Recognition: no theorem link
SPHINX: A Synthetic Environment for Visual Perception and Reasoning
Pith reviewed 2026-05-17 04:15 UTC · model grok-4.3
The pith
Sphinx benchmark shows state-of-the-art vision-language models reach only 51.1 percent accuracy on core visual reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
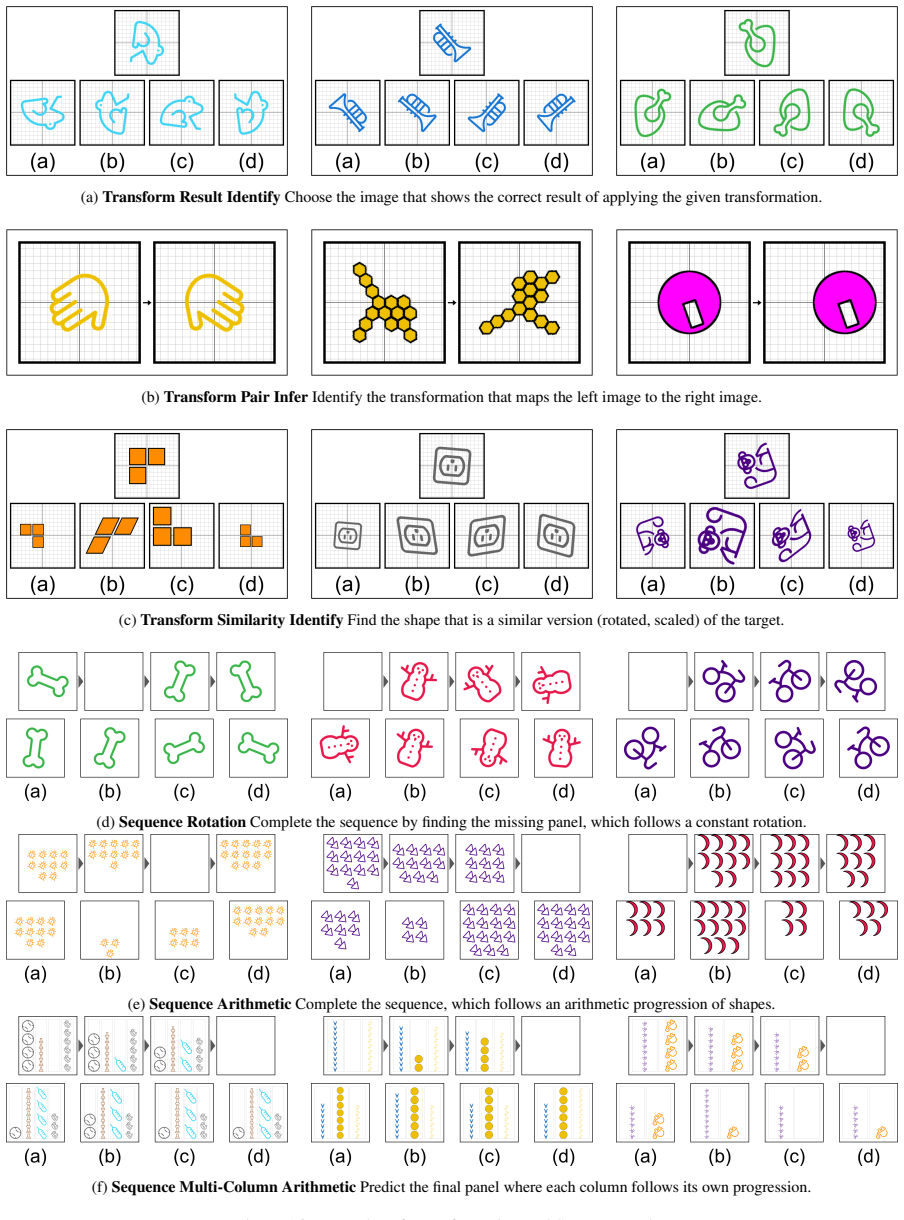
Sphinx procedurally generates puzzles using motifs, tiles, charts, icons, and geometric primitives, each paired with verifiable ground-truth solutions, enabling both precise evaluation and large-scale dataset construction. The benchmark covers 25 task types spanning symmetry detection, geometric transformations, spatial reasoning, chart interpretation, and sequence prediction. Evaluating recent large vision-language models shows that even state-of-the-art GPT-5 attains only 51.1% accuracy, well below human performance. Finally, reinforcement learning with verifiable rewards substantially improves model accuracy on these tasks and yields gains on external visual reasoning benchmarks.
