Auditing Data Membership in Reinforcement Learning With Verifiable Rewards
Pith reviewed 2026-05-17 21:33 UTC · model grok-4.3
The pith
RLVR training reshapes model responses on used prompts, leaving detectable behavioral traces that white-box auditing can surface.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
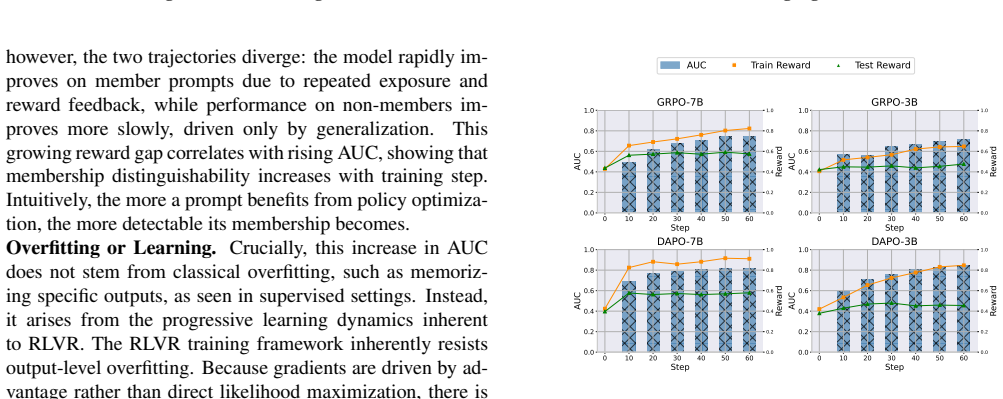
RLVR auditing works because the reinforcement step changes how the model behaves on the exact prompts it was trained on, creating divergence from the base model both in verifiable task success and in the distribution of generated responses. DIBA measures this divergence along reward and policy axes and aggregates over stochastic samples to produce a query-level score that distinguishes training prompts from others.
What carries the argument
Divergence-in-Behavior Auditing (DIBA), which compares the RLVR model to its pre-RLVR checkpoint on reward success and prompt-conditioned response drift, aggregated over multiple rollouts.
If this is right
- Auditing signal is stronger when RLVR produces non-trivial prompt-specific behavioral changes.
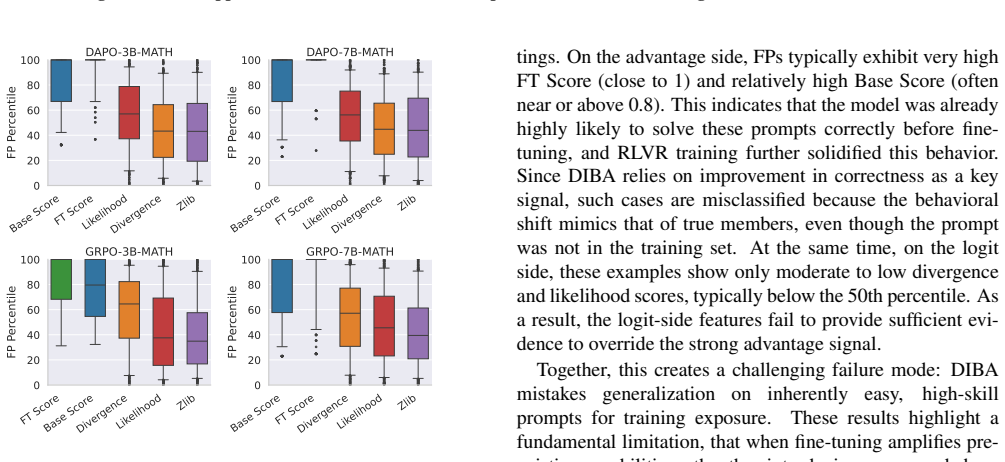
- Auditing signal weakens when the base model already succeeds on the prompt before RLVR.
