LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning
Pith reviewed 2026-05-19 07:48 UTC · model grok-4.3
The pith
Reinforcement learning enables a 32B model to generate superior ultra-long text without synthetic data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Starting entirely from scratch without any annotated or synthetic data, reinforcement learning guides the base model to engage in reasoning that facilitates planning and refinement during the writing process, supported by specialized reward models for length control, writing quality, and structural formatting, resulting in the LongWriter-Zero model that outperforms traditional SFT methods and even larger models on long-form writing benchmarks.
What carries the argument
The RL-based incentivization process with specialized reward models that steer the model towards better length control, quality, and formatting through reasoning and refinement.
If this is right
- Ultra-long generation becomes possible without the cost and quality issues of synthetic SFT data.
- The model learns to plan and refine its writing internally via RL-induced reasoning.
- Performance exceeds that of much larger models like 100B+ parameter ones on specific benchmarks.
- Open-sourcing allows replication and extension of the RL approach for long text tasks.
Where Pith is reading between the lines
- This approach might generalize to other sequence generation tasks where coherence over long outputs is key, such as multi-turn dialogues or technical documentation.
- Reward models could be refined further to target specific aspects like creativity or factual accuracy in long texts.
- Combining this RL method with existing long-context architectures might push generation lengths even further.
Load-bearing premise
The specialized reward models provide reliable signals that genuinely improve generation without introducing biases or artifacts that undermine coherence over ultra-long sequences.
What would settle it
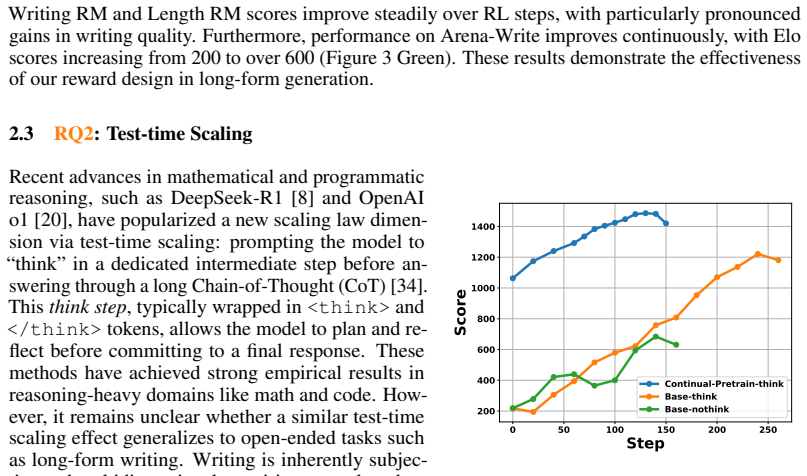
Running the LongWriter-Zero model on ultra-long writing tasks and finding that it produces less coherent or lower quality outputs than SFT baselines or larger models on WritingBench and Arena-Write would falsify the claim.
Figures



read the original abstract
Ultra-long generation by large language models (LLMs) is a widely demanded scenario, yet it remains a significant challenge due to their maximum generation length limit and overall quality degradation as sequence length increases. Previous approaches, exemplified by LongWriter, typically rely on ''teaching'', which involves supervised fine-tuning (SFT) on synthetic long-form outputs. However, this strategy heavily depends on synthetic SFT data, which is difficult and costly to construct, often lacks coherence and consistency, and tends to be overly artificial and structurally monotonous. In this work, we propose an incentivization-based approach that, starting entirely from scratch and without relying on any annotated or synthetic data, leverages reinforcement learning (RL) to foster the emergence of ultra-long, high-quality text generation capabilities in LLMs. We perform RL training starting from a base model, similar to R1-Zero, guiding it to engage in reasoning that facilitates planning and refinement during the writing process. To support this, we employ specialized reward models that steer the LLM towards improved length control, writing quality, and structural formatting. Experimental evaluations show that our LongWriter-Zero model, trained from Qwen2.5-32B, consistently outperforms traditional SFT methods on long-form writing tasks, achieving state-of-the-art results across all metrics on WritingBench and Arena-Write, and even surpassing 100B+ models such as DeepSeek R1 and Qwen3-235B. We open-source our data and model checkpoints under https://huggingface.co/THU-KEG/LongWriter-Zero-32B
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LongWriter-Zero, an RL-based method that starts from the Qwen2.5-32B base model and employs specialized reward models for length control, writing quality, and structural formatting to elicit ultra-long, high-quality text generation without any annotated or synthetic data. It reports consistent outperformance over SFT baselines and even 100B+ models on WritingBench and Arena-Write, with open-sourced model checkpoints and data.