What carries the argument
Procedural generation of puzzles with verifiable ground-truth solutions that supports both direct evaluation of models and reinforcement learning with verifiable rewards.
If this is right
- Reinforcement learning with verifiable rewards can substantially raise accuracy on the synthetic visual reasoning tasks.
- Gains achieved through this training transfer to performance on external visual reasoning benchmarks.
- The environment enables construction of large-scale training datasets with automatic, exact scoring.
- Current large vision-language models have a clear performance gap relative to human levels on these tasks.
- Precise evaluation of core visual perception primitives becomes possible at scale without manual annotation.
Where Pith is reading between the lines
- The same procedural approach could be extended to generate training curricula that progressively increase task difficulty for multimodal models.
- If the observed improvements persist, training pipelines may shift emphasis toward reward signals derived from verifiable answers rather than purely supervised data.
- The benchmark offers a controlled testbed for studying whether gains in synthetic settings reliably predict better performance in unstructured real-world visual scenes.
Load-bearing premise
The 25 procedurally generated task types using motifs, tiles, charts, icons, and geometric primitives accurately capture core cognitive primitives for visual perception and reasoning.
What would settle it
If models trained with reinforcement learning on Sphinx show no accuracy gains on established external visual reasoning benchmarks, this would indicate the synthetic tasks do not measure transferable skills.
Figures
































read the original abstract
We present Sphinx, a synthetic environment for visual perception and reasoning that targets core cognitive primitives. Sphinx procedurally generates puzzles using motifs, tiles, charts, icons, and geometric primitives, each paired with verifiable ground-truth solutions, enabling both precise evaluation and large-scale dataset construction. The benchmark covers 25 task types spanning symmetry detection, geometric transformations, spatial reasoning, chart interpretation, and sequence prediction. Evaluating recent large vision-language models (LVLMs) shows that even state-of-the-art GPT-5 attains only 51.1% accuracy, well below human performance. Finally, we demonstrate that reinforcement learning with verifiable rewards (RLVR) substantially improves model accuracy on these tasks and yields gains on external visual reasoning benchmarks, highlighting its promise for advancing multimodal reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SPHINX, a synthetic environment for visual perception and reasoning. SPHINX procedurally generates puzzles using motifs, tiles, charts, icons, and geometric primitives across 25 task types with verifiable ground-truth solutions. Evaluations show that state-of-the-art LVLMs like GPT-5 achieve only 51.1% accuracy, below human performance. The authors demonstrate that reinforcement learning with verifiable rewards (RLVR) substantially improves accuracy on these tasks and yields gains on external visual reasoning benchmarks.
Significance. This work offers a scalable, controllable benchmark for visual reasoning that addresses limitations in existing datasets by providing procedural generation and exact ground truth. The finding of a significant performance gap in current models and the positive results from RLVR training highlight potential directions for improving multimodal models. The transfer to external benchmarks suggests broader applicability.
minor comments (3)
- The paper would benefit from including a table that summarizes the 25 task types, their descriptions, and example inputs/outputs for clarity.
- Details on the human baseline evaluation, including number of participants and task presentation method, should be expanded in the main text or appendix.
- The RLVR implementation details, such as the specific reward formulation and training hyperparameters, could be more explicitly stated to facilitate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation of minor revision. We appreciate the recognition of SPHINX as a scalable benchmark with procedural generation and exact ground truth, as well as the value of the RLVR results and their transfer to external tasks.
