Recognition: no theorem link
Security Threat Modeling for Emerging AI-Agent Protocols: A Comparative Analysis of MCP, A2A, Agora, and ANP
Pith reviewed 2026-05-16 05:02 UTC · model grok-4.3
The pith
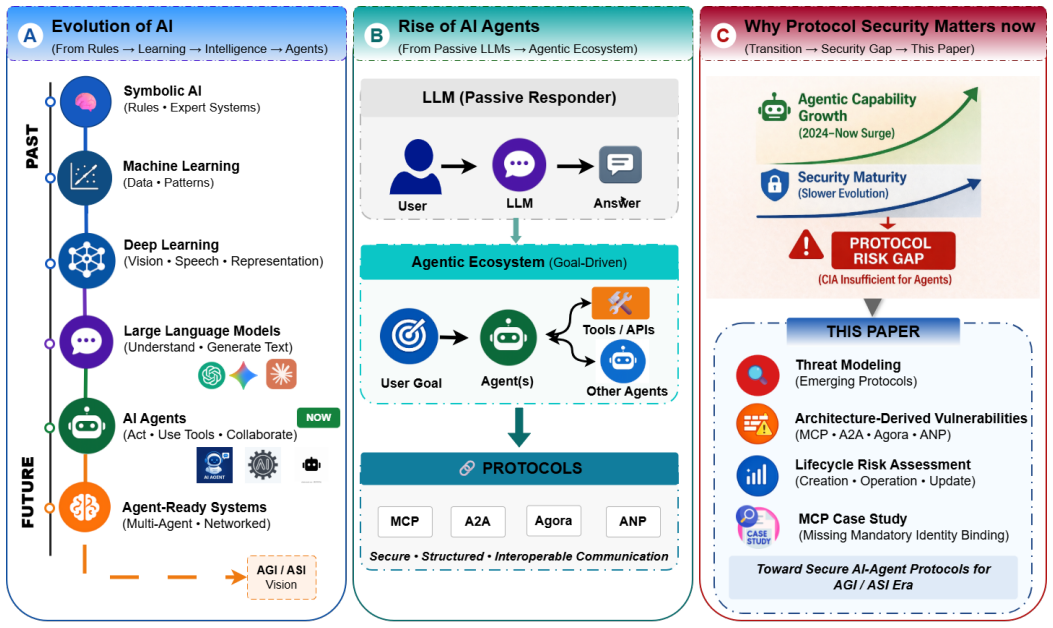
Four AI agent protocols share twelve design-linked risks that a new assessment framework scores across creation, operation, and update phases, with MCP measurements showing wrong-provider tool executions when validation is absent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the four protocols exhibit overlapping risk surfaces arising from their trust models and interaction patterns; these surfaces are captured by twelve risks whose likelihood, impact, and phase-specific scores can be evaluated systematically, and that MCP specifically allows measurable wrong-provider tool execution when mandatory validation or attestation of executable components is omitted under representative multi-server resolver policies.
What carries the argument
The qualitative risk assessment framework that defines twelve protocol-level risks and computes likelihood, impact, and overall risk scores for the creation, operation, and update phases of each protocol.
If this is right
- Protocol designers must add mandatory validation or attestation steps for executable components to reduce wrong-provider tool execution in MCP deployments.
- Security posture scores from the framework can be used to prioritize fixes in the operation phase over creation or update phases for all four protocols.
- Standardization bodies should require the threat-modeling steps described here when evaluating new agent communication protocols.
- Cross-protocol interoperability decisions should weigh the shared risk surfaces identified in the comparative analysis rather than treating each protocol in isolation.
- Deployers can map the twelve risks to their own resolver policies to decide which protocol offers the lowest overall risk for a given use case.
Where Pith is reading between the lines
- The measurement approach used for MCP could be applied directly to A2A, Agora, and ANP to produce comparable empirical numbers instead of relying only on qualitative scores.
- If the framework is adopted, agent platforms would likely need new runtime checks that enforce the validation steps the paper identifies as missing.
- The risk surfaces around trust assumptions may connect to broader questions of agent identity and delegation that appear in multi-agent coordination beyond pure communication protocols.
- Organizations could test whether adding attestation layers changes the observed wrong-provider rates in live MCP deployments and feed those results back into updated risk scores.
Load-bearing premise
The twelve risks comprehensively cover the main threat surfaces and the qualitative likelihood and impact scores accurately represent real deployment conditions without further empirical validation for every protocol.