Significance. If the results hold under scrutiny, the work would be significant for showing that pure incentivization via RL can produce scalable ultra-long generation capabilities, sidestepping the coherence and cost issues of synthetic SFT data. The explicit open-sourcing of data and checkpoints is a clear strength that aids reproducibility and community follow-up.
major comments (2)
- [Abstract and Method section] Abstract and Method section: The load-bearing claim that the approach operates 'entirely from scratch and without relying on any annotated or synthetic data' depends on the specialized reward models supplying unbiased signals that scale to ultra-long coherence; the manuscript provides no details on the reward models' own training data, sequence lengths used, or validation procedures, leaving open the possibility that they introduce the very synthetic dependencies the paper aims to avoid.
- [Experiments section] Experiments section: The SOTA claims across all metrics on WritingBench and Arena-Write, including surpassing DeepSeek R1 and Qwen3-235B, rest on the assumption that RL training is stable and free of post-hoc adjustments; without reported diagnostics on reward model reliability or generation stability over ultra-long sequences, the superiority over traditional SFT methods cannot be fully evaluated.
minor comments (2)
- The Hugging Face link for open-sourced resources should include explicit instructions for reproducing the RL training setup.
- [Method section] Notation for the three reward components (length, quality, formatting) could be formalized with equations to improve clarity in the method description.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We address each of the major comments point by point below, providing clarifications and indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and Method section] Abstract and Method section: The load-bearing claim that the approach operates 'entirely from scratch and without relying on any annotated or synthetic data' depends on the specialized reward models supplying unbiased signals that scale to ultra-long coherence; the manuscript provides no details on the reward models' own training data, sequence lengths used, or validation procedures, leaving open the possibility that they introduce the very synthetic dependencies the paper aims to avoid.
Authors: We appreciate the referee's careful reading and agree that more transparency regarding the reward models is necessary to support our claim. The reward models were developed to provide general signals for length, quality, and structure without depending on synthetic ultra-long texts. To fully address this concern, we will revise the Method section to include comprehensive details on the reward models, such as the sources of their training data (general writing quality datasets), the sequence lengths employed during their training, and the validation procedures used to ensure reliability. This addition will clarify that the RL process itself does not rely on annotated or synthetic long-form data. revision: yes
-
Referee: [Experiments section] Experiments section: The SOTA claims across all metrics on WritingBench and Arena-Write, including surpassing DeepSeek R1 and Qwen3-235B, rest on the assumption that RL training is stable and free of post-hoc adjustments; without reported diagnostics on reward model reliability or generation stability over ultra-long sequences, the superiority over traditional SFT methods cannot be fully evaluated.
Authors: We acknowledge the importance of providing evidence for training stability to substantiate the experimental claims. In the revised manuscript, we will include additional figures and text in the Experiments section showing the evolution of rewards during RL training and metrics assessing output stability, such as variance in quality scores across long sequences. These diagnostics will demonstrate the reliability of the process and support the reported performance improvements over SFT baselines. revision: yes
Circularity Check
No significant circularity; standard RL setup with external reward models
full rationale