Circularity Check
No significant circularity identified
full rationale
The paper introduces a procedurally generated synthetic benchmark with 25 explicitly enumerated task families using motifs, tiles, charts, icons, and geometric primitives, each with verifiable ground-truth solutions. Central claims rest on direct empirical evaluation (e.g., GPT-5 at 51.1% accuracy) and RLVR training results that transfer to external benchmarks. No equations, parameter fits, or derivations are presented as predictions; task validity is framed as an assumption open to external testing rather than self-referential. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The work is self-contained against reproduction and falsification.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Procedurally generated visual puzzles using motifs, tiles, charts, icons, and geometric primitives can target core cognitive primitives
invented entities (1)
-
SPHINX synthetic environment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Haider Al-Tahan, Quentin Garrido, Randall Balestriero, Diane Bouchacourt, Caner Hazirbas, Mark Ibrahim, et al. Unibench: Visual reasoning requires rethinking vision- language beyond scaling.NeurIPS Datasets and Bench- marks, 2024. 8
work page 2024
-
[2]
Alon Albalak, Duy Phung, Nathan Lile, Rafael Rafailov, Kanishk Gandhi, Louis Castricato, Anikait Singh, Chase Blagden, Violet Xiang, Dakota Mahan, et al. Big- math: A large-scale, high-quality math dataset for re- inforcement learning in language models.arXiv preprint arXiv:2502.17387, 2025. 1
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Nitzan Bitton-Guetta, Aviv Slobodkin, Aviya Maimon, Eliya Habba, Royi Rassin, Yonatan Bitton, Idan Szpektor, Amir Globerson, Yuval Elovici, et al. Visual riddles: A commonsense and world knowledge challenge for large vision and language models.NeurIPS Dataset / arXiv,
-
[5]
Mm-iq: Benchmarking human-like abstraction and reasoning in multimodal models
Huanqia Cai, Yijun Yang, and Winston Hu. Mm-iq: Benchmarking human-like abstraction and reasoning in multimodal models. 2025. 8
work page 2025
-
[6]
Xu Cao, Bolin Lai, Wenqian Ye, Yunsheng Ma, Joerg Heintz, Jintai Chen, Jianguo Cao, and James M Rehg. What is the visual cognition gap between humans and multimodal llms?arXiv preprint arXiv:2406.10424, 2024. 1, 2, 8
-
[7]
Patricia A Carpenter, Marcel A Just, and Peter Shell. What one intelligence test measures: a theoretical account of the processing in the raven progressive matrices test.Psy- chological review, 97(3):404, 1990. 2, 8
work page 1990
-
[8]
Ai models solve maths problems at level of top students.Nature, 644:7, 2025
Davide Castelvecchi. Ai models solve maths problems at level of top students.Nature, 644:7, 2025. 1
work page 2025
-
[9]
Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles
Jiangjie Chen, Qianyu He, Siyu Yuan, Aili Chen, Zhicheng Cai, Weinan Dai, Hongli Yu, Qiying Yu, Xue- feng Li, Jiaze Chen, et al. Enigmata: Scaling logical reasoning in large language models with synthetic verifi- able puzzles.arXiv preprint arXiv:2505.19914, 2025. 2, 8
-
[10]
V-star: Bench- marking video-llms on video spatio-temporal reasoning
Zixu Cheng, Jian Hu, Ziquan Liu, Chenyang Si, Wei Li, and Shaogang Gong. V-star: Benchmarking video- llms on video spatio-temporal reasoning.arXiv preprint arXiv:2503.11495, 2025. 7
-
[11]
Are deep neural net- works smarter than second graders? InProceedings of CVPR (Open Access), 2023
Anoop Cherian, Kuan-Chuan Peng, Suhas Lohit, Kevin A Smith, and Joshua B Tenenbaum. Are deep neural net- works smarter than second graders? InProceedings of CVPR (Open Access), 2023. 1, 8
work page 2023
-
[12]
ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
Francois Chollet, Mike Knoop, Gregory Kamradt, Bryan Landers, and Henry Pinkard. Arc-agi-2: A new chal- lenge for frontier ai reasoning systems.arXiv preprint arXiv:2505.11831, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gem- ini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. In Proceedings of the 32nd ACM international conference on multimedia, pages 11198–11201, 2024. 4, 7
work page 2024
-
[15]
The role of symmetry in infant form discrimination.Child development, pages 457–462, 1981
Celia B Fisher, Kay Ferdinandsen, and Marc H Bornstein. The role of symmetry in infant form discrimination.Child development, pages 457–462, 1981. 2
work page 1981
-
[16]
Blink: Multimodal large lan- guage models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large lan- guage models can see but not perceive. InEuropean Con- ference on Computer Vision, pages 148–166. Springer,