What would settle it
An experiment that runs MCP in a multi-server setup, counts the actual rate of wrong-provider tool executions under the paper's representative resolver policies both with and without mandatory component validation, and checks whether the observed rates match the paper's quantified claims.
Figures




read the original abstract
The rapid development of the AI agent communication protocols, including the Model Context Protocol (MCP), Agent2Agent (A2A), Agora, and Agent Network Protocol (ANP), is reshaping how AI agents communicate with tools, services, and each other. While these protocols support scalable multi-agent interaction and cross-organizational interoperability, their security principles remain understudied, and standardized threat modeling is limited; no protocol-centric risk assessment framework has been established yet. This paper presents a systematic security analysis of four emerging AI agent communication protocols. First, we develop a structured threat modeling analysis that examines protocol architectures, trust assumptions, interaction patterns, and lifecycle behaviors to identify protocol-specific and cross-protocol risk surfaces. Second, we introduce a qualitative risk assessment framework that identifies twelve protocol-level risks and evaluates security posture across the creation, operation, and update phases through systematic assessment of likelihood, impact, and overall protocol risk, with implications for secure deployment and future standardization. Third, we provide a measurement-driven case study on MCP that formalizes the risk of missing mandatory validation/attestation for executable components as a falsifiable security claim by quantifying wrong-provider tool execution under multi-server composition across representative resolver policies. Collectively, our results highlight key design-induced risk surfaces and provide actionable guidance for secure deployment and future standardization of agent communication ecosystems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to deliver a systematic security analysis of four emerging AI-agent communication protocols (MCP, A2A, Agora, ANP) by (1) applying structured threat modeling to protocol architectures, trust assumptions, interaction patterns, and lifecycles, (2) introducing a qualitative risk-assessment framework that identifies twelve protocol-level risks and scores them by likelihood and impact across creation, operation, and update phases, and (3) presenting a measurement-driven MCP case study that quantifies wrong-provider tool execution under multi-server composition to formalize the risk of missing mandatory validation/attestation as a falsifiable security claim.
Significance. If the central claims hold, the work is significant because it supplies the first protocol-centric threat-modeling framework for AI-agent communication ecosystems and supplies one concrete, quantified example that could serve as a template for future empirical security evaluations. The emphasis on design-induced risk surfaces and actionable standardization guidance is timely given the rapid adoption of these protocols.
major comments (2)
- [MCP case study] MCP case-study section: the quantification of wrong-provider tool execution is presented as a falsifiable claim, yet the manuscript does not specify the exact resolver-policy logic, composition rules, or threat-model parameters (e.g., what constitutes a 'wrong-provider' trigger or how multi-server resolution is modeled). Without these details the reported rates cannot be reproduced or independently falsified, undermining the load-bearing security claim.
- [Threat modeling and risk framework] Risk-identification section: the derivation of the twelve risks is described as systematic, but the paper provides no explicit mapping from the examined architectural features to each risk, nor any justification that the set is exhaustive. This leaves the completeness of the framework open to question and weakens the cross-protocol comparisons.
minor comments (2)
- [Abstract] Abstract: the twelve risks are referenced but never enumerated or briefly characterized, making it difficult for readers to grasp the scope of the contribution at first reading.
- [Risk assessment framework] Notation: the paper uses 'overall protocol risk' without defining the aggregation rule (e.g., max, weighted sum) applied to likelihood and impact scores.
Simulated Author's Rebuttal
Thank you for the constructive comments. We respond to each major comment below and will revise the manuscript accordingly to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [MCP case study] MCP case-study section: the quantification of wrong-provider tool execution is presented as a falsifiable claim, yet the manuscript does not specify the exact resolver-policy logic, composition rules, or threat-model parameters (e.g., what constitutes a 'wrong-provider' trigger or how multi-server resolution is modeled). Without these details the reported rates cannot be reproduced or independently falsified, undermining the load-bearing security claim.
Authors: We thank the referee for pointing this out. Upon review, we agree that additional details are needed for full reproducibility of the MCP case study. In the revised manuscript, we will expand the case study section to include explicit descriptions of the resolver-policy logic, composition rules, threat-model parameters, definitions of 'wrong-provider' triggers, and the modeling approach for multi-server resolution. This will include specific examples and potentially pseudocode to allow independent verification and falsification of the reported rates. revision: yes
-
Referee: [Threat modeling and risk framework] Risk-identification section: the derivation of the twelve risks is described as systematic, but the paper provides no explicit mapping from the examined architectural features to each risk, nor any justification that the set is exhaustive. This leaves the completeness of the framework open to question and weakens the cross-protocol comparisons.