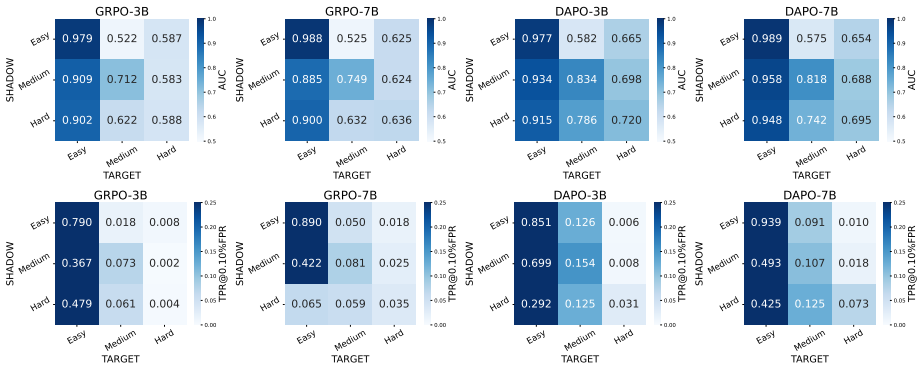
- Transfer performance holds across model sizes under the same RLVR algorithm.
- Transfer varies more across different RLVR algorithms.
- Grey-box transfer can remain useful under distribution shift when shadow data is chosen carefully.
Where Pith is reading between the lines
- Similar divergence techniques might apply to other generative training regimes that lack fixed target strings.
- Defenses could focus on reducing prompt-specific behavioral drift rather than hiding likelihoods.
- Practical deployment would benefit from methods that relax the white-box requirement while preserving signal strength.
Load-bearing premise
The method requires white-box access to both the post-RLVR model and its pre-RLVR checkpoint plus the ability to run multiple stochastic generations and obtain verifiable reward signals.
What would settle it
Running DIBA on a known training prompt yields no higher divergence score than on a matched non-training prompt of similar difficulty.
Figures















read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has become a core training stage in recent large language models (LLMs). Its reliance on non-public, high-value prompt sets raises concerns about unauthorized data use, creating a need for exposure auditing. A natural tool is membership inference attacks (MIAs), but existing methods detect fitting to a fixed target string. This does not apply to RLVR, which generates responses from the model itself and reinforces successful ones, thus hindering the auditing of data exposure. We show that it remains detectable: RLVR reshapes the model's response distribution on training prompts, producing behavioral traces that can be surfaced through targeted auditing. We propose Divergence-in-Behavior Auditing (DIBA), a white-box query-level auditing framework for RLVR. DIBA compares a fine-tuned model against its pre-RLVR checkpoint along two axes: reward-side evidence capturing changes in verifiable task success, and policy-side evidence capturing prompt-conditioned behavioral drift. By aggregating over multiple stochastic rollouts, DIBA produces a stable query-level auditing signal. Under a white-box setting, DIBA consistently outperforms strong transferred likelihood-based baselines, including calibrated and self-generated variants, achieving around 0.8 AUC and an order-of-magnitude stronger TPR@0.1%FPR. We further show that RLVR auditing is stronger when training leaves non-trivial prompt-specific traces and weaker when the base model already performs well on the prompt. Under a practical grey-box setting, transfer is often robust across model sizes under the same RLVR algorithm, but more varied across algorithms, and can remain useful under distribution shift with carefully chosen shadow data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that membership of prompts in RLVR training of LLMs remains detectable despite the lack of fixed target strings. It introduces Divergence-in-Behavior Auditing (DIBA), a white-box method that compares a post-RLVR model against its pre-RLVR checkpoint using reward-side evidence (changes in verifiable task success) and policy-side evidence (prompt-conditioned behavioral drift), aggregated over multiple stochastic rollouts. DIBA is reported to achieve ~0.8 AUC and an order-of-magnitude improvement in TPR@0.1%FPR over transferred likelihood baselines, with stronger signals when the base model does not already perform well on the prompt and some robustness under grey-box transfer.
Significance. If the central results hold under proper controls, this provides a concrete auditing technique for high-value, non-public prompt sets used in RLVR, a now-standard stage in LLM post-training. The work correctly identifies that standard MIAs fail for RLVR and instead exploits observable checkpoint differences plus verifiable rewards. Credit is due for the dual-axis design (reward + policy) and the empirical comparison to calibrated/self-generated baselines; these elements make the contribution more than incremental.
major comments (2)
- The central claim that RLVR produces prompt-specific behavioral traces detectable by DIBA is load-bearing, yet the manuscript provides no controlled contrast between training prompts and semantically or distributionally adjacent non-member prompts under identical auditing conditions (see Abstract and the experimental results). Because policy-gradient updates optimize over a prompt distribution, similar reward gains and policy drift can plausibly appear on near-distribution non-members; without this contrast the aggregated DIBA signal risks conflating membership with general task improvement.
