Recognition: no theorem link
MerNav: A Highly Generalizable Memory-Execute-Review Framework for Zero-Shot Object Goal Navigation
Pith reviewed 2026-05-16 07:20 UTC · model grok-4.3
The pith
A Memory-Execute-Review framework raises zero-shot object goal navigation success rates by 5 to 8 percent over baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Memory-Execute-Review framework consists of a hierarchical memory module for providing information support, an execute module for routine decision-making and actions, and a review module for handling abnormal situations and correcting behavior. This structure produces higher success rates and better generalization in object goal navigation under zero-shot conditions than prior training-free and supervised fine-tuning methods across four datasets, including absolute gains of 8 percent on HM3D_v0.1 and 6 percent on HM3D_OVON in zero-shot settings, plus outperformance of both training-free and supervised methods on MP3D and HM3D_OVON.
What carries the argument
The Memory-Execute-Review framework that integrates hierarchical memory for information support, routine execution for actions, and review-based correction of abnormal cases.
If this is right
- Average success rate rises of 7 percent in training-free settings and 5 percent in zero-shot settings across four datasets.
- Specific lifts of 8 percent on HM3D_v0.1 and 6 percent on HM3D_OVON under zero-shot conditions.
- Outperformance of all training-free and all supervised fine-tuning methods on MP3D and HM3D_OVON in both success rate and generalization.
- Successful deployment and testing on a physical humanoid robot in real-world environments.
Where Pith is reading between the lines
- Explicit separation of routine execution from error review may help close the performance-generalization gap in other embodied navigation tasks.
- The framework's structure could extend naturally to visual-language navigation problems that involve longer instructions or larger spaces.
- Real-world robot results point toward uses in household assistance or search scenarios where environments change unpredictably.
- Ablation experiments that isolate each module's contribution would clarify which component accounts for most of the observed gains.
Load-bearing premise
The reported gains rest on the assumption that the hierarchical memory supplies useful information, the execute module handles normal cases, and the review module reliably detects and fixes problems.
What would settle it
Disabling the review module during navigation trials and measuring whether success rates fall back to prior baseline levels on the same datasets would test whether the correction step drives the claimed improvements.
Figures






read the original abstract
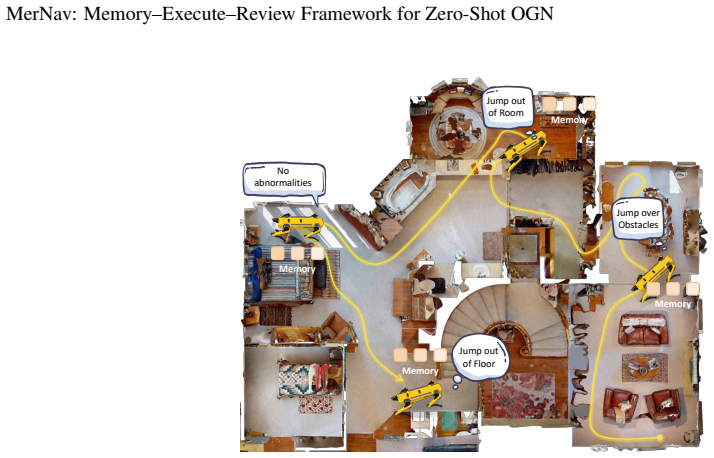
Visual Language Navigation (VLN) is one of the fundamental capabilities for embodied intelligence and a critical challenge that urgently needs to be addressed. However, existing methods are still unsatisfactory in terms of both success rate (SR) and generalization: Supervised Fine-Tuning (SFT) approaches typically achieve higher SR, while Training-Free (TF) approaches often generalize better, but it is difficult to obtain both simultaneously. To this end, we propose a Memory-Execute-Review framework. It consists of three parts: a hierarchical memory module for providing information support, an execute module for routine decision-making and actions, and a review module for handling abnormal situations and correcting behavior. We validated the effectiveness of this framework on the Object Goal Navigation task. Across 4 datasets, our average SR achieved absolute improvements of 7% and 5% compared to all baseline methods under TF and Zero-Shot (ZS) settings, respectively. On the most commonly used HM3D_v0.1 and the more challenging open vocabulary dataset HM3D_OVON, the SR improved by 8% and 6%, under ZS settings. Furthermore, on the MP3D and HM3D_OVON datasets, our method not only outperformed all TF methods but also surpassed all SFT methods, achieving comprehensive leadership in both SR (5% and 2%) and generalization. Additionally, we deployed the MerNav model on the humanoid robot and conducted experiments in the real world. The project address is: https://qidekang.github.io/MerNav.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MerNav, a Memory-Execute-Review framework for zero-shot Object Goal Navigation (OGN) in Visual Language Navigation (VLN). It decomposes navigation into a hierarchical memory module for information support, an execute module for routine decision-making, and a review module for detecting and correcting abnormal situations. The central empirical claim is that this yields average absolute success rate (SR) gains of 7% (TF) and 5% (ZS) over baselines across four datasets, with specific 8% and 6% gains on HM3D_v0.1 and HM3D_OVON under ZS, plus outperformance of both TF and SFT methods on MP3D and HM3D_OVON, supported by real-world humanoid robot deployment.