Authors: We acknowledge the value of an explicit mapping. We will revise the risk-identification section to include a detailed mapping table that links each of the twelve risks to the specific architectural features, trust assumptions, interaction patterns, and lifecycle behaviors examined during the threat modeling. Additionally, we will provide a justification for the set's coverage, explaining how it derives from the protocol analyses and noting its extensibility for future protocols. This should strengthen the cross-protocol comparisons and address concerns about completeness. revision: yes
Circularity Check
No circularity detected; threat modeling and case study are direct architectural analysis
full rationale
The paper develops its threat model and twelve-risk framework through direct examination of protocol architectures, trust assumptions, interaction patterns, and lifecycle behaviors. The MCP case study quantifies wrong-provider tool execution via measurement under representative resolver policies without any equations, fitted parameters, or reductions to self-defined inputs. No self-citations are invoked as load-bearing premises for uniqueness theorems or ansatzes. The derivation chain remains self-contained and does not reduce any claim to its own outputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 7 Pith papers
-
Attacks and Mitigations for Distributed Governance of Agentic AI under Byzantine Adversaries
Identifies concrete attacks from a malicious Provider on SAGA and proposes SAGA-BFT, SAGA-MON, SAGA-AUD, and SAGA-HYB mitigations offering different security-performance trade-offs.
-
MCP-DPT: A Defense-Placement Taxonomy and Coverage Analysis for Model Context Protocol Security
MCP-DPT creates a defense-placement taxonomy that organizes MCP threats and defenses across six architectural layers, revealing mostly tool-centric protections and gaps at orchestration, transport, and supply-chain layers.
-
MAGIQ: A Post-Quantum Multi-Agentic AI Governance System with Provable Security
MAGIQ introduces a post-quantum secure system for policy definition, enforcement, and accountability in multi-agent AI using novel cryptographic protocols and UC framework proofs.
-
Security Considerations for Multi-agent Systems
No existing AI security framework covers a majority of the 193 identified multi-agent system threats in any category, with OWASP Agentic Security Initiative achieving the highest overall coverage at 65.3%.
-
When Agents Handle Secrets: A Survey of Confidential Computing for Agentic AI
A survey providing a taxonomy of TEE platforms, an agent-centric threat model, and open challenges for applying confidential computing to secure agentic AI systems.
-
SoK: Security of Autonomous LLM Agents in Agentic Commerce
The paper systematizes security for LLM agents in agentic commerce into five threat dimensions, identifies 12 cross-layer attack vectors, and proposes a layered defense architecture.
-
When Agents Handle Secrets: A Survey of Confidential Computing for Agentic AI
A structured survey of confidential computing for agentic AI that catalogs TEE platforms, agent-specific threats, transferable defenses, and remaining gaps in end-to-end frameworks.
Reference graph
Works this paper leans on
- [1]
-
[2]
G. De Gasperis, S. D. Facchini, A comparative study of rule-based and data-driven approaches in industrial monitoring, arXiv preprint arXiv:2509.15848 (2025)
- [3]
-
[4]
M. Haenlein, A. Kaplan, A brief history of artificial intelligence: On the past, present, and future of artificial intelligence, California management review 61 (4) (2019) 5–14
work page 2019
-
[5]
J. Luo, W. Zhang, Y . Yuan, Y . Zhao, J. Yang, Y . Gu, B. Wu, B. Chen, Z. Qiao, Q. Long, et al., Large language model agent: A survey on method- ology, applications and challenges, arXiv preprint arXiv:2503.21460 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, M. S. Bernstein, Generative agents: Interactive simulacra of human behavior, in: Proceed- ings of the 36th annual acm symposium on user interface software and technology, 2023, pp. 1–22
