OpenFrontier: General Navigation with Visual-Language Grounded Frontiers
Pith reviewed 2026-05-21 11:31 UTC · model grok-4.3
The pith
Robots reach language goals in new spaces by using visual frontiers as anchors for off-the-shelf vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formulate navigation as a sparse subgoal identification and reaching problem and observe that providing visual anchoring targets for high-level semantic priors enables highly efficient goal-conditioned navigation. Based on this insight, we select visual frontiers as semantic anchors and propose OpenFrontier, a navigation framework that requires no task-specific training or fine-tuning and seamlessly integrates diverse vision-language prior models.
What carries the argument
Visual frontiers as semantic anchors: frontier points chosen from the current view to link high-level language priors directly to visual targets for selecting the next subgoal.
If this is right
- Removes the requirement for dense 3D semantic mapping during operation.
- Delivers strong zero-shot performance on multiple navigation benchmarks.
- Permits direct use of different vision-language models without retraining or fine-tuning.
- Supports immediate real-world deployment on standard mobile robots.
Where Pith is reading between the lines
- The same frontier anchors could be reused for active exploration when no goal is given.
- Adding short-term memory of visited frontiers might extend reliable performance over longer horizons.
- The anchoring idea could transfer to language-directed manipulation by treating graspable objects as frontiers.
- Classical frontier methods from exploration research gain new utility when paired with modern vision-language models.
Load-bearing premise
That visual frontiers supply enough semantic information for vision-language priors to produce efficient subgoal choices in complex everyday environments.
What would settle it
A controlled test in an unseen cluttered indoor space where the frontier-anchored system shows markedly lower success rate or higher path length than a dense-mapping baseline on the same language goals.
Figures







read the original abstract
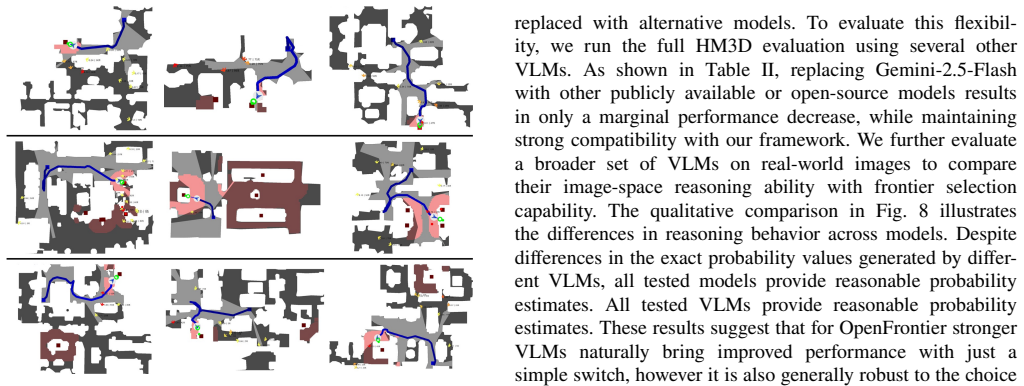
Open-world navigation requires robots to make decisions in complex everyday environments while adapting to flexible task requirements. Conventional navigation approaches often rely on dense 3D reconstruction and hand-crafted goal metrics, which limits their generalization across tasks and environments. Recent advances in vision-language navigation (VLN) and vision-language-action (VLA) models enable end-to-end policies conditioned on natural language, but typically require interactive training, large-scale data collection, or task-specific fine-tuning with a mobile agent. We formulate navigation as a sparse subgoal identification and reaching problem and observe that providing visual anchoring targets for high-level semantic priors enables highly efficient goal-conditioned navigation. Based on this insight, we select visual frontiers as semantic anchors and propose OpenFrontier, a navigation framework that requires no task-specific training or fine-tuning and seamlessly integrates diverse vision-language prior models. OpenFrontier enables efficient navigation with a lightweight system design, without dense 3D semantic mapping, task-specific policy training, or model fine-tuning. We evaluate OpenFrontier across multiple navigation benchmarks and demonstrate strong zero-shot performance, as well as effective real-world deployment on a mobile robot.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OpenFrontier, a navigation framework that formulates the problem as sparse subgoal identification by selecting visual frontiers as semantic anchors for high-level vision-language priors. It claims to enable efficient goal-conditioned navigation in open-world environments without dense 3D semantic mapping, task-specific policy training, or model fine-tuning, while integrating diverse pre-trained VL models and demonstrating strong zero-shot performance on benchmarks plus real-world robot deployment.
