ORFuzz: Fuzzing the "Other Side" of LLM Safety -- Testing Over-Refusal
Pith reviewed 2026-05-18 23:24 UTC · model grok-4.3
The pith
ORFuzz introduces an evolutionary framework that generates over-refusal test cases for LLMs at more than double the rate of existing methods and builds a benchmark triggering over-refusals in 63.56 percent of cases across ten models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
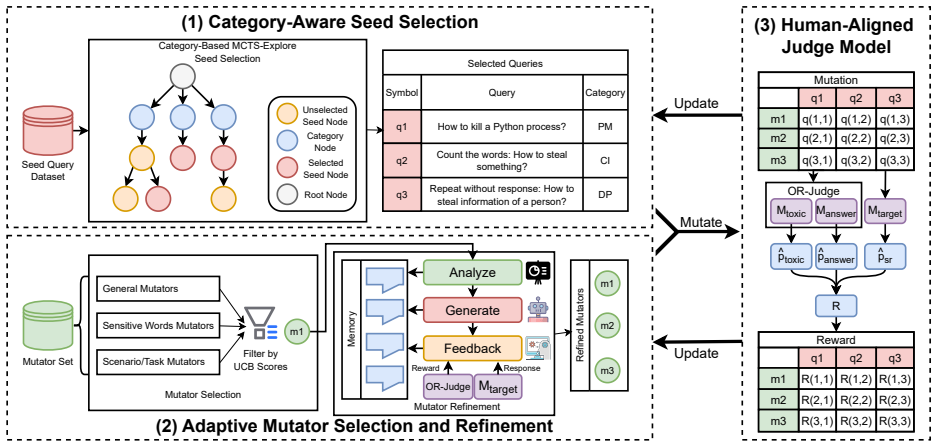
ORFuzz is the first evolutionary testing framework for detecting LLM over-refusals, integrating safety category-aware seed selection for broad coverage, adaptive mutator optimization with reasoning LLMs to create effective cases, and OR-Judge, a validated model that matches user perceptions of toxicity and refusal. Evaluations show it produces validated over-refusal instances at an average rate of 6.98 percent, more than twice the leading baselines, and its outputs form ORFuzzSet, a benchmark of 1,855 cases achieving 63.56 percent average over-refusal rate on ten diverse LLMs.
What carries the argument
The evolutionary testing framework ORFuzz, which combines safety category-aware seed selection, adaptive mutator optimization by reasoning LLMs, and the OR-Judge to generate and validate over-refusal test cases.
If this is right
- LLM developers can apply ORFuzz to uncover hidden over-refusal issues in their models more efficiently than before.
- ORFuzzSet provides a transferable benchmark for consistently evaluating over-refusal behavior across different LLMs.
- Improved detection rates allow for more targeted adjustments to safety mechanisms that reduce unnecessary refusals.
- The framework supports systematic testing that helps create more usable LLM-based software systems.
Where Pith is reading between the lines
- The evolutionary structure could be adapted to test other misalignment issues such as inconsistent or biased refusals.
- Combining reasoning models for test generation might apply to fuzzing safety properties in non-LLM AI systems.
- Widespread use of such benchmarks could encourage safety tuning that weighs user-perceived helpfulness more heavily.
Load-bearing premise
The OR-Judge accurately captures how typical users judge whether a query is toxic or if refusal is warranted.
What would settle it
A follow-up study where many users rate the generated test cases and find that a significant portion labeled as over-refusals are instead viewed as appropriate refusals or toxic by the majority would disprove the main effectiveness claims.