- Abstract: the reported ~0.8 AUC and strong TPR@0.1%FPR are presented without details on prompt selection criteria, number of stochastic rollouts, variance across seeds, or whether reward signals were post-hoc filtered. These omissions make it impossible to assess absence of selection bias and therefore weaken the claim that DIBA 'consistently outperforms' the transferred baselines.
minor comments (2)
- Clarify the exact aggregation function used to combine reward-side and policy-side evidence into the final query-level score; a short pseudocode block or equation would remove ambiguity.
- The grey-box transfer results across model sizes and algorithms would benefit from an explicit table listing the source/target pairs and the resulting AUC drop, rather than qualitative statements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, providing clarifications and indicating where revisions have been made to strengthen the manuscript.
read point-by-point responses
-
Referee: The central claim that RLVR produces prompt-specific behavioral traces detectable by DIBA is load-bearing, yet the manuscript provides no controlled contrast between training prompts and semantically or distributionally adjacent non-member prompts under identical auditing conditions (see Abstract and the experimental results). Because policy-gradient updates optimize over a prompt distribution, similar reward gains and policy drift can plausibly appear on near-distribution non-members; without this contrast the aggregated DIBA signal risks conflating membership with general task improvement.
Authors: We agree that explicitly contrasting training prompts against semantically or distributionally adjacent non-members is important for isolating membership-specific effects from broader task improvements. Our original experiments already included non-member prompts drawn from the same task families and demonstrated that DIBA signals are stronger when the base model performs poorly on a given prompt (indicating prompt-specific traces rather than uniform gains). However, to directly address the concern, we have added a new controlled experiment in the revised manuscript. Using embedding-based similarity, we selected near-neighbor non-member prompts and recomputed DIBA scores under identical conditions. The results show statistically significant separation, with member prompts yielding higher aggregated scores; we include this analysis, associated statistics, and a new figure in Section 4. revision: yes
-
Referee: Abstract: the reported ~0.8 AUC and strong TPR@0.1%FPR are presented without details on prompt selection criteria, number of stochastic rollouts, variance across seeds, or whether reward signals were post-hoc filtered. These omissions make it impossible to assess absence of selection bias and therefore weaken the claim that DIBA 'consistently outperforms' the transferred baselines.
Authors: We acknowledge that the abstract omitted several experimental parameters due to length constraints. In the revised version, we have updated the abstract to note that prompts were drawn from a held-out set of verifiable tasks with no training overlap, that the reported metrics are computed over 10 stochastic rollouts per prompt, and that results reflect averages with low variance across three random seeds (AUC standard deviation of approximately 0.03). No post-hoc filtering of reward signals was performed. These additions should permit better assessment of the setup while preserving the abstract's brevity; complete details, including seed-level breakdowns, remain in the Experiments section. revision: yes
Circularity Check
Derivation self-contained; no load-bearing circular reductions identified
full rationale
The DIBA auditing signal is constructed from direct, observable differences in verifiable reward success and prompt-conditioned policy drift between independently provided pre-RLVR and post-RLVR checkpoints. These quantities are measured via multiple stochastic rollouts on the audited prompts and do not reduce to parameters fitted inside the auditing procedure or to self-citations that define the target result. No self-definitional loops, fitted inputs renamed as predictions, or ansatzes smuggled via prior author work appear in the derivation chain. The central claim therefore retains independent empirical content from the pre/post comparison.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RLVR training leaves detectable prompt-specific traces in response distribution and task success
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DIBA quantifies behavioral divergence along two axes: advantage side (correctness gain) and logit side (policy drift) … sAdv_q = FT Score − Base Score; sKL via k3 estimator
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GRPO objective … advantage term Â_i,t + β KL term
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Towards Differentially Private Reinforcement Learning with General Function Approximation
The work establishes the first DP regret bound of order O(K^{3/5}) for model-free online RL under general function approximation and the first coverability-based regret bound for batched non-private RL.