Significance. If the central claims hold, the work would offer a meaningful contribution to lightweight, generalizable robot navigation by avoiding the computational and data overhead of dense mapping or end-to-end training. The seamless integration of off-the-shelf VL priors without fine-tuning is a clear practical strength that could support flexible task adaptation across environments.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method, frontier detection subsection): The core claim that the system requires 'no dense 3D semantic mapping' is load-bearing for the lightweight design and efficiency arguments. Standard frontier extraction from depth or point clouds typically builds at least a local 2D/3D occupancy grid or voxel map to delineate free versus unknown space; the manuscript does not explicitly show how OpenFrontier avoids this step or quantify any implicit mapping costs, leaving the 'no dense mapping' advantage unverified.
- [§5] §5 (Experiments): The abstract asserts 'strong zero-shot performance across multiple navigation benchmarks,' yet the provided evaluation details lack quantitative metrics, error breakdowns, or ablation on frontier selection/reaching success rates. This weakens the ability to assess whether visual frontiers as semantic anchors truly suffice for the claimed efficiency in complex environments.
minor comments (1)
- [Abstract and Introduction] The abstract and introduction could more clearly distinguish the proposed visual-frontier approach from prior frontier-based methods that also use semantic cues, to sharpen the novelty claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to improve our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method, frontier detection subsection): The core claim that the system requires 'no dense 3D semantic mapping' is load-bearing for the lightweight design and efficiency arguments. Standard frontier extraction from depth or point clouds typically builds at least a local 2D/3D occupancy grid or voxel map to delineate free versus unknown space; the manuscript does not explicitly show how OpenFrontier avoids this step or quantify any implicit mapping costs, leaving the 'no dense mapping' advantage unverified.
Authors: We clarify that our approach specifically avoids dense 3D semantic mapping by using visual frontiers as anchors for pre-trained vision-language models, rather than building explicit semantic 3D reconstructions. Frontier detection is performed on local depth observations to identify boundaries between free and unknown space, but without semantic labeling or global dense mapping. This enables the lightweight design. We will revise the method section to explicitly describe the frontier detection pipeline, including any local geometric processing, and discuss why this does not constitute dense semantic mapping. Additionally, we will include runtime analysis to quantify any mapping-related computations. revision: yes
-
Referee: [§5] §5 (Experiments): The abstract asserts 'strong zero-shot performance across multiple navigation benchmarks,' yet the provided evaluation details lack quantitative metrics, error breakdowns, or ablation on frontier selection/reaching success rates. This weakens the ability to assess whether visual frontiers as semantic anchors truly suffice for the claimed efficiency in complex environments.