-
[17]
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, and Noah D Goodman. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars.arXiv preprint arXiv:2503.01307,
work page internal anchor Pith review arXiv
-
[18]
Ben Goertzel. Artificial general intelligence: Concept, state of the art, and future prospects.Journal of Artificial General Intelligence, 5(1):1, 2014. 1
work page 2014
-
[19]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reason- ing capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 1, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, et al. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathemat- ical dataset for advancing reasoning.arXiv preprint arXiv:2504.11456, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [21]
-
[22]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed El-Kishky, Aiden Low, Alec Helyar, Alek- sander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Yifan Jiang, Kexuan Sun, Zhivar Sourati, Kian Ahrabian, Kaixin Ma, Filip Ilievski, Jay Pujara, et al. Marvel: Mul- tidimensional abstraction and reasoning through visual evaluation and learning.Advances in Neural Information Processing Systems, 37:46567–46592, 2024. 2, 4, 8
work page 2024
-
[24]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910, 2017. 3
work page 2017
-
[25]
Seungpil Lee, Woochang Sim, Donghyeon Shin, Wongyu Seo, Jiwon Park, Seokki Lee, Sanha Hwang, Sejin Kim, and Sundong Kim. Reasoning abilities of large language models: In-depth analysis on the abstraction and reason- ing corpus. 2024. 2, 8
work page 2024
-
[26]
Modomodo: Multi-domain data mixtures for multimodal llm reinforcement learning
Yiqing Liang, Jielin Qiu, Wenhao Ding, Zuxin Liu, James Tompkin, Mengdi Xu, Mengzhou Xia, Zhengzhong Tu, Laixi Shi, and Jiacheng Zhu. Modomodo: Multi-domain data mixtures for multimodal llm reinforcement learning
-
[27]
Visual-RFT: Visual Reinforcement Fine-Tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual- rft: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025. 1, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter- gps: Interpretable geometry problem solving with for- mal language and symbolic reasoning.arXiv preprint arXiv:2105.04165, 2021. 3
-
[29]
IconQA: A new benchmark for abstract diagram un- derstanding and visual language reasoning
Pan Lu, Liang Qiu, Jiaqi Chen, Tony Xia, Yizhou Zhao, Wei Zhang, Zhou Yu, Xiaodan Liang, and Song-Chun Zhu. IconQA: A new benchmark for abstract diagram un- derstanding and visual language reasoning. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. 8
work page 2021
-
[30]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023. 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Lu Ma, Hao Liang, Meiyi Qiang, Lexiang Tang, Xiaochen Ma, Zhen Hao Wong, Junbo Niu, Chengyu Shen, Run- ming He, Yanhao Li, et al. Learning what reinforcement learning can’t: Interleaved online fine-tuning for hardest questions.arXiv preprint arXiv:2506.07527, 2025. 8
-
[32]
Reasoning limitations of multimodal large language models
Mikołaj Małki´nski, Szymon Pawlonka, and Jacek Ma´ndz- iuk. Reasoning limitations of multimodal large language models. a case study of bongard problems.arXiv preprint arXiv:2411.01173, 2024. 1, 2, 8
-
[33]
A-i-raven and i-raven-mesh: Two new benchmarks for abstract visual reasoning
Mikołaj Małki´nski and Jacek Ma´ndziuk. A-i-raven and i-raven-mesh: Two new benchmarks for abstract visual reasoning. 2025. 8
work page 2025
-
[34]
Mikołaj Małki´nski and Jacek Ma´ndziuk. Deep learning methods for abstract visual reasoning: A survey on raven’s progressive matrices.ACM Computing Surveys, 57(7): 1–36, 2025. 8
work page 2025
-
[35]
Llama 3.2: Revolutionizing edge ai and vision with open, customizable models.Meta AI Blog
AI Meta. Llama 3.2: Revolutionizing edge ai and vision with open, customizable models.Meta AI Blog. Retrieved December, 20:2024, 2024. 4
work page 2024
-
[36]
Weili Nie, Zhiding Yu, Lei Mao, Ankit B Patel, Yuke Zhu, Animashree Anandkumar, et al. Bongard-logo: A new benchmark for human-level concept learning and reasoning.NeurIPS 2020 (Dataset), 2020. 8
work page 2020
-
[37]
OpenAI. Introducing gpt-5. https://openai.com/ index/introducing- gpt- 5/, 2025. Accessed August 2025. 4
work page 2025
-
[38]
Ntsebench: Cog- nitive reasoning benchmark for vision language models
Pranshu Pandya, Vatsal Gupta, Agney S Talwarr, Tushar Kataria, Dan Roth, and Vivek Gupta. Ntsebench: Cog- nitive reasoning benchmark for vision language models
-
[39]
LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL
Yingzhe Peng, Gongrui Zhang, Miaosen Zhang, Zhiyuan You, Jie Liu, Qipeng Zhu, Kai Yang, Xingzhong Xu, Xin Geng, and Xu Yang. Lmm-r1: Empowering 3b lmms with strong reasoning abilities through two-stage rule-based rl. arXiv preprint arXiv:2503.07536, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Zygmunt Pizlo and J Acacio De Barros. The concept of symmetry and the theory of perception.Frontiers in Computational Neuroscience, 15:681162, 2021. 2
work page 2021
-
[41]
Pqa: Perceptual question answering
Yonggang Qi, Kai Zhang, Aneeshan Sain, and Yi-Zhe Song. Pqa: Perceptual question answering. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12056–12064, 2021. 4
work page 2021
-
[42]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sen- tence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084, 2019. 7
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[43]
Tarr, Aviral Kumar, and Katerina Fragki- adaki
Gabriel Sarch, Snigdha Saha, Naitik Khandelwal, Ayush Jain, Michael J. Tarr, Aviral Kumar, and Katerina Fragki- adaki. Grounded reinforcement learning for visual rea- soning. 2025. 8
work page 2025
-
[44]
Visual cognition in multimodal large language models.Nature Machine Intelligence, 7(1):96– 106, 2025
Luca M Schulze Buschoff, Elif Akata, Matthias Bethge, and Eric Schulz. Visual cognition in multimodal large language models.Nature Machine Intelligence, 7(1):96– 106, 2025. 1
work page 2025
-
[45]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junx- iao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Roger N Shepard and Lynn A Cooper.Mental images and their transformations.The MIT Press, 1986. 2
work page 1986
-
[47]
Zafir Stojanovski, Oliver Stanley, Joe Sharratt, Richard Jones, Abdulhakeem Adefioye, Jean Kaddour, Andreas Köpf, et al. Reasoning gym: Reasoning environments for reinforcement learning with verifiable rewards.arXiv preprint arXiv:2505.24760, 2025. 2, 8, 9
-
[48]
Reason-rft: Reinforcement fine-tuning for visual reason- ing
Huajie Tan, Yuheng Ji, Xiaoshuai Hao, Minglan Lin, Pengwei Wang, Zhongyuan Wang, and Shanghang Zhang. Reason-rft: Reinforcement fine-tuning for visual reason- ing. 2025. 8
work page 2025
- [49]
-
[50]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9568–9578, 2024. 7
work page 2024
-
[51]
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl-rethinker: Incen- tivizing self-reflection of vision-language models with reinforcement learning.arXiv preprint, 2025. 8
work page 2025
-
[52]
Measuring multimodal mathe- matical reasoning with math-vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathe- matical reasoning with math-vision dataset. 2024. 3, 7, 8
work page 2024
-
[53]
Zifu Wang, Junyi Zhu, Bo Tang, Zhiyu Li, Feiyu Xiong, Jiaqian Yu, and Matthew B Blaschko. Jigsaw-r1: A study of rule-based visual reinforcement learning with jigsaw puzzles.arXiv preprint arXiv:2505.23590, 2025. 1, 8
-
[54]
Wechsler intelligence scale for children
David Wechsler. Wechsler intelligence scale for children
-
[55]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022. 1
work page 2022
-
[56]
Yanbin Wei, Shuai Fu, Weisen Jiang, James T Kwok, and Yu Zhang. Rendering graphs for graph reasoning in multimodal large language models.arXiv preprint arXiv:2402.02130, 1, 2024. 4
-
[57]
Motor processes in mental rotation.Cognition, 68(1): 77–94, 1998
Mark Wexler, Stephen M Kosslyn, and Alain Berthoz. Motor processes in mental rotation.Cognition, 68(1): 77–94, 1998. 3
work page 1998
-
[58]
On the visual analytic intelligence of neural networks.Nature Communications, 14(1):5978, 2023
Stanisław Wo´ zniak, Hlynur Jónsson, Giovanni Cherubini, Angeliki Pantazi, and Evangelos Eleftheriou. On the visual analytic intelligence of neural networks.Nature Communications, 14(1):5978, 2023. 3
work page 2023
-
[59]
Zhaofeng Wu, Linlu Qiu, Alexis Ross, Ekin Akyürek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob An- dreas, and Yoon Kim. Reasoning or reciting? explor- ing the capabilities and limitations of language models through counterfactual tasks. Association for Computa- tional Linguistics, 2024. 1
work page 2024
-
[60]
LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts
Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Log- icvista: Multimodal llm logical reasoning benchmark in visual contexts.arXiv preprint arXiv:2407.04973, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, and Chong Luo. Logic-rl: Unleashing llm reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2502.14768, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Weiye Xu, Jiahao Wang, Weiyun Wang, Zhe Chen, Wen- gang Zhou, Aijun Yang, Lewei Lu, Houqiang Li, Xiaohua Wang, Xizhou Zhu, et al. Visulogic: A benchmark for evaluating visual reasoning in multi-modal large language models.arXiv preprint arXiv:2504.15279, 2025. 2, 3, 8