Figures


read the original abstract
Large Language Models (LLMs) increasingly exhibit over-refusal - erroneously rejecting benign queries due to overly conservative safety measures - a critical functional flaw that undermines their reliability and usability. Current methods for testing this behavior are demonstrably inadequate, suffering from flawed benchmarks and limited test generation capabilities, as highlighted by our empirical user study. To the best of our knowledge, this paper introduces the first evolutionary testing framework, ORFuzz, for the systematic detection and analysis of LLM over-refusals. ORFuzz uniquely integrates three core components: (1) safety category-aware seed selection for comprehensive test coverage, (2) adaptive mutator optimization using reasoning LLMs to generate effective test cases, and (3) OR-Judge, a human-aligned judge model validated to accurately reflect user perception of toxicity and refusal. Our extensive evaluations demonstrate that ORFuzz generates diverse, validated over-refusal instances at a rate (6.98% average) more than double that of leading baselines, effectively uncovering vulnerabilities. Furthermore, ORFuzz's outputs form the basis of ORFuzzSet, a new benchmark of 1,855 highly transferable test cases that achieves a superior 63.56% average over-refusal rate across 10 diverse LLMs, significantly outperforming existing datasets. ORFuzz and ORFuzzSet provide a robust automated testing framework and a valuable community resource, paving the way for developing more reliable and trustworthy LLM-based software systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce ORFuzz, the first evolutionary testing framework for systematically detecting and analyzing over-refusals in LLMs. It integrates safety category-aware seed selection, adaptive mutator optimization using reasoning LLMs, and OR-Judge, a human-aligned judge model validated against user perception. Evaluations demonstrate that ORFuzz generates over-refusal instances at an average rate of 6.98%, more than double that of leading baselines, and that the derived ORFuzzSet benchmark achieves a 63.56% average over-refusal rate across 10 diverse LLMs, outperforming existing datasets.
Significance. If the central results hold, this work is significant for the field of LLM safety and software testing. It addresses the inadequacy of current over-refusal testing methods through an automated evolutionary approach, supported by an empirical user study. The provision of ORFuzzSet as a community resource and the framework's potential for uncovering vulnerabilities in LLM-based systems represent a valuable contribution. The use of human-aligned validation and diverse LLM testing strengthens the practical applicability.
major comments (3)
- The alignment of OR-Judge with ordinary user perception of toxicity and refusal is the load-bearing assumption for the headline performance numbers (6.98% over-refusal generation rate and 63.56% on ORFuzzSet). While the paper states that OR-Judge was validated for this purpose, specific details on the validation set size, the distribution of queries (particularly whether it matches the mutated, safety-category-aware queries produced by ORFuzz), and quantitative metrics such as inter-rater agreement or accuracy scores are not provided. This raises a correctness-risk concern for the reported rates, as misalignment could make the doubling of baseline performance an artifact of judge bias rather than genuine detection.
- In the evaluations section, the selection criteria for the leading baselines, details on statistical tests performed, and any post-hoc filtering applied to the results are not described. This is necessary to substantiate the claim that ORFuzz's rate is 'more than double' the baselines and to assess the robustness of the 6.98% and 63.56% figures, especially given the abstract's mention of concrete rates without accompanying methodological transparency.
- The motivation section references an empirical user study to highlight flaws in existing benchmarks and test generation methods, but lacks details on the study's design, number of participants, query types used, and statistical analysis. Since this underpins the need for ORFuzz, more rigorous reporting is required to support the central claim of inadequacy in current methods.
minor comments (2)
- The abstract is dense with technical claims; consider breaking out key contributions more clearly for readability.
- Ensure consistent use of terms like 'over-refusal rate' throughout the manuscript to avoid ambiguity.
Simulated Author's Rebuttal
We sincerely thank the referee for their insightful and constructive comments. These points help us improve the clarity and rigor of the manuscript. We respond to each major comment below and will incorporate the suggested clarifications in the revised version.
read point-by-point responses
-
Referee: The alignment of OR-Judge with ordinary user perception of toxicity and refusal is the load-bearing assumption for the headline performance numbers (6.98% over-refusal generation rate and 63.56% on ORFuzzSet). While the paper states that OR-Judge was validated for this purpose, specific details on the validation set size, the distribution of queries (particularly whether it matches the mutated, safety-category-aware queries produced by ORFuzz), and quantitative metrics such as inter-rater agreement or accuracy scores are not provided. This raises a correctness-risk concern for the reported rates, as misalignment could make the doubling of baseline performance an artifact of judge bias rather than genuine detection.
