, and Xiaowei Zhou. Gener- ating human motion in 3d scenes from text descriptions. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 1855–1866, 2024. 3
work page 2024
-
[11]
Maskgit: Masked generative image transformer
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11315–11325, 2022. 3
work page 2022
-
[12]
Fan- tasia3d: Disentangling geometry and appearance for high- quality text-to-3d content creation
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. Fan- tasia3d: Disentangling geometry and appearance for high- quality text-to-3d content creation. In Proceedings of the IEEE/CVF international conference on computer vision , pages 22246–22256, 2023. 3
work page 2023
-
[13]
Executing your Commands via Motion Diffusion in Latent Space
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, Jingyi Yu, and Gang Yu. Executing your Commands via Motion Diffusion in Latent Space. arXiv e-prints, art. arXiv:2212.04048, 2022. 3, 6
-
[14]
Mofusion: A framework for denoising-diffusion-based motion synthesis
Rishabh Dabral, Muhammad Hamza Mughal, Vladislav Golyanik, and Christian Theobalt. Mofusion: A framework for denoising-diffusion-based motion synthesis. In CVPR,
-
[15]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13142–13153, 2023. 3
work page 2023
-
[16]
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models. arXiv preprint arXiv:2405.10314, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Synthesis of compositional animations from textual descriptions
Anindita Ghosh, Noshaba Cheema, Cennet Oguz, Christian Theobalt, and Philipp Slusallek. Synthesis of compositional animations from textual descriptions. In ICCV, 2021. 2
work page 2021
-
[18]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19...
work page 2024
-
[19]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. In CVPR, 2022. 1, 2, 3, 5, 6, 7
work page 2022
-
[21]
Chuan Guo, Xinxin Zuo, Sen Wang, and Li Cheng. Tm2t: Stochastic and tokenized modeling for the reciprocal gener- ation of 3d human motions and texts. In ECCV, 2022. 3
work page 2022
-
[22]
Momask: Generative masked model- ing of 3d human motions
Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Sen Wang, and Li Cheng. Momask: Generative masked model- ing of 3d human motions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 1900–1910, 2024. 3
work page 1900
-
[23]
Richard I. Hartley and Peter Sturm. Triangulation. Computer Vision and Image Understanding, 68(2):146 – 157, 1997. 3, 4, 5
work page 1997
-
[24]
Denoising diffu- sion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models. In NeurIPS, 2020. 3, 4, 6
work page 2020
-
[25]
Avatarclip: zero-shot text- driven generation and animation of 3d avatars
Fangzhou Hong, Mingyuan Zhang, Liang Pan, Zhongang Cai, Lei Yang, and Ziwei Liu. Avatarclip: zero-shot text- driven generation and animation of 3d avatars. ACM Trans. Graph., 41(4), 2022. 3
work page 2022
-
[26]
Motiongpt: Human motion as a foreign lan- 9 guage
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign lan- 9 guage. Advances in Neural Information Processing Systems, 36:20067–20079, 2023. 3
work page 2023
-
[27]
Mas: Multi-view ancestral sampling for 3d motion generation using 2d diffusion
Roy Kapon, Guy Tevet, Daniel Cohen-Or, and Amit H Bermano. Mas: Multi-view ancestral sampling for 3d motion generation using 2d diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1965–1974, 2024. 3, 4, 5, 6, 7, 8
work page 1965
-
[28]
Guided motion diffusion for controllable human motion synthesis
Korrawe Karunratanakul, Konpat Preechakul, Supasorn Suwajanakorn, and Siyu Tang. Guided motion diffusion for controllable human motion synthesis. In ICCV, 2023. 3
work page 2023
-
[29]
Oren Katzir, Or Patashnik, Daniel Cohen-Or, and Dani Lischinski. Noise-free score distillation. arXiv preprint arXiv:2310.17590, 2023. 3
-
[30]
Emdb: The electromagnetic database of global 3d human pose and shape in the wild
Manuel Kaufmann, Jie Song, Chen Guo, Kaiyue Shen, Tian- jian Jiang, Chengcheng Tang, Juan Jos ´e Z ´arate, and Otmar Hilliges. Emdb: The electromagnetic database of global 3d human pose and shape in the wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 14632–14643, 2023. 2
work page 2023
-
[31]
Flame: Free- form language-based motion synthesis & editing
Jihoon Kim, Jiseob Kim, and Sungjoon Choi. Flame: Free- form language-based motion synthesis & editing. In AAAI,
-
[32]
Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. arXiv e-prints, 2014. 5
work page 2014
-
[33]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In NeurIPS, 2022. 3
work page 2022
-
[34]
Priority-centric human motion genera- tion in discrete latent space
Hanyang Kong, Kehong Gong, Dongze Lian, Michael Bi Mi, and Xinchao Wang. Priority-centric human motion genera- tion in discrete latent space. In ICCV, 2023. 3
work page 2023