work page 2023
- [7]
-
[8]
A. Ehtesham, A. Singh, G. K. Gupta, S. Kumar, A survey of agent interop- erability protocols: Model context protocol (mcp), agent communication protocol (acp), agent-to-agent protocol (a2a), and agent network protocol (anp), arXiv preprint arXiv:2505.02279 (2025)
- [9]
-
[10]
B. C. Das, M. H. Amini, Y . Wu, Security and privacy challenges of large language models: A survey, ACM Computing Surveys 57 (6) (2025) 1–39
work page 2025
-
[11]
M. Q. Li, B. C. Fung, Security concerns for large language models: A sur- vey, Journal of Information Security and Applications 95 (2025) 104284
work page 2025
- [12]
- [13]
- [14]
-
[15]
Y . Yao, J. Duan, K. Xu, Y . Cai, Z. Sun, Y . Zhang, A survey on large language model (llm) security and privacy: The good, the bad, and the ugly, High-Confidence Computing 4 (2) (2024) 100211
work page 2024
-
[16]
S. Zeng, J. Zhang, P. He, Y . Liu, Y . Xing, H. Xu, J. Ren, Y . Chang, S. Wang, D. Yin, et al., The good and the bad: Exploring privacy issues in retrieval-augmented generation (rag), in: Findings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 4505–4524
work page 2024
- [17]
-
[18]
K.-T. Tran, D. Dao, M.-D. Nguyen, Q.-V . Pham, B. O’Sullivan, H. D. Nguyen, Multi-agent collaboration mechanisms: A survey of llms, arXiv preprint arXiv:2501.06322 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Bizety, The push for standard protocols in the age of ai agents, https: //bizety.com/2025/09/30/the-push-for-standard-protoco ls-in-the-age-of-ai-agents/, accessed: 2026-01-21 (Sep. 2025)
work page 2025
-
[20]
B. Radosevich, J. Halloran, Mcp safety audit: Llms with the model context protocol allow major security exploits, arXiv preprint arXiv:2504.03767 (2025)
-
[21]
X. Hou, Y . Zhao, S. Wang, H. Wang, Model context protocol (mcp): Landscape, security threats, and future research directions, arXiv preprint arXiv:2503.23278 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [22]
-
[23]
N. Yang, G. Lyu, M. Ma, Y . Lu, Y . Li, Z. Gao, H. Ye, J. Zhang, T. Chen, Y . Chen, Iot-mcp: Bridging llms and iot systems through model context protocol, in: Proceedings of the ACM Workshop on Wireless Network Testbeds, Experimental evaluation & Characterization, 2025, pp. 73–80
work page 2025
-
[24]
S. Li, X. Wei, J. Yuan, X. Wang, K. Miao, Secure model context protocol for large language models with dual signatures, in: Proceedings of the 20th Workshop on Mobility in the Evolving Internet Architecture, 2025, pp. 1–6
work page 2025
- [25]
- [26]
- [27]
- [28]
-
[29]
X. Duan, Z. Huang, S. Liang, S. Zheng, L. Lu, T. Sun, Ai-agent com- munication network for 6g: vision, architecture, and key technologies, Frontiers of Information Technology & Electronic Engineering 26 (11) (2025) 2065–2080
work page 2025
- [30]
-
[31]
X. Zhang, X. Dong, Y . Wang, D. Zhang, F. Cao, A survey of multi-ai agent collaboration: Theories, technologies and applications, in: Proceedings of the 2nd Guangdong-Hong Kong-Macao Greater Bay Area International Conference on Digital Economy and Artificial Intelligence, 2025, pp. 1875–1881
work page 2025
-
[32]
Y . Wang, Y . Pan, S. Guo, Z. Su, Security of internet of agents: Attacks and countermeasures, IEEE Open Journal of the Computer Society (2025)
work page 2025
- [33]
-
[34]
Q. Duan, J. Zhou, W. Zhang, Agent communications in edge computing toward agentic ai-driven internet of things
- [35]
- [36]
- [37]
- [38]
-
[39]
S. Gupta, Ai agents collaboration under resource constraints: Practical implementations, INTERNATIONAL JOURNAL OF ARTIFICIAL IN- TELLIGENCE RESEARCH AND DEVELOPMENT 3 (1) (2025) 51–63
work page 2025
-
[40]
Anthropic, Introducing the Model Context Protocol, https://www.anth ropic.com/news/model-context-protocol , accessed: 2025-08-07 (Nov. 2024)
work page 2025
-
[41]