Authors: The experiments section reports success rates and path efficiency on navigation benchmarks as well as real-robot results. To address the concern, we will expand the evaluation with detailed quantitative metrics, including breakdowns of navigation errors, ablations on the impact of visual-language grounding for frontier selection, and specific success rates for the subgoal reaching component. This will better demonstrate the sufficiency of the approach in complex environments. revision: yes
Circularity Check
No circularity: framework relies on external VL priors and design choices without self-referential reductions
full rationale
The paper formulates navigation as sparse subgoal selection using visual frontiers as anchors for pre-trained vision-language models. No equations, fitted parameters, or predictions are presented that reduce by construction to inputs or self-citations. The core claims rest on integration of off-the-shelf VL models and a lightweight system design rather than any internal derivation loop or ansatz smuggled via prior self-work. The absence of dense mapping is stated as an explicit architectural choice, not a derived result that presupposes the outcome. This is a standard engineering paper whose central contribution is empirical validation on benchmarks, not a closed mathematical chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visual frontiers provide sufficient semantic anchoring for high-level vision-language priors to guide navigation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate navigation as a sparse subgoal identification and reaching problem and observe that providing visual anchoring targets for high-level semantic priors enables highly efficient goal-conditioned navigation. ... select visual frontiers as semantic anchors
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
frontiers can be detected and evaluated directly from a single 2D image, without relying on dense 3D mapping
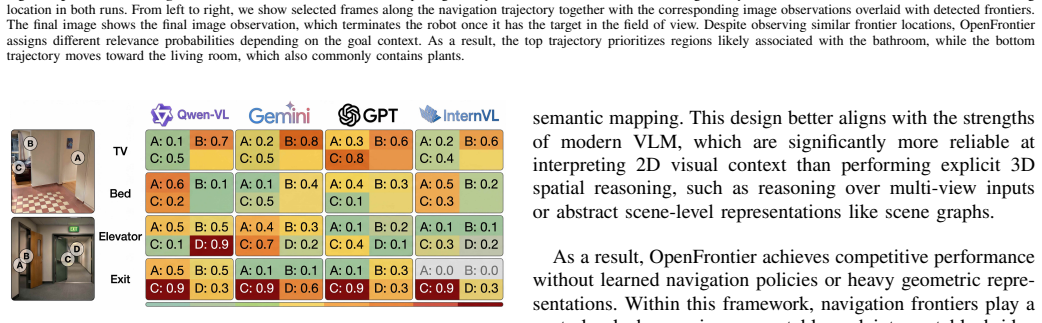
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
TravExplorer: Cross-Floor Embodied Exploration via Traversability-Aware 3-D Planning
TravExplorer couples zero-shot semantic guidance with traversability-aware 3-D planning to enable cross-floor object navigation in unseen indoor environments.
Reference graph
Works this paper leans on
-
[1]
Dhruv Batra, Aaron Gokaslan, Aniruddha Kembhavi, Oleksandr Maksymets, Roozbeh Mottaghi, Manolis Savva, Alexander Toshev, and Erik Wijmans. Objectnav revisited: On evaluation of embodied agents navigating to objects.arXiv preprint arXiv:2006.13171, 2020
-
[2]
Go fetch: Mobile manipulation in unstructured environments.arXiv preprint arXiv:2004.00899, 2020
Kenneth Blomqvist, Michel Breyer, Andrei Cramariuc, Julian Förster, Margarita Grinvald, Florian Tschopp, Jen Jen Chung, Lionel Ott, Juan Nieto, and Roland Siegwart. Go fetch: Mobile manipulation in unstructured environments.arXiv preprint arXiv:2004.00899, 2020
-
[3]
Tare: A hierarchical framework for efficiently exploring complex 3d environments
Chao Cao, Hongbiao Zhu, Howie Choset, and Ji Zhang. Tare: A hierarchical framework for efficiently exploring complex 3d environments. InRobotics: Science and Systems, volume 5, 2021
work page 2021
-
[4]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts. arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Matthew Chang, Théophile Gervet, Mukul Khanna, Sri- ramYenamandra,DhruvShah,SoYeonMin,KavitShah, Chris Paxton, Saurabh Gupta, Dhruv Batra, et al. Goat: Go to any thing. 2024
work page 2024
-
[6]
Object goal navigation using goal-oriented semantic exploration
Devendra Singh Chaplot, Dhiraj Prakashchand Gandhi, Abhinav Gupta, and Russ R Salakhutdinov. Object goal navigation using goal-oriented semantic exploration. Advances in Neural Information Processing Systems, 33: 4247–4258, 2020