-
[35]
Eschernet: A genera- tive model for scalable view synthesis
Xin Kong, Shikun Liu, Xiaoyang Lyu, Marwan Taher, Xi- aojuan Qi, and Andrew J Davison. Eschernet: A genera- tive model for scalable view synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9503–9513, 2024. 3
work page 2024
-
[36]
Autoregressive image generation using residual quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive image generation using residual quantization. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 11523–11532, 2022. 3
work page 2022
-
[37]
Mage: Masked generative encoder to unify representation learning and image synthe- sis
Tianhong Li, Huiwen Chang, Shlok Mishra, Han Zhang, Dina Katabi, and Dilip Krishnan. Mage: Masked generative encoder to unify representation learning and image synthe- sis. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition , pages 2142–2152,
-
[38]
Omg: Towards open-vocabulary motion generation via mix- ture of controllers
Han Liang, Jiacheng Bao, Ruichi Zhang, Sihan Ren, Yuecheng Xu, Sibei Yang, Xin Chen, Jingyi Yu, and Lan Xu. Omg: Towards open-vocabulary motion generation via mix- ture of controllers. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 482–493, 2024. 3, 6
work page 2024
-
[39]
Magic3d: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 300–309, 2023. 3
work page 2023
-
[40]
Being comes from not-being: Open-vocabulary text-to-motion generation with wordless training
Junfan Lin, Jianlong Chang, Lingbo Liu, Guanbin Li, Liang Lin, Qi Tian, and Chang-wen Chen. Being comes from not-being: Open-vocabulary text-to-motion generation with wordless training. In CVPR, 2023. 3
work page 2023
-
[41]
Motion-x: A large- scale 3d expressive whole-body human motion dataset
Jing Lin, Ailing Zeng, Shunlin Lu, Yuanhao Cai, Ruimao Zhang, Haoqian Wang, and Lei Zhang. Motion-x: A large- scale 3d expressive whole-body human motion dataset. Ad- vances in Neural Information Processing Systems, 36, 2024. 2, 5
work page 2024
-
[42]
Align your gaussians: Text-to-4d with dynamic 3d gaussians and composed diffusion models
Huan Ling, Seung Wook Kim, Antonio Torralba, Sanja Fi- dler, and Karsten Kreis. Align your gaussians: Text-to-4d with dynamic 3d gaussians and composed diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8576–8588, 2024. 3
work page 2024
-
[43]
Plan, posture and go: To- wards open-world text-to-motion generation
Jinpeng Liu, Wenxun Dai, Chunyu Wang, Yiji Cheng, Yan- song Tang, and Xin Tong. Plan, posture and go: To- wards open-world text-to-motion generation. arXiv preprint arXiv:2312.14828, 2023. 3
-
[44]
One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimiza- tion
Minghua Liu, Chao Xu, Haian Jin, Linghao Chen, Mukund Varma T, Zexiang Xu, and Hao Su. One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimiza- tion. Advances in Neural Information Processing Systems , 36, 2024. 3
work page 2024
-
[45]
Zero-1-to- 3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to- 3: Zero-shot one image to 3d object. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9298–9309, 2023. 2, 3, 6, 7
work page 2023
-
[46]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. SMPL: A skinned multi- person linear model. ACM Trans. Graph., 2015. 5
work page 2015
-
[47]
Amass: Archive of motion capture as surface shapes
Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Ger- ard Pons-Moll, and Michael J Black. Amass: Archive of motion capture as surface shapes. In ICCV, 2019. 2, 3, 5, 6
work page 2019
-
[48]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis. Commun. ACM, 2021. 3
work page 2021
-
[49]
OpenAI. Openai: Introducing chatgpt. https : / / openai.com/blog/chatgpt, 2022. 3, 5
work page 2022
- [50]
- [51]
-
[52]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3d hands, face, and body from a single image. In CVPR, 2019. 5
work page 2019
-
[53]
Mathis Petrovich, Michael J. Black, and G ¨ul Varol. Action- conditioned 3D human motion synthesis with transformer V AE. InICCV, 2021. 3
work page 2021
-
[54]
Mathis Petrovich, Michael J. Black, and G ¨ul Varol. TEMOS: Generating diverse human motions from textual descriptions. In ECCV, 2022. 2, 3
work page 2022
-
[55]
Hierarchical generation of human-object inter- actions with diffusion probabilistic models
Huaijin Pi, Sida Peng, Minghui Yang, Xiaowei Zhou, and Hujun Bao. Hierarchical generation of human-object inter- actions with diffusion probabilistic models. In ICCV, 2023. 3 10
work page 2023
-
[56]
The kit motion-language dataset
Matthias Plappert, Christian Mandery, and Tamim Asfour. The kit motion-language dataset. Big data, 2016. 2
work page 2016
-
[57]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Milden- hall. DreamFusion: Text-to-3D using 2D Diffusion. arXiv e-prints, art. arXiv:2209.14988, 2022. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[58]