Significance. If the reported SR gains and generalization hold under the described module interactions, the work is significant for embodied AI: it offers a training-free route that simultaneously exceeds typical TF generalization and SFT performance, addressing a core VLN trade-off. The multi-dataset evaluation (including open-vocabulary HM3D_OVON) and real-robot experiments are concrete strengths that could influence practical navigation systems.
major comments (2)
- [§4.2, Table 2] §4.2, Table 2: the claim of 5% and 2% SR leadership over all SFT methods on MP3D and HM3D_OVON requires explicit listing of the SFT baselines, their training regimes, and whether they were evaluated under identical zero-shot conditions; without this, the cross-paradigm comparison is not fully load-bearing.
- [§3.3] §3.3: the review module's abnormal-situation detection relies on qualitative triggers (e.g., 'stuck' or 'looping'); a precise condition or threshold (e.g., via entropy or trajectory statistics) is needed to substantiate that corrections are reliable rather than introducing new failure modes.
minor comments (3)
- The abstract states improvements 'compared to all baseline methods' but the main text should include a consolidated table enumerating every TF and SFT baseline with exact SR numbers for direct verification.
- [Figure 5] Figure captions for the real-robot experiments should report quantitative SR or path-efficiency metrics rather than relying solely on qualitative success descriptions.
- [§3.1] Notation for the hierarchical memory (e.g., short-term vs. long-term buffers) is introduced without a compact summary equation or diagram legend; adding one would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. The comments highlight opportunities to strengthen the clarity of our empirical claims and the precision of our module descriptions. We address each point below and will incorporate the necessary revisions in the updated manuscript.
read point-by-point responses
-
Referee: [§4.2, Table 2] §4.2, Table 2: the claim of 5% and 2% SR leadership over all SFT methods on MP3D and HM3D_OVON requires explicit listing of the SFT baselines, their training regimes, and whether they were evaluated under identical zero-shot conditions; without this, the cross-paradigm comparison is not fully load-bearing.
Authors: We agree that explicit documentation is required to make the cross-paradigm comparison fully transparent. In the revised §4.2 and an expanded Table 2, we will list every SFT baseline (including their original training datasets, fine-tuning regimes, and model sizes), confirm that all methods—including SFT—are evaluated on identical test splits and episode sets without any additional training or adaptation for our zero-shot protocol, and note that SFT results are taken from their original publications under the same evaluation metrics. This will substantiate the reported 5% and 2% SR gains on MP3D and HM3D_OVON. revision: yes
-
Referee: [§3.3] §3.3: the review module's abnormal-situation detection relies on qualitative triggers (e.g., 'stuck' or 'looping'); a precise condition or threshold (e.g., via entropy or trajectory statistics) is needed to substantiate that corrections are reliable rather than introducing new failure modes.
Authors: We accept the need for quantitative rigor. The review module already employs concrete trajectory-based thresholds: a loop is flagged when the agent revisits a position within 0.5 m for more than 8 consecutive steps, and 'stuck' is declared after 15 steps with displacement below 0.2 m. We will add these exact conditions, along with the entropy-based fallback check on action distributions, to §3.3. New ablation results will be included to demonstrate that these corrections raise SR without increasing failure modes on the four datasets. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces an empirical Memory-Execute-Review framework for zero-shot object goal navigation, supported by performance comparisons on four datasets against TF and SFT baselines. No equations, derivations, fitted parameters, or self-referential definitions appear in the provided text. Claims rest on module descriptions and reported success rates rather than any deductive chain that reduces to its own inputs by construction. The argument is self-contained once the framework components are accepted as described.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Habitat challenge 2021.https://aihabitat.org/challenge/2021/,
AI Habitat. Habitat challenge 2021.https://aihabitat.org/challenge/2021/,
work page 2021
-
[2]
Shazia Akhtar, Lucy V Justice, Lauren Knott, Fraenze Kibowski, and Martin A Conway
Accessed: 2026-01-26. Shazia Akhtar, Lucy V Justice, Lauren Knott, Fraenze Kibowski, and Martin A Conway. The ‘common sense’memory belief system and its implications.The International Journal of Evidence & Proof, 22(3):289–304,
work page 2026
-
[3]
On Evaluation of Embodied Navigation Agents
Peter Anderson, Angel Chang, Devendra Singh Chaplot, Alexey Dosovitskiy, Saurabh Gupta, Vladlen Koltun, Jana Kosecka, Jitendra Malik, Roozbeh Mottaghi, Manolis Savva, et al. On evaluation of embodied navigation agents. arXiv preprint arXiv:1807.06757,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https://arxiv.org/abs/2511.21631. Aron K Barbey, Michael Koenigs, and Jordan Grafman. Dorsolateral prefrontal contributions to human working memory.cortex, 49(5):1195–1205,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Objectnav revisited: On evaluation of embodied agents navigating to objects
Dhruv Batra, Aaron Gokaslan, Aniruddha Kembhavi, Oleksandr Maksymets, Roozbeh Mottaghi, Manolis Savva, Alexander Toshev, and Erik Wijmans. Objectnav revisited: On evaluation of embodied agents navigating to objects. arXiv preprint arXiv:2006.13171,
-
[6]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Openfmnav: Towards open-set zero-shot object navigation via vision-language foundation models
Yuxuan Kuang, Hai Lin, and Meng Jiang. Openfmnav: Towards open-set zero-shot object navigation via vision-language foundation models. InICLR 2024 Workshop on Large Language Model (LLM) Agents,
work page 2024
-
[8]
Peiran Liu, Qiang Zhang, Daojie Peng, Lingfeng Zhang, Yihao Qin, Hang Zhou, Jun Ma, Renjing Xu, and Yiding Ji. Toponav: Topological graphs as a key enabler for advanced object navigation.arXiv preprint arXiv:2509.01364, 2025a. Qingxiang Liu, Ting Huang, Zeyu Zhang, and Hao Tang. Nav-r1: Reasoning and navigation in embodied scenes.arXiv preprint arXiv:2509...