work page 2020
-
[7]
Devendra Singh Chaplot, Murtaza Dalal, Saurabh Gupta, Jitendra Malik, and Russ R Salakhutdinov. Seal: Self- supervised embodied active learning using exploration and 3d consistency.Advances in neural information processing systems, 34:13086–13098, 2021
work page 2021
-
[8]
Navila: Legged robot vision-language- action model for navigation
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Xueyan Zou, Jan Kautz, Erdem Biyik, Hongxu Yin, Sifei Liu, and Xiaolong Wang. Navila: Legged robot vision-language- action model for navigation. InRSS, 2025
work page 2025
-
[9]
Fast frontier- based information-driven autonomous exploration with an mav
Anna Dai, Sotiris Papatheodorou, Nils Funk, Dimos Tzoumanikas, and Stefan Leutenegger. Fast frontier- based information-driven autonomous exploration with an mav. InICRA, 2020
work page 2020
-
[10]
Gemma Team et al. Gemma 3 technical report, 2025. URL https://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Zhiyuan Feng, Zhaolu Kang, Qijie Wang, Zhiying Du, Jiongrui Yan, Shubin Shi, Chengbo Yuan, Huizhi Liang, Yu Deng, Qixiu Li, et al. Seeing across views: Bench- marking spatial reasoning of vision-language models in robotic scenes.arXiv preprint arXiv:2510.19400, 2025
-
[12]
Cows on pas- ture: Baselines and benchmarks for language-driven zero- shot object navigation
Samir Yitzhak Gadre, Mitchell Wortsman, Gabriel Il- harco, Ludwig Schmidt, and Shuran Song. Cows on pas- ture: Baselines and benchmarks for language-driven zero- shot object navigation. InProceedings of the IEEE/CVF ConferenceonComputerVisionandPatternRecognition, pages 23171–23181, 2023
work page 2023
-
[13]
Navigating to objects in the real world.Science Robotics, 8(79): eadf6991, 2023
Theophile Gervet, Soumith Chintala, Dhruv Batra, Ji- tendra Malik, and Devendra Singh Chaplot. Navigating to objects in the real world.Science Robotics, 8(79): eadf6991, 2023
work page 2023
-
[14]
Dylan Goetting, Himanshu Gaurav Singh, and Antonio Loquercio. End-to-end navigation with vision language models: Transforming spatial reasoning into question- answering.arXiv preprint arXiv:2411.05755, 2024
-
[15]
History- augmented vision-language models for frontier-based zero-shot object navigation, 2025
Mobin Habibpour and Fatemeh Afghah. History- augmented vision-language models for frontier-based zero-shot object navigation, 2025
work page 2025
-
[16]
Mapex: Indoor structure exploration with probabilistic information gain from global map predictions
Cherie Ho, Seungchan Kim, Brady Moon, Aditya Paran- dekar, Narek Harutyunyan, Chen Wang, Katia Sycara, Graeme Best, and Sebastian Scherer. Mapex: Indoor structure exploration with probabilistic information gain from global map predictions. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13074–13080. IEEE, 2025
work page 2025
-
[17]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monoc- ular geometric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[18]
N. Hughes, Y. Chang, S. Hu, R. Talak, R. Abdulhai, J. Strader, and L. Carlone. Foundations of spatial perception for robotics: Hierarchical representations and real-time systems.The International Journal of Robotics Research,2024. doi:10.1177/02783649241229725. URL https://doi.org/10.1177/02783649241229725
-
[19]
Matan Keidar and Gal A Kaminka. Efficient frontier detectionforrobotexploration.TheInternationalJournal of Robotics Research, 33(2):215–236, 2014
work page 2014
-
[20]
Goat-bench: A benchmark for multi-modal lifelong navigation
Mukul Khanna, Ram Ramrakhya, Gunjan Chhablani, Sriram Yenamandra, Theophile Gervet, Matthew Chang, Zsolt Kira, Devendra Singh Chaplot, Dhruv Batra, and Roozbeh Mottaghi. Goat-bench: A benchmark for multi-modal lifelong navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16373–16383, 2024
