Learning to Pose Problems: Reasoning-Driven and Solver-Adaptive Data Synthesis
Pith reviewed 2026-05-17 22:57 UTC · model grok-4.3
The pith
A problem generator reasons explicitly about directions then adapts difficulty using solver feedback to synthesize high-value training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing related problem pairs, augmenting them with intermediate problem-design chain-of-thought, and using the solver's feedback as a reward signal, the generator learns to plan directions and calibrate difficulty so that it produces complementary problems near the solver's competence edge, resulting in a cumulative average improvement of 3.4 percent across ten benchmarks and generalization to both language and vision-language models.
What carries the argument
The solver-adaptive problem generator that bootstraps design strategies from augmented chain-of-thought on related problem pairs and treats solver feedback as a reward to adjust difficulty.
If this is right
- Yields a cumulative 3.4 percent average improvement on ten mathematical and general reasoning benchmarks.
- Generalizes across both language models and vision-language models.
- Produces problems that are complementary to those a solver already handles well, rather than indiscriminate variants.
- Bootstraps problem-design strategies from explicit reasoning traces without complex external pipelines.
Where Pith is reading between the lines
- The method could support iterative self-improvement where a model repeatedly generates and solves its own training problems.
- Similar feedback-driven adaptation might apply to synthesizing code problems or scientific questions beyond the tested domains.
- Combining the generator with existing data-augmentation techniques could further increase the efficiency of creating training sets.
Load-bearing premise
The solver's performance on the generated problems provides a reliable, unbiased signal for calibrating future problem difficulty.
What would settle it
An ablation that disables the solver-feedback reward and instead uses random or fixed difficulty targets, then measures whether the 3.4 percent benchmark gains disappear.
Figures







read the original abstract
Data synthesis for training large reasoning models offers a scalable alternative to limited, human-curated datasets, enabling the creation of high-quality data. However, existing approaches face several challenges: (i) indiscriminate generation that ignores the solver's ability and yields low-value problems, or reliance on complex data pipelines to balance problem difficulty; and (ii) a lack of reasoning in problem generation, leading to shallow problem variants. In this paper, we develop a problem generator that reasons explicitly to plan problem directions before synthesis and adapts difficulty to the solver's ability. Specifically, we construct related problem pairs and augment them with intermediate problem-design CoT produced by a reasoning model. These data are used to bootstrap problem-design strategies in the generator. Then, we treat the solver's feedback on synthetic problems as a reward signal, enabling the generator to calibrate difficulty and produce complementary problems near the edge of the solver's competence. Extensive experiments on 10 mathematical and general reasoning benchmarks show that our proposed framework achieves a cumulative average improvement of 3.4%, demonstrating robust generalization across both language and vision-language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a data synthesis framework for training reasoning models. It first constructs related problem pairs augmented with problem-design Chain-of-Thought produced by a reasoning model to bootstrap explicit planning strategies in a generator. It then treats solver feedback on generated problems as a reward signal to calibrate difficulty and synthesize complementary problems near the solver's competence boundary. Experiments across 10 mathematical and general reasoning benchmarks report a cumulative average improvement of 3.4% with generalization to both language and vision-language models.
Significance. If validated, the explicit reasoning step for problem planning combined with solver-adaptive difficulty calibration could improve the quality and relevance of synthetic data over indiscriminate generation or complex balancing pipelines. The approach credits the use of external solver performance as an adaptive signal rather than purely internal fitting, which is a constructive direction for scalable reasoning data synthesis.
major comments (2)
- [§3.3] §3.3 (Difficulty Adaptation): Treating solver feedback (accuracy or error signals) as a reward for calibrating difficulty implicitly assumes this signal is a reliable, low-bias proxy for competence edge. The construction does not address how prompt sensitivity, model-specific failure modes, or sampling stochasticity are mitigated; if unaddressed, the adaptation loop risks reinforcing narrow distributions instead of producing genuinely complementary problems, which would undermine the generalization claim across 10 benchmarks.
- [§5] §5 (Experiments): The reported 3.4% cumulative average improvement lacks any description of the baselines, number of independent runs, statistical significance tests, or data exclusion criteria. Without these controls it is impossible to determine whether the gains are attributable to the reasoning-driven generator and solver-adaptive loop or to uncontrolled factors in the evaluation setup.
minor comments (2)
- [Abstract] The abstract uses 'cumulative average improvement' without clarifying whether this is an unweighted mean, a weighted sum, or aggregated across specific metrics; a precise definition would aid interpretation.
- [§3] Notation for the reward signal derived from solver feedback should be introduced explicitly (e.g., as r(s) or similar) when first defined in the method section to improve readability.