The paper's central claim rests on applying reinforcement learning (starting from Qwen2.5-32B) with specialized reward models for length control, writing quality, and structural formatting to incentivize ultra-long generation capabilities. This is an empirical training procedure rather than a mathematical derivation chain. No equations, fitted parameters renamed as predictions, or self-citations that reduce the core result to inputs by construction are present in the provided abstract and method description. The approach is benchmarked against external datasets (WritingBench, Arena-Write) and compared to other models, making the performance claims falsifiable outside any internal definitions. The reward models are treated as independent steering mechanisms, not quantities defined in terms of the target outputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we employ specialized reward models that steer the LLM towards improved length control, writing quality, and structural formatting... Afinal = 1/3 (Alength + Awrite + Aformat)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We perform RL training starting from a base model, similar to R1-Zero, guiding it to engage in reasoning that facilitates planning and refinement
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GRPO... normalized advantages over a group of sampled completions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The llama 4 herd: The beginning of a new era of natively multimodal ai innovation, April 2025
Meta AI. The llama 4 herd: The beginning of a new era of natively multimodal ai innovation, April 2025. URL https://ai.meta.com/blog/ llama-4-multimodal-intelligence/
work page 2025
-
[2]
Anthropic: Introducing claude 3.5 sonnet, 2024
Anthropic. Anthropic: Introducing claude 3.5 sonnet, 2024. URL https://www. anthropic.com/news/claude-3-5-sonnet
work page 2024
-
[3]
Anthropic: Introducing claude 4, 2025
Anthropic. Anthropic: Introducing claude 4, 2025. URL https://www.anthropic. com/news/claude-4. 10
work page 2025
-
[4]
Benchmarking foundation models with language-model-as-an- examiner
Yushi Bai, Jiahao Ying, Yixin Cao, Xin Lv, Yuze He, Xiaozhi Wang, Jifan Yu, Kaisheng Zeng, Yijia Xiao, Haozhe Lyu, et al. Benchmarking foundation models with language-model-as-an- examiner. Advances in Neural Information Processing Systems , 36, 2024
work page 2024
-
[5]
Longwriter: Unleashing 10,000+ word generation from long context llms
Yushi Bai, Jiajie Zhang, Xin Lv, Linzhi Zheng, Siqi Zhu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longwriter: Unleashing 10,000+ word generation from long context llms. arXiv preprint arXiv:2408.07055, 2024
-
[6]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952
work page 1952
-
[7]
Google DeepMind. Gemini 2.5 pro, 2025. URL https://storage.googleapis.com/ deepmind-media/gemini/gemini_v2_5_report.pdf
work page 2025
-
[8]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
-
[10]
URL https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv
- [11]
-
[12]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Chatglm-rlhf: Practices of aligning large language models with human feedback
Zhenyu Hou, Yiin Niu, Zhengxiao Du, Xiaohan Zhang, Xiao Liu, Aohan Zeng, Qinkai Zheng, Minlie Huang, Hongning Wang, Jie Tang, et al. Chatglm-rlhf: Practices of aligning large language models with human feedback. arXiv preprint arXiv:2404.00934, 2024
-
[15]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Ishita Kumar, Snigdha Viswanathan, Sushrita Yerra, Alireza Salemi, Ryan A. Rossi, Franck Dernoncourt, Hanieh Deilamsalehy, Xiang Chen, Ruiyi Zhang, Shubham Agarwal, Nedim Lipka, Chien Van Nguyen, Thien Huu Nguyen, and Hamed Zamani. Longlamp: A benchmark for personalized long-form text generation, 2024. URL https://arxiv.org/abs/2407. 11016
work page 2024
-
[17]
Dacheng Li, Shiyi Cao, Tyler Griggs, Shu Liu, Xiangxi Mo, Eric Tang, Sumanth Hegde, Kourosh Hakhamaneshi, Shishir G Patil, Matei Zaharia, et al. Llms can easily learn to reason from demonstrations structure, not content, is what matters! arXiv preprint arXiv:2502.07374, 2025
-
[18]
Preference leakage: A contamination problem in llm-as-a-judge,
Dawei Li, Renliang Sun, Yue Huang, Ming Zhong, Bohan Jiang, Jiawei Han, Xiangliang Zhang, Wei Wang, and Huan Liu. Preference leakage: A contamination problem in llm-as-a-judge,
- [19]
-
[20]
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. arXiv preprint arXiv:2406.11939, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
OpenAI. Openai: Hello gpt-4o, 2024. URL https://openai.com/index/ hello-gpt-4o/
work page 2024
-
[22]
Learning to reason with llms, 2024
OpenAI. Learning to reason with llms, 2024. URL https://openai.com/index/ learning-to-reason-with-llms/ . 12
work page 2024
-
[23]
Introducing gpt-4.1 in the api, April 2025
OpenAI. Introducing gpt-4.1 in the api, April 2025. URL https://openai.com/index/ gpt-4-1/
work page 2025
-
[24]
Suri: Multi-constraint instruction following for long-form text generation
Chau Minh Pham, Simeng Sun, and Mohit Iyyer. Suri: Multi-constraint instruction following for long-form text generation. arXiv preprint arXiv:2406.19371, 2024