Punnakkal, Arjun Chandrasekaran, Nikos Athanasiou, Alejandra Quiros-Ramirez, and Michael J
Abhinanda R. Punnakkal, Arjun Chandrasekaran, Nikos Athanasiou, Alejandra Quiros-Ramirez, and Michael J. Black. Babel: Bodies, action and behavior with english la- bels. In CVPR, 2021. 2
work page 2021
-
[59]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. In ICML, 2021. 3, 4
work page 2021
-
[60]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020. 3
work page 2020
-
[61]
Generat- ing diverse high-fidelity images with vq-vae-2
Ali Razavi, Aaron van den Oord, and Oriol Vinyals. Generat- ing diverse high-fidelity images with vq-vae-2. In NeurIPS,
-
[62]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. In CVPR, 2022. 3, 6
work page 2022
-
[63]
Human motion diffusion as a generative prior
Yoni Shafir, Guy Tevet, Roy Kapon, and Amit Haim Bermano. Human motion diffusion as a generative prior. In The Twelfth International Conference on Learning Rep- resentations, 2024. 3
work page 2024
-
[64]
MVDream: Multi-view Diffusion for 3D Generation
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d gen- eration. arXiv preprint arXiv:2308.16512, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Wham: Reconstructing world-grounded humans with accu- rate 3d motion
Soyong Shin, Juyong Kim, Eni Halilaj, and Michael J Black. Wham: Reconstructing world-grounded humans with accu- rate 3d motion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 2070– 2080, 2024. 4, 5
work page 2070
-
[66]
Text-to-4d dy- namic scene generation
Uriel Singer, Shelly Sheynin, Adam Polyak, Oron Ashual, Iurii Makarov, Filippos Kokkinos, Naman Goyal, Andrea Vedaldi, Devi Parikh, Justin Johnson, et al. Text-to-4d dy- namic scene generation. arXiv preprint arXiv:2301.11280 ,
-
[67]
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for effi- cient 3d content creation. arXiv preprint arXiv:2309.16653,
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior
Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, and Dong Chen. Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior. In Pro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 22819–22829, 2023. 3
work page 2023
-
[69]
Motionclip: Exposing human motion generation to clip space
Guy Tevet, Brian Gordon, Amir Hertz, Amit H Bermano, and Daniel Cohen-Or. Motionclip: Exposing human motion generation to clip space. In ECCV, 2022. 2, 3
work page 2022
-
[70]
Human motion diffu- sion model
Guy Tevet, Sigal Raab, Brian Gordon, Yoni Shafir, Daniel Cohen-or, and Amit Haim Bermano. Human motion diffu- sion model. In ICLR, 2023. 2, 3, 4, 5, 6, 8
work page 2023
-
[71]
Llama: Open and efficient foundation lan- guage models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, Aure- lien Rodriguez, Armand Joulin, Edouard Grave, and Guil- laume Lample. Llama: Open and efficient foundation lan- guage models. arXiv preprint, 2023. 3
work page 2023
-
[72]
Textmesh: Gen- eration of realistic 3d meshes from text prompts
Christina Tsalicoglou, Fabian Manhardt, Alessio Tonioni, Michael Niemeyer, and Federico Tombari. Textmesh: Gen- eration of realistic 3d meshes from text prompts. In 2024 International Conference on 3D Vision (3DV), pages 1554–
work page 2024
-
[73]
Neural discrete representation learning
Aaron van den Oord, Oriol Vinyals, and koray kavukcuoglu. Neural discrete representation learning. In NeurIPS, 2017. 3
work page 2017
-
[74]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017. 4, 5
work page 2017
-
[75]
Vicon. Vicon. https://www.vicon.com/. 2
-
[76]
Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation
Haochen Wang, Xiaodan Du, Jiahao Li, Raymond A Yeh, and Greg Shakhnarovich. Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12619–12629, 2023. 3
work page 2023
-
[77]
Holistic-motion2d: Scalable whole-body human motion generation in 2d space
Yuan Wang, Zhao Wang, Junhao Gong, Di Huang, Tong He, Wanli Ouyang, Jile Jiao, Xuetao Feng, Qi Dou, Shix- iang Tang, et al. Holistic-motion2d: Scalable whole-body human motion generation in 2d space. arXiv preprint arXiv:2406.11253, 2024. 3
-
[78]
Humanise: Language-conditioned hu- man motion generation in 3d scenes
Zan Wang, Yixin Chen, Tengyu Liu, Yixin Zhu, Wei Liang, and Siyuan Huang. Humanise: Language-conditioned hu- man motion generation in 3d scenes. In NeurIPS, 2022. 3
work page 2022
-
[79]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion. Advances in Neural Information Processing Systems , 36, 2024. 3
work page 2024
-
[80]
Omnicontrol: Control any joint at any time for human motion generation
Yiming Xie, Varun Jampani, Lei Zhong, Deqing Sun, and Huaizu Jiang. Omnicontrol: Control any joint at any time for human motion generation. In The Twelfth International Conference on Learning Representations, 2024. 3
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.