Reference graph
Works this paper leans on
-
[1]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024. 1, 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tanget al., “Qwen2. 5- vl technical report,”arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Y . Liu, Z. Zhong, Y . Liao, Z. Sun, J. Zheng, J. Wei, Q. Gong, F. Tong, Y . Chen, Y . Zhanget al., “On the generalization and adaptation ability of machine- generated text detectors in academic writing,” inPro- ceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 5674–5685. 1, 2
work page 2025
-
[4]
Qwen2.5-Coder Technical Report
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Luet al., “Qwen2. 5-coder technical report,”arXiv preprint arXiv:2409.12186,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Alt- man, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Training language models to follow in- structions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wain- wright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow in- structions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730– 27 744, 2022. 1, 2
work page 2022
-
[7]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al- Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv e- prints, pp. arXiv–2407, 2024. 1, 12
work page 2024
-
[8]
X. Wen, Z. Liu, S. Zheng, Z. Xu, S. Ye, Z. Wu, X. Liang, Y . Wang, J. Li, Z. Miaoet al., “Reinforce- ment learning with verifiable rewards implicitly incen- tivizes correct reasoning in base llms,”arXiv preprint arXiv:2506.14245, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, W. Dai, T. Fan, G. Liu, L. Liuet al., “Dapo: An open- source llm reinforcement learning system at scale,” arXiv preprint arXiv:2503.14476, 2025. 1, 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
S. S. Srivastava and V . Aggarwal, “A technical survey of reinforcement learning techniques for large language models,”CoRR, vol. abs/2507.04136, 2025. 1
-
[11]
Kimi K2: Open Agentic Intelligence
K. Team, Y . Bai, Y . Bao, G. Chen, J. Chen, N. Chen, R. Chen, Y . Chen, Y . Chen, Y . Chenet al., “Kimi k2: Open agentic intelligence,”arXiv preprint arXiv:2507.20534, 2025. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huanget al., “Qwen2 technical report, 2024,”URL https://arxiv. org/abs/2407.10671, vol. 7, p. 8, 2024. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Recall: Membership in- ference via relative conditional log-likelihoods,
R. Xie, J. Wang, R. Huang, M. Zhang, R. Ge, J. Pei, N. Z. Gong, and B. Dhingra, “Recall: Membership in- ference via relative conditional log-likelihoods,”arXiv preprint arXiv:2406.15968, 2024. 1, 2, 4
-
[14]
Min-k%++: Improved baseline for detecting pre-training data from large language models,
J. Zhang, J. Sun, E. Yeats, Y . Ouyang, M. Kuo, J. Zhang, H. F. Yang, and H. Li, “Min-k%++: Improved baseline for detecting pre-training data from large language models,”arXiv preprint arXiv:2404.02936,
-
[15]
Exposing privacy gaps: Membership inference attack on preference data for llm alignment,
Q. Feng, S. R. Kasa, S. K. Kasa, H. Yun, C. H. Teo, and S. B. Bodapati, “Exposing privacy gaps: Membership inference attack on preference data for llm alignment,” arXiv preprint arXiv:2407.06443, 2024. 1, 3, 4
-
[16]
W. Fu, H. Wang, C. Gao, G. Liu, Y . Li, and T. Jiang, “Practical membership inference attacks against fine- tuned large language models via self-prompt calibra- tion,”arXiv preprint arXiv:2311.06062, 2023. 1, 3, 4, 6
-
[17]
Lora-leak: Membership inference at- tacks against lora fine-tuned language models,
D. Ran, X. He, T. Cong, A. Wang, Q. Li, and X. Wang, “Lora-leak: Membership inference at- tacks against lora fine-tuned language models,”arXiv preprint arXiv:2507.18302, 2025. 1, 3, 4, 6, 16
-
[18]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
T. Chu, Y . Zhai, J. Yang, S. Tong, S. Xie, D. Schu- urmans, Q. V . Le, S. Levine, and Y . Ma, “Sft memorizes, rl generalizes: A comparative study of foundation model post-training,”arXiv preprint arXiv:2501.17161, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighanet al., “Training a helpful and harmless assistant with reinforcement learning from human feed- back,”arXiv preprint arXiv:2204.05862, 2022. 2, 16