R. Surapaneni, M. Jha, M. Vakoc, T. Segal, Announcing the agent2agent protocol (a2a), https://developers.googleblog.com/en/a2a-a -new-era-of-agent-interoperability/ , accessed: Aug. 11, 2025 (Apr. 2025)
work page 2025
-
[42]
Hardt, The oauth 2.0 authorization framework, Tech
D. Hardt, The oauth 2.0 authorization framework, Tech. rep. (2012)
work page 2012
- [43]
-
[44]
a2aproject, A2a: An open protocol enabling communication and interoper- ability between opaque agentic applications, https://github.com/a 2aproject/A2A, accessed: Aug. 11, 2025 (2025)
work page 2025
-
[45]
GaoWei Chang and the Agent Network Protocol Project, Agent network protocol: The http of the agentic web era, https://www.agent-netwo rk-protocol.com/, accessed: Aug. 14, 2025 (2025)
work page 2025
-
[46]
agent-network-protocol, Agentnetworkprotocol- an open-source protocol for agent communication enabling decentralized, secure collaboration, https://github.com/agent-network-protocol/AgentNetwork Protocol, accessed: Aug. 15, 2025 (2025)
work page 2025
-
[47]
D. Biswas, Agentic ai mcp tools governance, https://medium.com/d ata-science-collective/agentic-ai-mcp-tools-governanc e-14c933386abe, accessed: Sep. 20, 2025 (Jul. 2025)
work page 2025
-
[48]
C. Posta, Deep dive mcp and a2a attack vectors for ai agents, https: //www.solo.io/blog/deep-dive-mcp-and-a2a-attack-vecto rs-for-ai-agents, accessed: Sep. 20, 2025 (May 2025)
work page 2025
-
[49]
J. A. Wibowo, G. C. Polyzos, Toward a safe internet of agents, arXiv preprint arXiv:2512.00520 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [50]
-
[51]
S. Zhao, Q. Hou, Z. Zhan, Y . Wang, Y . Xie, Y . Guo, L. Chen, S. Li, Z. Xue, Mind your server: A systematic study of parasitic toolchain attacks on the mcp ecosystem, arXiv preprint arXiv:2509.06572 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [52]
- [53]
-
[54]
M. M. Hasan, H. Li, E. Fallahzadeh, G. K. Rajbahadur, B. Adams, A. E. Hassan, Model context protocol (mcp) at first glance: Studying the secu- rity and maintainability of mcp servers, arXiv preprint arXiv:2506.13538 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [55]
-
[56]
X. Li, X. Gao, Toward understanding security issues in the model context protocol ecosystem, arXiv preprint arXiv:2510.16558 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [57]
- [58]
- [59]
-
[60]
S. Jamshidi, K. W. Nafi, A. M. Dakhel, N. Shahabi, F. Khomh, N. Ezzati- Jivan, Securing the model context protocol: Defending llms against tool poisoning and adversarial attacks, arXiv preprint arXiv:2512.06556 (2025)
- [61]
- [62]
- [63]
-
[64]
L. Stappen, A. E. Turan, J. Hagerer, G. Groh, Agent2agent threats in safety-critical llm assistants: A human-centric taxonomy, arXiv preprint arXiv:2602.05877 (2026)
-
[65]
Z. Wang, Y . Gao, Y . Wang, S. Liu, H. Sun, H. Cheng, G. Shi, H. Du, X. Li, Mcptox: A benchmark for tool poisoning on real-world mcp servers, in: Proceedings of the AAAI Conference on Artificial Intelligence, V ol. 40, 2026, pp. 35811–35819
work page 2026
-
[66]
S. Guo, Y . Wang, Z. Su, Y . Pan, Q. Hu, T. H. Luan, Agent discovery in internet of agents: Challenges and solutions, IEEE Network (2026)
work page 2026
- [67]
-
[68]
R. S. Ross, Guide for conducting risk assessments (2012)
work page 2012
- [69]
-
[70]
International Organization for Standardization, International Electrotechni- cal Commission, Iso/iec 27005:2022 - information security, cybersecurity and privacy protection - information security risk management, accessed: Sep. 20, 2025 (2022). URLhttps://www.iso.org/standard/80585.html
work page 2022
- [71]
-
[72]
W. Zou, R. Geng, B. Wang, J. Jia, {PoisonedRAG}: Knowledge corruption attacks to {Retrieval-Augmented} generation of large language models, in: 34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 3827–3844
work page 2025
- [73]
-
[74]
S. Chen, J. Piet, C. Sitawarin, D. Wagner, {StruQ}: Defending against prompt injection with structured queries, in: 34th USENIX Security Sym- posium (USENIX Security 25), 2025, pp. 2383–2400. 19
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.