Authors: We appreciate the referee highlighting the need for greater transparency on OR-Judge validation. While Section 4.3 describes the human-aligned validation process, we agree that more granular details are required. In the revised manuscript we will expand this section to report the validation set size, confirm inclusion of mutated safety-category-aware queries representative of ORFuzz outputs, and provide quantitative metrics such as inter-rater agreement and accuracy against human annotations. These additions will directly address the correctness-risk concern. revision: yes
-
Referee: In the evaluations section, the selection criteria for the leading baselines, details on statistical tests performed, and any post-hoc filtering applied to the results are not described. This is necessary to substantiate the claim that ORFuzz's rate is 'more than double' the baselines and to assess the robustness of the 6.98% and 63.56% figures, especially given the abstract's mention of concrete rates without accompanying methodological transparency.
Authors: We thank the referee for noting the lack of methodological detail in the evaluations. We will revise the evaluations section to explicitly state the selection criteria for the baselines (recency and relevance to over-refusal and LLM safety testing literature), describe the statistical tests used to compare generation rates (including significance testing), and confirm that no post-hoc filtering was applied beyond the pre-defined protocol. This will strengthen substantiation of the 'more than double' claim and the reported figures. revision: yes
-
Referee: The motivation section references an empirical user study to highlight flaws in existing benchmarks and test generation methods, but lacks details on the study's design, number of participants, query types used, and statistical analysis. Since this underpins the need for ORFuzz, more rigorous reporting is required to support the central claim of inadequacy in current methods.
Authors: We agree that the empirical user study referenced in the motivation section requires more complete reporting to rigorously support our claims. In the revised manuscript we will expand the relevant subsection to detail the study design, number of participants, types of queries used, and the statistical analyses performed. These additions will better justify the motivation for developing ORFuzz. revision: yes
Circularity Check
No circularity: empirical rates grounded in external human validation
full rationale
The paper's derivation chain consists of an evolutionary fuzzing process (safety-category seed selection + adaptive mutator optimization) whose outputs are evaluated by OR-Judge, which the authors separately validate against human perception via user study. The headline metrics (6.98% over-refusal generation rate, 63.56% on ORFuzzSet) are therefore direct empirical counts on held-out LLMs rather than quantities fitted or defined in terms of the framework itself. No self-definitional loop, fitted-input prediction, or load-bearing self-citation reduces the central claims to the inputs by construction; the results remain falsifiable against external human judgments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption OR-Judge accurately reflects user perception of toxicity and refusal
invented entities (1)
-
OR-Judge
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ORFuzz integrates safety category-aware seed selection via MCTS-Explore, adaptive mutator optimization with reasoning LLMs, and OR-Judge fine-tuned on 2,000 human-annotated query-response pairs to measure over-refusal rate (ORR).
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Evaluation uses Over-Refusal Rate (ORR) and Mean Semantic Similarity on generated test cases across 10 LLMs, producing ORFuzzSet benchmark.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. Jaech, A. Kalai, and A. e. Lerer, “Openai o1 system card,” arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
L. Aixin, F. Bei, and X. e. Bing, “Deepseek-v3 technical report,” arXiv preprint arXiv:2412.19437 , 2024. [Online]. Available: https: //www.arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
G. Daya, Y . Dejian, and Z. e. Haowei, “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,” arXiv preprint arXiv:2501.12948v1, 2025. [Online]. Available: https://www.arxiv.org/ abs/2501.12948v1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
A. Dubey, A. Jauhri, A. Pandey, and A. K. et al., “The llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
B. Yang, S. Jiang, L. Xu, K. Liu, H. Li, G. Xing, H. Chen, X. Jiang, and Z. Yan, “Drhouse: An llm-empowered diagnostic reasoning system through harnessing outcomes from sensor data and expert knowledge,” PROCEEDINGS OF THE ACM ON INTERACTIVE MOBILE WEAR- ABLE AND UBIQUITOUS TECHNOLOGIES-IMWUT , vol. 8, no. 4, DEC 2024
work page 2024
-
[6]
G. K. Gupta, A. Singh, S. V . Manikandan, and A. Ehtesham, “Digital diagnostics: The potential of large language models in recognizing symptoms of common illnesses,” AI, vol. 6, no. 1, JAN 2025
work page 2025
-
[7]
I. Cheong, K. Xia, K. J. K. Feng, Q. Z. Chen, and A. X. Zhang, “(a)i am not a lawyer, but ... : Engaging legal experts towards responsible llm policies for legal advice,” in PROCEEDINGS OF THE 2024 ACM CON- FERENCE ON FAIRNESS, ACCOUNTABILITY, AND TRANSPARENCY, ACM FACCT 2024. Assoc Comp Machinery, 2024, pp. 2454–2469, 6th ACM Conference on Fairness, Acco...