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Direct preference optimiza- tion: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimiza- tion: Your language model is secretly a reward model,” Advances in neural information processing systems, vol. 36, pp. 53 728–53 741, 2023. 2, 16
work page 2023
-
[21]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017. 2, 16
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Thought manipulation: External thought can be efficient for large reasoning models,
Y . Liu, J. Zheng, Z. Sun, Z. Peng, W. Dong, Z. Sha, S. Cui, W. Wang, and X. He, “Thought manipulation: External thought can be efficient for large reasoning models,”arXiv preprint arXiv:2504.13626, 2025. 2
-
[23]
Detecting Pretraining Data from Large Language Models
W. Shi, A. Ajith, M. Xia, Y . Huang, D. Liu, T. Blevins, D. Chen, and L. Zettlemoyer, “Detecting pretrain- ing data from large language models,”arXiv preprint arXiv:2310.16789, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Membership in- ference attacks against language models via neighbour- 14 hood comparison,
J. Mattern, F. Mireshghallah, Z. Jin, B. Schölkopf, M. Sachan, and T. Berg-Kirkpatrick, “Membership in- ference attacks against language models via neighbour- 14 hood comparison,”arXiv preprint arXiv:2305.18462,
-
[25]
Extracting training data from large language models,
N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-V oss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingssonet al., “Extracting training data from large language models,” in30th USENIX secu- rity symposium (USENIX Security 21), 2021, pp. 2633–
work page 2021
-
[26]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskeveret al., “Language models are unsupervised multitask learners,”OpenAI blog, vol. 1, no. 8, p. 9,
-
[27]
Pythia: A suite for analyzing large language models across train- ing and scaling,
S. Biderman, H. Schoelkopf, Q. G. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raffet al., “Pythia: A suite for analyzing large language models across train- ing and scaling,” inInternational Conference on Ma- chine Learning. PMLR, 2023, pp. 2397–2430. 3
work page 2023
-
[28]
Y . Dong, X. Jiang, H. Liu, Z. Jin, B. Gu, M. Yang, and G. Li, “Generalization or memorization: Data contam- ination and trustworthy evaluation for large language models,”arXiv preprint arXiv:2402.15938, 2024. 3, 4
-
[29]
Membership inference attacks from first principles,
N. Carlini, S. Chien, M. Nasr, S. Song, A. Terzis, and F. Tramer, “Membership inference attacks from first principles,” in2022 IEEE symposium on security and privacy (SP). IEEE, 2022, pp. 1897–1914. 4, 5, 6, 16
work page 2022
-
[30]
Meta, “Llama-license,” 2025. [Online]. Available: https://github.com/meta-llama/llama-models/blob/ma in/models/llama4/LICENSE 4
work page 2025
-
[31]
Alibaba, “Qwen-license,” 2025. [Online]. Available: https://hf-mirror.com/Qwen/Qwen2.5-Math-7B/blob/ main/LICENSE 4
work page 2025
-
[32]
Measuring Mathematical Problem Solving With the MATH Dataset
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Mea- suring mathematical problem solving with the math dataset,”arXiv preprint arXiv:2103.03874, 2021. 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
J. LI, E. Beeching, L. Tunstall, B. Lipkin, R. Soletskyi, S. C. Huang, K. Rasul, L. Yu, A. Jiang, Z. Shen, Z. Qin, B. Dong, L. Zhou, Y . Fleureau, G. Lample, and S. Polu, “Numinamath,” [https://huggingface.co/AI-MO/Num inaMath-1.5](https://github.com/project-numina/aim o-progress-prize/blob/main/report/numina_dataset.pd f), 2024. 4, 6, 17
work page 2024
-
[34]
Livebench: A challenging, contamination-free LLM benchmark,