-
[25]
Shanghaoran Quan, Tianyi Tang, Bowen Yu, An Yang, Dayiheng Liu, Bofei Gao, Jianhong Tu, Yichang Zhang, Jingren Zhou, and Junyang Lin. Language models can self-lengthen to generate long texts. arXiv preprint arXiv:2410.23933, 2024
-
[26]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems , 36, 2024
work page 2024
-
[27]
Reasoning-enhanced self-training for long-form personalized text generation, 2025
Alireza Salemi, Cheng Li, Mingyang Zhang, Qiaozhu Mei, Weize Kong, Tao Chen, Zhuowan Li, Michael Bendersky, and Hamed Zamani. Reasoning-enhanced self-training for long-form personalized text generation, 2025. URL https://arxiv.org/abs/2501.04167
-
[28]
Agent laboratory: Using llm agents as research assistants,
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants,
-
[29]
URL https://arxiv.org/abs/2501.04227
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. URL https://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/ 2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024. URL https: //qwenlm.github.io/blog/qwen2.5/
work page 2024
-
[34]
Qwq-32b: Embracing the power of reinforcement learning, March 2025
Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, March 2025. URL https://qwenlm.github.io/blog/qwq-32b/
work page 2025
-
[36]
Longwriter-v: Enabling ultra-long and high- fidelity generation in vision-language models, 2025
Shangqing Tu, Yucheng Wang, Daniel Zhang-Li, Yushi Bai, Jifan Yu, Yuhao Wu, Lei Hou, Huiqin Liu, Zhiyuan Liu, Bin Xu, and Juanzi Li. Longwriter-v: Enabling ultra-long and high- fidelity generation in vision-language models, 2025. URL https://arxiv.org/abs/ 2502.14834
-
[37]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems , 35:24824–24837, 2022
work page 2022
-
[38]
Superwriter: Reflection- driven long-form generation with large language models, 2025
Yuhao Wu, Yushi Bai, Zhiqiang Hu, Juanzi Li, and Roy Ka-Wei Lee. Superwriter: Reflection- driven long-form generation with large language models, 2025. URL https://arxiv. org/abs/2506.04180
-
[39]
Shifting long-context llms research from input to output, 2025
Yuhao Wu, Yushi Bai, Zhiqing Hu, Shangqing Tu, Ming Shan Hee, Juanzi Li, and Roy Ka- Wei Lee. Shifting long-context llms research from input to output, 2025. URL https: //arxiv.org/abs/2503.04723. 13
-
[40]
Longgenbench: Bench- marking long-form generation in long context LLMs
Yuhao Wu, Ming Shan Hee, Zhiqiang Hu, and Roy Ka-Wei Lee. Longgenbench: Bench- marking long-form generation in long context LLMs. In The Thirteenth International Con- ference on Learning Representations, 2025. URL https://openreview.net/forum? id=3A71qNKWAS
work page 2025
-
[41]
Writingbench: A comprehensive benchmark for generative writing, 2025
Yuning Wu, Jiahao Mei, Ming Yan, Chenliang Li, Shaopeng Lai, Yuran Ren, Zijia Wang, Ji Zhang, Mengyue Wu, Qin Jin, and Fei Huang. Writingbench: A comprehensive benchmark for generative writing, 2025. URL https://arxiv.org/abs/2503.05244
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Re3: Generating longer stories with recursive reprompting and revision
Kevin Yang, Yuandong Tian, Nanyun Peng, and Dan Klein. Re3: Generating longer stories with recursive reprompting and revision. In Proc. of EMNLP, pages 4393–4479, 2022
work page 2022
-
[44]
DOC: Improving long story coherence with detailed outline control
Kevin Yang, Dan Klein, Nanyun Peng, and Yuandong Tian. DOC: Improving long story coherence with detailed outline control. In Proc. of ACL, pages 3378–3465, 2023
work page 2023
-
[45]
Plan-And-Write: Towards Better Automatic Storytelling
Lili Yao, Nanyun Peng, Ralph Weischedel, Kevin Knight, Dongyan Zhao, and Rui Yan. Plan- and-write: Towards better automatic storytelling, 2019. URL https://arxiv.org/abs/ 1811.05701
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[46]
Demystifying Long Chain-of-Thought Reasoning in LLMs
Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, and Xiang Yue. Demystifying long chain-of-thought reasoning in llms. arXiv preprint arXiv:2502.03373, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?, 2025. URL https://arxiv.org/abs/2504.13837
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
WildChat: 1M ChatGPT Interaction Logs in the Wild
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1m chatgpt interaction logs in the wild. arXiv preprint arXiv:2405.01470, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric. P Xing, Joseph E. Gonzalez, Ion Stoica, and Hao Zhang. Lmsys-chat-1m: A large-scale real-world llm conversation dataset, 2023. 14 A Appendix A.1 Writing-Task Selection and Length-Range Prediction with QwQ-32B We reformulate the pipel...