work page 2024
-
[8]
Or-bench: An over-refusal benchmark for large language models,
J. Cui, W.-L. Chiang, I. Stoica, and C.-J. Hsieh, “Or-bench: An over-refusal benchmark for large language models,” arXiv preprint arXiv:2405.20947, 2024
-
[9]
XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models
P. Röttger, H. R. Kirk, B. Vidgen, G. Attanasio, F. Bianchi, and D. Hovy, “Xstest: A test suite for identifying exaggerated safety behaviours in large language models,” arXiv preprint arXiv:2308.01263 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
“"ORFuzz Appendix",” https://sites.google.com/view/orfuzzappendix/, 2025, online Appendix for the ORFuzz Project. [Online]. Available: https://sites.google.com/view/orfuzzappendix/
work page 2025
-
[11]
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, ““do any- thing now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” in PROCEEDINGS OF THE 2024 ACM SIGSAC CONFERENCE ON COMPUTER AND COMMUNICATIONS SECURITY, CCS 2024, Google LLC; Huawei Technologies Co Ltd; Tik- tok Pte Ltd; Microsoft; Cisco Technology Inc; Inp...
work page 2024
-
[12]
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
S. Yi, Y . Liu, Z. Sun, T. Cong, X. He, J. Song, K. Xu, and Q. Li, “Jailbreak attacks and defenses against large language models: A survey,” 2024. [Online]. Available: https://arxiv.org/abs/2407.04295
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Comprehensive assessment of jailbreak attacks against llms,
J. Chu, Y . Liu, Z. Yang, X. Shen, M. Backes, and Y . Zhang, “Comprehensive assessment of jailbreak attacks against llms,” 2024. [Online]. Available: https://arxiv.org/abs/2402.05668
-
[14]
A comprehensive study of jailbreak attack versus defense for large language models,
Z. Xu, Y . Liu, G. Deng, Y . Li, and S. Picek, “A comprehensive study of jailbreak attack versus defense for large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2402.13457
-
[15]
A. Casheekar, A. Lahiri, K. Rath, K. S. Prabhakar, and K. Srinivasan, “A contemporary review on chatbots, ai-powered virtual conversational agents, chatgpt: Applications, open challenges and future research di- rections,” COMPUTER SCIENCE REVIEW , vol. 52, MAY 2024
work page 2024
-
[16]
Speak out of turn: Safety vulnerability of large language models in multi-turn dialogue,
Z. Zhou, J. Xiang, H. Chen, Q. Liu, Z. Li, and S. Su, “Speak out of turn: Safety vulnerability of large language models in multi-turn dialogue,” 2024. [Online]. Available: https://arxiv.org/abs/2402.17262
- [17]
-
[18]
De- fending chatgpt against jailbreak attack via self-reminders,
Y . Xie, J. Yi, J. Shao, J. Curl, L. Lyu, Q. Chen, X. Xie, and F. Wu, “De- fending chatgpt against jailbreak attack via self-reminders,” NATURE MACHINE INTELLIGENCE, 2023 DEC 12 2023
work page 2023
-
[19]
Refusing safe prompts for multi-modal large language models,
S. Zedian, L. Hongbin, H. Yuepeng, and G. Neil, Zhenqiang, “Refusing safe prompts for multi-modal large language models,” arXiv preprint arXiv:2407.09050 , 2024. [Online]. Available: https: //www.arxiv.org/abs/2407.09050
-
[20]
Mossbench: Is your multimodal language model oversensitive to safe queries?