C. White, S. Dooley, M. Roberts, A. Pal, B. Feuer, S. Jain, R. Shwartz-Ziv, N. Jain, K. Saifullah, S. Dey, Shubh-Agrawal, S. S. Sandha, S. V . Naidu, C. Hegde, Y . LeCun, T. Goldstein, W. Neiswanger, and M. Gold- blum, “Livebench: A challenging, contamination-free LLM benchmark,” inThe Thirteenth International Conference on Learning Representations, 2025. 4
work page 2025
-
[35]
J. Schulman, “Approximating kl divergence,” 2020. [Online]. Available: http://joschu.net/blog/kl-approx.h tml 5
work page 2020
-
[36]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
G. Cui, Y . Zhang, J. Chen, L. Yuan, Z. Wang, Y . Zuo, H. Li, Y . Fan, H. Chen, W. Chenet al., “The entropy mechanism of reinforcement learning for reasoning language models,”arXiv preprint arXiv:2505.22617,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Spurious Rewards: Rethinking Training Signals in RLVR
R. Shao, S. S. Li, R. Xin, S. Geng, Y . Wang, S. Oh, S. S. Du, N. Lambert, S. Min, R. Krishnaet al., “Spuri- ous rewards: Rethinking training signals in rlvr,”arXiv preprint arXiv:2506.10947, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
HybridFlow: A Flexible and Efficient RLHF Framework
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu, “Hybridflow: A flexi- ble and efficient rlhf framework,”arXiv preprint arXiv: 2409.19256, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Inter-gps: Interpretable geometry prob- lem solving with formal language and symbolic reason- ing,
P. Lu, R. Gong, S. Jiang, L. Qiu, S. Huang, X. Liang, and S.-C. Zhu, “Inter-gps: Interpretable geometry prob- lem solving with formal language and symbolic reason- ing,” inThe Joint Conference of the 59th Annual Meet- ing of the Association for Computational Linguistics and the 11th International Joint Conference on Natu- ral Language Processing (ACL-IJCN...
work page 2021
-
[40]
Differentially private decoding in large language models,
J. Majmudar, C. Dupuy, C. Peris, S. Smaili, R. Gupta, and R. Zemel, “Differentially private decoding in large language models,”arXiv preprint arXiv:2205.13621,
-
[41]
Privacy- preserving mobile edge generation: Analog and digital transmission,
Y . Xue, R. Zhong, J. Li, Y . Chen, and Y . Liu, “Privacy- preserving mobile edge generation: Analog and digital transmission,”IEEE Transactions on Vehicular Tech- nology, pp. 1–6, 2025. 12
work page 2025
-
[42]
J. Ye, C. Huang, Z. Chen, W. Fu, C. Yang, L. Yang, Y . Wu, P. Wang, M. Zhou, X. Yanget al., “A multi- dimensional constraint framework for evaluating and improving instruction following in large language mod- els,”arXiv preprint arXiv:2505.07591, 2025. 13, 20
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Pri- vacy risk in machine learning: Analyzing the connec- tion to overfitting,
S. Yeom, I. Giacomelli, M. Fredrikson, and S. Jha, “Pri- vacy risk in machine learning: Analyzing the connec- tion to overfitting,” in2018 IEEE 31st computer secu- rity foundations symposium (CSF). IEEE, 2018, pp. 268–282. 16
work page 2018
-
[44]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” 2019. [Online]. Available: https://arxiv.org/abs/1907.11692 16
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[45]
C. Dwork, “Differential privacy,” inInternational col- loquium on automata, languages, and programming. Springer, 2006, pp. 1–12. 19, 20
work page 2006
-
[46]
Federated learning with differential privacy: Algorithms and performance analysis,
K. Wei, J. Li, M. Ding, C. Ma, H. H. Yang, F. Farokhi, S. Jin, T. Q. Quek, and H. V . Poor, “Federated learning with differential privacy: Algorithms and performance analysis,”IEEE transactions on information forensics and security, vol. 15, pp. 3454–3469, 2020. 19
work page 2020
-
[47]
Instruction-Following Evaluation for Large Language Models
J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y . Luan, D. Zhou, and L. Hou, “Instruction-following 15 evaluation for large language models,”arXiv preprint arXiv:2311.07911, 2023. 20 A Related work •LOSS [43]:The simplest baseline uses the negative log- likelihood (NLL) under the target model: ScoreLOSS(q) =−logπ θ(q) =− |q| ∑ i=1 logπ θ(qi |q <i). A thr...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.