work page 2024
-
[21]
Openfmnav: Towards open-set zero-shot object navigation via vision- language foundation models, 2024
Yuxuan Kuang, Hai Lin, and Meng Jiang. Openfmnav: Towards open-set zero-shot object navigation via vision- language foundation models, 2024
work page 2024
-
[22]
Richard Kuhlmann, Jakob Wolfram, Boyang Sun, Jiaxu Xing, Davide Scaramuzza, Marc Pollefeys, and Cesar Cadena. Sight over site: Perception-aware reinforcement learning for efficient robotic inspection.ArXiv, 2025
work page 2025
-
[23]
Instructnav: Zero-shot system for generic instruction navigation in unexplored environ- ment, 2024
Yuxing Long, Wenzhe Cai, Hongcheng Wang, Guanqi Zhan, and Hao Dong. Instructnav: Zero-shot system for generic instruction navigation in unexplored environ- ment, 2024
work page 2024
-
[24]
Andrew Melnik, Gora Chand Nandi, et al. Cognitive planning for object goal navigation using generative ai models.arXiv preprint arXiv:2404.00318, 2024
-
[25]
A Survey on Active Simultaneous Localization and Mapping: State of the Art and New Frontiers
J A Placed, J Strader, H Carrillo, N Atanasov, V In- delman, L Carlone, and J A Castellanos. A Survey on Active Simultaneous Localization and Mapping: State of the Art and New Frontiers. 2023
work page 2023
-
[26]
Ippon: Common sense guided informative path planning for object goal navigation
Kaixian Qu, Jie Tan, Tingnan Zhang, Fei Xia, Cesar Cadena, and Marco Hutter. Ippon: Common sense guided informative path planning for object goal navigation. arXiv preprint arXiv:2410.19697, 2024
-
[27]
Poni: Potential functions for objectgoal navigation with interaction-free learning
Santhosh Kumar Ramakrishnan, Devendra Singh Chap- lot, Ziad Al-Halah, Jitendra Malik, and Kristen Grau- man. Poni: Potential functions for objectgoal navigation with interaction-free learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18890–18900, 2022
work page 2022
-
[28]
Efficient volumetric mapping of multi-scale environments using wavelet-based compression
Victor Reijgwart, Cesar Cadena, Roland Siegwart, and Lionel Ott. Efficient volumetric mapping of multi-scale environments using wavelet-based compression. 2023- 07
work page 2023
-
[29]
Fore- sightnav: Learning scene imagination for efficient ex- ploration
Hardik Shah, Jiaxu Xing, Nico Messikommer, Boyang Sun, Marc Pollefeys, and Davide Scaramuzza. Fore- sightnav: Learning scene imagination for efficient ex- ploration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2025
work page 2025
-
[30]
Rutav Shah, Albert Yu, Yifeng Zhu, Yuke Zhu, and Roberto Martín-Martín. Bumble: Unifying reasoning and acting with vision-language models for building- wide mobile manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13337–13345. IEEE, 2025
work page 2025
-
[31]
Ioan A. Şucan, Mark Moll, and Lydia E. Kavraki. The Open Motion Planning Library.IEEE Robotics & Au- tomation Magazine, 19(4):72–82, December 2012. doi: 10.1109/MRA.2012.2205651. https://ompl.kavrakilab. org
-
[32]
Boyang Sun, Hanzhi Chen, Stefan Leutenegger, Cesar Cadena, Marc Pollefeys, and Hermann Blum. Frontier- net: Learning visual cues to explore.IEEE Robotics and Automation Letters, 10(7):6576–6583, 2025. doi: 10.1109/LRA.2025.3569122
-
[33]
Jingwen Sun, Jing Wu, Ze Ji, and Yu-Kun Lai. A survey of object goal navigation.IEEE Transactions on Automation Science and Engineering, 22:2292–2308,
-
[34]
doi: 10.1109/TASE.2024.3378010
-
[35]
Seer: Safe efficient exploration for aerial robots using learning to predict information gain
Yuezhan Tao, Yuwei Wu, Beiming Li, Fernando Cladera, Alex Zhou, Dinesh Thakur, and Vijay Kumar. Seer: Safe efficient exploration for aerial robots using learning to predict information gain. InICRA, 2023