Simulated Author's Rebuttal
We are grateful to the referee for the careful review and the recommendation for major revision. We believe the suggested changes will improve the paper, and we address the comments point-by-point below.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Difficulty Adaptation): Treating solver feedback (accuracy or error signals) as a reward for calibrating difficulty implicitly assumes this signal is a reliable, low-bias proxy for competence edge. The construction does not address how prompt sensitivity, model-specific failure modes, or sampling stochasticity are mitigated; if unaddressed, the adaptation loop risks reinforcing narrow distributions instead of producing genuinely complementary problems, which would undermine the generalization claim across 10 benchmarks.
Authors: We thank the referee for this comment. The current version of the paper does not detail mitigations for prompt sensitivity, model-specific failure modes, or sampling stochasticity in the difficulty adaptation loop. We will revise the manuscript to include a discussion of these issues in §3.3, explaining our approach to using averaged feedback from multiple prompts and generations to reduce bias and stochastic effects. We believe this addition will support the generalization claims. revision: yes
-
Referee: [§5] §5 (Experiments): The reported 3.4% cumulative average improvement lacks any description of the baselines, number of independent runs, statistical significance tests, or data exclusion criteria. Without these controls it is impossible to determine whether the gains are attributable to the reasoning-driven generator and solver-adaptive loop or to uncontrolled factors in the evaluation setup.
Authors: We agree with the referee that the experimental section would benefit from more details on the evaluation protocol. The revised manuscript will expand §5 to describe the baselines compared against, the number of independent runs, the statistical significance tests performed, and any data exclusion criteria used in the experiments. revision: yes
Circularity Check
No significant circularity; derivation grounded in external solver feedback and benchmark evaluation
full rationale
The paper's core construction bootstraps a generator from related problem pairs augmented with external reasoning-model CoT, then calibrates difficulty via solver feedback treated as a reward signal. Neither the claimed 3.4% cumulative improvement nor the adaptation loop reduces by construction to quantities defined solely by the generator's own fitted parameters or self-citations. Evaluation occurs on 10 independent mathematical and general reasoning benchmarks, providing external falsifiability. This satisfies the criteria for a self-contained empirical method with no load-bearing self-definition or fitted-input-as-prediction steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A reasoning model can produce useful intermediate problem-design chain-of-thought from related problem pairs.
- domain assumption Solver feedback on synthetic problems provides a reliable signal for calibrating difficulty near the edge of competence.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Language models that think, chat better
Bhaskar, A., Ye, X., and Chen, D. Language models that think, chat better.arXiv preprint arXiv:2509.20357,
-
[3]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Du, X., Yao, Y ., Ma, K., Wang, B., Zheng, T., Zhu, K., Liu, M., Liang, Y ., Jin, X., Wei, Z., et al. Supergpqa: Scaling llm evaluation across 285 graduate disciplines.arXiv preprint arXiv:2502.14739,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Deepseek- R1 incentivizes reasoning in llms through reinforcement learning.Nature, 2025a
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al. Deepseek- R1 incentivizes reasoning in llms through reinforcement learning.Nature, 2025a. Guo, Y ., Guo, Z., Huang, C., Wang, Z.-A., Zhang, Z., Yu, H., Zhang, H., and Shen, Y . Synthetic data rl: Task definition is all you need.arXiv preprint arXiv:2505.17...
-
[6]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Huang, C., Yu, W., Wang, X., Zhang, H., Li, Z., Li, R., Huang, J., Mi, H., and Yu, D. R-Zero: Self- evolving reasoning LLM from zero data.arXiv preprint arXiv:2508.05004,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision
Jayalath, D., Goel, S., Foster, T., Jain, P., Gururangan, S., Zhang, C., Goyal, A., and Schelten, A. Compute as teacher: Turning inference compute into reference-free supervision.arXiv preprint arXiv:2509.14234,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Kazemi, M., Fatemi, B., Bansal, H., Palowitch, J., Anas- tasiou, C., Mehta, S. V ., Jain, L. K., Aglietti, V ., Jindal, D., Chen, P., et al. Big-bench extra hard.arXiv preprint arXiv:2502.19187,
-
[9]
Skywork-Reward: Bag of Tricks for Reward Modeling in LLMs
Liu, C. Y ., Zeng, L., Liu, J., Yan, R., He, J., Wang, C., Yan, S., Liu, Y ., and Zhou, Y . Skywork-reward: Bag of tricks for reward modeling in llms.arXiv preprint arXiv:2410.18451,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Math- Vista: Evaluating mathematical reasoning of foundation models in visual contexts
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.-W., Galley, M., and Gao, J. Math- Vista: Evaluating mathematical reasoning of foundation models in visual contexts. InICLR, 2024a. 9 Learning to Pose Problems: Reasoning-Driven and Solver-Adaptive Data Synthesis for Large Reasoning Models Lu, Z., Zhou, A., Ren, H., Wang, K....