work page 2023
-
[51]
Decide if it asks for original written content
-
[52]
If Writing, output a reasonable word-count range “[lower, upper]” (ignore ±10%). Response Format • If not writing – respond exactly: NotWriting. • If writing – respond with only the code block {"range": [lower, upper]} Heuristics for Range Estimation
-
[53]
Depth & Complexity: more analysis → higher upper bound
-
[54]
Scope: multiple sub-topics/sections → longer
-
[55]
Requested Form: tweets/notes (0–300); short blog/letter (300–800); school essay (800–1 200); report/article (1200–2500); thesis/proposal/business plan (4000–10000)
-
[56]
Tips for Preparing for College Final Exams
Explicit Length Clues: honour any word/page requirement if stated. Few-Shot Examples Example 1 Query: Write a Weibo post titled “Tips for Preparing for College Final Exams.” Answer: {"range": [0, 300]} Example 2 Query: Translate “Seize the day” into Spanish. Answer: NotWriting Example 3 Query: Draft a comprehensive 10-page business plan for a new cat-litt...
-
[57]
How do I start writing my thesis from scratch
Deeply understand the core requirement of the query (e.g., essay, blog post, summary, outline, thesis section, etc.). For example, the query “How do I start writing my thesis from scratch” asks for guidance on “how to begin writing a thesis,” so you would estimate a word-count range of [400, 800], rather than the total words needed to complete the entire ...
-
[58]
Choose a lower bound that is a multiple of 100, with a minimum of 0
-
[59]
If the reasonable range certainly exceeds these limits, output: {"range": [0, 0]}
Choose an upper bound that is a multiple of 100, with a maximum of 12,000. If the reasonable range certainly exceeds these limits, output: {"range": [0, 0]}
-
[60]
Ignore the 10% of extreme length cases to keep the range reasonable for most scenarios, and ensure the difference between upper and lower bounds does not exceed 3,000
-
[61]
If the query contains an explicit word-count requirement, set the range to ±10% of that number. - For “write a 2,000-word essay,” output: {"range": [1800, 2200]} - For “no more than 2,000 words,” output [1800, 2000]; for “at least 2,000 words,” output [2000, 2200]. 15
work page 2000
-
[62]
If the query cannot be fulfilled under the given conditions—for example, “Read and analyze this paper” without providing the paper, or “Analyze a project’s prospects” without specifying the project details—then output: {"range": [0, 0]} Example: Input “Write a high school essay” → {"range": [800, 1000]} Input “Complete an academic paper on green cities” →...
work page 2025
-
[63]
Relevance and Completeness: Does the assistant fully respond to the writing prompt? Does the length meet the user’s query expectations? Is the content relevant to the topic, and does it provide sufficient depth, length, and detail, rather than drifting off-topic or simplistic?
-
[64]
The overall quality of the writing is high, with elegant
Writing Quality : Evaluate whether the assistant’s writing is clear, fluent, and free of obvious grammatical errors. The overall quality of the writing is high, with elegant
-
[65]
Creativity and Originality: If applicable, assess the creativity of the response. Does the assistant offer fresh perspectives, unique insights, or demonstrate a certain level of originality?
-
[66]
Properly justified repetition is permissible
Specificity and Detail : Determine whether the assistant provides concrete examples or detailed explanations. Properly justified repetition is permissible
-
[67]
Tone and Style : Is the tone appropriate for the writing prompt? Is the writing style consistent throughout? Consider whether it aligns with the expectations of the intended audience or writing purpose. After evaluating each response, determine which one is superior based on the factors above. Provide your explanation and then select one of the following ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.