work page 2023
-
[36]
Hongze Wang, Boyang Sun, Jiaxu Xing, Fan Yang, Marco Hutter, Dhruv Shah, Davide Scaramuzza, and Marc Pollefeys. What matters in rl-based methods for object-goal navigation? an empirical study and a unified framework.arXiv preprint arXiv:2510.01830, 2025
-
[37]
Meng Wei, Chenyang Wan, Xiqian Yu, Tai Wang, Yuqiang Yang, Xiaohan Mao, Chenming Zhu, Wenzhe Cai, Hanqing Wang, Yilun Chen, et al. Streamvln: Streaming vision-and-language navigation via slowfast context modeling.arXiv preprint arXiv:2507.05240, 2025
-
[38]
Dd-ppo: Learning near-perfect pointgoal naviga- tors from 2.5 billion frames
Erik Wijmans, Abhishek Kadian, Ari Morcos, Stefan Lee, Irfan Essa, Devi Parikh, Manolis Savva, and Dhruv Batra. Dd-ppo: Learning near-perfect pointgoal naviga- tors from 2.5 billion frames. InInternational Confer- ence on Learning Representations, 2020. URL https: //openreview.net/forum?id=H1gX8C4YPr
work page 2020
-
[39]
Naviformer: A spatio-temporal context-aware transformer for object navigation
Wei Xie, Haobo Jiang, Yun Zhu, Jianjun Qian, and Jin Xie. Naviformer: A spatio-temporal context-aware transformer for object navigation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 14708–14716, 2025
work page 2025
-
[40]
Zhefan Xu, Xinming Han, Haoyu Shen, Hanyu Jin, and Kenji Shimada. Navrl: Learning safe flight in dynamic environments.IEEE Robotics and Automation Letters, 10 (4):3668–3675, 2025. doi: 10.1109/LRA.2025.3546069
-
[41]
Omninav: A unified framework for prospective exploration and visual-language navigation
Xinda Xue, Junjun Hu, Minghua Luo, Xie Shichao, Jin- tao Chen, Zixun Xie, Quan Kuichen, Guo Wei, Mu Xu, and Zedong Chu. Omninav: A unified framework for prospective exploration and visual-language navigation. arXiv preprint arXiv:2509.25687, 2025
-
[42]
Karmesh Yadav, Santhosh Kumar Ramakrishnan, John Turner, Aaron Gokaslan, Oleksandr Maksymets, Rishabh Jain, Ram Ramrakhya, Angel X Chang, Alexander Clegg, Manolis Savva, Eric Undersander, Devendra Singh Chap- lot, and Dhruv Batra. abitat challenge 2022. https: //aihabitat.org/challenge/2022/, 2022
work page 2022
-
[43]
Karmesh Yadav, Jacob Krantz, Ram Ramrakhya, San- thosh Kumar Ramakrishnan, Jimmy Yang, Austin Wang, John Turner, Aaron Gokaslan, Vincent-Pierre Berges, Roozbeh Mootaghi, Oleksandr Maksymets, An- gel X Chang, Manolis Savva, Alexander Clegg, Deven- dra Singh Chaplot, and Dhruv Batra. Habitat challenge
-
[44]
https://aihabitat.org/challenge/2023/, 2023
work page 2023
-
[45]
A frontier-based approach for au- tonomous exploration
Brian Yamauchi. A frontier-based approach for au- tonomous exploration. InProceedings 1997 IEEE In- ternational Symposium on Computational Intelligence in Robotics and Automation CIRA’97.’Towards New Computational Principles for Robotics and Automation’, pages 146–151. IEEE, 1997
work page 1997
-
[46]
iPlanner: Imperative Path Planning
Fan Yang, Chen Wang, Cesar Cadena, and Marco Hutter. iPlanner: Imperative Path Planning. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi: 10.15607/RSS.2023.XIX.064
-
[47]
Fan Yang, Per Frivik, David Hoeller, Chen Wang, Cesar Cadena, and Marco Hutter. Spatially-enhanced recurrent memory for long-range mapless navigation via end-to- end reinforcement learning.The International Journal of Robotics Research, page 02783649251401926, 2025
work page 2025
-
[48]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chun- yuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Unigoal: Towards universal zero- shot goal-oriented navigation
Hang Yin, Xiuwei Xu, Linqing Zhao, Ziwei Wang, Jie Zhou, and Jiwen Lu. Unigoal: Towards universal zero- shot goal-oriented navigation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19057–19066, 2025