-
[9]
Morgan Stanley Insights (Research)
URL https://www.morganstanley.com/ insights/articles/humanoid-robot-market-5-trillion-by-2050. Morgan Stanley Insights (Research). Dujun Nie, Xianda Guo, Yiqun Duan, Ruijun Zhang, and Long Chen. Wmnav: Integrating vision-language models into world models for object goal navigation.2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (I...
work page 2050
-
[10]
Yaxiong Wu, Sheng Liang, Chen Zhang, Yichao Wang, Yongyue Zhang, Huifeng Guo, Ruiming Tang, and Yong Liu. From human memory to ai memory: A survey on memory mechanisms in the era of llms.arXiv preprint arXiv:2504.15965,
-
[11]
Wentao Xiang, Haokang Zhang, Tianhang Yang, Zedong Chu, Ruihang Chu, Shichao Xie, Yujian Yuan, Jian Sun, Zhining Gu, Junjie Wang, et al. Nav- r2 dual-relation reasoning for generalizable open-vocabulary object-goal navigation.arXiv preprint arXiv:2512.02400,
-
[12]
Habitat challenge 2022.https://aihabitat.org/challenge/2022/,
Karmesh Yadav, Santhosh Kumar Ramakrishnan, John Turner, Aaron Gokaslan, Oleksandr Maksymets, Rishabh Jain, Ram Ramrakhya, Angel X Chang, Alexander Clegg, Manolis Savva, Eric Undersander, Devendra Singh Chaplot, and Dhruv Batra. Habitat challenge 2022.https://aihabitat.org/challenge/2022/,
work page 2022
-
[13]
https: //aihabitat.org/challenge/2023/, 2023a. Karmesh Yadav, Ram Ramrakhya, Arjun Majumdar, Vincent-Pierre Berges, Sachit Kuhar, Dhruv Batra, Alexei Baevski, and Oleksandr Maksymets. Offline visual representation learning for embodied navigation. InWorkshop on Reincarnating Reinforcement Learning at ICLR 2023, 2023b. Karmesh Yadav, Ram Ramrakhya, Santhos...
work page 2023
-
[14]
FiLM-Nav: Efficient and Generalizable Navigation via VLM Fine-tuning
Naoki Yokoyama and Sehoon Ha. Film-nav: Efficient and generalizable navigation via vlm fine-tuning.arXiv preprint arXiv:2509.16445,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Shuang Zeng, Dekang Qi, Xinyuan Chang, Feng Xiong, Shichao Xie, Xiaolong Wu, Shiyi Liang, Mu Xu, and Xing Wei. Janusvln: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation.arXiv preprint arXiv:2509.22548,
-
[16]
Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks. arXiv preprint arXiv:2412.06224, 2024a. Lingfeng Zhang, Hao Wang, Erjia Xiao, Xinyao Zhang, Qiang Zhang, Zixuan Jiang, and Renjing Xu. Multi-...
-
[17]
Imagine before go: Self-supervised generative map for object goal navigation
Sixian Zhang, Xinyao Yu, Xinhang Song, Xiaohan Wang, and Shuqiang Jiang. Imagine before go: Self-supervised generative map for object goal navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16414–16425, 2024b. Linqing Zhong, Chen Gao, Zihan Ding, Yue Liao, Huimin Ma, Shifeng Zhang, Xu Zhou, and Si Liu. T...
-
[18]
6 Appendices 6.1 Reason for the Module Name It’s worth noting that review and reflection differ in emphasis: reflection tends to come from a self-centered perspective, whereas review is more like looking from an “observer” standpoint, or from a higher-level vantage point of your own. There is also a distinction between action and execution: action usually...
work page 2021
-
[19]
was used in the Habitat Challenge 2022 (Yadav et al., 2022). It is designed for Object Goal Navigation and includes 6 object-goal categories: chair, couch, potted plant, bed, toilet, and tv. Its validation set contains 2000 episodes. HM3D_v0.2 (HM3D-Semantics v0.2) (Yadav et al., 2023c) was used in the Habitat Challenge 2023 (Yadav et al., 2023a). Compare...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.