-
[63]
Learning to Reason under Off-Policy Guidance
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learn- ing to reason under off-policy guidance.arXiv preprint arXiv:2504.14945, 2025. 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, et al. R1-onevision: Advancing gen- eralized multimodal reasoning through cross-modal for- malization.arXiv preprint arXiv:2503.10615, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Kaining Ying, Fanqing Meng, Jin Wang, Zhiqian Li, Han Lin, Yue Yang, Hao Zhang, Wenbo Zhang, Yuqi Lin, Shuo Liu, et al. Mmt-bench: A comprehensive multimodal benchmark for evaluating large vision-language models towards multitask agi.arXiv preprint arXiv:2404.16006,
-
[67]
Vl-cogito: Progressive curriculum rein- forcement learning for advanced multimodal reasoning
Ruifeng Yuan, Chenghao Xiao, Sicong Leng, Jianyu Wang, Long Li, Tingyang Xu, Zhongyu Wei, Hao Zhang, Yu Rong, et al. Vl-cogito: Progressive curriculum rein- forcement learning for advanced multimodal reasoning. arXiv preprint, 2025. 8
work page 2025
-
[68]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms be- yond the base model?arXiv preprint arXiv:2504.13837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision- language models behave like bags-of-words, and what to do about it?arXiv preprint arXiv:2210.01936, 2022. 1, 3
-
[70]
Aimen Zerroug, Mohit Vaishnav, Julien Colin, Sebastian Musslick, and Thomas Serre. A benchmark for composi- tional visual reasoning.Advances in neural information processing systems, 35:29776–29788, 2022. 3, 8
work page 2022
-
[71]
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? In European Conference on Computer Vision, pages 169–
-
[72]
Springer, 2024. 2, 3, 7
work page 2024
-
[73]
Easyr1: An efficient, scalable, multi-modality rl training framework,
Yaowei Zheng, Junting Lu, Shenzhi Wang, Zhangchi Feng, Dongdong Kuang, and Yuwen Xiong. Easyr1: An efficient, scalable, multi-modality rl training framework,
-
[74]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479, 2025. 4 11 A. Implementation Summary A.1. Overview SPHINXis a framework for programmatically generating ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Geometry varies in radius, sweep angle, thickness, and end-cap style
Arc.Circular arc defined by center, radius, start angle, and sweep; optionally closed into a sector. Geometry varies in radius, sweep angle, thickness, and end-cap style. Appearance includes stroke color/width, op- tional fills, and dashed or solid rendering. Layout covers position, rotation, and multi-arc groupings
-
[76]
Geometry varies via head angle, shaft width/length, curvature, and tail caps
Arrow.Vector-like shape with a shaft and triangular or chevron head, optionally double-headed. Geometry varies via head angle, shaft width/length, curvature, and tail caps. Appearance includes filled or outlined styles, color palettes, and shading suppression. Layout controls orientation, alignment, and crowding
-
[77]
Geometry includes bar count, width/height, spacing, and jitter
Bars.Parallel rectangular bars (horizontal or ver- tical) used for counts or measurements. Geometry includes bar count, width/height, spacing, and jitter. Appearance supports solid or gradient fills and op- tional outlines. Layout covers grouping, stacking, and background grid usage
-
[78]
Geometry includes grid size, cell aspect ratio, bit density, and mask struc- ture
Bitgrid.Binary on/off cell grid. Geometry includes grid size, cell aspect ratio, bit density, and mask struc- ture. Appearance includes on/off colors, padding, rounding, and borders. Layout supports margins, rota- tion, and embedding within scenes
-
[79]
Geometry varies via tick count, numeral style, and hand lengths/angles
Clock.Analog clock with ticks, numerals, and hands. Geometry varies via tick count, numeral style, and hand lengths/angles. Appearance includes face and background styles. Layout supports centering and partial occlusion
-
[80]
Geometry varies in side count, number of layers, spac- ing, and relative rotation
Concentric Polygon.Multiple nested regular poly- gons sharing a center, optionally with rotation offsets. Geometry varies in side count, number of layers, spac- ing, and relative rotation. Appearance includes filled or outlined layers and alternating colors. Layout con- trols scale and juxtaposition
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.