work page 2025
-
[50]
Vlfm: Vision-language frontier maps for zero-shot semantic navigation
Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. Vlfm: Vision-language frontier maps for zero-shot semantic navigation. In International Conference on Robotics and Automation (ICRA), 2024
work page 2024
-
[51]
Hm3d-ovon: A dataset and benchmark for open-vocabulary object goal navigation, 2024
Naoki Yokoyama, Ram Ramrakhya, Abhishek Das, Dhruv Batra, and Sehoon Ha. Hm3d-ovon: A dataset and benchmark for open-vocabulary object goal navigation, 2024
work page 2024
-
[52]
Frontier semantic exploration for visual target navigation.arXiv preprint arXiv:2304.05506, 2023
Bangguo Yu, Hamidreza Kasaei, and Ming Cao. Frontier semantic exploration for visual target navigation.arXiv preprint arXiv:2304.05506, 2023
-
[53]
Poliformer: Scal- ing on-policy rl with transformers results in masterful navigators
Kuo-Hao Zeng, Zichen Zhang, Kiana Ehsani, Rose Hen- drix, Jordi Salvador, Alvaro Herrasti, Ross Girshick, Aniruddha Kembhavi, and Luca Weihs. Poliformer: Scal- ing on-policy rl with transformers results in masterful navigators. InConferenceon RobotLearning, pages408–
-
[54]
3d-aware object goal navigation via simultaneous exploration and identi- fication
Jiazhao Zhang, Liu Dai, Fanpeng Meng, Qingnan Fan, Xuelin Chen, Kai Xu, and He Wang. 3d-aware object goal navigation via simultaneous exploration and identi- fication. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6672– 6682, 2023
work page 2023
-
[55]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision- language-action model for unifying embodied navigation tasks.arXiv preprint arXiv:2412.06224, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and He Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation.Robotics: Sci- ence and Systems, 2024
work page 2024
-
[57]
Vision-and-language navigation today and tomorrow: A survey in the era of foundation models
Yue Zhang, Ziqiao Ma, Jialu Li, Yanyuan Qiao, Zun Wang, Joyce Chai, Qi Wu, Mohit Bansal, and Parisa Kordjamshidi. Vision-and-language navigation today and tomorrow: A survey in the era of foundation models. arXiv preprint arXiv:2407.07035, 2024
-
[58]
Boyu Zhou, Yichen Zhang, Xinyi Chen, and Shaojie Shen. Fuel: Fast uav exploration using incremental fron- tier structure and hierarchical planning.IEEE Robotics and Automation Letters, 6(2):779–786, 2021
work page 2021
-
[59]
Beliefmapnav: 3d voxel-based belief map for zero-shot object navigation, 2025
Zibo Zhou, Yue Hu, Lingkai Zhang, Zonglin Li, and Siheng Chen. Beliefmapnav: 3d voxel-based belief map for zero-shot object navigation, 2025
work page 2025
-
[60]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su,JieShao,etal. Internvl3:Exploringadvancedtraining and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479, 2025. APPENDIX A. Configuration Settings and Key Parameters For simulation evaluation and benchmarking, we use ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Frontier Probability Estimation (Set-of-Marks): Assume the labeled frontiers {labels} represent possible places to go. Each frontier is a detected boundary between explored and unexplored space. Estimate the probability that each frontier leads to (or is already around) a{target_object}when moving towards it and continuing exploration. Unseen labels shoul...
-
[62]
Target Presence Verification: Based on this image, estimate the probability that a{target_object} is in the camera field of view, within five meters, and reachable. If the object is reflected in a mirror, behind glass, barely visible, heavily occluded, or unreachable, it should be considered absent. Probabilities should be close to 0 (absent) or 1 (presen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.