-
[11]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Meng, F., Du, L., Liu, Z., Zhou, Z., Lu, Q., Fu, D., Han, T., Shi, B., Wang, W., He, J., et al. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2503.07365,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Pei, Q., Pan, Z., Lin, H., Gao, X., Li, Y ., Tang, Z., He, C., Yan, R., and Wu, L. Scalediff: Scaling difficult problems for advanced mathematical reasoning.arXiv preprint arXiv:2509.21070,
-
[13]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Measuring multimodal mathematical reasoning with math-vision dataset
Wang, K., Pan, J., Shi, W., Lu, Z., Ren, H., Zhou, A., Zhan, M., and Li, H. Measuring multimodal mathematical reasoning with math-vision dataset. InNeurIPS, 2024a. Wang, P., Li, Z.-Z., Yin, F., Ran, D., and Liu, C.-L. Mv- math: Evaluating multimodal math reasoning in multi- visual contexts. InCVPR, 2025a. Wang, S., Jiao, Z., Zhang, Z., Peng, Y ., Ze, X., ...
-
[16]
WizardLM: Empowering large pre-trained language models to follow complex instructions
Wu, B., Shi, W., Wang, J., and Ye, M. Synthetic data is an elegant gift for continual vision-language models. In CVPR, 2025a. Wu, T., Lan, J., Yuan, W., Jiao, J., Weston, J. E., and Sukhbaatar, S. Thinking LLMs: General instruction fol- lowing with thought generation. InICML, 2025b. Xu, C., Sun, Q., Zheng, K., Geng, X., Zhao, P., Feng, J., Tao, C., and Ji...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Yu, P., Lanchantin, J., Wang, T., Yuan, W., Golovneva, O., Kulikov, I., Sukhbaatar, S., Weston, J., and Xu, J. Cot- self-instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks.arXiv preprint arXiv:2507.23751, 2025a. Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al. DAPO: A...
-
[19]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Zeng, W., Huang, Y ., Liu, Q., Liu, W., He, K., Ma, Z., and He, J. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild. arXiv preprint arXiv:2503.18892,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InECCV, 2024a
Zhang, R., Jiang, D., Zhang, Y ., Lin, H., Guo, Z., Qiu, P., Zhou, A., Lu, P., Chang, K.-W., Qiao, Y ., et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InECCV, 2024a. Zhang, Y ., Khalifa, M., Logeswaran, L., Kim, J., Lee, M., Lee, H., and Wang, L. Small language models need strong verifiers to self-correct reaso...
-
[21]
Reinforcing general reason- ing without verifiers.arXiv preprint arXiv:2505.21493,
Zhou, X., Liu, Z., Sims, A., Wang, H., Pang, T., Li, C., Wang, L., Lin, M., and Du, C. Reinforcing general reason- ing without verifiers.arXiv preprint arXiv:2505.21493,
-
[22]
TTRL: Test-Time Reinforcement Learning
Zuo, Y ., Zhang, K., Sheng, L., Qu, S., Cui, G., Zhu, X., Li, H., Zhang, Y ., Long, X., Hua, E., et al. Ttrl: Test-time reinforcement learning.arXiv preprint arXiv:2504.16084,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Gradients are clipped at a max norm of 1.0. We use Fully Sharded Data Parallel (FSDP) with full parameter sharding and optional CPU offloading for parameters and optimizer states to balance GPU memory. GRPO experiments are implemented with the EasyR1 codebase (Zheng et al., 2025), and MathRuler (hiyouga,
work page 2025
-
[24]
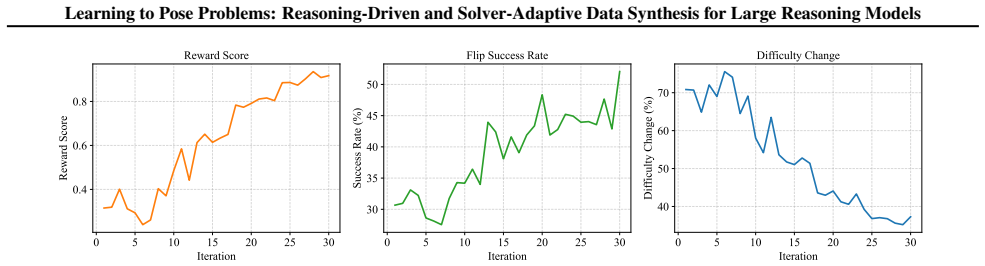
Two additional iterations yield an average solver improvement of 0.7%, confirming effective co-evolution. D. Training Quantity During synthesis, some generated items may be invalid (e.g., missing the <question> tag) or unsolvable, so the number of usable examples can vary across methods. We keep the seed input budget consistent for all methods; therefore,...
- [25]
- [26]
-
[27]
800080.20 92.57 56.41 30.51 40.89 16.51 15.08 47.45 + Solver Feedback (Ours) 800082.2093.03 60.70 32.7244.8917.2115.63 49.48 problems rather than the quantity. E. Consistency Proxy We employ the solver’s accuracy as the reward signal to train the problem generator. Since the ground truth of generated problems is unavailable during rollout, we use the solv...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.