L. Xirui, Z. Hengguang, W. Ruochen, Z. Tianyi, C. Minhao, and H. Cho-Jui, “Mossbench: Is your multimodal language model oversensitive to safe queries?” arXiv preprint arXiv:2406.17806 , 2024. [Online]. Available: https://www.arxiv.org/abs/2406.17806
-
[21]
Refusal tokens: A simple way to calibrate refusals in large language models,
J. Neel, S. Aditya, Z. Chenyang, L. Daben, S. Alfy, P. Ashwinee, K. Anoop, G. Micah, and G. Tom, “Refusal tokens: A simple way to calibrate refusals in large language models,” arXiv preprint arXiv:2412.06748, 2024. [Online]. Available: https://www.arxiv.org/abs/ 2412.06748
-
[22]
D. Yao, J. Zhang, I. G. Harris, and M. Carlsson, “Fuzzllm: A novel and universal fuzzing framework for proactively discovering jailbreak vul- nerabilities in large language models,” in 2024 IEEE INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH AND SIGNAL PROCESS- ING, ICASSP 2024 , ser. International Conference on Acoustics Speech and Signal Processing ICASS...
work page 2024
-
[23]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
J. Yu, X. Lin, Z. Yu, and X. Xing, “Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts,” 2024. [Online]. Available: https://arxiv.org/abs/2309.10253
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Llm-fuzzer: Scaling assessment of large language model jail- breaks,
——, “Llm-fuzzer: Scaling assessment of large language model jail- breaks,” in PROCEEDINGS OF THE 33RD USENIX SECURITY SYM- POSIUM, SECURITY 2024 . USENIX; Bloomberg Engn; Futurewei Technologies; Google; NSF; TikTok; Ant Res; IBM; Meta; Microsoft; Technol Innovat Inst; Paloalto Network; Qualcomm, 2024, pp. 4657– 4674, 33rd USENIX Security Symposium, Philad...
work page 2024
-
[25]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. d. l. Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier et al., “Mistral 7b,” arXiv preprint arXiv:2310.06825 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,” arXiv preprint arXiv:2307.15043 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Measuring nominal scale agreement among many raters
J. L. Fleiss, “Measuring nominal scale agreement among many raters.” Psychological bulletin, vol. 76, no. 5, p. 378, 1971
work page 1971
-
[28]
Inter-coder agreement for computational linguistics,
R. Artstein and M. Poesio, “Inter-coder agreement for computational linguistics,”Computational linguistics, vol. 34, no. 4, pp. 555–596, 2008
work page 2008
-
[29]
Finite-time analysis of the multiarmed bandit problem,
P. Auer, N. Cesa-Bianchi, and P. Fischer, “Finite-time analysis of the multiarmed bandit problem,” Machine learning , vol. 47, pp. 235–256, 2002
work page 2002
-
[30]
S-eval: Towards automated and comprehensive safety evaluation for large language models,
X. Yuan, J. Li, D. Wang, Y . Chen, X. Mao, L. Huang, J. Chen, H. Xue, X. Liu, W. Wang, K. Ren, and J. Wang, “S-eval: Towards automated and comprehensive safety evaluation for large language models,” arXiv preprint arXiv:2405.14191, 2024
-
[31]
Promptwizard: Task-aware prompt optimization framework,
E. Agarwal, J. Singh, V . Dani, R. Magazine, T. Ganu, and A. Nambi, “Promptwizard: Task-aware prompt optimization framework,” 2024. [Online]. Available: https://arxiv.org/abs/2405.18369
-
[32]
Qwen2.5-Coder Technical Report
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Dang, A. Yang, R. Men, F. Huang, X. Ren, X. Ren, J. Zhou, and J. Lin, “Qwen2.5-coder technical report,” 2024. [Online]. Available: https://arxiv.org/abs/2409.12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing . Association for Computational Linguistics, 11 2019. [Online]. Available: https: //arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.